Jbd4:Hbase
Jbd4:Hbase
- 教程地址
- 0. 背景
-
- 0.1 Hadoop的局限性
- 0.2 HBase VS 传统数据库
-
- 0.2.1 数据类型
- 0.2.2 数据库类型
- 0.2.3 数据库区别
- 1. 概述
-
- 1.1 HBase 简介
- 1.2 HBase 访问接口
- 2. HBase 数据模型
-
- 2.1 数据模型概述
- 2.2 模型相关概念
- 2.3 数据坐标
- 2.4 概念视图
- 2.5 物理视图
- 2.6 面向列的存储
- 3. HBase的实现原理
-
- 3.1 HBase功能组件
- 3.2 表和Region
-
- 3.2.1 相应概念
- 3.2.2 分裂region
- 3.2.3 region详情
- 3.3 Region定位
-
- 3.3.1 定位Region
- 3.3.2 定位.META.表
- 3.3.3 结构图示
- 4. HBase运行机制
-
- 4.1 HBase系统架构
- 4.2 Region服务器的工作原理
-
- 4.2.1 用户读写数据过程
- 4.2.2 缓存的刷新
- 4.2.3 StoreFile的合并
- 4.3 Store工作原理
- 4.4 HLog工作原理
- 4.5 HBase性能优化
- 5. HBase 编程实战
-
- 5.1 实验一:HBase的安装部署和使用
-
- 5.1.1 实验准备
- 5.1.2 实验内容
- 5.1.3 实验步骤
-
- 5.1.3.1 解压安装包
- 5.1.3.2 更改文件夹名和所属用户
- 5.1.3.3 设置HBASE_HOME环境变量
- 5.1.3.4 修改hbase-site.xml配置文件
- 5.1.3.5 修改hbase-env.sh配置文件
- 5.1.3.6 启动hadoop
- 5.1.3.7 启动HBase
- 5.1.3.8 启动HBase Shell
- 5.1.3.9 创建表(create命令)
- 5.1.3.10 添加数据(put命令)
- 5.1.3.11 查看表内容(scan命令)
- 5.1.3.12 查询数据(get命令)
- 5.1.3.13 修改内容(put命令)
- 5.1.3.14 添加列族(alter命令)
- 5.1.3.15 删除列族(alter命令)
- 5.1.3.16 删除表(disable命令)
- 5.2 实验二:常用的HBase操作
-
- 5.2.1 实验准备
- 5.2.2 实验内容
- 5.2.3 实验步骤
-
- 5.2.3.1 构造数据
- 5.2.3.2 list命令
- 5.2.3.3 scan命令
- 5.2.3.4 alter命令
- 5.2.3.5 truncate命令
- 5.2.3.6 count命令
教程地址
https://github.com/datawhalechina/juicy-bigdata/
0. 背景
0.1 Hadoop的局限性
-
优点
Hadoop可以通过HDFS来存储结构化、半结构甚至非结构化的数据
