MYSQL的CRUD
目录
CRUD
新增数据(Create)
单行数据+全列插入
多行数据+指定列插入
查询数据(Retrieve)
全列查询
指定列查询
别名
去重
排序:ORDER BY
条件查询
分页查询
修改数据(Update)
删除数据(Delete)
数据库约束
约束类型
NULL约束
UNIQUE约束
DEFAULT约束
PRIMARY KEY约束
FOREIGN KEY
编辑
编辑
编辑
表的设计
一对一
一对多
多对多
新增
查询
聚合查询
COUNT:查询表里面的行数
SUM:求和
AVG:平均值
MAX
MIN
GROUD BY字句
HAVING
联合查询
内连接
外连接
自连接
子查询
合并查询
CRUD
先简单认识一下什么是CRUD?他们的作用是什么?
新增数据(Create)
查询数据(Retrieve)
修改数据(Update)
删除数据(Delete)
新增数据(Create)
先创建一个演示用的数据库,再在数据库里面创建一个演示用的表
create database Test1120 charset utf8;
use Test1120;
create table Test(
id int,
name varchar(20),
age int,
chinese Decimal(3,1),
math Decimal(3,1),
english Decimal(3,1)
);插入主要使用的是两种插入方式
1.单行数据+全列插入 2.多行数据+指定列插入
单行数据+全列插入
插入多条记录, 数量必须和定义表的列的数量及顺序一致
insert into Test values
(1,'张李紫',23,93.5,99,99.5),
(2,'李雪',22,93.5,98,94.5),
(3,'李雪妮',22,94.5,85.5,91.5),
(4,'赵李',22,80.5,85.5,86.5),
(5,'null',22,63.5,75.5,76.5); 
多行数据+指定列插入
插入多条记录,数量必须和指定列数量及顺序一致
insert into Test(id,name,age,math) values
(6,'周八',24,58),
(7,'张三',24,53),
(8,'李四',25,43),
(9,'王五',22,33),
(10,'吴九',26,20); 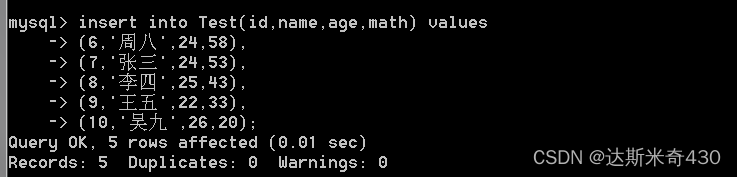
插入数据以后,想必一定很想知道,我要怎么样才能看到我前面插入进去的数据,
下面就开始介绍如何查看自己前面插入的数据
查询数据(Retrieve)
查询分为很多种类,可以满足很多不同需求,下面来看看都有哪些功能:
1全列查询 2.指定列查询 3.查询字段为表达式 4.别名 5.去重 6.排序:order by 7.条件查询 8.分页查询
查询是mysql里面种类最多的功能,耐下心来慢慢看
全列查询
通常情况下不建议使用 * 进行全列查询
1. 查询的列越多,意味着需要传输的数据量越大;
2. 可能会影响到索引的使用(后面的文章介绍索引的使用)
select * from Test;
通过本次全列查询,可以看出前面指定列插入的时候没有被赋值的数据全部用null填充了
指定列查询
指定列的顺序不需要按定义表的顺序来
想查那些,就查那些
select name,math from Test;

查询字段为表达式
表达式包含一个字段
select id,name,math from Test;
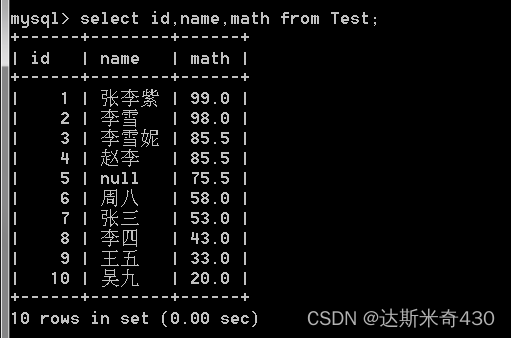
表达式包含多个字段
select name,math+chinese+english from Test; 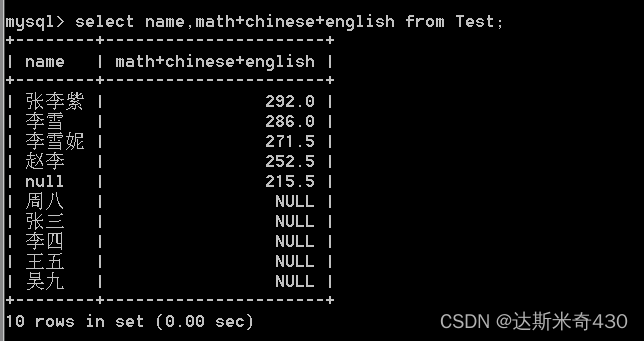
别名
为查询结果中的列指定别名,表示返回的结果集中,以别名作为该列的名称
就是起个外号,小名,别名.我可以叫作者,也可以叫学生,也可以叫同志
select name as '姓名' from Test;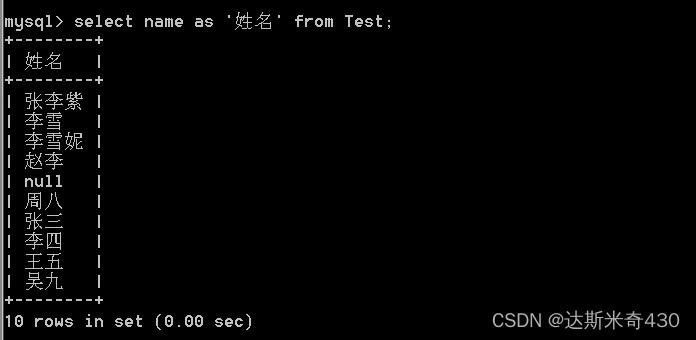
上面出现的as属于可有可无的,但是一般建议加上,1.不要给自己挖坑,2.为了代码的可读性
去重
使用DISTINCT关键字对某列数据进行去重:
select math from Test;先看一下眼去重前的数学成绩

这是去重后的数学成绩

可以看到少了一行数据,就是重复的数据没有了
排序:ORDER BY
1.ASC 为升序(从小到大)
2.DESC 为降序(从大到小)
3.默认为 ASC
select name,math from Test order by math;
select name,math from Test order by math desc;


