从0开始python学习-40.通过正则表达式/json进行接口关联
目录
1. 正则表达式:使用re库(需安装-pip install re),只能提取字符串的数据。
1.1 re.seach:提取一个值,得到的是一个对象,通过下标group(1)取值,如果没有匹配到值则返回None
1.2 re.findall:提取多个值,得到的是一个列表,通过下标【0】取值,如果没有匹配到值则返回一个空列表
2. Jsonpath表达式:jsonpath
2.1 jsonpath.jsonpath() 提取多个值,得到的是一个列表,通过下标【0】取值,如果没有匹配到值则返回None
2.2 语法规则
响应数据示例
{
"code": 200,
"messages": "ok",
"data": [
{
"name": "宋瑶",
"time": "2020-09-30 18:58:33",
"relation": {
"mobile": "15811111111",
"CardType": "身份证"
}
}
]
}1. 正则表达式:使用re库(需安装-pip install re),只能提取字符串的数据。
1.1 re.seach:提取一个值,得到的是一个对象,通过下标group(1)取值,如果没有匹配到值则返回None
url = 'http://192.168.1.1:8088/list'
data = {"name":"张三","age":18}
res = requests.get(url=url, data=data)
print(res.text)
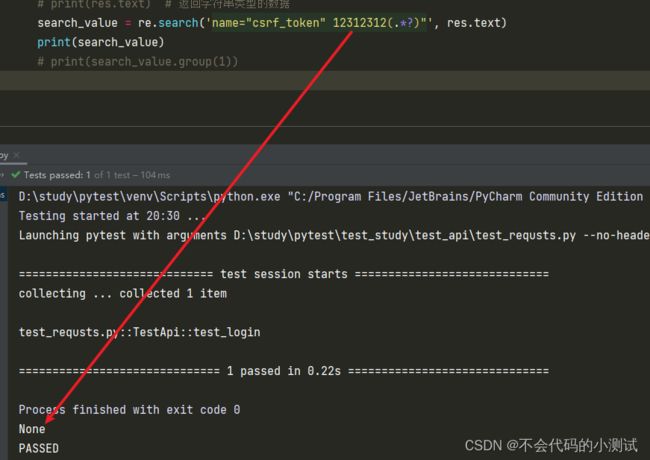
search_value = re.search('name="csrf_token" value="(.*?)"', res.text)
print("\n"+search_value.group(1))正常提取到的情况
.*? 表示匹配任意字符到下一个符合条件的字符
.group(1) 列出第一个括号匹配的部分,适用于有多个括号的情况
 .group(2) 则可以将第二个匹配的部分提取出来
.group(2) 则可以将第二个匹配的部分提取出来
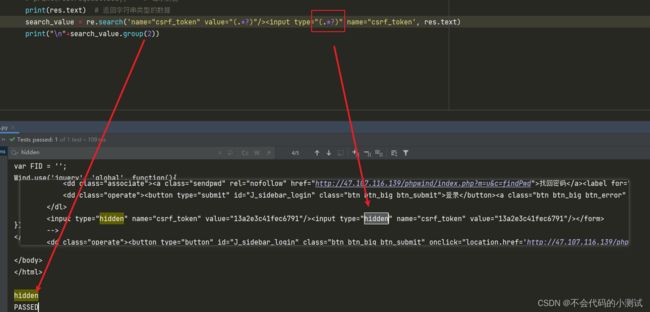
无法提取到的情况,若使用search_value.group(1)则会报错AttributeError,因为并没有提取到任何数据
1.2 re.findall:提取多个值,得到的是一个列表,通过下标【0】取值,如果没有匹配到值则返回一个空列表
url = 'http://192.168.1.1:8088/list'
data = {"name":"张三","age":18}
res = requests.get(url=url, data=data)
print(res.text)findall_value = re.findall('name="csrf_token" value="(.*?)"', res.text)
print(findall_value[0])正常提取到情况,提取出角标为0的值
 使用角标的形式提取,若角标值大于了可匹配到的数据总数,则会出现角标越界的情况IndexError
使用角标的形式提取,若角标值大于了可匹配到的数据总数,则会出现角标越界的情况IndexError
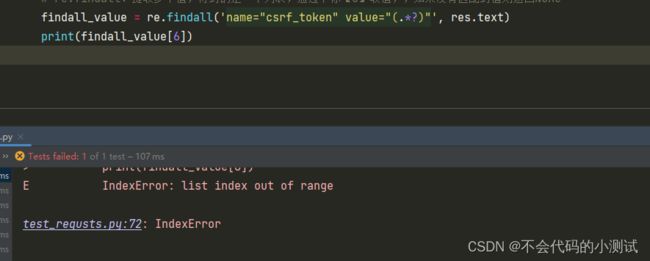
获取不到时返回空列表

2. Jsonpath表达式:jsonpath
2.1 jsonpath.jsonpath() 提取多个值,得到的是一个列表,通过下标【0】取值,如果没有匹配到值则返回None
import requests
import json
url = "http://test/project/list"
payload = json.dumps({
"pageNo": 0,
"pageSize": 5,
"queryDto": {
"projectName": "测试"
}
})
headers = {
'authInfo': '%7B%22user%22',
'Content-Type': 'application/json'
}
response = requests.post(url, headers=headers, data=payload)
print(response.text)打印结果为:
{
"code": "0",
"action": "/project/list",
"msg": "succeeded",
"data": {
"pageNo": 0,
"pageSize": 5,
"totalRecords": 1,
"data": [{
"id": "1310935793613242370",
"projectName": "测试"
}]
},
"timestamp": "2024-01-03 21:33:38",
"ok": true
}2.2 语法规则
(1) $ 根节点
(2) $.取子节点
j = jsonpath.jsonpath(response.json(),'$.code')
print(j) 
(3) 取列表中的值:$.上级[角标] .key
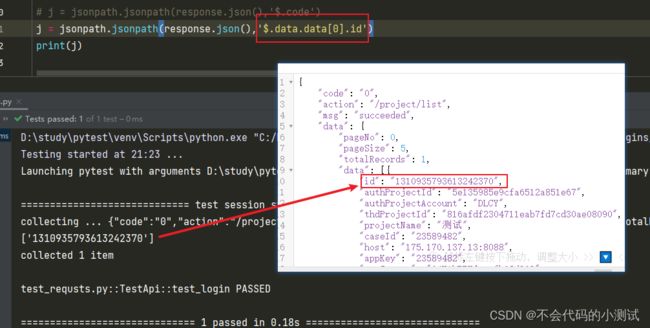
j = jsonpath.jsonpath(response.json(),'$.data.data[0].id')
print(j)表示提取第一层级为data,下一级也是data的列表中的第一组数据中的id的value值。这里可以通过id反写层级
 (4) $..递归取值:会把所有data的value都取出来,以列表形式显示
(4) $..递归取值:会把所有data的value都取出来,以列表形式显示
j = jsonpath.jsonpath(response.json(),'$..data')
print(j)结果:
