C语言深度剖析 -- 32个关键字(下)
文章目录
-
- if else 语句
-
- bool 与 0 的比较
- float 与 0 的比较
- 指针与 0 的比较
- switch case 语句
- do while for 关键字
- goto语句真的没人使用吗?
- void 关键字
-
- void能否定义变量?
- void定义指针
- void修饰函数返回值和作为函数参数
- return关键字
- const关键字
-
- const修饰的只读变量
- const修饰数组
- const修饰指针
- const修饰函数参数
- const修饰函数返回值
- 最易变的关键字 -- volatile
- extern关键字
- struct结构体
-
- 空结构体多大?
- 柔性数组
- 结构体内存对齐
- union联合体
- enum枚举关键字
- typedef关键字
- 32个关键字总结
-
- 数据类型关键字(12个)
- 控制语句关键字(12个)
- 存储类型关键字(5个)
- 其他关键字(3个)
- 关键字我们已经全部,讲完了,下一节将符号篇,这一节比较基础,下一节比较好玩哦!!!
if else 语句
- if else 语句的基本用法就不说了,我们重点看补充的知识点;
我们 if else 的语法就讲三个难点
- if else语句的执行顺序:先执行完成 if括号中表达式的值,得到逻辑结果,在进行判定
- if else 语句是支持嵌套使用的
- if else 中的else是匹配离上一个最近的if语句的,我们在写 if else 语句的时候,最好带上 代码块,不然会引起误会;
- 什么是语句? C语言中由一个分号 ;隔开的语句,例如:
printf("hello world"\n);int a = 10; - 什么是表达式? C语言中用各种操作符将变量连起来,形成有意义的式子,就叫做表达式;
bool 与 0 的比较
我们先来理解一下C语言中的 bool
我们首先要知道,C90标准是没有bool类型的(C++是有的),一直到C99才引入 _Bool类型(_Bool就是一个类型,头文件是 stdbool.h中,被重新用宏写成了bool,就是为了 C/C++的兼容性)
我们将bool转到定义,可以看到bool是由 _Bool用宏重写的了,而且 C将 false和 true用宏重写成了 0和1;
我们可以看到,不写头文件,C语言是不认识 bool类型的数据的;
那么bool类型的数据占用内存多少个字节呢?
我们可以看到bool类型占用一个字节的内存空间;
如果我们见多识广的话,还会在书上看到过大写的的BOOL 和大写的 FALSE 和 TRUE;这种大写的是微软的编译器自己开发的,不可跨平台,在Linux环境下试运行不了的,我们最好不要使用;之前看比特蛋哥讲过,但是我的VS2022不识别这个标识符,他们都是占用4个字节大小空间,我们只需要了解一下即可,无需使用他们;
C90不支持bool,而C99支持bool;我们这里按照最高屏的C90来讲bool与0的比较
我们首先要知道,以上三种写法都是正确的,但是我们更推荐第三种写法;
bool类型直接判定,不需要使用操作符和特定值来进行比较;

float 与 0 的比较
float类型的数据的存储我们会在后面讲到;我们现在只需要知道:浮点数在内存中的存储,并不是像我们想的那样是完整存储的,在十进制转为二进制的时候,是会有精度损失的;浮点数本身存储的时候,会采取四舍五入的规则;
不妨,我们来看个 demo:

我们将浮点数打印50位看:发现我们存储的 3.6存储到内存中并不是 3.6;
我们再来看一下 demo2:
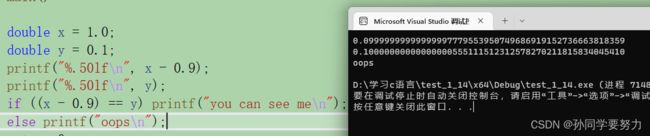
我们直观的看 1.0 - 0.9 就是等于 0.1 的,可是在编译器中并不是我们想的那样:x - 0.9是无限趋近于 0.1的,但并不等于 0.1;
从上面我们可以大概知道了,浮点数在内存中存储时,是会有精度损失的;
因为精度损失的问题,两个浮点数,是绝对不可以用双等号来进行比较的
那么两个浮点数该如何来进行比较呢?应该进行范围精度来比较
我们直接来看一下规则:是通过两个浮点数相减小于一个精度来比较这两个浮点数是否相等
伪代码:

这里面的精度是我们自己定义的吗?-> 这里的精度既可以我们自己来定义,也可以使用系统定义好的(宏定义);一般我们自己定义精度的时候,一般看题目中要我们保留几位小数,再往上精度两位就可以了,例如:题目要求我们保留六位小数,那么我们的精度就设置成八位;
使用宏定义的时候,需要带上头文件!!
#include 现在,我们再来看上面的那个例子!!!
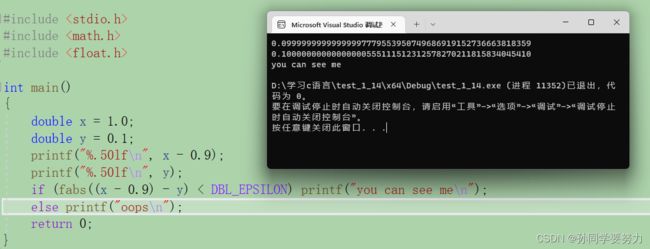
我们发现 1.0 - 0.9 就等于 0.1了
这里面补充一下,上面的 fabs() < EPS ,我们最好不要写成 <=;
指针与 0 的比较
指针我会在后面的专题细说
int* p = NULL;//指针一定要初始化
1. if(p == 0)
2. if(p)
3. if(NULL == p)
上面,更推荐大家使用第三种情况,第一种会让人误认为 p是整形变量,第二种会让人误认为 p是bool类型变量;
switch case 语句
基本语法就不说了,我们要知道case本质是用来进行判定功能的,break本质是用来进行分支功能的,default是用来处理异常情况的。
switch(m) 中的 m可以是我们定义的变量,而 case(n) 中的 n必须是常量,const修饰的常变量不可以。
补充:
- default可以放在任意顺序,但是好的代码风格我们要放在最后;
- 尽量每个 case语句都有 break 和 default;
- 语法书上说我们不可以在 switch case 语句中使用 return,但是实际上我们是可以使用的;但是不可以使用 continue关键字;
do while for 关键字
do while、for、while的循环基本语法就不说了;
我们看一下三种循环对应的死循环;
while(1) {}
for(;;) {}
do {}while(1)
在循环里面我们补充一个 getchar() 和 putchar() 函数:
#include 注意:getchar这个函数也会读取键盘上的 enter键(换行符);所以我们使用printf函数打印的时候就没有必要再换行了;
循环中最关键的无非就是 break和 continue这两个关键了!!!
但是基本的我就不说了,我就说一下 碰到continue下一次循环从哪里开始执行!!!

注意点:
- 在多重循环中,我们尽量将长的循环放在内部 -> 可以减少CPU跨越循环的次数
- for循环中的区间我们尽量写成左闭右开的形式;-> 可以方便计算循环次数
goto语句真的没人使用吗?
goto语句其实在以后我们工作环境中是会经常使用的!!!
基本语法:
#include 
void 关键字
void能否定义变量?
void a;像这样我们定义一个空类型a在vs中是编译不过去的,为什么编译不过去呢?我们来求一下 sizeof(void) 的大小是多少;