注意事项:
1. 没有 ORDER BY 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序
2. NULL 数据排序,视为比任何值都小,升序出现在最上面,降序出现在最下面
同时SQL,mull和任何数值进行运算,结果都是null
select * from Test; 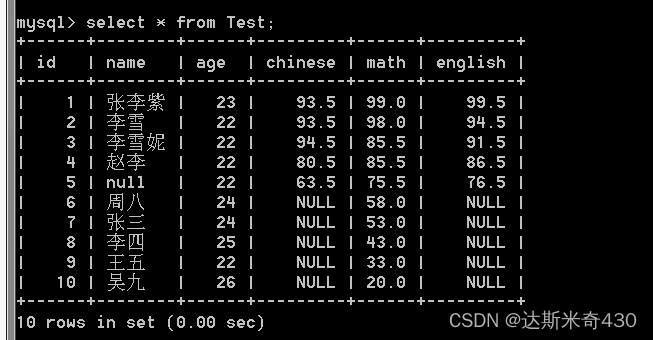
看似有序但是不一定可靠
前面我们使用了别名来查询,那么我们是否可以使用别名来进行排序?
select name as 姓名,chinese+math+english as 成绩 from Test order by 成绩 desc;
可以看到是可以实现的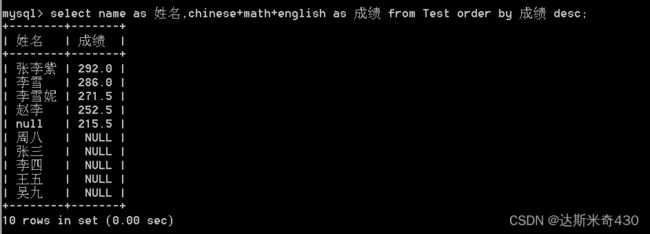
条件查询
比较运算符:
| 运算符 | 说明 |
| >, >=, <, <= | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL |
| <=> | 等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) |
| !=, <> | 不等于 |
| BETWEEN a0 AND a1 |
范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 TRUE(1) |
| IN (option, ...) | 如果是 option 中的任意一个,返回 TRUE(1) |
| IS NULL | 是 NULL |
| IS NOT NULL | 不是 NULL |
| LIKE | 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符 |
逻辑运算 :
| 运算符 | 说明 |
| AND | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| OR | 任意一个条件为 TRUE(1), 结果为 TRUE(1) |
| NOT | 条件为 TRUE(1),结果为 FALSE(0) |
注意:
1.WHERE条件可以使用表达式,但不能使用别名。
2. AND的优先级高于OR,在同时使用时,需要使用小括号()包裹优先执行的部分
代码演示:
查询:英语成绩小于80
select name,english from Test where english < 80;
查询:语文成绩>英语成绩
select name,chinese,english from Test where chinese > english; 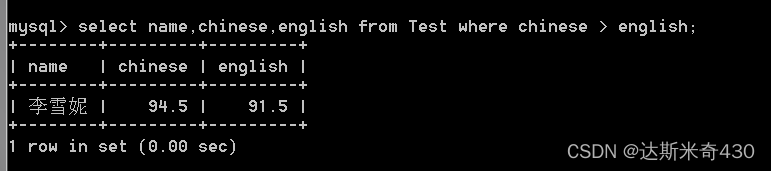
查询:语文加数学加英语小于220的
select name,chinese+english+math as total from Test where total < 220; ![]()
会看到MYSQL不支持这样进行计算,所以我们需要换一种写法
select name,chinese+english+math as total from Test where chinese+english+math < 220;

and与or
查询:语文成绩大于80 and 英语成绩大于80
select * from Test where chinese > 80 and english > 80;
查询:语文成绩大于80 or 英语成绩大于80
select * from Test where chinese > 80 or english > 80; 
范围查询
1.between...and...
查询:语文成绩在[80-90]的同学
select name,chinese from Test where chinese beteen 80 and 90; 
2.and
select name,chinese from Test where chinese >= 80 and chinese >= 90; 
3.in
查询:数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩
select name,math from Test where math in(58,59,98,99); 
使用 OR 也可以实现
select name,math from Test where math = 58 or math = 59 or math = 98 or math = 99; 
模糊查询:like
李 字开头的都可以查到
select * from Test where name like '李%'; 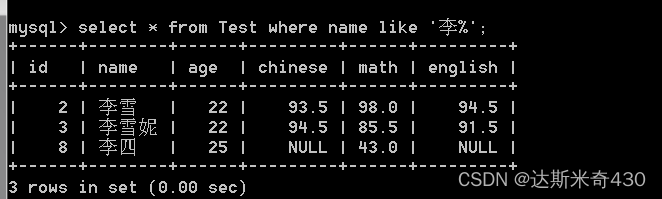
李 字开头的后面只有一个字的都可以查到
下划线只匹配一个字符
select * from Test where name like '李_'; 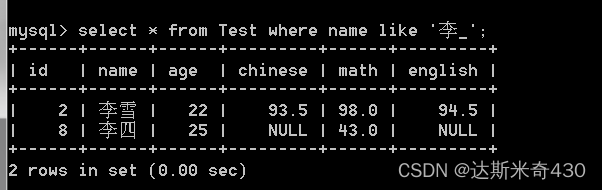
李 字结尾的可以查询到
select * from Test where name like '%李'; 
只要名字里面有'李'就可以查询到
select * from Test where name like '%李%'; 
null的查询:
select * from Test where chinese = null;

可以看到mysql显示的是设置成功
是因为null和null比较,结果还是null,判定结果为false
我们可以换一种比较方式
select * from Test where chinese <=> null;

我们也可以使用 is null 语句来判断语文成绩是否为空
select * from Test where chinese is null;

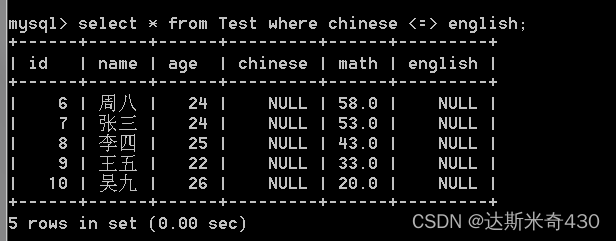
is null 语句 和 <=> 的区别就是:
1. is null 要求只能比较一个列是否为空
2. <=> 可以直接比较两个列,万一某一行,两列都是 null ,也能查询出来,这个场景使用 is null 来写,
就不好搞了
select * from Test where chinese <=> english;
我们也可以在 is null 的基础上家伙是加上 not 变成 is not null
select name,math from Test where math is not null; 
分页查询
从0开始,筛选五条结果
select * from Test order by id limit 5;
一页一条
select id,name,math,english,chinese from Test order by id limit 1 offset 1;

我们还可以让 update搭配order by/limit使用
select name,chinese+english+math as total from Test order by total limit 3;

