深入理解 Hadoop (七)YARN资源管理和调度详解
资源调度解决方案探讨
Hadoop 最初是为批处理设计而生,对于资源管理和调度,仅仅支持 FIFO 的调度机制。随着 Hadoop 的发展和流行,单个 Hadoop 集群中的用户量 和 应用程序类型不断增加,适用于批处理场景的 FIFO 调度机制不能很好地利用集群资源,也不能够满足不同应用程序的服务质量要求,因此需要设计适用于多用户的资源调度器。
- HOD(Hadoop On Demand)调度器:将物理集群,虚拟成多个 Hadoop 集群。类似于 Flink On YARN : Session Cluster 模式
- 优点:完全隔离
- 缺点:运维难度高,负载均衡引起的资源利用率不高,不能实现数据本地性计算特性
- YARN 调度器:支持多队列多用户
- 优点:一个集群只有一套资源管理系统,内部运行的每个 Application 都能使用到集群任何节点上的资源,简而言之,将资源划分成多个队列实现资源隔离,但是每个队列都是横跨整个集群的。
YARN 调度器将整个 Hadoop 集群逻辑上划分成若干个拥有相对独立资源的子集群,而由于这些子集群实际上是公用大集群中的资源,因此可以共享资源,相对于 HOD 而言,提高了资源利用率且降低了运维成本。
- 优点:一个集群只有一套资源管理系统,内部运行的每个 Application 都能使用到集群任何节点上的资源,简而言之,将资源划分成多个队列实现资源隔离,但是每个队列都是横跨整个集群的。
就 YARN 的整体调度来说,采用双层资源调度模型:
第一层:ResourceManager 中的资源调度器将资源分配给各个 ApplicationMaster,由 YARN 决定。
第二层:ApplicationMaster 再进一步将资源分配给它内部的各个任务 Task,由用户应用程序 ApplicationMaster 决定。
由此可见,YARN 是一个统一的资源调度系统,只要满足 YARN 的调度规范的分布式应用程序,都可以运行在 YARN 中,调度规范:定义一个 ApplicatoinMaster,问 RM 申请资源,AM 自己来完成 Container 到 Task 的分配。
YARN 采用拉模型实现异步资源分配,资源调度器将资源分配给应用程序之后,暂存于缓冲区中,等待 ApplicationMaster 通过心跳来进行获取。大概流程如下:
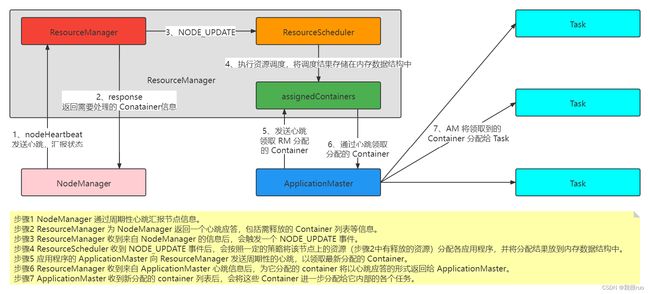
YARN 资源管理
Hadoop-2.x 版本中的 YARN 在 MRv1 基础之上提供了三种可用资源调度器,分别是:
- FIFO(First In First Out)
- Yahoo! 的 CapacityScheduler(Hadoop 3.x 中的默认调度策略)
- Facebook 的 FairScheduler
YARN 队列管理机制由用户权限管理和系统资源管理两部分组成:
- 用户权限管理:管理员可配置每个叶子队列对应的操作系统用户和用户组,也可以配置每个队列的管理员,他可以杀死该队列中任何应用程序,改变任何应用程序的优先级等(操作系统的用户或者用户组 :队列 = n:n)队列管理员。
- 系统资源管理:YARN 资源管理和调度均由调度器完成,管理员可在调度器中设置每个队列的资源容量,每个用户可用资源量等信息,而调度器则按照这些资源约束对应用程序进行调度。
总结一下 YARN 的 CapacityScheduler 的一些核心特点:
- 容量保证:给每个队列,都可以设置一个最低资源使用保证占比,提交到队列内的所有 Application 按照提交时间和优先级来共享使用这些资源。
- 灵活性:如果一个队列的资源使用还没有达到上限,则可以暂时借用其他队列富余的资源使用。
- 多重租赁:支持多用户共享集群和多应用程序同时运行。
- 安全保证:每个队列可以指定使用它的用户。还可以指定队列管理员和系统管理员等。
- 资源配置动态更新:YARN 集群管理员可以调整 capacity-scheduler.xml 资源配置,然后动态刷新。动态刷新的时候,不能删除队列。
总之,两句话可以完全概括:
- YARN 的资源调度以层级队列(队列树)进行资源隔离划分,每个队列可以设置一定比例的资源使用最低保证。
