8.云原生存储之Ceph集群
1. 私有云实战之基础环境搭建
2. 云原生实战之kubesphere搭建
3.云原生之kubesphere运维
4. 云原生之kubesphere基础服务搭建
5.云原生安全之kubesphere应用网关配置域名TLS证书
6.云原生之DevOps和CICD
7.云原生之jenkins集成SonarQube
8.云原生存储之Ceph集群
文章目录
- 为什么要用Ceph?
-
- glusterfs、ceph、nfs对比
- 使用阿里云nas作为日志存储,多个服务写nas出现日志丢失和混乱
- k8s将数据文件挂载到nas可能会出现的问题
- k8s将数据文件挂载到nas并发写问题
- Ceph 并发写问题(存在瓶颈)
- 部署前准备
-
- os与ceph版本
- rook与ceph版本
- ceph与kubenetes版本
- ceph磁盘要求
- 境外镜像拉取处理
-
- 方式1:部署镜像代理服务
- 方式2:导入离线docker镜像
- 使用Rook安装Ceph集群(常规)
-
- 部署Admission Controller
- 部署RooK Operator
- 修改cluster.yaml文件
- 创建ceph集群
- Ceph toolbox 命令行工具
- 暴露dashboard
- helm安装ceph集群
- 删除ceph集群(重要)
-
- 常规部署ceph情况
- helm部署ceph情况
-
- 删除Terminating状态命名空间
- cephcluster无法删除
- ConfigMap和Secret删除不了处理
- 通用删除ceph集群方式
Ceph官网文档
为什么要用Ceph?
简单总结:使用nfs作为nas存在并发写和数据一致性问题,ceph提供并发写支持
glusterfs、ceph、nfs对比
| 特性 | GlusterFS | Ceph | NFS |
|---|---|---|---|
| 架构 | 分布式文件系统 | 对象存储 | 客户端-服务器模型 |
| 数据一致性 | 强一致性和弱一致性可配置 | 副本和一致性协议 | 强一致性 |
| 可扩展性 | 良好的横向扩展性 | 高度可扩展性 | 有限的扩展性 |
| 性能 | 适用于大文件和顺序访问 | 适用于并发写入和随机访问 | 受限于网络和服务器性能 |
| 管理复杂性 | 相对简单 | 相对复杂 | 相对简单 |
GlusterFS、Ceph和NFS(Network File System)都是分布式存储系统,但它们在架构、功能和适用场景上有所不同。下面是对它们进行比较的一些关键方面:
- 架构:
- GlusterFS:采用分布式文件系统的方式,将数据分布在多个存储节点上,通过集中式管理器(glusterd)来管理和协调数据访问。
- Ceph:采用对象存储的方式,将数据分片并分布在多个存储节点上,通过 CRUSH 算法计算数据位置,并使用 OSD 处理数据存储和访问。
- NFS:基于客户端-服务器模型,客户端通过网络挂载远程存储服务器上的文件系统,使用标准的文件系统接口进行数据访问。
- 数据一致性:
- GlusterFS:提供强一致性和弱一致性两种模式,可以根据需求进行配置。
- Ceph:通过副本和一致性协议来保证数据的一致性和可靠性。
- NFS:提供强一致性,客户端对文件的修改会立即反映到服务器上。
- 可扩展性:
- GlusterFS:具有良好的横向扩展性,可以通过添加存储节点来扩展存储容量和性能。
- Ceph:具有高度可扩展性,可以通过添加 OSD 和存储节点来扩展存储容量和吞吐量。
- NFS:不太适合大规模存储集群,扩展性有限。
- 性能:
- GlusterFS:适用于大文件和顺序访问,对小文件和随机访问的性能可能较差。
- Ceph:具有较好的性能,尤其在并发写入和随机访问方面表现出色。
- NFS:性能受限于网络和服务器的性能,对小文件和随机访问的性能可能较差。
- 管理和配置复杂性:
- GlusterFS:相对较简单,使用命令行工具或图形界面进行管理和配置。
- Ceph:相对复杂,需要配置 CRUSH 算法、数据分片策略等,但提供了更高级的管理和配置选项。
- NFS:相对简单,采用标准的文件系统接口,易于管理和配置。
综合来说,GlusterFS适用于大文件和顺序访问,易于部署和管理;Ceph适用于大规模存储集群,具有高度可扩展性和并发写入能力;NFS适用于简单的文件共享和标准文件系统访问。选择哪个系统取决于具体的需求、数据访问模式和规模。
使用阿里云nas作为日志存储,多个服务写nas出现日志丢失和混乱
使用阿里云 NAS(Network Attached Storage)作为日志存储时,多个服务同时写入 NAS 可能会导致日志丢失和混乱的问题。这是因为 NAS 是一个共享存储设备,多个服务同时写入同一个文件可能会引发以下问题:
- 写冲突:多个服务同时写入同一个文件可能导致写冲突,其中一个服务的写入可能会覆盖其他服务的写入内容,导致日志丢失或混乱。
- 文件锁定:某个服务正在写入文件时,其他服务可能无法同时写入,需要等待文件解锁。这可能会导致服务之间的延迟和性能问题。
为了避免这些问题,可以考虑以下解决方案:
- 使用分离的日志文件:每个服务使用独立的日志文件,避免多个服务写入同一个文件。这样可以降低写冲突的风险。