所有的查询操作均为临时表,不会对表里面的数据进行任何修改 ! ! !
所有的查询操作均为临时表,不会对表里面的数据进行任何修改 ! ! !
所有的查询操作均为临时表,不会对表里面的数据进行任何修改 ! ! !
查询总结:
1.全列查询 select * from 表名;
2.指定列查询 select 列名 from 表名;
3.带表达式的查询 select 表达式 from 表名;
4.带别名的查询 select 列名/表达式 as 别名 from 表名;
5.去重查询 select distinct 列名 from 表名;
6.排序 select 列名 from 表名 order by 列名/表达式/别名 asc/desc;
修改数据(Update)
从这里开始,针对表的一切修改,皆是永久修改,不是针对临时表的修改! ! !
从这里开始,针对表的一切修改,皆是永久修改,不是针对临时表的修改! ! !
从这里开始,针对表的一切修改,皆是永久修改,不是针对临时表的修改! ! !
把李雪妮的数学修改到80
update Test set math = 80 where name = '李雪妮';

成功把李雪妮的数学成绩修改到了80
表达式修改,所有同学数学成绩减少5
update Test set math = math -5; 
让李雪的成绩全部为零
update Test set chinese = 0,math = 0, english = 0 where name = '李雪';

删除数据(Delete)
赵李同学换班了,我们可以删除他的所有数据
delete from Test where name = '赵李';

我们还可以删表
不过先不拿张表来做删除实验,毕竟删除以后没有回收站
create table GG(
id int,
name varchar(20)
);
insert into GG (name) values ('Z'),('X'),('C');
delete from GG;
我们可以看到GG这张表依然存在
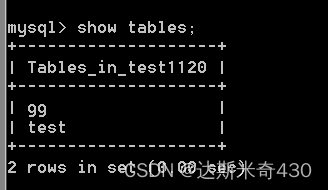
但是他的表已经空了,里面并没有数据

下面开始上数据库的难度,内容有:
数据库约束,表的设计,新增,查询
数据库约束
数据库约束的作用: 限制数据库中表内的数据,保证数据的正确性、有效性和完整性。如果向表中添加了约束,则不能向表中插入不正确的数据。创建表时添加约束更合适。约束用于限制加入表的数据的类型。可以在创建表时或创建表后规定约束。
约束类型
| 约束类型 | 作用 |
| NOT NULL | 指示某列不能存储 NULL 值 |
| UNIQUE | 保证某列的每行必须有唯一的值 |
| DEFAULT | 规定没有给列赋值时的默认值 |
| PRIMARY KEY | NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标 识,有助于更容易更快速地找到表中的一个特定的记录 |
| FOREIGN KEY | 保证一个表中的数据匹配另一个表中的值的参照完整性 |
| CHECK | 保证列中的值符合指定的条件。对于MySQL数据库,对CHECK子句进行分析,但是忽略 CHECK子句 |
注意:
NOT NULL 是必须填不能为空,允许为 NULL 就是选填项
UNIQUE 里面的唯一值 指的是 表里面不能有重复的值
主键,是非常重要的的约束,是每条记录的身份标识
下面开始详细介绍每个约束类型
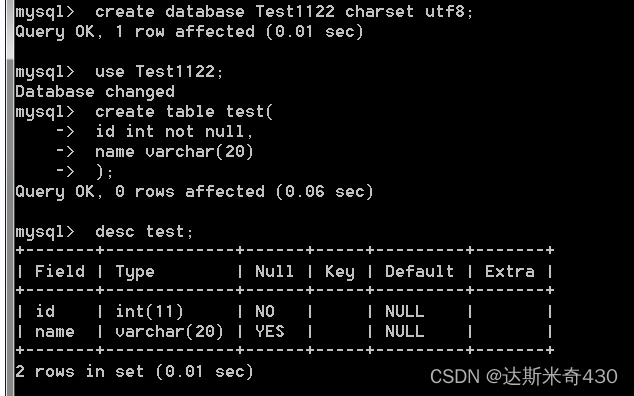
NULL约束
老规矩,先重新创建一个演示用的数据库,再建一张演示用的表
create database Test1122 charset utf8;
use Test1122;
-- 给id 添加上 not null 标记
create table test(
id int not null,
name varchar(20)
);
-- 表创建完成,查看表结构
desc test;通过查看表结构,我们可以发现在 NULL 这行属于的id的是 NO,属于name的是 YES,说明 NOT NULL约束起效了

现在进行如果在 id 上面加了 NOT NULL 约束以后,我还放 NULL,是什么效果
insert into test values(null,null);![]()
简单粗暴的报错
再来个正确的添加方式
insert into test values(1,null);
![]()
可以看到只要 id 不为空,name 为空,也不会报错,就是因为只有 id 添加了 NOT NULL 约束
name 并没有添加 NOT NULL 约束
UNIQUE约束
-- 删了上一张测试表,重新建立一张
drop table test;
-- 给id添加 unique 约束
-- 使得id不能重复
create table test(
id int unique,
name varchar(20)
);
-- 查看表结构
desc test;
可以看到 id 的key 这里多了一个 uni 这就是前面添加的 UNIQUE 约束
开始测试 unique 约束
insert into test values
(1,'张三'),
(1,'李四');
简单粗暴的报错
insert into test values
(1,'张三'),
(2,'李四'); 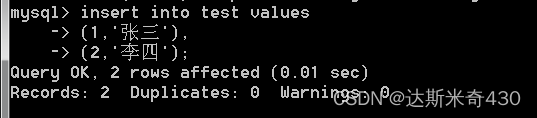
可以看到 unique 约束 发挥他的作用
DEFAULT约束
drop table test;
-- 使用default约束修改默认值
create table test(
id int,
name varchar(20) default '无名'
);
desc test;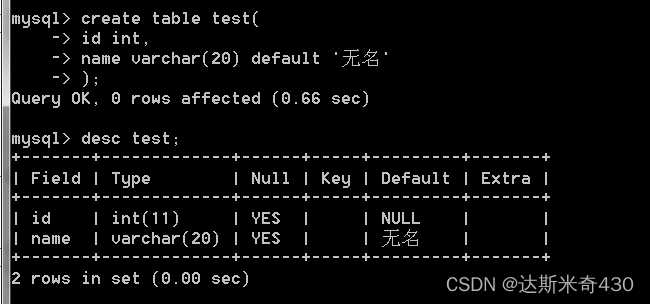
可以看到 name 的 default 这列显示的我修改完的 '无名' 不是他默认的 NULL
insert into test(id) values
(1),
(2);
select * from test; 
默认值不是系统的 null 而是我修改完的 无名
PRIMARY KEY约束
约束也可以组合使用,比如把最开始演示的 NOT NULL 和 UNIQUE 结合到一起使用
继续重新建表
drop table test;
-- 把 not null 和 unique 组合使用
create table test(
id int not null unique,
name varchar(20)
);
desc test;
还是对 id 进行 not null 和 unique约束,会发现 id 的 NULL 这列显示的是 NO 和最开始演示的一样
但是 KEY 这列显示的却不是 UNI 而是 PRI,哎,这个时候就会产生疑问,为什么会显示 PRI 而不是 UNI 我明明是用 not null 和 unique 约束 ,结果 key 显示的却是 PRI ? PRI有是什么东西?
PRI = PRIMARY KEY = NOT NULL + UNIQUE = 主键约束
这个时候就会有人说了:'哎,不是我不相信你,是我们大伙想亲眼看看'
现在开始演示
drop table test;
-- 使用primary key 对 id 进行约束
create table test(
id int primary key,
name varchar(20)
);
desc test;
我们可以看到 id 的 NULL 这列显示的东西和 Key 这列显示的东西 和前面 '对 id 进行 not null 和 unique约束',显示出来的效果一模一样
下面开始测试主键约束,看看他的功能是不是也和前面的两个约束一样
Insert into test values(null,null);
![]()
可以看到 id 不允许为 NULL
Insert into test values(1,'张三');