- 同时,YARN 也可以给每个队列设置资源使用上限,队列中的每个用户也可以设置资源使用上限,目的就是为了防止资源滥用。当一个队列的资源资源出现富余时,可以暂时借给其他队列使用。设置资源使用上限,也是为了充分发挥资源利用率。
CapacityScheduler 的更多理解,可以查看官网:
https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/CapacityScheduler.html
YARN 资源保证机制
在分布式资源调度系统中,一般资源的分配保证机制有如下两种常见方案:
- 增量资源分配:当应用程序申请的资源暂时无法保证时,系统会为应用程序预留一个节点上的资源直到累计释放的空闲资源满足应用程序需求。
- 缺点:资源预留会导致资源浪费,降低集群资源利用率。
- 一次资源分配:当应用程序申请的资源暂时无法保证时,系统放弃当前资源直到出现一个节点剩余资源一次性满足应用程序需求。
- 缺点:应用程序可能永远等不到满足资源需求的节点出现导致饿死。
YARN 采用的是 增量资源分配,尽管这种机制会造成浪费,但不会出现饿死现象。正常情况,资源总会在有限时间范围内释放的。
YARN 资源分配算法
在 YARN 默认的资源分配算法实现是:DefaultResourceCalculator 资源计算器,只负责调度内存。其实还有另外一个资源计算器:DRF(主资源公平调度算法 Dominant Resource Fairness)。在 DRF 算法中,将所需份额(资源比例)最大的资源称为主资源,而 DRF 的基本设计思想则是将最大最小公平算法应用于主资源上,进而将多维资源调度问题转化为单资源调度问题。
实例:假设系统中共有9个CPU和18GB RAM,有两个用户(或者框架)分别运行了两种任务,需要的资源量分别为<1CPU,4GB>和<3CPU,1GB>。对于用户A,每个任务要消耗总CPU的1/9(份额)和总内存的2/9,因而A的主资源为内存;对于用户B,每个任务要消耗总CPU的1/3和总内存的1/18,因而B的主资源为CPU。DRF将最大化所有用户的主资源,具体分配过程如表6-1所示。最终,A获取的资源量为<3CPU,12GB>,可运行3个任务;而B获取的资源量为<6CPU,2GB>,可运行2个任务。
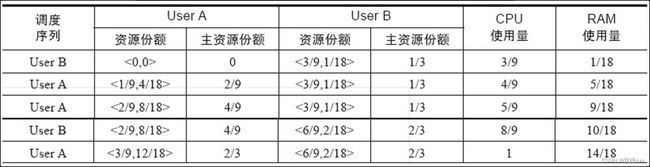
一句话理解:谁是主资源,就按照谁来进行分配。
资源抢占模型
在资源调度器中,每个队列可设置一个最小资源量和最大资源量。其中,最小资源量是资源紧缺情况下每个队列需保证的资源量,而最大资源量则是极端情况下队列也不能超过的资源使用量。
最小资源量 X = 最低资源使用保证 = 资源再紧缺,都会保证这个队列至少有这么多的资源可用
最大资源量 Y = 最多资源使用上限 = 资源能使用的再多,也不能超过这个值
通常而言,为了提高资源利用率,资源调度器会将负载较轻的队列的资源暂时分配给负载重的队列,仅当负载较轻队列突然收到新提交的应用程序时,调度器才进一步将本属于该队列的资源分配给它。但由于此时资源可能正被其他队列使用,因此调度器必须等待其他队列释放资源后,才能将这些资源“物归原主”,这通常需要一段不确定的等待时间。为了防止应用程序等待时间过长,调度器等待一段时间后若发现资源并未得到释放,则进行资源抢占。
Spark 中,有一个内存动态占用机制。有两种类型的内存:堆内内存,堆外内存,这两种的类型的内存都可以划分成两个逻辑区域:存储内存 + 执行内存。
- 在 Spark-1x 版本中,用的是 StaticMemoryManager 静态内存模型,存储内存 和 执行内存 的这个使用比例是写死的。
- 改进方案:spark-2.x 版本中,用的是 统一内存管理模型,默认比例是 1:1, 如果 A 用完了,B 还有资源可用,则 A 可以借用 B 的资源。
- 存储内存 A 占用了 执行内存 B 的话,执行内存可以要回来
- 执行内存 B 占用了 存储内存 A 的话,存储内存 A 要不回来
资源抢占,默认不启用,可以通过 yarn.resourcemanager.scheduler.monitor.enable 参数将其设置为 true 来启用。
资源抢占的工作,是由 SchedulingMonitor 来实现完成的。SchedulingMonitor 将周期性调用策略类(YARN 的默认实现是:ProportionalCapacityPreemptionPolicy )中的 editSchedule() 函数,以决定抢占哪些 Container 的资源,核心逻辑位于 containerBasedPreemptOrKill 方法中。