- 使用日志收集工具:将每个服务的日志发送到一个中央日志收集工具,如 Elasticsearch、Fluentd、Logstash 等。这样每个服务可以独立写入自己的日志文件,而中央日志收集工具负责收集和聚合所有日志,并存储到 NAS 或其他存储后端。
- 使用分布式日志系统:使用分布式日志系统如 Apache Kafka、RabbitMQ 等,每个服务将日志写入消息队列中,然后由消费者服务将日志写入 NAS 或其他存储后端。这样可以实现解耦和水平扩展。
无论选择哪种解决方案,都应该注意日志的并发写入和文件锁定问题,以确保日志的完整性和一致性。此外,还应该考虑日志文件的大小和定期归档,以避免单个文件过大导致的性能问题。
k8s将数据文件挂载到nas可能会出现的问题
将数据文件挂载到 Kubernetes 中的 NAS 存储时,可能会遇到以下问题:
- 性能问题:NAS 存储通常与节点通过网络连接,相对于本地存储,它的性能可能会较低。这可能会影响应用程序的读写性能和响应时间。因此,在将数据文件挂载到 NAS 上时,需要评估 NAS 存储的性能是否满足应用程序的需求。
- 网络稳定性:由于 NAS 存储是通过网络连接的,因此网络的稳定性和延迟可能会对数据访问产生影响。如果网络连接不稳定或延迟较高,可能会导致应用程序对数据的读写操作变慢或超时。
- 并发访问:如果多个 Pod 或节点同时访问 NAS 存储上的同一数据文件,可能会导致并发访问冲突。这可能会引发数据一致性问题或导致文件损坏。在设计应用程序时,需要考虑并发访问的情况,并采取适当的并发控制措施,如使用文件锁定机制或设计合适的数据访问模式。
- 数据保护和备份:NAS 存储通常需要进行数据保护和备份,以防止数据丢失。确保定期备份数据,并采取适当的容灾措施,如使用 RAID 或者跨区域备份,以保护数据免受硬件故障或其他意外事件的影响。
在使用 NAS 存储时,建议进行充分的测试和评估,确保它能满足应用程序的性能、可靠性和数据一致性要求。同时,还可以考虑其他存储选项,如分布式存储系统(如 Ceph、GlusterFS)或云原生存储解决方案(如云提供商的对象存储服务),根据具体需求选择最适合的存储方案。
k8s将数据文件挂载到nas并发写问题
将数据文件挂载到 Kubernetes 中的 NAS 存储时,如果多个 Pod 并发写入同一个文件,可能会出现并发写问题。这种情况下,可能会发生以下问题:
- 写冲突:多个 Pod 同时写入同一个文件时,写冲突可能会导致数据损坏或丢失。如果多个写操作同时发生,可能会导致文件内容混乱,其中一个写入的内容可能会覆盖其他写入的内容。
- 文件锁定:当一个 Pod 正在写入文件时,其他 Pod 可能无法同时写入,需要等待文件解锁。这可能会导致其他 Pod 的写入延迟和性能下降。
为了避免并发写问题,可以考虑以下解决方案:
- 使用独立的文件:每个 Pod 使用独立的文件进行写入,避免多个 Pod 写入同一个文件。这样可以降低写冲突的风险。
- 使用文件锁定机制:在访问共享文件时,可以使用文件锁定机制,如 POSIX 文件锁定或分布式锁,以确保只有一个 Pod 可以写入文件。其他 Pod 在写入之前需要等待锁定的释放。
- 使用分布式文件系统:考虑使用分布式文件系统,如 Ceph、GlusterFS 等,这些系统可以提供并发写入的支持,并确保数据一致性。
- 使用分布式日志系统:如果是写入日志文件,可以考虑使用分布式日志系统,如 Elasticsearch、Fluentd、Logstash 等,这些系统可以提供并发写入和聚合日志的功能。
无论选择哪种解决方案,都需要根据实际需求和负载特性进行评估和测试,以确保数据的完整性和一致性,并避免并发写问题导致的数据损坏或丢失。
Ceph 并发写问题(存在瓶颈)
Ceph 的并发写入能力是其设计的一个关键特性,但在实际应用中,也可能会面临一些与并发写入相关的问题。以下是一些可能出现的问题和相应的解决方法:
- 写入冲突:当多个客户端同时写入相同的对象时,可能会发生写入冲突。这可能导致数据不一致或丢失。
解决方法:可以使用一致性协议(如分布式锁)来保证对同一对象的并发写入的顺序。另外,可以使用版本控制或乐观并发控制机制来处理冲突,以确保数据的一致性。
- 性能瓶颈:并发写入可能会导致存储集群的性能瓶颈,特别是在写入密集型工作负载下。
解决方法:可以通过增加 OSD 的数量、调整 CRUSH 算法的配置、优化网络带宽和延迟等方式来提高存储集群的性能。另外,可以使用缓存、批处理写入等技术来减轻写入压力。
- 数据一致性和持久性:并发写入可能会导致数据一致性和持久性方面的挑战。如果写入操作没有正确完成或失败,可能会导致数据丢失或不一致。
解决方法:Ceph 提供了数据副本和故障恢复机制,可以通过配置适当数量的副本来提高数据的冗余和可靠性。此外,可以使用写入确认机制来确保写入操作的完成,并进行适当的错误处理和故障恢复。
- 网络和带宽限制:并发写入可能会对网络和带宽造成压力,特别是在跨多个节点的分布式存储集群中。
解决方法:可以通过增加网络带宽、优化网络拓扑、使用链路聚合技术等方式来缓解网络和带宽限制。另外,可以使用数据本地化和就近复制等策略来减少跨节点的写入操作。
需要根据具体的应用场景和需求来评估并解决并发写入问题。Ceph 提供了一系列的配置选项和优化策略,可以根据实际情况进行调整和优化,以提供更好的并发写入性能和数据一致性保证。
部署前准备
| 环境 | 版本 |
|---|---|
| 系统 | centos7.5 |
| k8s | v1.23.10 |