id 不为空 即可完成插入数据.
主键总结:
1.大部分表都会使用主键,主键往往是一个整数表示的id
2.在mysql中,一个表只能有一个主键,不能有多个主键
3.虽然主键不能有多个,但是mysql允许把多个列放到一起共同作为一个主键
4.主键一般不是手动递增,而是使用mysql自带的"自增主键"来完成递增
AUTO_INCREMENT
主键递增:AUTO_INCREMENT
继续重新建表演示:主键递增
drop table test;
-- 同时使用主键和主键递增
create table test(
id int primary key auto_increment,
name varchar(20)
);
desc test;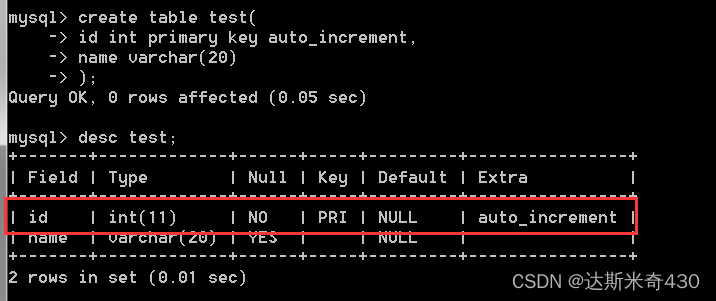
PS:补一条,如果没有写主键,只写了主键自增

明显也是不行的
开始插入数据
-- null 并不是设成空,而是交给数据库自己赋值
-- 每次插入数据他都会自己递增
insert into test values
(null,'张三'),
(null,'李四');
select * from test;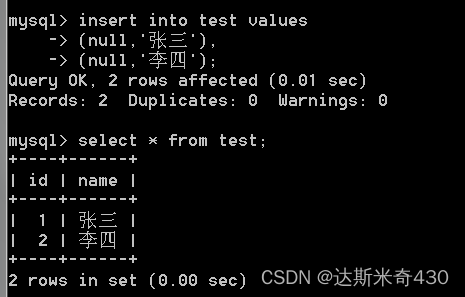
这个时候就会有人想说了:如果我在使用了主键递增的情况,我还给id进行赋值,他是数据库自己处理,还是按照赋值处理?
insert into test values
(100,'王五'); 
插入成功,现在让我们看看是什么答案是什么?

我们发现他是按照给 id 赋值的数据进行处理,并没有交给数据库处理
那我们如果在这个时候给 id 继续赋值 null 让数据库进行剩下的主键递增,他是从3开始还是从101开始?
insert into test values
(null,'你'),
(null,'猜'),
(null,'对'),
(null,'了'),
(null,'吗'); 
你猜对了吗?
当然了,可能也会有人觉得这样太浪费,但是int类型的范围在-21亿-21亿,一般来说都是够用的
FOREIGN KEY
外键约束:针对两个表之间产生约束
create table class(
id int primary key,
name varchar(20)
);
-- 班级的 Id 约束学生的 classId
create table student(
id int primary key,
name varchar(20),
classId int,
foreign key(classId) references class(id)
); 