层级队列管理机制
YARN 最开始采用 平级 队列资源管理方式。新版本的 YARN 采用层级队列资源管理方式:
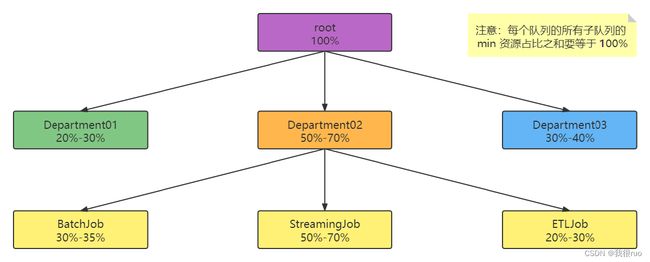
该队列组织方式具有以下特点:
- 子队列
- 队列可以嵌套,每个队列均可以包含子队列。
- 用户只能将应用程序提交到最底层的队列,即叶子队列。最少容量
- 最少容量
- 每个子队列均有一个“最少容量比”属性,表示可以使用父队列的容量的百分比。
- 调度器总是优先选择当前资源使用率最低的队列,并为之分配资源。
- 最少容量不是“总会保证的最低容量”,也就是说,如果一个队列的最少容量为 100,而该队列中所有队列仅使用了 20,那么剩下的 80 可能会分配给其他需要的队列。
- 最少容量的值为不小于 0 的数,但也不能大于 “最大容量”。
- 最大容量
- 为了防止一个队列超量使用资源,可以为队列设置一个最大容量,这是一个资源使用上限,任何时刻使用的资源总量都不能超过该值;
- 默认情况下队列的最大容量是无限大,这意味着,当一个队列只分配了 20% 的资源,所有其他队列没有应用程序时,该队列可能使用 100% 的资源,当其他队列有应用程序提交时,再逐步归还。(不建议使用)
CapacityScheduler 配置文件解析
CapacityScheduler 是 Yahoo! 开发的多用户调度器,它以队列为单位划分资源,每个队列可设定一定比例的资源最低保证和使用上限,同时,每个用户也可设定一定的资源使用上限以防止资源滥用。而当一个队列的资源有剩余时,可暂时将剩余资源共享给其他队列。
CapacityScheduler 配置文件 capacity-scheduler.xml 解读
capacity-scheduler.xml 常见的一些配置参数解释:
- 参数的固定搭配:A + B + C = A.B.C = value
- A = yarn.scheduler.capacity
- B = queue_path = root.hive.hive1
- C = 参数
- 具体的参数(C 的选项):
- 资源分配相关参数
- 队列 A 的参数 B 的配置名称为 yarn.scheduler.capacity.A.B,也就是说,所有的参数配置前缀都是 yarn.scheduler.capacity
- capacity:队列的资源容量(百分比)(yarn.scheduler.capacity.root.hive.hive1.capacity = 40)
- maximum-capacity:队列的资源使用上限(百分比)
- minimum-user-limit-percent:每个用户最低资源保障(百分比)
- user-limit-factor:每个用户最多可使用的资源量(百分比)
- 限制应用程序数目相关参数
- maximum-applications:集群或者队列中同时处于等待和运行状态的应用程序数目上限,超过该上限,后续的 App 将会被拒绝,默认值是 10000
- 集群的总数目上限:yarn.scheduler.capacity.maximum-applications = 10000
- 队列的总数目上限:yarn.scheduler.capacity..maximum-applications = X
- maximum-am-resource-percent:集群中用于运行应用程序 ApplicationMaster 的资源比例上限,默认是 0.1
- 集群的 ApplicationMaster 资源比例上限:yarn.scheduler.capacity.maximum-am-resource-percent = 0.1
- 队列的 ApplicationMaster 资源比例上限:yarn.scheduler.capacity..maximum-am-resource-percent = X
- 队列访问和权限控制参数
- state:队列状态,可以为 STOPPED 或者 RUNNING
- acl_submit_applications:限定哪些用户/ 用户组可向给定队列中提交应用程序