| docker | 20.10.8 |
| kubesphere | 3.3.2 |
| rook | v1.9.12 |
| ceph | v15.2.17 |
os与ceph版本
OS Recommendations — Ceph Documentation
- A:Ceph 提供了软件包,并对其中的软件进行了全面测试。
- B:Ceph 提供了软件包,并对其中的软件进行了基本测试。
- C:Ceph 仅提供软件包。尚未对这些版本进行任何测试。
centos7.x系统ceph版本最好选择Pacific(16.2.z)版本
rook与ceph版本
Ceph Upgrades - Rook Ceph Documentation 选择版本如下图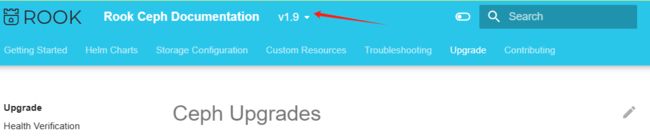




centos7.x系统ceph版本最好选择Pacific(16.2.z)版本,综上rook最好选择v1.9版本
ceph与kubenetes版本
| ceph版本 | k8s版本要求 |
|---|---|
| rook v1.12 | v1.22及以上 |
| rook v1.9 | v1.17及以上 |
ceph磁盘要求
- ceph磁盘要求
- 原始设备(没有分区或格式化的文件系统)
- 原始分区(没有格式化的文件系统)
- LVM逻辑卷(没有格式化的文件系统)
- 块模式存储类中可用的持久卷
- 查看当前磁盘并添加
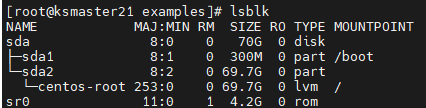

- 添加磁盘后查看

境外镜像拉取处理
由于容器镜像均无法正常访问,
- 推荐安装镜像代理服务,自动使用镜像代理服务拉取新创建的 Pod 中的外网容器镜像(仅限公有镜像)
- 推荐在能访问外网的机器上拉取docker镜像子在离线,该放弃要求较高,需在yaml找到docker镜像版本
方式1:部署镜像代理服务
- 安装 cert-manager
官方文档: Install cert-manager
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.13.2/cert-manager.yaml
# 代理地址
kubectl apply -f https://ghproxy.com/https://github.com/cert-manager/cert-manager/releases/download/v1.13.2/cert-manager.yaml
- 安装 registry-proxy
官方网站: https://ketches.cn/registry-proxy/
# 整个命令的作用是从 GitHub 仓库的最新发布版本的重定向 URL 中提取文件名,并将其赋值给名为 LATEST 的环境变量。这样,变量 LATEST 就包含了最新发布版本的文件名,可以在后续的脚本中使用
export LATEST=$(basename $(curl -s -w %{redirect_url} https://github.com/ketches/registry-proxy/releases/latest))
# 打印LATEST -- v1.0.0
echo $LATEST
kubectl apply -f https://raw.githubusercontent.com/ketches/registry-proxy/$LATEST/deploy/manifests.yaml
# 代理地址
kubectl apply -f https://ghproxy.com/https://raw.githubusercontent.com/ketches/registry-proxy/$LATEST/deploy/manifests.yaml
export逐步解释这个命令:
- curl -s -w %{redirect_url} https://github.com/ketches/registry-proxy/releases/latest:这部分命令使用 curl 命令从指定的 GitHub 仓库的 /releases/latest 页面获取重定向的 URL。-s 参数表示静默模式,不显示进度或错误信息,-w %{redirect_url} 参数表示输出重定向的 URL。
- basename:这个命令用于从给定的路径中提取文件名部分。
- $(…):这个语法用于执行命令,并将命令的输出结果作为变量的值。

- 配置
registry-proxy 安装后自动创建 ConfigMap registry-proxy-config,ConfigMap 内容为默认配置,可以通过修改 ConfigMap 来修改默认配置。默认配置如下:
apiVersion: v1
kind: ConfigMap
metadata:
name: registry-proxy-config
namespace: registry-proxy
data:
config.yaml: |
proxies:
docker.io: docker.ketches.cn
registry.k8s.io: k8s.ketches.cn
quay.io: quay.ketches.cn
ghcr.io: ghcr.ketches.cn
gcr.io: gcr.ketches.cn
k8s.gcr.io: k8s-gcr.ketches.cn
docker.cloudsmith.io: cloudsmith.ketches.cn
excludeNamespaces:
- kube-system
- kube-public
- kube-node-lease
includeNamespaces:
- *
- 默认使用 ketches/cloudflare-registry-proxy 镜像代理服务;
- 默认排除 kube-system、kube-public、kube-node-lease 命名空间下的 Pod 容器镜像代理;
- 修改上述配置实时生效,无需重启 registry-proxy;
- 可以自定义代理地址,例如:docker.io: docker.m.daocloud.io;
- 可以去除代理地址,免去代理;
- 可以增加代理地址,例如:mcr.microsoft.com: mcr.dockerproxy.com;
- 可以通过向 ketches/cloudflare-registry-proxy 项目 提交 Issue 来申请添加新的国外镜像代理服务
方式2:导入离线docker镜像
- 若不能访问外网,安装过程下载镜像会失败

- 可以在可以访问外网的机器上下载镜像,或者修改镜像源,以下是rook-v1.13.1版本
docker pull rook/ceph:v1.13.1
docker pull quay.io/cephcsi/cephcsi:v3.10.1
docker pull registry.k8s.io/sig-storage/csi-node-driver-registrar:v2.9.1
docker pull registry.k8s.io/sig-storage/csi-resizer:v1.9.2
docker pull registry.k8s.io/sig-storage/csi-provisioner:v3.6.2
docker pull registry.k8s.io/sig-storage/csi-snapshotter:v6.3.2
docker pull registry.k8s.io/sig-storage/csi-attacher:v4.4.2
docker pull quay.io/ceph/ceph:v18.2.1
docker save -o D:/rook-1.13.1.tar rook/ceph:v1.13.1 quay.io/cephcsi/cephcsi:v3.10.1 registry.k8s.io/sig-storage/csi-node-driver-registrar:v2.9.1 registry.k8s.io/sig-storage/csi-resizer:v1.9.2 registry.k8s.io/sig-storage/csi-provisioner:v3.6.2 registry.k8s.io/sig-storage/csi-snapshotter:v6.3.2 registry.k8s.io/sig-storage/csi-attacher:v4.4.2
- 将镜像打包成tar
docker save -o D:/RooKOperator.tar registry.k8s.io/sig-storage/csi-node-driver-registrar:v2.8.0 registry.k8s.io/sig-storage/csi-resizer:v1.8.0 registry.k8s.io/sig-storage/csi-provisioner:v3.5.0 registry.k8s.io/sig-storage/csi-snapshotter:v6.2.2 registry.k8s.io/sig-storage/csi-attacher:v4.3.0
docker save -o D:/storage-cephcsi.tar k8s.gcr.io/sig-storage/csi-provisioner:v3.0.0 k8s.gcr.io/sig-storage/csi-resizer:v1.3.0 k8s.gcr.io/sig-storage/csi-attacher:v3.3.0 k8s.gcr.io/sig-storage/csi-snapshotter:v4.2.0 k8s.gcr.io/sig-storage/csi-node-driver-registrar:v2.3.0 quay.io/cephcsi/cephcsi:v3.4.0
docker save -o D:/toolbox.tar quay.io/ceph/ceph:v18.2.1
docker save -o D:/ceph.tar registry.k8s.io/sig-storage/csi-node-driver-registrar:v2.8.0 registry.k8s.io/sig-storage/csi-resizer:v1.8.0 registry.k8s.io/sig-storage/csi-provisioner:v3.5.0 registry.k8s.io/sig-storage/csi-snapshotter:v6.2.2 registry.k8s.io/sig-storage/csi-attacher:v4.3.0 k8s.gcr.io/sig-storage/csi-provisioner:v3.0.0 k8s.gcr.io/sig-storage/csi-resizer:v1.3.0 k8s.gcr.io/sig-storage/csi-attacher:v3.3.0 k8s.gcr.io/sig-storage/csi-snapshotter:v4.2.0 k8s.gcr.io/sig-storage/csi-node-driver-registrar:v2.3.0 quay.io/cephcsi/cephcsi:v3.4.0 quay.io/ceph/ceph:v18.2.1