我们创建三个班级,分别是java100班,c101班,python102班
然后把张三分到1,李四分到100,看看能不能操作成功
-- 创建三个班级
insert into class values
(1,'java100'),
(2,'c101'),
(3,'python102');
-- 给学生分配到班级
insert into student values(1,'张三',1);
insert into student values(2,'李四',100);
我们成功把张三分到了一班,现在我们把李四分到100班
![]()
我们可以看到,想把李四分到100班,失败了,因为班级只建立了三个那就是1班2班和3班,并没有100班,所以我们不能把李四分到100班
此时,产生约束的班级表,我们叫做'父表'(parent),被约束的表,就叫做'子表'(child)
这个时候,张三突然说他不想在1班待着,1班不好玩,她要换班,换到100班去
update student set classId = 100 where name = '张三';报错说不让移动到100,因为外界约束
说明外键约束,不管父表约束子表,子表也在约束父表
不让移动,那我们再试试让不让删除
delete from class where id = 1;
![]()
可以看出也不让删除
如果想删除,只能先删子表,再删父表
drop table student;
drop table class;
如果我们在建表的时候不加主键约束,直接用外键约束来建表,行不行?
create table class(
id int,
name varchar(20)
);
create table student(
id int,
name varchar(20),
classId int,
foreign key (classId) references class(id)
);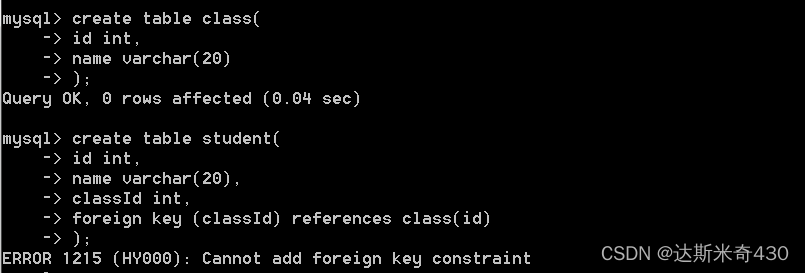
可以看到他不让外键约束生效,因为没有主键约束
同样的,如果不创建父表,先创建子表,也是无法约束的
表的设计
表的设计就是明确数据库里面:需要使用几个数据库.几个表,表里面有哪些列
一般思路是:
1.明确实体
2.明确实体之间的关系
3.套入到'固定'公式当中
一对一
比如:学信网里面,学生和账号的关系
一个学生在学信网有一个账号
一个学信网账号也只能被一个学生使用
'固定'公式一般为:
1.学生和账号在一个表里面
student_account(id,name,username,password);
2.学生和账号在不同的表里面,相互关联
student(studentId,name);
account(accountId,username,password,studentId);这两种方式都可以
student(studentId,name,accountId);
account(accountId,username,password);一对多
比如:学校的成绩系统里面,学生和班级的关系
一个学生只能在一个班级
一个班级里面可以有多个学生
'固定'公式一般为:
student(id,name,classId);
class(classId,name);多对多
比如:学校里面,学生和课程的关系
一个学生可以选择多门课程
一个课程可以被多个学生选择
'固定'公式一般为:
先建两张表
-- 一张学生表
student(studentId,name);
1 张三
2 李四
3 王五
-- 一张课程表
corse(courseId,name);
100 语文
101 数学
102 英语
-- 通过这张表他们连接起来
student_course(studentId,courseId)
1 100
1 101
2 100新增
插入查询结果
重新建表,插入数据
create table student(
id int,
name varchar(20)
);
insert into student values
(1,'张三'),
(1,'李四'),
(1,'王五'),
(1,'赵六');
select * from student;
现在开始插入查询结果
create table student2(
id int,
name varchar(20)
);
insert into student2 select * from student;
select * from student2;
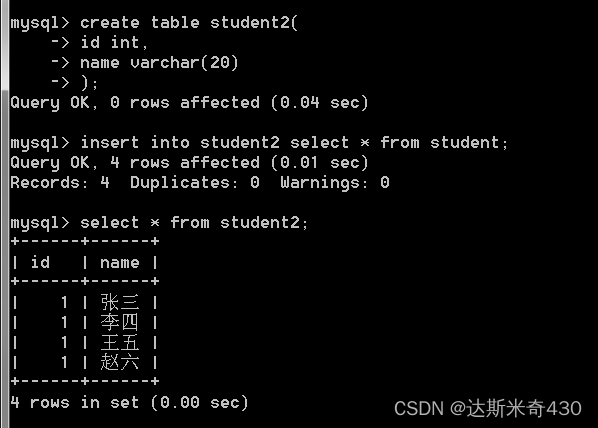
可以看到我们把student表里面的数据全部搬到了student2里面
查询
聚合查询
本质上是针对行和行之间的运算
| 函数 | 说明 |
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
开始测试
创建测试用例
create table test(
id int,
name varchar(20),
chinese Decimal(3,1),
math Decimal(3,1),
english Decimal(3,1)
);
insert into test values
(1,'张三',93.5,99,99.5),
(2,'李四',93.5,98,94.5),
(3,'王五',94.5,85.5,91.5),
(4,'赵六',80.5,85.5,86.5),
(5,'null',63.5,75.5,76.5),
(6,'刘一',80.5,85.5,86.5);COUNT:查询表里面的行数
select count(*) from test;
可以看到返回了六行
count() 的括号里面可以是任意列名/表达式,不一定是 *
换成 name 也是可以的
select count(name) from test;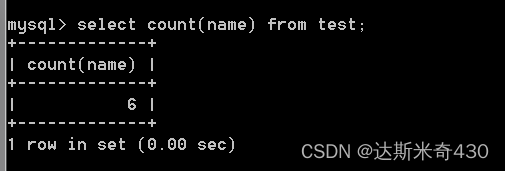
那么,如果我们插入一行全是null的数据,他会不会计算进去呢?
insert into test values(null,null,null,null,null);

查询一下,看看结果是什么
select count(*) from test;
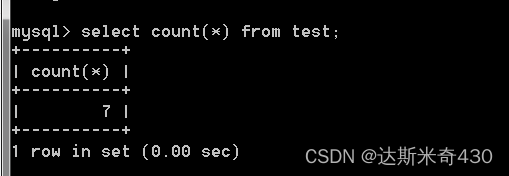
可以看到增加了一行,说明他是算进去的,那么如果我把括号里面的 * 换成name来查询,他是显示多少呢?
select count(name) from test;

可以看到他把全是null的那一行给去掉了
想必现在已经掌握count查询了,那么我们来看看下面这个sql语句为什么报错呢?
select count (*) from test;
 只是因为在count和(*)之间加了一个空格就导致了报错,真是可惜呢
只是因为在count和(*)之间加了一个空格就导致了报错,真是可惜呢
SUM:求和
下面我们来看看sum的用法
sum是求和,把这一列的所有行进行相加,求得这个列必须是数字,不能是字符串或者日期
select sum(chinese) from test;
通过求和拿到了所有的语文成绩,但是,原本有一行是全NULL的,sum在进行运算的时候会避免和NULL进行运算,因为任何数据和NULL运算,结果都是NULL

如果我们用不是数字的列进行运算,会得到上面结果呢?
select sum(name) from test;

AVG:平均值
我们还可以求语文的平均值
select avg(chinese) from test;

也可以求语文+数学+英语的平均值
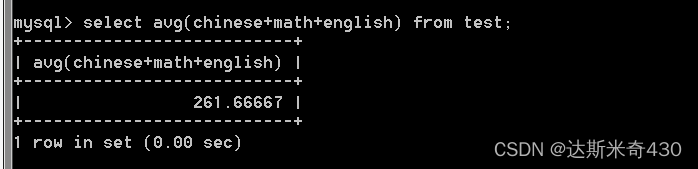
select avg(chinese+math+english) from test;
MAX
我们可以求语文的最高成绩
MIN
我们可以求语文的最低成绩
也可以最大值和最小值一起求
select max(chinese), min(chinese)from test;