对大文件的存储、批量访问和流式访问都做了优化,也有多副本设计
-
局限
但是Hadoop的缺陷在于它只能执行批处理,并且只能以顺序的方式访问数据
即使是最简单的工作,也必须搜索整个数据库,无法实现对数据的随机访问
反观传统的关系型数据库,其主要特点就在于随机访问,但不适用海量数据
Cassandra、ouchDB、Dynamo和MongoDB也能存储海量数据并支持随机访问。
0.2 HBase VS 传统数据库
0.2.1 数据类型
先来看一下数据的分类,按照结构可以分为:
-
结构化数据:
即以关系型数据库表形式管理的数据
例如各种符合范式的表格类型的文件
-
半结构化数据:
具有非关系模型、基本固定结构模式的数据
例如日志文件、XML文档、JSON文档、Email等
-
非结构化数据:
没有固定模式的数据
如Word、PDF、PPT、Excel
或者各种格式的图片、视频等
0.2.2 数据库类型
对于不同类型的数据,我们一般存入不同类型的数据库:
-
关系型数据库:
使用二维表格形式存储复杂的数据结构
代表软件:MySQL
-
键值存储数据库:
键值数据库是一种非关系数据库,将数据存储为键值对集合
代表软件:Redis
-
列存储数据库:
列式存储是相对于传统的行式存储来说的
两者的主要区别是对数据存储形式的差异
代表软件:HBase
-
面向文档数据库:
存放XML、JSON、BSON等格式的文档数据
具备自描述性,呈现分层的树状结构
可以包含映射表、集合和纯量值
代表软件:MongoDB
-
图形数据库:
NoSQL数据库的一种类型,可以用于存储实体之间的关系信息。
最常见例子就是社会网络中人与人之间的关系
代表软件:Neo4J、ArangoDB、OrientDB、FlockDB、
GraphDB、InfiniteGraph、Titan和Cayley等
-
搜索引擎数据库:
搜索引擎数据库是一类专门用于数据内容搜索的非关系数据库。
搜索引擎数据库使用索引对数据中的相似特征进行归类,并提高搜索能力。
搜索引擎数据库经过优化,以处理可能内容很长的半结构化或非结构化数据
它们通常提供专业的方法,例如全文搜索、复杂搜索表达式和搜索结果排名等。
代表软件:Solr、Elasticsearch等
0.2.3 数据库区别
新的形势下,传统数据库无法很好地处理数据高并发、高可拓展性及高可用性
因此造成了HBase的崭露头角,其与传统数据库的主要区别如下:
-
数据类型:
关系型数据库数据类型较为丰富,数据类型有int、date、long等。
Hbase数据类型简单,每个数据都被存储为未经解释的字符串
用户需要自己编写程序把字符串解析成不同的数据类型。
-
数据操作:
关系型数据库存在增删改查,还有我们比较熟悉的联表操作,效率较低。
Hbase不会把数据进行充分的规范化,而是存在一张表里,避免了低效率的连接操作。
-
存储模式:
关系型数据库采用行模式存储,Hbase是基于列存储。
-
数据索引:
关系型数据库可以对不同的列构建复杂的索引结构