# 删除镜像
docker rmi registry.k8s.io/sig-storage/csi-node-driver-registrar:v2.8.0 registry.k8s.io/sig-storage/csi-resizer:v1.8.0 registry.k8s.io/sig-storage/csi-provisioner:v3.5.0 registry.k8s.io/sig-storage/csi-snapshotter:v6.2.2 registry.k8s.io/sig-storage/csi-attacher:v4.3.0 k8s.gcr.io/sig-storage/csi-provisioner:v3.0.0 k8s.gcr.io/sig-storage/csi-resizer:v1.3.0 k8s.gcr.io/sig-storage/csi-attacher:v3.3.0 k8s.gcr.io/sig-storage/csi-snapshotter:v4.2.0 k8s.gcr.io/sig-storage/csi-node-driver-registrar:v2.3.0 quay.io/cephcsi/cephcsi:v3.4.0 quay.io/ceph/ceph:v18.2.1
- 将tar上传到服务器,执行如下命令导入镜像:
小编已经准备好离线安装包RooKOperator.tar,storage-cephcsi.tar
docker load -i ceph.tar
- 将tar拷贝到其他机器脚本
#!/bin/bash
# 定义要传输的文件和目标路径
file_to_transfer="./storage-cephcsi.tar"
destination_path="/opt"
# 定义远程主机列表
remote_hosts=(
"[email protected]"
"[email protected]"
"[email protected]"
"[email protected]"
"[email protected]"
"[email protected]"
"[email protected]"
)
# 循环遍历远程主机列表,并执行文件传输
for remote_host in "${remote_hosts[@]}"; do
echo "Transferring file to ${remote_host}..."
scp "${file_to_transfer}" "${remote_host}:${destination_path}"
done
使用Rook安装Ceph集群(常规)
部署Admission Controller
启用Rook准入控制器,以确保使用自定义资源(CR)设置正确配置了Rook。
cert-manager.yaml
kubectl apply -f https://github.com/jetstack/cert-manager/releases/download/v1.7.1/cert-manager.yaml
部署RooK Operator
用 Helm 托管安装 Ceph 集群并提供后端存储 · Kubernetes 中文指南——云原生应用架构实战手册
- 修改operator.yaml
还是operator文件,新版本rook默认关闭了自动发现容器的部署,如果没有指定osd节点的位置,这层配置一定要打开,来让自动发现容器帮助我们去发现设备上的块设备,可以找到ROOK_ENABLE_DISCOVERY_DAEMON改成true即可
- 下载rook源码:https://github.com/rook/rook,部署RooK Operator
# 进入源码/deploy/examples目录
kubectl apply -f crds.yaml -f common.yaml -f operator.yaml
# 删除部署
kubectl delete -f crds.yaml -f common.yaml -f operator.yaml
# 查看rook Operator是否running
kubectl get pods -n rook-ceph
- 部署完成内容如下


修改cluster.yaml文件
Linux 命令大全 | 菜鸟教程
- 查看k8s node
kubectl get node -o wide

- 放开注释,表明可以在k8s集群之外使用ceph集群
provider: host
- 设置ceph集群节点和磁盘
# 修改ceph镜像版本关闭更新检查
cephClusterSpec:
cephVersion:
image: quay.io/ceph/ceph:v18.2.1
# 关闭更新检查
cephClusterSpec:
skipUpgradeChecks: true
# dashboard关闭ssl
dashboard:
enabled: true
port: 8443
ssl: false
# 选择自定义挂载卷
storage: # cluster level storage configuration and selection
useAllNodes: false
useAllDevices: false
nodes:
- name: "ksnode20"
devices:
- name: "sdb"
- name: "ksnode24"
devices:
- name: "sdb"
- name: "ksnode25"
devices:
- name: "sdb"
- name: "ksnode26"
devices:
- name: "sdb"
- name: "ksnode27"
devices:
- name: "sdb"
其中nodes下name只能填hostname,不能填写ip地址
device下name为磁盘盘符,新版必须采用裸盘,即未格式化的磁盘。建议最少三个节点,否则后面的试验可能会出现问题
创建ceph集群
- 创建ceph集群
# 创建ceph集群
kubectl create -f cluster.yaml
# 删除
kubectl delete -f cluster.yaml
# 查看Ceph部署情况
kubectl describe node <节点名称>
# 查看Ceph部署情况
kubectl get pods -n rook-ceph
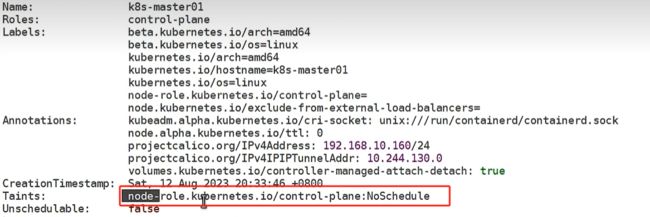
出现该现象则是存在污点
- 若cluster.yaml中配置使用到master节点磁盘,则将master污点取消
master节点存在污点,是不允许调度的。取消污点:![]()
或者删除 node-role.kubernetes.io/master

- 查看部署情况
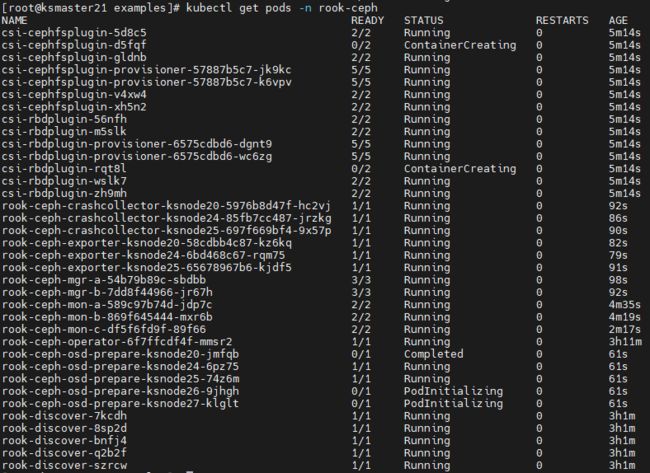
登录kubesphere控制台查看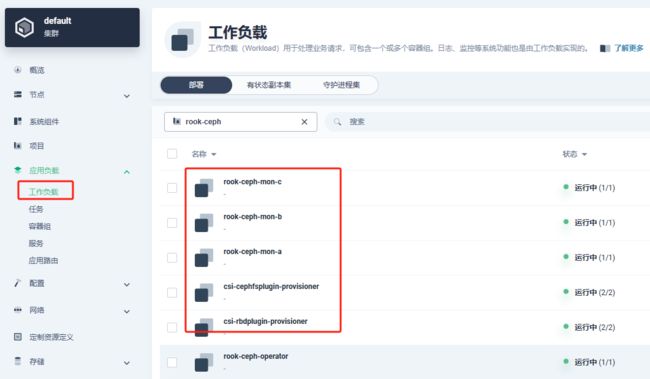
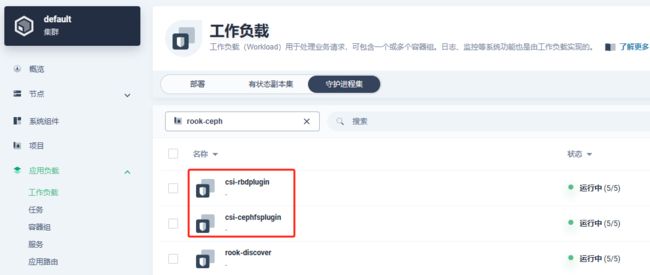
Ceph toolbox 命令行工具
- 部署toolbox
# 部署toolbox
kubectl create -f toolbox.yaml -n rook-ceph
# 删除toolbox
kubectl delete -f toolbox.yaml -n rook-ceph
# 查看toolbox部署情况
kubectl get po -n rook-ceph -l app=rook-ceph-tools
- 验证ceph集群状态
# 进入toolbox容器内部
kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- bash
bash-4.4$ ceph osd status
ID HOST USED AVAIL WR OPS WR DATA RD OPS RD DATA STATE
0 ksnode25 26.3M 499G 0 0 0 0 exists,up
1 ksnode24 26.8M 499G 0 0 0 0 exists,up
2 ksnode26 26.8M 499G 0 0 0 0 exists,up
3 ksnode27 26.8M 499G 0 0 0 0 exists,up
# 查看ceph磁盘情况
bash-4.4$ ceph df
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 2.0 TiB 2.0 TiB 107 MiB 107 MiB 0
TOTAL 2.0 TiB 2.0 TiB 107 MiB 107 MiB 0
--- POOLS ---
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
.mgr 1 1 449 KiB 2 1.3 MiB 0 633 GiB

暴露dashboard
- 查看内部访问方式
# 查看mgr service
kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- bash
bash-4.4$ ceph mgr services
{
"dashboard": "https://192.168.31.24:8443/",
"prometheus": "http://192.168.31.24:9283/"
}
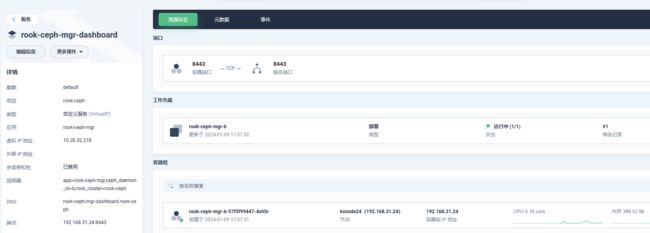
- 内部访问测试

- nodeport方式暴露
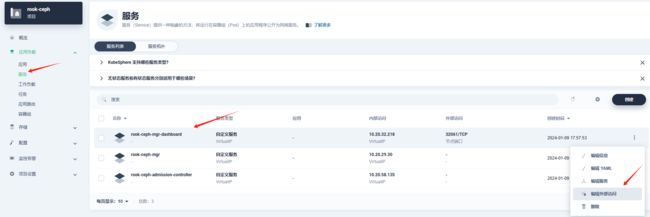
- 获取ceph dashboard访问密码
用户名admin 密码获取使用如下命令:
kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath="{['data']['password']}" | base64 --decode && echo
登录ceph控制台
- rook-ceph-mgr-dashboard服务端口漂移问题
有的版本存在端口漂移问题,测试1.9.12无该问题,1.13.1存在该问题
