论文阅读-Attention Is All You Need阅读报告-机器翻译
1 Introduction
本文是2017年底谷歌大脑发表的文章,针对自然语言处理领域的经典问题-机器翻译,提出了一个只基于attention的结构来处理序列模型相关的问题,该模型被称为“Transformer”。文中提到,主流的序列转换模型都是基于复杂的循环神经网络(RNN)或卷积神经网络(CNN),且都包含一个encoder和一个decoder。RNN及其衍生网络的缺点就是慢,问题在于前后隐藏状态的依赖性,无法实现并行。截至“Transformer”提出前,表现最好的机器翻译模型是通过attention机制把encoder和decoder联接起来,而这篇文章提出的“Transformer”完全摒弃了递归结构,仅依赖注意力机制,挖掘输入和输出之间的全局依赖关系,同时具有更高的并行性,且训练所需要的时间更少。
2 Background
在此之前,针对机器翻译任务,为了应对RNN网络无法并行问题,已经有过一些使用CNN的解决方案了,例如谷歌的ByteNet,Facebook的FairSeq等等,它们都使用了卷积神经网络作为基础模块,并行计算所有输入和输出位置的隐藏表示,但在学习远距离位置之间的依赖性这方面仍具有挑战。
本文使用自注意力机制(Self-attention)将输入序列上不同位置的信息联系起来,然后计算出整条序列的某种表达,目前自注意力机制主要应用于阅读理解、提取摘要、文本推论等领域。Transformer是第一个完全依赖于self-attetion来计算其输入和输出表示,而不使用序列对齐的RNN或卷积的转换模型。
3 Model Architecture
模型总体架构如上图1所示,整个网络架构中使用堆叠的self-attention层、point-wise和全连接层,分别用于encoder和decoder。

3.1 Encoder and Decoder Stack
Encoder
Transformer模型的Encoder(编码端)由6个基本层堆叠起来,每个基本层包含两个子层,第一个子层是一个注意力机制,第二个是一个全连接前向神经网络。对两个子层都引入了残差边以及layer normalization。
Decoder
Transformer模型的Decoder(解码端)也由6个基本层堆叠起来,每个基本层包含三个子层,第一个子层是一个注意力机制,第二个是一个cross-attention, 第三层全连接前向神经网络,同样引入残差边以及layer normalization。
其中,交叉注意力部分是指解码端的每一层与编码端的最后输层做cross-attention。
3.2 注意力机制
注意力机制(Attention)是给定一个查找(Query)和一个键值表(key-value pairs),将Query映射到正确的输入的过程。此处的query、key、value和最终的输出都是向量。输出往往是一个加权求和的形式,而权重则由query、key和value决定。

Figure2: (left) Scaled Dot-Product Attention. (right) Multi-Head Attention consists of several attention layers running in parallel.
Scaled Dot-Product Attention
本文引入了一个特殊的attention,为Scaled Dot-Product Attention(上图2左)。输入由query、dk的key和dv的value组成。我们计算query和所有key的点积,我们计算query和所有key的点积,再除以,然后再通过softmax函数来获取values的权重。
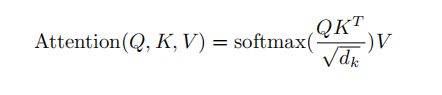
Multi-Head Attention
在queries, keys和values的每个映射版本上,我们并行的执行attention函数,生成dv维输出值。它们被拼接起来再次映射,生成一个最终值,如 Figure 2 中所示。
Multi-head attention允许模型把不同位置子序列的表示都整合到一个信息中。如果只有一个attention head,它的平均值会削弱这个信息。
本文使用的注意力机制

本文使用的是Multi-Head Attention,具体体现在两个方面。
a. 在“encoder-decoder attention”层中,query来自前一个decoder层,而key和value是encoder的输出。这允许decoder的每个位置都去关注输入序列的所有位置。
b. decoder包含self-attention层,在self-attention层中所有的key、value和query都来自前一层的encoder。这样decoder的每个位置都能去关注前一层encoder输出的所有位置。
3.3 前向神经网络(FFN)
这是一个 Position-wise 前向神经网络,encoder和decoder的每一层都包含一个前向神经网络,激活函数顺序是线性、RELU、线性。