Hbase支持对行键的索引。
-
数据维护:
更新操作时,关系型数据库会把数据替换掉,
Hbase会保留旧的版本数据一段时间,到了一定期限才会在后台清理数据。
-
可伸缩性:
关系型数据库很难实现水平扩展
Hbase采用分布式集群存储,水平扩展性较好
1. 概述
1.1 HBase 简介
HBase是高可靠、高性能、面向列、可伸缩的分布式数据库
主要用来存储非结构化和半结构化的松散数据
旨在提供对大量结构化数据的快速随机访问
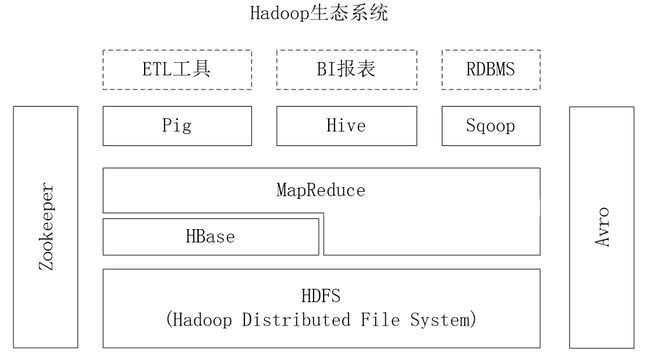
其与Hadoop生态系统组件的配合如下:
-
使用HDFS提供的容错功能,提供数据的随机实时读写访问
-
使用Hadoop MapReduce来处理HBase中的海量数据,实现高性能计算
-
使用ZooKeeper作为协同服务,实现稳定服务和失败恢复
-
使用HDFS作为高可靠的底层存储,利用廉价集群提供海量数据存储能力。
当然,HBase也可以直接使用本地文件系统而不用HDFS作为底层数据存储方式
-
使用Sqoop实现高效、便捷的RDBMS数据导入HBase的功能
-
使用Pig和Hive为HBase提供了高层语言支持。
1.2 HBase 访问接口
类型 特点 场合 Native Java API 最常规和高效的访问方式 适合Hadoop MapReduce作业并行批处理HBase表数据 HBase Shell HBase的命令行工具,最简单的接口 适合HBase管理使用 Thrift Gateway 利用Thrift序列化技术,支持C++、PHP、Python等多种语言 适合其他异构系统在线访问HBase表数据 REST Gateway 解除了语言限制 支持REST风格的Http API访问HBase Pig 使用Pig Latin流式编程语言来处理HBase中的数据 适合做数据统计 Hive 简单 当需要以类似SQL语言方式来访问HBase的时候
2. HBase 数据模型
2.1 数据模型概述
-
索引
HBase是一个稀疏、多维度、排序的映射表
这张表的索引是行键、列族、列限定符和时间戳
-
字段类型
每个值是一个未经解释的字符串,没有数据类型。
-
行构成
用户在表中存储数据,每一行都有一个可排序的行键和任意多的列。
-
列构成
表在水平方向由一个或者多个列族组成
一个列族中可以包含任意多个列
同一个列族里面的数据存储在一起
-
扩展列族
列族支持动态扩展,可以很轻松地添加一个列族或列
无需预先定义列的数量以及类型,所有列均以字符串形式存储
因此对于一行数据而言,有些列的值是空的,所以说HBase是稀疏的。
-
更新操作
HBase中执行更新操作时,并不会删除数据旧的版本
而是生成一个新的版本,旧有的版本仍然保留
这是和HDFS只允许追加不允许修改的特性相关的
2.2 模型相关概念
-
表:
HBase采用表来组织数据,表由行和列组成,列划分为若干个列族。
-
行:
每个HBase表都由若干行组成,每个行由行键(row key)来标识。
-
列族:
一个HBase表被分组成许多“列族”(Column Family)的集合,它是基本的访问控制单元。
表中的每个列都归属于某个列族,数据可以被存放到已存在的列族的某个列下面
列名都以列族作为前缀来进行访问操作,例如,courses:history属于courses这个列族。
-
列限定符:
列族里的数据通过列限定符(或列)来定位
-
单元格:
在HBase表中,通过行、列族和列限定符确定一个“单元格”(cell)
单元格中存储的数据没有数据类型,总被视为字节数组byte[]
-
时间戳:
每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引。
下面引用一张图来作示例:
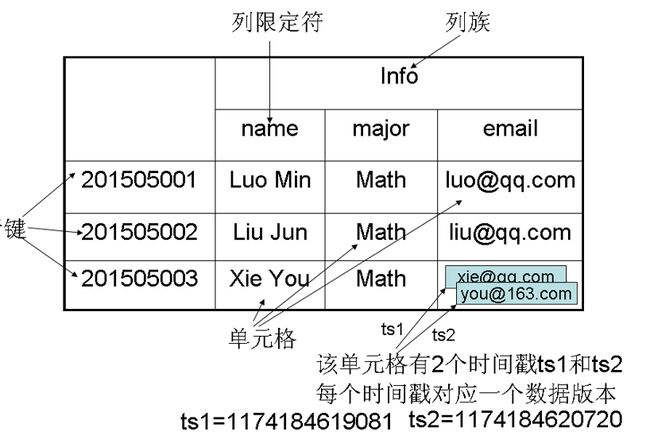
学号作为行键来唯一标识每个学生,应该也就是数据行的关键字
表中设计了列族Info来保存学生相关信息,也就是这里列族是个人信息
列族Info中包含3个列——name、major和email,分别用来保存对应的信息
学号为201505003的学生存在两个版本的电子邮件地址,拥有不同的时间戳
时间戳较大的版本的数据是最新的数据,但是旧版的数据依旧存在没有覆盖
2.3 数据坐标
依照上文所说,这个数据库单元格的索引是一个四维的坐标
即:[行键, 列族, 列限定符, 时间戳],也可以视作key,值为value

2.4 概念视图
引用示例如下:

行键是一个反向URL,由于HBase是按照行键的字典序来排序存储数据的
采用这种方式可以让来自同一个网站的数据内容都存在相邻的位置
在按照行键的值进行水平分区时,就可以尽量将他们分到同一个分区(Region)
在概念视图中可以看到,每个行都包含相同的列族,但并不是在每个列族里都有数据存储
从这个角度来说,HBase表是一个稀疏的映射关系,即里面存在很多空的单元格。
2.5 物理视图
继续引用上图的举例:
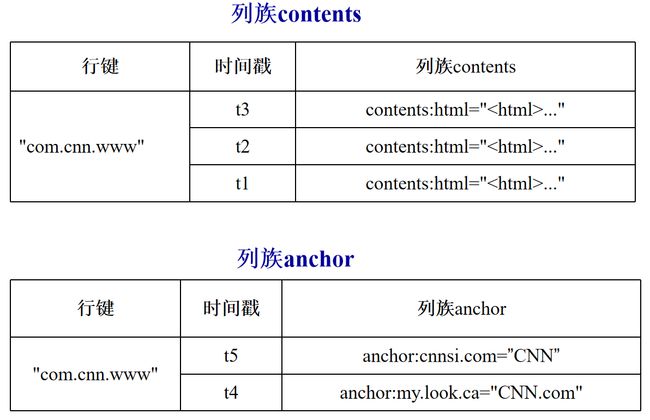
之前的概念视图层是按照行进行组织的,但是这个物理图是按列的,区别明显
注意:在概念视图中,我们可以发现,有些列是空的。但是在物理视图中, 这些空的列不会被存储。如果请求这些空白的单元格的时候,会返回null值。
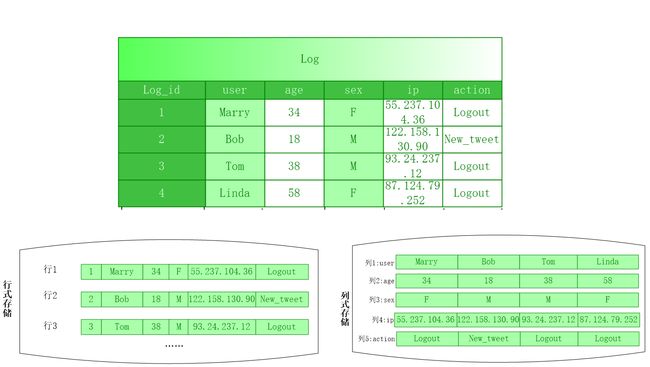
2.6 面向列的存储
引用示例如下:
-
传统行式数据库
-
数据是按行存储的,对比之前的概念图与物理图
-
没有索引的查询使用大量I/O,需要扫描完整内容再进行筛选
-
建立索引和物理视图需要花费大量时间和资源
-
面对查询的需求,数据库必须被大量膨胀才能满足性能要求
-
-
列式数据库
-
数据按列存储,对比之前的概念图与物理图
-
数据即是索引,根据关键字进行查询
-
只访问查询涉及的列,大量降低系统IO
-
每一列由一个线索来处理,查询采用并发处理方式
-
数据类型一致,数据特征相似,采用高效压缩方式
-
点陷在执行连接操作时,需要昂贵的元组重构代价
-
3. HBase的实现原理
3.1 HBase功能组件
主要的功能组件有三个,分别是 :
-
库函数(用于连接到每个客户端)
-
一个Master主服务器
-
许多个Region服务器。
其中,需要注意的是:
-
主服务器Master:
维护分区信息,维护Region服务器列表,分配Region,均衡负载
-
Region服务器:
维护分配给自己的Region,处理来自客户端的读写请求
-
读取数据
客户端是在查找节点后,直接从Region服务器上读取数据
-
查找节点
客户端并不依赖Master,查找节点也是通过Zookeeper获得位置信息
大多数客户端甚至从来不和Master通信,这种设计方式使得Master负载很小
3.2 表和Region
3.2.1 相应概念
-
HBase表根据行键的值的字典序对数据行维护
-
分布式存储的实现,是根据字典序划分行的区间
-
每个行区间构成一个分区,被称为Region。
-
每个分区存储了该区间内所有行的数据
-
分区是负载均衡和数据分发的基本单位
3.2.2 分裂region
但是这是初始化的时候,随着集群运行,分区肯定会变大
所以为了应对不断新增是数据,势必要新增region:
-
开始只有一个Region,随着新数据的不断加入,Region会越来越大。
-
当达到一定的阈值时,原始的一个region会分裂成两个新的Region
-
再之后,随着表中行的数量继续增加,就会分裂出更多的Region
需要注意的是:
-
Region拆分操作非常快,但是拆分之后的Region读取的仍然是原存储文件
-
直到“合并”过程把存储文件异步地写到独立的文件之后,才会读取新文件
-
这个特性应该是源于HDFS只能追加的特点,所以设置新区的时候旧区还存在

3.2.3 region详情
-
每个Region默认大小是100MB到200MB(2006年以前的硬件配置)
-
每个Region的最佳大小取决于单台服务器的有效处理能力
-
目前每个Region最佳大小建议1GB-2GB(2013年以后的硬件配置)
-
同一个Region不会被分拆到多个Region服务器
-
通常每个Region服务器负责管理10-1000个分区
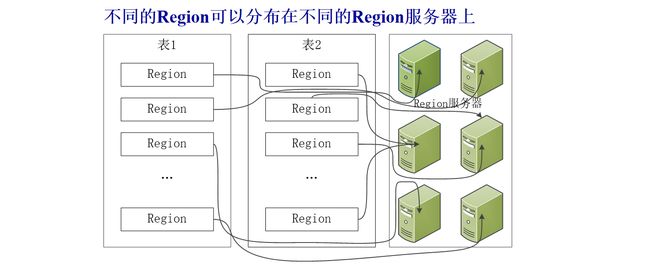
3.3 Region定位
3.3.1 定位Region
为了准确定位每个Region,我们赋予其唯一的RegionID来标识
一个Region标识符就可以表示成:表名+开始主键+RegionID
为了汇集每个Region所在的位置,可以构建一张映射表
每行包含两项内容:Region标识符、Region服务器标识
借此,我们可以定位某个Region所在的Region服务器
这个映射表包含了关于Region的元数据,又名.META.表。
3.3.2 定位.META.表
当表中的数据超多,Region数量就会非常庞大,.META.表也会很大
这个时候也需要进行分布式存储,.META.表也会被分裂成多个Region