我们看到在vs中一个void类型是不占用空间的,之前我们说定义变量首先开辟好多少个字节的空间,而void是0个字节,所以就不可以在内存中开辟空间,因此void是不可以定义变量的!!!
在Linux中,void也是不可以定义变量的,但是在Linux中 sizeof(int)的大小是1,这是编译器的理解问题;我们只需要知道void不可以定义变量就可以了。
void定义指针
void是可以定义指针的,void*;void可以接受任意指针类型;例如:`void p = NULL:
但是,void*定义的指针变量不可以进行运算操作;我们在后面会系统讲解指针,我们应该知道,指针的加减操作,是指柱子很往后移动了了几个字节;比如说:int* p = &a; p++;指针p是一个整形指针,p++就是指指针p向后移动四个字节所指向的内容;而void可以接受任意指针类型,我们将void的指针加减是不明白指针向后移动几个字节的问题!!!void* p = NULL; p++;//报错 p += 1;//报错
void修饰函数返回值和作为函数参数
我们在定义函数的时候,函数没有返回值,我们就可以把函数的返回值设置成void;我们不可以不写,自定义函数默认的返回值类型是int。 void作为函数返回值,只是一个占位符的概念;
#include 如果一个函数没有参数,我们将函数的参数列表设置成void,是一个很好的习惯!!!
return关键字
首先,我们先来理解一段代码:
#include 我们来看一下输出结果:
为什么导致乱码了呢?
我们先来补充一个小概念,C语言中的常量字符串。我们知道C语言是没有string类的,而我们如果想在C语言中定义字符串有两种方式:分别是:
char str[] = "hello world";和char* s = "hello world";
我们先来看一下这样写法是否正确char str[20]; str = "hello world";这样写法是错误的!!!直接把数组元素赋值给数组名(数组首元素的地址)是不行的;如果我们刚开始没有初始化的话,只可以通过strcpy函数来实现!!!char str[20]; strcpy(str, "hello world");这样是正确的;C语言没有string容器,所以C语言的字符串是不可以直接str1 = str2;这样操作的,只可以使用字符串拷贝函数;但是,我们可以使用赋值对单个字符进行赋值,例如:str[0] = 'h'; str[1] = 'e';我们再来看第二种情形:char* s; s = "hello world";这样写法是正确的,我们理解一下:s是个字符指针,指向的是常量字符串h的地址!切记:这里面的字符串属于常量字符串,不可以修改字符串中的值;例如:
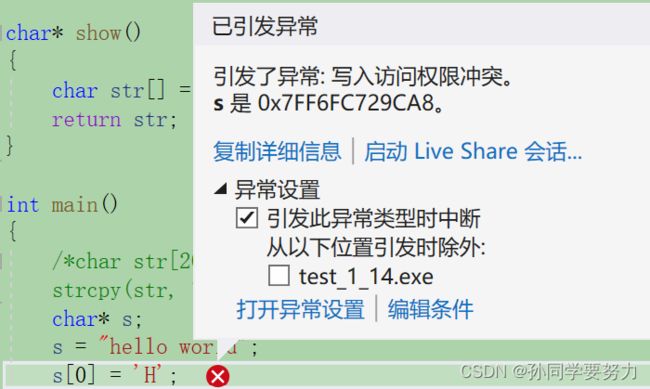
我们现在再来看一下上面的代码为什么是乱码呢?

我们必须要理解函数栈帧的概念,首先函数是在栈里面开辟空间,函数的开辟空间是一片一片的,每个函数里面又分为很多栈帧,我们知道:==调用函数,形成栈帧,函数返回,释放栈帧。==我们调用show函数时,形成栈帧,当返回函数时,show函数会被释放;注意,这里函数释放时,并不是直接将函数里面的内容都清零,而是只要保证这片空间下次可以使用就可以了,(计算机中,释放空间并不是将我们的数据全部清为0,只要将数据设置成无效就可以了。)因此里面的内容并不会清空。那为什么我们输出的还是随机数呢?因为printf也是函数,当show函数被释放时,内容还在,但我们使用printf函数的时候,又形成printf的函数栈帧,就是使用上次show函数的地址,所以就会导致生成随机数了!!!
我们再来看一个例子:
char* show()
{
char str[] = "hello world";
return str;
}
int test()
{
int a = 10;
return a;
}
int main()
{
int a = test();
printf("%d\n", a);
return 0;
}
这里我们输出的数是10,因为我们已经知道了test函数的返回值是10,我们将返回值存放到我们新定义的变量a中去了,上一个我们是使用地址来接收的;那么函数返回是通过什么来接受的呢?函数的返回值,通过寄存器的方式,返回给函数调用方。我们知道就可以了,这里面涉及汇编的知识。
const关键字
首先我们说一下,为什么要使用const修饰变量呢?提高效率