位置编码
由于本文的模型结构没有使用任何递归结构或卷积结构,为了让模型能利用输入序列的顺序信息,必须引入某种能表达输入序列每个部分的绝对或相对位置的信息才行。文章采取的方法是位置编码(positional encoding),在送入encoder和decoder之前,先对输入进行编码,编码后的向量维度是dmodel。具体来说,采用正弦和余弦函数进行编码。

4 为什么使用self-attention
本文从三个方面去对比self-attention和递归结构、卷积结构的优劣性,首先是每一层的计算复杂度,self-Attention layer用一个常量级别的顺序操作,将所有的positions连接起来,Recurrent Layer需要O(n)个顺序操作,其次是能够被并行的计算量,最后是网络中长期依赖的路径长度。对比显示,self-attention表现最好。

训练
训练数据使用WMT English-German数据集,包含450w对语句。句子都被编码过了,使用了一个大小约37000个token的字典。样本被分为若干个batch,每个batch大概25000个token,每个batch中的句子长度保持基本一致。硬件上使用了8块GPU。Optimizer使用了Adam。过拟合方面使用了dropout和Label Smoothing。
Hardware and Schedule(硬件和时间)
本文模型训练在一台具有8个 NVIDIA P100 gpu的机器上训练我们的模型。对于paper中描述的使用超参数的基础模型,每个训练步骤大约需要0.4秒。对基础模型进行了总共100000步或12小时的训练。
Optimizer(优化器)
我们使用Adam优化器,其中β1=0.9, β2=0.98及ϵ=10-9。我们根据以下公式在训练过程中改变学习率:
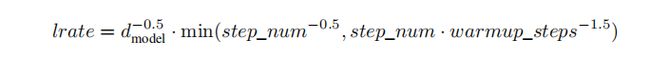
Regularization(正则化,本文使用三种)
Residual Dropout 我们在对每个子层的输出上执行dropout操作,这个操作在additive操作(子层的输出加上子层的输入)和 normalized操作之前。此外,在编码器和解码器堆栈中,我们将丢弃应用到嵌入和位置编码的和。对于基础模型,我们使用Pdrop=0.1丢弃率。
结果
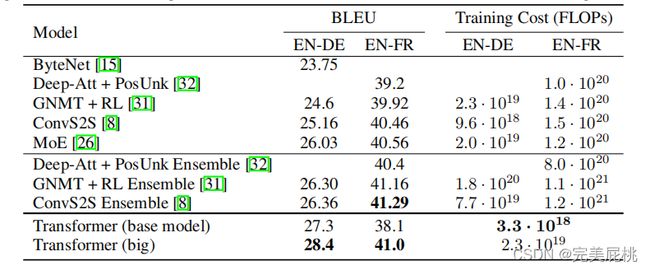
不论是英语-德语还是英语-法语的翻译任务,对比之前的一些模型,本文提出的模型都达到更好的BELU值,同时Training Cost也最低
4 论文总结
总结
总的来说,本文提出的模型十分成功。本文中提出的Transformer模型抛弃了传统的CNN和RNN进行机器翻译的架构,整个网络结构完全是由Attention机制组成。更准确地讲,Transformer由且仅由self-Attenion和Feed Forward Neural Network组成。一个基于Transformer的可训练的神经网络可以通过堆叠Transformer的形式进行搭建,作者的实验是通过搭建编码器和解码器各6层,总共12层的Encoder-Decoder,并在机器翻译中取得了BLEU值得新高,而且从模型的图片来看,该模型很可能是在尝试“理解”句子。
作者采用Attention机制的原因是考虑到RNN(或者LSTM,GRU等)的计算限制为是顺序的,也就是说RNN相关算法只能从左向右依次计算或者从右向左依次计算。作者提出的模型十分创新,并在近几年来应用广泛,算法设计十分精彩,我认为其是NLP领域的里程碑式的模型之一。
不足
作者提出的模型十分创新,但我觉得虽然该模型可能一步到位的捕捉到了全局特征关系,但或许在捕捉局部特征方面有待改进,且该论文中仅在特征向量中加入Position Embedding去表征文章位置信息并不能表示位置信息在NLP技巧翻译任务中的重要性。
改进
可以尝试将Transformer与CNN和RNN相结合的网络结构实现一个新的模型,或许会有更好的效果。