- acl_administer_queue:为队列指定一个管理员,该管理员可控制该队列的所有应用程序,比如杀死任意一个应用程序等。
- maximum-applications:集群或者队列中同时处于等待和运行状态的应用程序数目上限,超过该上限,后续的 App 将会被拒绝,默认值是 10000
- 资源分配相关参数
YARN 的配置参数可参考官网:https://hadoop.apache.org/docs/r3.3.1/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
当管理员需动态修改队列资源配置时,可修改配置文件 conf/capacity-scheduler.xml,然后运行 “yarn rmadmin -refreshQueues”,具体如下:
$ vi ${HADOOP_HOME}/etc/hadoop/capacity-scheduler.xml
$ ${HADOOP_YARN_HOME}/bin/yarn rmadmin –refreshQueues
ResourceScheduler 设计实现和功能详解
ResourceScheduler 顶层抽象设计
ResourceScheduler 是运行在 ResourceManager 中的用来做资源管理和调度的抽象实现。
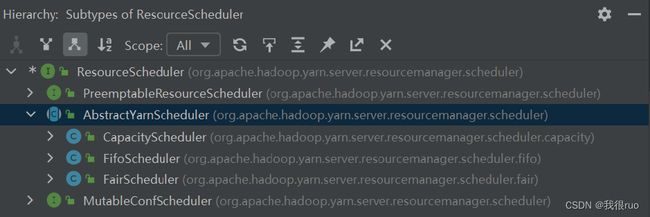
YARN 中的资源调度器是一种高可扩展式的可插拔设计(策略模式),用户可以按照接口规范编写一个新的资源调度器,这个接口就是:ResourceScheduler。
ResourceScheduler 功能实现详解
ResourceScheduler 初始化
ResourceScheduler 是 ResourceManager 中的众多子 Service 的其中之一,在 ResourceManager 启动的时候,会创建一个 ResourceScheduler 实现类对象,默认实现是:CapacityScheduler,注意:CapacityScheduler 是一个 Service 也是一个 EventHandler。
CapacityScheduler 构造器
CapacityScheduler serviceInit()
CapacityScheduler serviceStart()
接收 Application 并初始化
客户端通过 ApplicationClientProtocol 通信协议提交 Application 到 ResourceManager,然后交给 RMAppManager 去启动执行。RMAppManager 就是 RM 中专门用来管理 Application 的。RMAppManager 会为给 Application 生成一个 RMAppImpl 状态机,并且提交 SchedulerEventType. APP_ADDED 事件。 CapacityScheduler 收到该事件后,将为应用程序创建一个 FiCaSchedulerApp 对象跟踪和维护该应用程序的运行时信息,同时将应用程序提交到对应的叶子队列中,叶子队列会对应用程序进行一系列合法性检查。
- 检查提交 Application 的用户的权限
- 递归检查提交 Application 的队列及其父队列是 RUNNING 状态
- 检查当前队列是否达到 Application 数量上限
- 检查用户提交的 Application 数量是否达到上限
为 Application 做资源调度
当 ResourceManager 收到来自 NodeManager 发送的心跳信息( NM 通过心跳发送 RPC 请求 nodeHeartBeat() 给 RM 申请 Container)后,将向 CapacityScheduler 发送一个 SchedulerEventType. NODE_UPDATE 事件,CapacityScheduler 收到该事件后,会依次进行以下操作:
- 处理心跳:需要处理 NM 通过心跳汇报上来的 New Container 和 Completed Containers
- 资源分配:资源调度器收到资源申请后,将暂时将这些数据请求存放到一个数据结构中,以等待空闲资源出现后为其分配合适的资源:
- 第一步:选择 Queue
- 第二步:选择 Application
- 第三步:选择 Container