const修饰的只读变量
const修饰的变量具有只读性,不可直接进行修改;为什么说不能直接修改呢?是不是可以间接进行修改呢?答案是是的!!!我们可以通过指针来对const修饰的只读变量进行间接修改
#include 总结:
- const修饰的变量并非是真的不可被修改,指针可以对他进行间接修改
- const修饰的变量称为常变量,本质上还是变量;case后面必须跟的是常量,所以case后面跟的值不可以是const修饰的常变量
- const修饰的常变量在定义时必须直接初始化,不可以二次赋值
const修饰数组
C语言中数组的大小必须是个常量,不可以是const修饰的常变量;例如:const int n = 10; int arr[n];这种写法是错误的;但是c++是允许这种写法的;
const修饰数组与修饰一般变量一样,数组里面的值不可以再修改了;
const修饰指针
int a = 10;
1. const int* p = &a;
//int const *p = &a;
2. int* const p = &a;
3. const int* const p = &a;
- p指向的变量不可直接被修改,即:*p = 20;这种写法是错误的
- p的内容不可直接被修改,即:p = &b;这种写法是错误的
- p指向的变量和内容都不可被直接修改,即:*p = 20;p = &b;这两种都是错误的
const修饰函数参数
例如:void show(const int *p)我们这个函数的功能就是打印的,我们不希望改变传过来参数的值,我们就可以给形参加上const关键字告诉编译器不可改变指针p;一般修饰指针偏多;
const修饰函数返回值
例如:const int* getVal() { static int a = 10; return &a;}表示函数的返回值 &a不可被修改;
最易变的关键字 – volatile
如果我们写如下的代码时:
#include 当我们写如上的代码时,编译器会将变量pass读取到寄存器中(eax寄存器),程序知道这是个死循环,从此之后,不会再去内存中读取pass变量,而是直接在寄存器中读取就可以了;但是我们想:如果我们再循环过程中把pass变量改了咋办?程序认为这还是个死循环;
当我们在变量前加个关键字volatile后,程序还是将变量先读取到eax寄存器当中,但是下次读取的时候,会实现到内存中读取pass变量,然后再放到寄存器当中!!!这个关键字一般在多线程中会使用到;
注意:volatile const int a = 10;这样写代码是不冲突的!!!const是定义只读变量,我们不该变量就可以了;volatile意思是我们每次读取变量时,都要从内存中去读;
接下来的几个关键字,我们重点要掌握他们的语法就可以了!
extern关键字
在讲关键字的开始我们就说过了这个关键字,我们再来复习一下;
再多文件程序中,我们想访问别的源文件中的全局变量,需要加上extern关键字;例如:
extern int g_val;注意:extern是声明全局变量,我们不可以在进行赋值操作。 变量的声明必须要加上extern,函数的声明建议加上extern关键字(不加extern会有告警);
例如:test.c

main.c

struct结构体
基础语法,demo:描述一个学生:
struct stu
{
char name[20];
int age;
char sex;
int id[20];
}s1, s2, s3;//顺便定义几个结构体变量,就相当于int a, b, c;
空结构体多大?
struct stu
{
};
printf("%d\n", sizeof(struct stu));
我们会发现vs编译器会报错:![]()
但是我们要知道vs环境下,一个空结构体的大小为1个字节。 Linux下一个空结构体的大小为0个字节
柔性数组
在讲结构体时,我们就必须要说一下柔性数组的概念了;
C99中,结构体中的最后一个元素是允许是未知大小的数组,这个数组就称为柔性数组;但结构体的柔型数组前面必须至少有一个其他成员。
struct stu
{
int x;
int arr[0];
//int arr[];
};
上面的数组arr就称为柔型数组,我们想让数组的大小是多少,我们就动态内存开辟多少个空间;
例如:
struct stu* p = malloc(sizeof(struct stu) + sizeof(int) * 10);
这样我们就开辟了可以存放10个int的整形数组;最后再使用free释放就可以了;
记住,这里柔性数组是不占用结构体大小空间的,也就是结构体的大小是不包括柔型数组的!
结构体内存对齐
我们先来看一段代码:
//代码一
struct s1
{
char c1;
int i;
char c2;
};
int main()
{
struct s1 s = { 0 };
printf("%d\n", sizeof s);
return 0;
}
//代码二:
struct s2
{
char c1;
char c2;
int i;
};
int main()
{
struct s2 ss = { 0 };
printf("%d\n", sizeof ss);
return 0;
}
答案应该实际呢?我么可能会想:都是两个char是两个字节,一个int是四个字节,所以答案都是6?
我们来看一下输出:


结果和我们想的不一样,而且一样的内容,开辟的空间大小还不一样,那就是结构体开辟的空间大小是和我么想的不一样的!只是位置不同,就导致了大小不一样;
那么我么在以后该怎么样计算结构体大小呢?我们就不得不了解结构体的对齐规则了!!!
- 第一个结构体成员在结构体偏移量为0的地址处
- 其他成员变量要对齐到某个数字(对齐数)的整数倍地址处;对齐数=编译器默认的一个对齐数与该成员大小的较小值; vs编译器默认对齐数是8,Linux中默认对齐数是4;
- 结构体总大小为最大对齐数(每二个成员变量都有一个对齐数)的整数倍
- 如果嵌套了结构体的情况下,嵌套的结构体对齐到自己的最大对齐数的整数倍,结构体整体大小就是所有最大对齐数的整数倍

我们再来看一下结构嵌套该怎么计算大小:
struct s1
{
char c1;
int i;
char c2;
};
struct s2
{
char c1;
struct s1 s;
double d;
};
int main()
{
struct s2 ss = { 0 };
printf("%d\n", sizeof ss);
return 0;
}
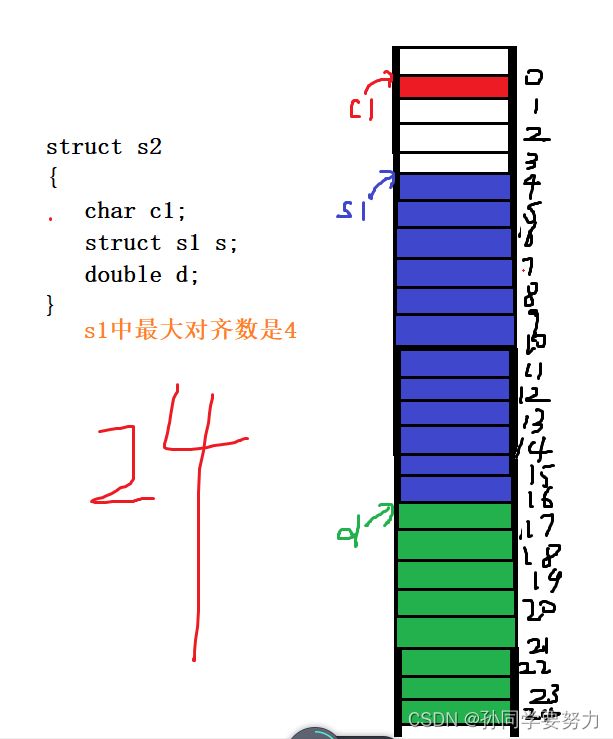

总结:
- 结构体的内存对齐是拿空间换取时间的做法
- 在设计结构体的时候,我们既为了满足对齐,又要节省空间,尽量让空间小的成员聚集在一起。
有时候不满意内存对齐数时,我们可以自己修改默认对齐数:
#pragma pack(4) //设置默认对齐数为4
#pragma pack() //取消设置的默认对齐数,还原为默认
#pragma pack(1) //设置默认对齐数为8
百度的一道面试题:写一个宏,计算结构体中某变量对于首地址的偏移,并给出说明
考察:offsetof宏的实现
#include 
在结构体里面,我们还要补充一下位段的概念
什么是位段?
位段的声明与结构体类似,有两个不同
- 位段的成员必须是int、unsigned int或者signed int
- 位段的成员后面有一个冒号和数字
#include 
看一个例子:
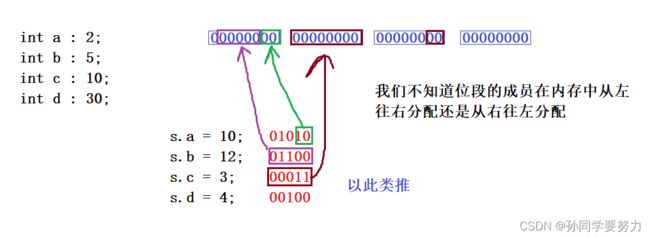
struct S
{
int a : 2;
int b : 5;
int c : 10;
int d : 30;
};
int main()
{
struct S s = { 0 };
s.a = 10;
s.b = 12;
s.c = 3;
s.d = 4;
return 0;
}
空间是如何开辟的呢?