kubectl get svc rook-ceph-mgr-dashboard -n rook-ceph


发现容器端口漂移从8443漂移到7000,等一会服务nodePort端口会重置关闭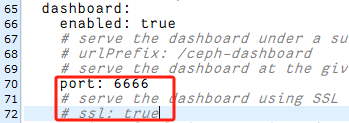
修改port,重新部署
helm安装ceph集群
参考:k8s部署rook-ceph记录_k8s安装rook-ceph1.10
- 先安装rook-operator , 运行正常后安装rook-cluster
- 添加应用仓库:https://charts.rook.io/release

- 从应用仓库中安装ceph
- 修改vlues.yml该配置参考cluster.yaml配置文件,主要修改内容如下:
# 修改ceph镜像版本关闭更新检查
cephClusterSpec:
cephVersion:
image: quay.io/ceph/ceph:v18.2.1
# 关闭更新检查
cephClusterSpec:
skipUpgradeChecks: true
# dashboard关闭ssl
dashboard:
enabled: true
port: 8443
ssl: false
# 选择自定义挂载卷
storage: # cluster level storage configuration and selection
useAllNodes: false
useAllDevices: false
nodes:
- name: "node180"
devices: # specific devices to use for storage can be specified for each node
- name: "sdc"
- name: "node181"
devices:
- name: "sdc"
- name: "node182"
devices:
- name: "sdc"
- 开启其他功能(可选)Ceph Docs
删除ceph集群(重要)
在搭建过程存在反复搭建删除的情况,删除集群存在很多坑,这儿小编特别说明,删除小编参考kubernetes上的分布式存储集群搭建(Rook/ceph)
常规部署ceph情况
- 常规部署ceph情况,执行下述命令即可删除
kubectl delete -f cluster.yaml
kubectl delete -f crds.yaml -f common.yaml -f operator.yaml
helm部署ceph情况
小编通过下述命令先部署了operator
kubectl apply -f crds.yaml -f common.yaml -f operator.yaml
小编在kubesphere应用仓库部署了
上诉在应用仓库部署ceph相当于
kubectl create -f cluster.yaml
部署过程没有问题,当小编想删除ceph时
- 小编直接在应用删除了ceph应用
该操作不等价kubectl delete -f cluster.yaml ,资源没有被删除,此时小编直接在kubesphere控制台删除了rook-ceph项目,出现现象rook-ceph命名空间一直处于Terminating,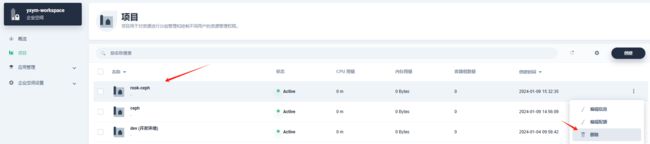
rook-ceph命名空间删除后,该空间下的ConfigMap资源rook-ceph-mon-endpoints和Secret资源rook-ceph-mon删除不了
删除Terminating状态命名空间
- 查看命名空间下是否还存在资源没删除干净
kubectl api-resources -o name --verbs=list --namespaced | xargs -n 1 kubectl get --show-kind --ignore-not-found -n <命名空间>
- 若存在着删除
kubectl api-resources -o name --verbs=list --namespaced | xargs -n 1 kubectl delete --ignore-not-found --all -n <命名空间>
- 强制删除命名空间
kubectl delete namespace <命名空间> --grace-period=0 --force
- 大多数情况下,命名空间下的资源无法强制删除,您可以使用原生接口进行删除
kubectl get ns <命名空间> -o json > <命名空间>.json
# 删除json文件下述内容:
"spec": {
"finalizers": [
"kubernetes"
]
},
- 开启代理接口
[root@ksmaster21 opt]# kubectl proxy
Starting to serve on 127.0.0.1:8001
- 调用接口删除namespace,注意修改要删除的<命名空间>
curl -k -H "Content-Type: application/json" -X PUT --data-binary @<命名空间>.json http://127.0.0.1:8001/api/v1/<命名空间>/rook-ceph/finalize
cephcluster无法删除
# 查看cephcluster
kubectl -n rook-ceph get cephcluster