GROUD BY字句
我们可以使用group by对表中的行进行分组
不用group by分组就相当于只有一组
引入group by就可以针对不同的组分别进行聚合
重新建个测试表
create table test(
id int primary key auto_increment,
name varchar(20),
role varchar(20),
salary Decimal(9,2)
);
insert into test values
(null,'曹操','老板',1000000),
(null,'荀彧','谋士',99000),
(null,'刘备','老板',10000),
(null,'关羽','武将',8000),
(null,'孙坚','老板',100000),
(null,'夏侯渊','武将',80000),
(null,'夏侯惇','武将',88000),
(null,'郭嘉','谋士',98000);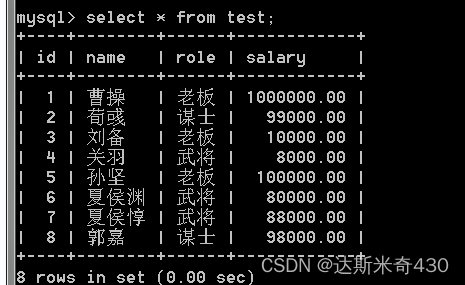
我们可以使用前面学会到avg来算工资的平均值
select avg(salary) from test;
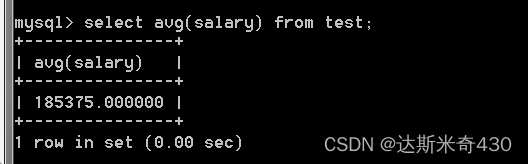
但是这个工资平均值毫无意义,因为老板拿的钱肯定和武将还有谋士的不一样
这就像阿斗当年和赵云在长坂坡七进七出甚至一直领先子龙半个身位一样
我们应该根据岗位不同来进行划分
select role,avg(salary) from test group by role;
这样我们就可以得到一个合理的划分

但是,刘皇叔毕竟家底薄,导致他虽然是老板,但是他能分到的钱,可能还没有别人家的武将或者谋士多,所以我们可以把刘皇叔也从里面拿出来
select role,avg(salary) from test where name != "刘备" group by role;

我们可以看到老板的平均工资直线上升
我们也可以对他进行排序
select role,avg(salary) from test where name != "刘备"
group by role order by avg(salary) desc;
如果我们不使用聚合查询就使用group by会怎么样呢?
select * from test group by role;
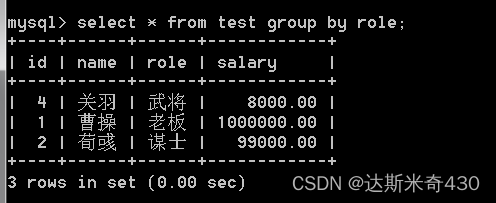
这里得到的就是每个分组记录的第一条记录
分组查询,可以指定条件
1.分组之前,指定条件, 先筛选,后分组 where
2.分组之后,指定条件 先分组,后筛选 having
3.分组之前和分组之后,都指定条件
前面那个演示的把刘皇叔去调就是典型的分组之前,指定条件
下面看一个分组之后,指定条件
HAVING
查询各个岗位平均薪资,但是要刨除平均薪资在十万以上的
select role, avg(salary) from test group by role having avg(salary) < 100000;
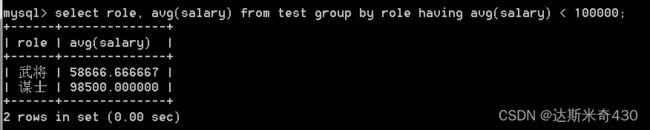
如果我们想看谋士的工资,不想看武将和老板的,也可以做到
select role,avg(salary) from test group by role having
avg(salary) < 100000 and avg (salary) > 60000;

逻辑运算符,在sql语句中也是支持的,也可以和group by还有 having一起使用
我们还可以在多融合一些操作方式进去
select role, avg(salary) from test where name != '刘备' group by
role having role != '武将';
联合查询
联合查询就是多表查询,多表查询就是对多张表的数据取笛卡尔积
笛卡尔积:就是把两张表放到一起进行计算,分别取出第一张表的第一行和第二张表的第一行,配对,然后得到一个新的记录
create database test1202 charset utf8;
use test1202;
create table class(
classId int primary key,
name varchar(20)
);
create table student(
id int primary key auto_increment,
name varchar(20),
classId int,
foreign key (classId) references class(classId)
);
insert into class values
(1,'主公'),
(2,'谋士'),
(3,'武将');
insert into student values
(null,'曹操',1),
(null,'刘备',1),
(null,'诸葛亮',2),
(null,'荀彧',2),
(null,'夏侯惇',3),
(null,'赵云',3);
select * from student;
select * from class;
还可以顺手检验一下前面的主键约束,外键约束,主键自增掌握的如何
insert into student values(null,'王朗',4);![]()
跑题了,下面开始演示笛卡尔积
两表相交,得到笛卡尔积
select * from student,class;

笛卡尔积是通过排列组合得到的,列数就是两个表列数之和,行数就是两个表行数之积
通过观察笛卡尔积可以发现大部分数据都是废数据,有用的数据只占一部分,我们需要清除掉没有用的数据
可以看出 classId 相同的数据就是有用的数据,不同的数据就是废数据
由此我们可以得出一条sql语句
select * from student,class where classId = classId;
![]()
出错了,尬住了,但是先不要急,仔细看看为什么报错
他说where子句里面 classId 列,模棱两可
我们需要把classId搞得清楚一些
select * from student,class where student.classId = class.classId;

student.classId 中的 . ,就是成员访问运算符
当我们明确了需要筛选的数据也就是明确了链接条件以后
我们就得到了上图里面正确的数据
也可以不使用全列查询,使用指定列查询,效果也是一样
下面演示一个不要id和classId的指定列查询
-- 有点长,不方便看,我把他断开了,使用的时候需要连起来
select student.name,class.name from student,class where
student.classId = class.classId;

重新建表
create database test1202 charset utf8;
use test1202;
create table classes(
id int primary key auto_increment,
name varchar(20),
`desc` varchar(100)
);
create table student (
id int primary key auto_increment,
sn varchar(20),
name varchar(20),
qq_mail varchar(20),
classes_id int
);
create table course(
id int primary key auto_increment,
name varchar(20)
);
create table score(
score decimal(3,1),
student_id int,
course_id int
);
insert into classes(name, `desc`) values
('计算机系2019级1班', '学习了计算机原理、C和JAVA语言、数据结构和算法'),
('中文系2019级3班', '学习了中国传统文学'),
('自动化2019级5班', '学习了机械自动化');
insert into student(sn,name,qq_mail,classes_id) values
('09982','黑旋风李逵','[email protected]',1),
('00835','菩提老祖','null',1),
('00391','白素贞','null',1),
('00054','许仙','[email protected]',1),
('00054','不想毕业','null',1),
('51234','好好说话','[email protected]',2),
('83223','tellme','null',2),
('09527','老外学中文','[email protected]',2);
insert into course(name) values
('java'),('中国传统文化'),('计算机原理'),('语文'),('高阶数学'),('英语');
insert into score(score,student_id,course_id) values
-- 黑旋风
(70.5,1,1),(98.5,1,3),(33,1,5),(98,1,6),
-- 菩提
(60,2,1),(59.5,2,5),
-- 白素贞
(33,3,1),(68,3,3),(99,3,5),
-- 许仙
(67,4,1),(23,4,3),(56,4,5),(72,4,6),
-- 不想毕业
(81,5,1),(37,5,5),
-- 好好说话
(56,6,2),(43,6,4),(79,6,6),
-- tellme
(80,7,2),(92,7,6);我们已经学会了使用笛卡尔积来进行多表查询,现在在回顾一下
第一步:计算笛卡尔积
select * from student, score;

