matplotlib绘图过程存在大量的细节设置,以Boston_housing散点图绘制过程为例,通过逐步优化,理解绘图参数的设置逻辑。
第一版:实现一张散点图绘制
import tensorflow as tf
import matplotlib.pyplot as plt
(train_x, train_y),(test_x, test_y)=tf.keras.datasets.boston_housing.load_data(test_split=0) # 下载boston_housing数据,train_x为一个13列数据,train_y为一个1列数据,可以认为y是13列x的函数
plt.figure(figsize=(3,2)) #首先需要生成一张画布
plt.scatter(train_x[:,1],train_y) # 绘制散点图,使用train_x的第1列和train_y
plt.show() # 绘图后必须有此行才能显示出来
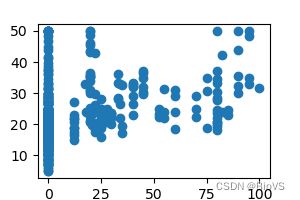
第二版:实现4×4散点图绘制
import tensorflow as tf
import matplotlib.pyplot as plt
(train_x, train_y),(test_x, test_y)=tf.keras.datasets.boston_housing.load_data(test_split=0)
plt.figure(figsize=(3,2))
break_marker = 0 # break只能跳出最深层循环,需设置一个标记,遇到标记后所有层都跳出
for i in range(4):
if break_marker == 1:
break
for j in range(4):
plt.subplot(4,4,i*4+j+1)
plt.scatter(train_x[:,i*4+j],train_y)
# 总共13张子图,因此双重for循环需要在执行完最后一张图绘制后结束循环
if i*4+j == 12:
break_marker = 1
break
plt.show()

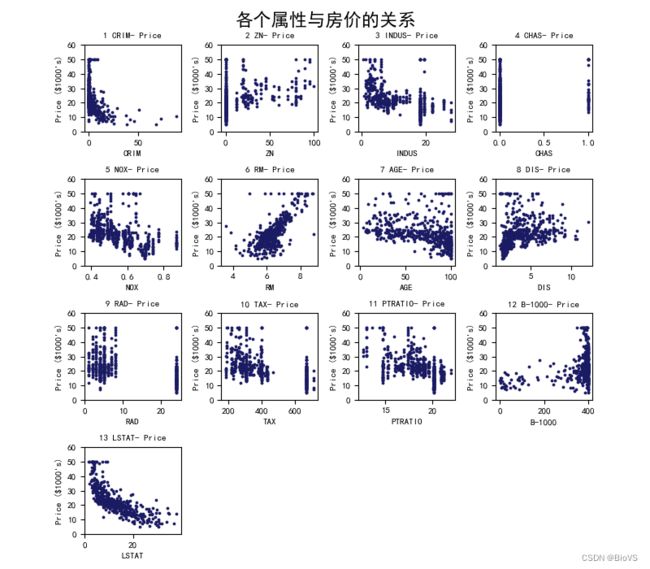
第三版:修改画布大小、marker大小,增加label和title
import tensorflow as tf
import matplotlib.pyplot as plt
(train_x, train_y),(test_x, test_y)=tf.keras.datasets.boston_housing.load_data(test_split=0)
plt.figure(figsize=(8,7))
break_marker = 0 # break只能跳出最深层循环,需设置一个标记,遇到标记后所有层都跳出
# print(train_x.shape)
xName = ['CRIM','ZN','INDUS','CHAS','NOX','RM','AGE','DIS','RAD','TAX','PTRATIO','B-1000','LSTAT','MEDV']
for i in range(4):
if break_marker == 1:
break
for j in range(4):
plt.subplot(4,4,i*4+j+1)
plt.scatter(train_x[:,i*4+j],train_y,color=(27/255,27/255,167/255),s=3)
plt.xlabel(xName[i*4+j])
plt.ylabel('Price ($1000\'s)')
title_list=str(i*4+j+1)+' '+xName[i*4+j]+'- Price'
plt.title(title_list)
if i*4+j == 12:
break_marker = 1
break
plt.suptitle('各个属性与房价的关系')
plt.show()
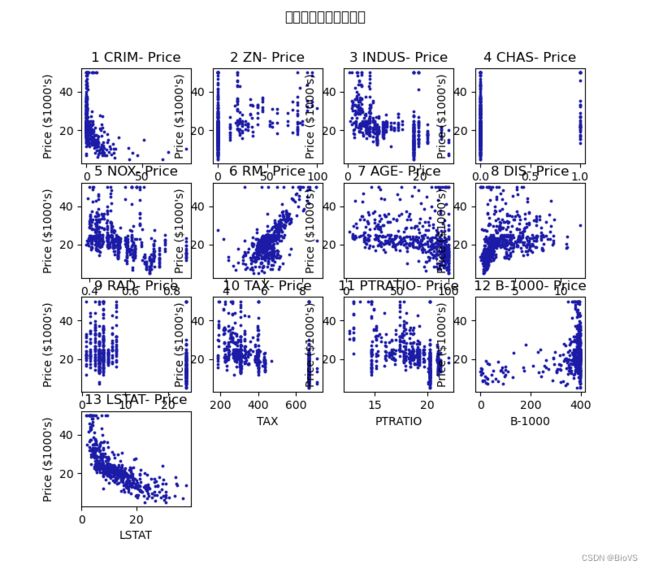
第四版: 设置中文和字大小,更新marker颜色
import tensorflow as tf
import matplotlib.pyplot as plt
(train_x, train_y),(test_x, test_y)=tf.keras.datasets.boston_housing.load_data(test_split=0)
plt.figure(figsize=(8,7))
plt.rcParams['font.sans-serif']='SimHei'# 此处设置坐标轴上字的大小
plt.rcParams.update({'font.size':8}) # 此处设置坐标轴上字的大小
break_marker = 0 # break只能跳出最深层循环,需设置一个标记,遇到标记后所有层都跳出
# print(train_x.shape)
xName = ['CRIM','ZN','INDUS','CHAS','NOX','RM','AGE','DIS','RAD','TAX','PTRATIO','B-1000','LSTAT','MEDV']
for i in range(4):
if break_marker == 1:
break
for j in range(4):
plt.subplot(4,4,i*4+j+1) # 句柄
# axes[0, 0].set_title('Default', fontsize=8)
plt.scatter(train_x[:,i*4+j],train_y,color=(27/255,27/255,100/255),s=3)
plt.xlabel(xName[i*4+j], fontsize=8)
plt.ylabel('Price ($1000\'s)', fontsize=8)
plt.ylim(0,60)
plt.yticks(range(0,61,10)) # xticks不会设置
title_list=str(i*4+j+1)+' '+xName[i*4+j]+'- Price'
plt.title(title_list,fontsize=8)
if i*4+j == 12:
break_marker = 1
break
plt.tight_layout(rect=[0.07,0,0.93,0.96]) # 不包含suptitle
plt.suptitle('各个属性与房价的关系',fontsize=16)
plt.show()