# 查看资源
kubectl api-resources --namespaced=true -o name|xargs -n 1 kubectl get --show-kind --ignore-not-found -n rook-ceph
# 编辑资源,进行删除
kubectl edit cephcluster.ceph.rook.io -n rook-ceph
# 把finalizers的值删掉,cephcluster.ceph.rook.io便会自己删除
ConfigMap和Secret删除不了处理
当您尝试删除 Kubernetes 命名空间时,如果出现错误消息 “Some content in the namespace has finalizers remaining”,并且提到了特定的 finalizer(例如 ceph.rook.io/disaster-protection),这意味着该命名空间中的某些资源仍然具有未删除的 finalizer。
Finalizers 是 Kubernetes 中用于确保资源在删除过程中执行特定逻辑的机制。如果资源具有 finalizer,Kubernetes 将阻止删除该资源,直到 finalizer 的逻辑完成。
- 确定具有 finalizers 的资源:使用以下命令查找具有 finalizers 的资源
安装jq工具
sudo yum install epel-release
sudo yum install jq
# 确定具有 finalizers 的资源
kubectl get <resource-type> -n <namespace> -o json | jq '.items[] | select(.metadata.finalizers!=null) | .metadata.name'
将 替换为具有 finalizers 的资源类型(例如 Deployment、StatefulSet、Pod 等),将 替换为命名空间名称
![]()
- 删除 finalizers:对于每个具有 finalizers 的资源,您可以使用以下命令删除 finalizers
kubectl patch <resource-type> <resource-name> -n <namespace> -p '{"metadata":{"finalizers":[]}}' --type=merge
将 替换为具有 finalizers 的资源类型,将 替换为资源名称,将 替换为命名空间名称
通用删除ceph集群方式
- 删除Cephcluster CRD
kubectl -n rook-ceph delete cephcluster rook-ceph
# 确实是否删除
kubectl -n rook-ceph get cephcluster
- 删除Operator 和相关的资源
kubectl delete -f operator.yaml
kubectl delete -f common.yaml
kubectl delete -f crds.yaml
- 删除主机上的数据
rook创建cluster的时候会把部分数据卸载本机的/var/lib/rook(dataDirHostPath指定的目录)中,如果不删除会影响下次集群部署,rook据说下个版本会增加k8s 本地存储调用的功能,就不会直接存在硬盘上了
rm -rf /var/lib/rook
- 擦除硬盘上的数据
创建osd时被写入了数据,需要擦除,否则无法再次创建ceph集群,脚本中有各种硬盘的擦除命令,不需要全部执行成功,根据当前机器的硬盘情况确定。
安装依赖组件
sudo yum install gdisk
执行如下脚本:
#!/usr/bin/env bash
# 定义了一个变量 DISK,表示要进行清理的磁盘设备路径
DISK="/dev/sdb"
# 使用 sgdisk 命令对指定的磁盘设备进行全盘擦除,将磁盘分区表和分区信息清除
sgdisk --zap-all $DISK
# 使用 dd 命令将 /dev/zero 的内容写入指定的磁盘设备,以清除设备上的数据。bs=1M 指定每次写入的块大小为 1MB,count=100 指定写入 100 个块。oflag=direct,dsync 用于将数据直接写入设备并确保数据同步到物理设备上
dd if=/dev/zero of="$DISK" bs=1M count=100 oflag=direct,dsync
# 使用 blkdiscard 命令对指定的磁盘设备进行块丢弃操作,将设备上的数据块标记为可回收状态
blkdiscard $DISK
# 列出以 /dev/mapper/ceph- 开头的设备映射,并使用 dmsetup 命令逐个移除这些设备映射
ls /dev/mapper/ceph-* | xargs -I% -- dmsetup remove %
# 递归删除以 /dev/ceph- 开头的设备节点
rm -rf /dev/ceph-*
# 递归删除以 /dev/mapper/ceph-- 开头的设备映射节点
rm -rf /dev/mapper/ceph--*
这个脚本的目的是清理 Ceph 存储集群相关的设备和映射,以便重新配置或删除 Ceph 存储集群。请注意,运行此脚本将会清除指定磁盘上的数据,因此在运行之前,请确保您已经备份了重要的数据,并且明确了脚本中 DISK 变量指定的磁盘设备是正确的。