太长了,摆不下,随便切了一点
第二步:加上链接条件
select * from student,score where student.id = score.student_id;

第三步:上附加条件
比如:我要找许仙的成绩
-- 太长,切开,自用链接,懂?
select * from student, score where student.id = score.student_id
and student.name = '许仙';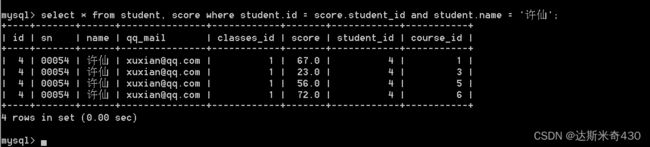
第四步:精简
-- 同上,懂?
select name, score from student, score where score.student_id = student.id
and student.name = '许仙'; 
内连接
还可以使用内连接的方式
-- 懂?
select * from student join score on student.id = score.student_id and
student.name = '许仙';
第二种语法格式
-- 和上一个比多一个join,懂?
select * from student inner join score on student.id = score.student_id and
student.name = '许仙'; 
from和join的区别:
from只能内连接
join不光可以内连接还可以外连接
此时,我们接到一个任务,需要查询所有同学的成绩,及个人信息
为了解决任务,我们需要用到学生表,成绩表,课程表,需要进行三表联合,让三张表进行笛卡尔积
我们先看看这三张表需要什么链接条件
desc student;
desc course;
desc score;
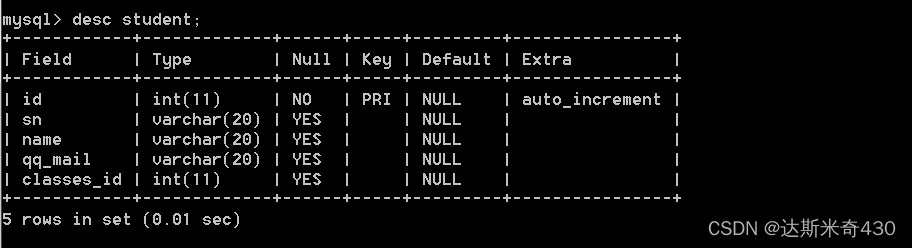

仔细观察,可以发现score的student_id和course_id和student的id以及course的id可以形成三表笛卡尔积的连接条件

由此我们得出,不过我们先用from来实现,等下再用join来实现
-- 懂?
select * from student,course,score where student.id = score.student_id
and course.id = score.course_id;
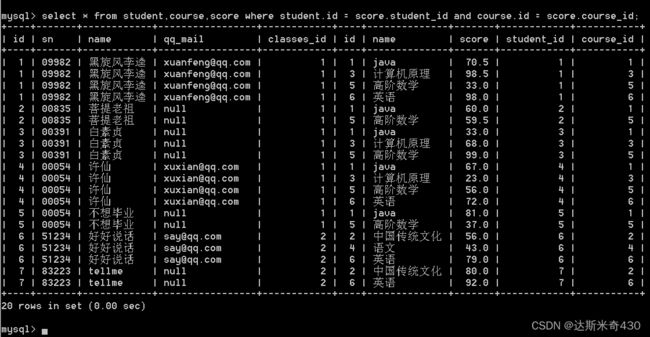
开始根据需求,对笛卡尔积进行删减
-- 懂?
select student.name, course.name, score.score from student, course, score
where student.id = score.student_id and course.id = score.course_id;

也支持改名功能
-- ?
select student.name as 学生姓名, course.name as 课程名称, score.score from
student, course, score where student.id = score.student_id and
course.id = score.course_id;
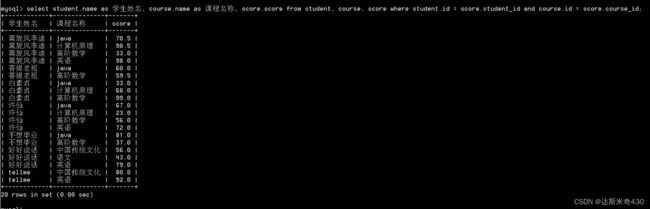
下面开始用join实现
-- 表1和表2线join 然后再和表3join
-- ?
select student.name as 学生姓名, course.name as 课程名称, score.score
from student join score on student.id = score.student_id join
course on score.course_id = course.id;
外连接
新建表演示
create database test1201 charset utf8;
use test1201;
create table student(
id int primary key auto_increment,
name varchar(20)
);
create table score(
student_id int primary key auto_increment,
score Decimal(3,1)
);
insert into student values
(null,'张三'),
(null,'李四'),
(null,'王五');
insert into score values
(null,'90'),
(null,'80'),
(null,'70');瞄一眼我们建好的表
select * from student;
select * from score;
此时学生表和分数表的关系是一对一的关系
要想知道那个学生的分数,拿出来看一眼就知道
select * from student,score where student.id = score.student_id;
select * from student join score on student.id = score.student_id;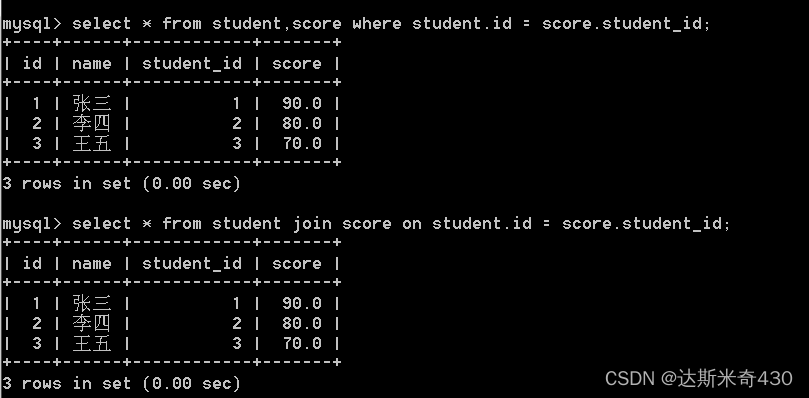
如果此时王五同学的成绩出现问题,在使用内连接查询,得到的结果就会不一样
update score set student_id = 4 where student_id = 3;
select * from student;
select * from score;