在整个过程中,还有一些细枝末节也可以多做做了解:
- CapacityScheduler 作为一个 EventHandler 其实会接收到多种类型的事件,比如 NodeManager 上线和下线,Container 超时,Application 被 Kill 等
- CapacityScheduler 有两种比较器用以比较两个资源的大小,分别是:DefaultResourceCalculator(内存) 和 DominantResourceCalculator(内存和CPU)
CapacityScheduler 源码解读
CapacityScheduler 采用了树型结构 + 深度优先遍历算法(通过有序迭代器来保证队列优先级)。
CapacityScheduler 是一个 EventHandler 也是一个 Service,更是一个 YarnScheduler。

所以我们需要关注它的四个方法:
- CapacityScheduler 的 构造 方法
- CapacityScheduler 的 serviceInit() 方法
- CapacityScheduler 的 serviceStart() 方法
- CapacityScheduler 的 handle() 方法
CapacityScheduler 对 Container 资源分配逻辑
用户提交应用程序后,应用程序对应的 ApplicationMaster 会为它申请资源,而资源的表示方式是 Container。Container 主要包含 5 类信息,分别是优先级、期望资源所在节点、资源量、Container 数目和是否松弛本地性。
资源调度器收到资源申请后,将暂时将这些请求存放到一个数据结构中,以等待空闲资源出现后为其分配合适的资源。
message ResourceRequestProto {
optional PriorityProto priority = 1; //优先级
optional string resource_name = 2; //期望资源所在的节点或者机架 ANY
optional ResourceProto capability = 3; //资源量
optional int32 num_containers = 4; //Container数目
optional bool relax_locality = 5 [default = true]; //是否松弛本地性
}
YARN 采用了三级资源分配策略,当一个节点上有空闲资源时,它会依次选择队列、应用程序和 container(请求)使用该资源。
- 第一步:选择队列
因为 YARN 采取了层级队列管理方式,这些队列结构就自然形成了树形结构。这样资源分配过程实际上就是基于优先级的多叉树遍历的过程,在选择队列时,YARN 采用了基于优先级(子队列资源使用率)的深度优先遍历方法。 - 第二步:选择 Application
在上一步确认了叶子队列之后,CapacityScheduler 按照 AppId 对叶子队列中的应用程序进行排序来分派 Container。 - 第三步:分派 Container
在上一步确认了 Application 之后,CapacityScheduler 将尝试优先满足优先级高的 Container,对于同一类优先级,优先选择满足本地性的 Container。依次选择 node local、rack local 和 no local 的 Container。
CapacityScheduler 和 FairScheduler 对比
FairScheduler 是 Facebook 开发的多用户调度器,同 CapacityScheduler 类似,它以队列为单位划分资源,每个队列可设定一定比例的资源最低保证和使用上限。同时,每个用户也可设定一定的资源使用上限以防止资源滥用;当一个队列的资源有剩余时,可暂时将剩余资源共享给其他队列。
- 资源公平共享。默认情况下,每个队列内部采用 Fair 策略分配资源。队列中的所有应用程序均分资源。
- 支持资源抢占。
- 支持负载均衡。
- 调度策略配置灵活。在每个队列中,FairScheduler 可选择按照 FIFO、Fair 或 DRF 策略为应用程序分配资源。管理员可以单独设置。
- 提高小应用程序响应时间。由于采用了最大最小公平算法,小作业可以快速获取资源并运行完成。
最大最小公平算法分配示意图