union联合体
联合体的定义:
#include 
联合体的特点:联合体的成员共用一块内存空间,这样一个联合体变量的大小,至少是最大成员的大小(因为联合体至少得有能力存放最大的那个成员)
联合体大小的计算:
- 联合体的大小至少是最大成员的大小
- 当最大成员大小不是最大对齐数的整倍数时,就要对齐到最大对齐数的整数倍
例如:
#include 
例如第一个:c的对齐数是1,而i的对齐数是4;取最大对齐数的整数倍
第二个:本来应该是14个字节的,但14不是最大对齐数(4)的整数倍,所以应该是16个字节
union判定系统大小端:我们上面画的那个图

如果是小端存储的话,我们把联合体中的 i赋值成1,如果c也是1的话,那么就是小端存储了
#include 结果输出小端!!!
enum枚举关键字
枚举顾明思议就是列举;例如:
enum Day
{
Mon,
Tues,
Wed,
Thur,
Fri,
Sat,
Sun
};
enum Color
{
RED,
BLUE,
GREEN
};
注意:这些枚举类型都是有数值的,默认从0开始,依次递增1,;当然我们可以给一个枚举数据赋初始值,这个枚举元素的后面开始递增1
例如:

补充一点:枚举的大小默认是4个字节!!!(一般enum枚举的个数小于10 ^9个占4个字节,大于10 ^10占8个字节)

枚举与 #define宏的区别
- #define宏是在预编译阶段进行简单替换;枚举常量则是在编译的时候确定其值
- 一般在调试器中,可以调试枚举常量,但不能调试宏常量
- 枚举可以一次性枚举大量相关的常量,而#define宏一次只能定义一个
typedef关键字
typedef就是对类型重定义
typedef unsigned int u_int;//1.对一般类型重命名
typedef int* int_p;//2.对指针重命名
typedef int num[10];//3.对数组重命名,必须指定数组大小
typedef struct stu
{
char name[20];
int age;
char sex;
}stu;//4.对结构体重命名

我们可以看到上面监视的类型!!!
typedef与#define的一些区别:
我们先来看一个问题
int* a, b;
a和b分别是什么类型呢?

我们可以看到a是int*类型,而b确实int类型
问题一:
typedef int* ptr;
#define ptr_t int*
int main()
{
ptr p1, p2;
ptr_t p3, p4;
return 0;
}

我们发现用宏定义的和原来一样,p3是int*类型,而p4是int类型;
而我们用typedef重命名int后,p1和p2都变成了int类型了
问题二:下面那个是正确的
#include 32个关键字总结
数据类型关键字(12个)
- char:声明字符变量或函数
- short:声明短整型变量或函数
- int:声明整形变量或函数
- long:声明长整型变量或函数
- float:声明浮点数变量或函数
- double:声明双精度变量或函数
- signed:声明有符号类型变量或函数
- unsigned:声明无符号类型变量或函数
- struct:声明结构体变量或函数
- union:声明联合体(共用体)数据类型
- enum:声明枚举类型
- void:声明函数无返回值或无参数,声明无类型指针
控制语句关键字(12个)
- 循环控制(5个)
- for:一般循环语句
- do:循环语句的循环体
- while:循环语句的循环条件
- break:跳出当前循环
- continue:结束当前循环,开始下一轮循环
- 条件语句(3个)
- if:条件语句
- else:条件语句否定分支
- goto:无条件跳转语句
- 开关语句(3个)
- switch:用于开关语句
- case:开关语句分支
- default:开关语句的其他分支
- 返回语句(1个)
return:函数返回语句(可以带参数,也可以不带)
存储类型关键字(5个)
- auto:声明自动变量,一般不使用
- extern:声明变量是在其他文件中声明
- register:声明寄存器变量
- static:声明静态变量
- typedef:给数据类型取别名(分在这类没什么关联性)
存储类型关键字,不可以同时出现,也就是说,在一个变量定义的时候,只能有一个存储类型关键字
例如:typedef static int int32;这种写法是错误的!!!

但是:这种写法是可以编译过去的;
typedef int int32; static int32 a = 10;
其他关键字(3个)
- const:声明只读变量
- sizeof:计算数据类型长度
- volatile:说明变量在程序执行中可被隐含的改变