此时查询结果最终只剩下两个表都有的数据
select * from student,score where student.id = score.student_id;
select * from student join score on student.id = score.student_id;
但是,如果我们使用外连接,结果就会不一样
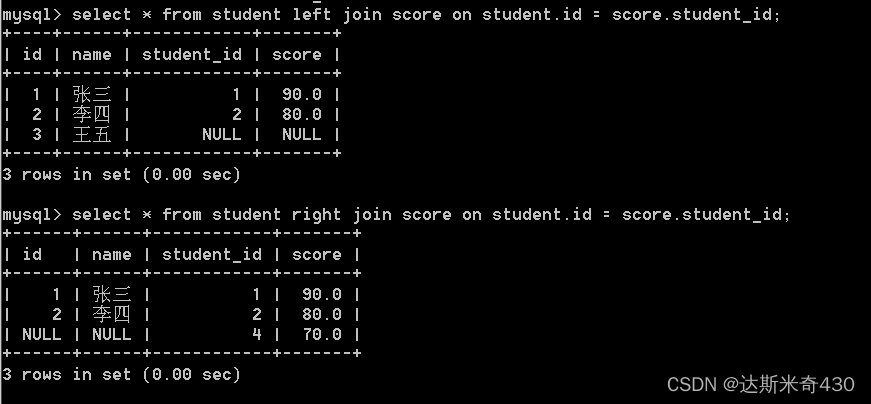
select * from student left join score on student.id = score.student_id;
select * from student right join score on student.id = score.student_id;我们可以看到左外连接和右外连接都会尽量把东西显示出来,哪怕没有对应的数据,它也会用null显示出来
自连接
自连接,就是自己和自己笛卡尔积
这个操作方式少见,属于'冷门',不是通用方案,是针对特殊问题的特殊解,就像生物上面的噬菌体一样
自连接的效果就是把行转成列
sql中无法针对行和行进行之间,使用条件比较
但是有的需求,有需要行和行之间进行比较,就可以使用自连接把行转成列,来进行比较
接到任务,任务要求使用上一个数据库里面的东西比较那个同学的计算机原理成绩比java的成绩高
(如果你删库了,那就可以回到上面重新建库了,重申:删库需谨慎)
我们先看看这些课程的id是多少,确定了是哪个id才好下手
看完id我们就开始看成绩找人
use test1202;
select * from score;
select * from course;
我们的目标是1和3,找到3比1高的

那么我们自交一下看看效果如果
select * from score,score;

尬住了,失败了,他说名字重复了,不是唯一的,这个有什么办法就解决呢?
起别名啊,活用知识
select * from score as s1,score as s2;
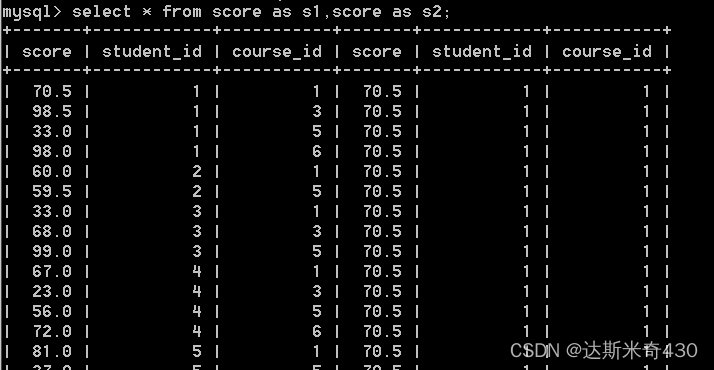
稍微有亿点长,摆不下
反正成功了,想看的自己试试
咳咳,继续正题,自交虽然成功了,但是大部分数据想必也是废数据,需要链接条件来让他筛选出正确的数据
select * from score as s1, score as s2 where s1.student_id = s2.student_id;

还是有亿点长,摆不下
我们继续观察自交后得到的笛卡尔积,继续上连接条件
通过观察,我们需要找到符合左侧是计算机原理的右侧是java的
select * from score as s1, score as s2 where s1.student_id = s2.student_id and s1.course_id = 3 and s2.course_id = 1;

继续观察,发现我们只需要保证3的成绩比1的大就行
select * from score as s1, score as s2 where s1.student_id = s2.student_id and s1.course_id = 3 and s2.course_id = 1 and s1.score > s2.score;

由此得到计算机原理成绩大于java成绩的同学
子查询
子查询,本质是俄罗斯套娃,把多个sql叠到一起
单行子查询:指嵌入在其他sql语句中的select语句,也叫嵌套查询
单行子查询:返回一行记录的子查询
查询与'不想毕业'同学的同班同学
select * from student;
我们需要先知道'不想毕业'同学是那个班级的

正常查询是用两条sql语句解决问题
select classes_id from student where name = '不想毕业';
select name from student where classes_id = 1 and name != '不想毕业';
子查询可以一条解决问题
select name from student where classes_id = (select classes_id from student where name = '不想毕业') and name != '不想毕业';

注意事项:
1.括号里面的内容必须只返回一条记录,此时才可以写作 = 否则是不行的
2.括号里面的查询,是另一个查询的一部分条件(就是套娃)
多行子查询:返回多行记录的子查询
接到任务:查询语文或者英语课程的成绩信息
分析:需要先根据名字得到得出id再根据课程id查询出课程分数
第一步:
select * from course where name = '语文' or name = '英语';

第二步:
select * from score where course_id = 4 or course_id = 6;

一行sql解决(一拳超人):
select * from score where course_id in (select id from course where name = '语文' or name = '英语');

注意事项:
1.括号里面的查询内容是存在内存中的,如果查询结果太大,内存放不下,in就会使用不了可以使用exists来代替
2.exists关键字.这个关键字,可读性差,执行效率大大低于in,使用是解决特殊场景
合并查询
合并查询:顾名思义,就是把两个查询结果集,合并成一个(需要两个结果的列相同才能合并)
union:此操作符用于取得两个结果集的并集,当使用该操作符时,会自动去重
任务:查询id小于3的,或者名字为'英语'的课程
select * from course where id < 3 union select * from course where name = '英语';
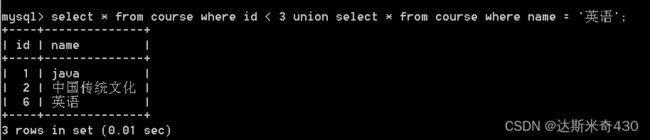
看到这里就有人发现了,这个union看起来和or差不多啊,那我为什么不用or要大费周章的用union呢
因为用or你的查询只能是来自同一个表
如果是union查询结果可以是来自不同的表,只要查询的结果的列匹配即可
(匹配:列的类型+列的个数+列的名字)
nuion all:该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行
union all和union 的区别:
union去重
union all不去重
以上内容便是MYSQL的CRUD全部内容了,有不对的地方欢迎指出,本文将对其进行修改,感谢观看