那么当我们需要定位Region,我们需要先定位存储其位置的.META.表
那么.META.表理应也有元数据表,即存储所有的.META.表的位置
这个元数据表的元数据表就是-ROOT-表,其存在以下的特点:
-ROOT-表是不能被分割的,永远只存在一个Region用于存放-ROOT-表。
程序中写死了这唯一Region的名字,Master主服务器永远知道它的位置。
3.3.3 结构图示
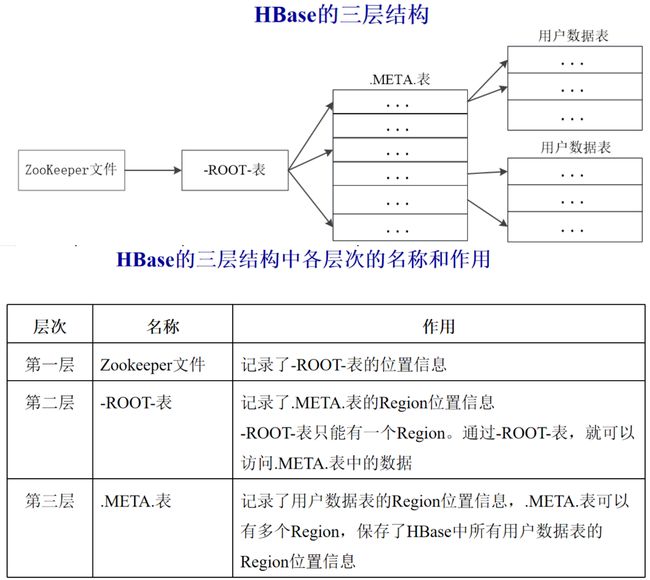
需要注意:
为了加快访问速度,.META.表的全部Region都会被保存在内存中
客户端访问数据时采用的是三级寻址,如图所示的root-meta-region结构
为了加速寻址,客户端会缓存位置信息。同时,需要解决缓存失效问题
寻址过程客户端只需要询问Zookeeper服务器,不需要连接Master服务器
因此,主服务器Master的负载相对就小了很多,几乎不与客户端通信
4. HBase运行机制
4.1 HBase系统架构
主要的结构如下:1
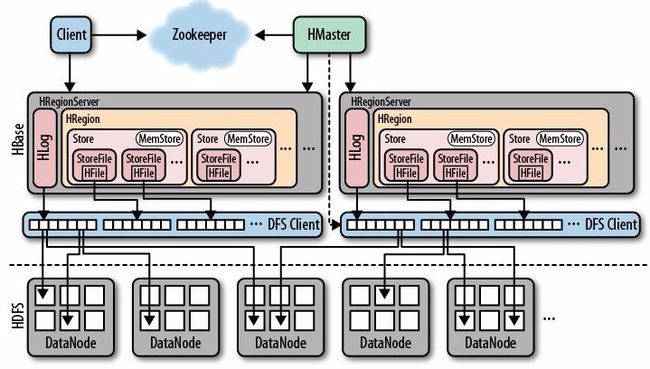
-
客户端:
客户端包含访问HBase的接口
同时在缓存中维护着已经访问过的Region位置信息
用来加快后续数据访问过程。
-
Zookeeper服务器:
用于选出集群的Master服务器
并保证在任何时刻总有唯一一个Master在运行
这就避免了Master的“单点失效”问题
同时,Zookeeper也被用于配置维护、域名服务等集群管理
-
Master服务器:
管理用户对表的增加、删除、修改、查询等操作
在Region分裂或合并后,重新调整Region的分布
对失效的Region服务器上的Region进行迁移
从而实现不同Region服务器之间的负载均衡
-
Region服务器:
负责维护分配给自己的Region分区
并与客户端进行通信,响应读写请求
一个region服务器包含多个region
多个region共用一个HLog日志
4.2 Region服务器的工作原理
4.2.1 用户读写数据过程
-
用户写入数据时,被zookeeper分配到相应Region服务器
-
需要写入的数据首先被写入到Region的MemStore和Hlog
-
当操作写入Hlog之后,调用commit() 方法才会将其返回给客户端
-
当用户读取数据时, Region服务器会首先访问MemStore缓存
-
如果找不到,再到磁盘的StoreFile中寻找
4.2.2 缓存的刷新
系统会周期性地把MemStore缓存刷写到磁盘的StoreFile文件
也就是清空MemStore缓存,并在Hlog里面写入一个标记
每次刷写都生成一个新的StoreFile文件,每个Store有多个StoreFile
每个Region服务器都有一个自己的HLog文件,每次启动都检查该文件
确认最近一次执行缓存刷新操作之后是否发生新的写入操作
如果发现更新,则先写入MemStore,再刷写到StoreFile
最后删除旧的Hlog文件,再开始为用户提供服务
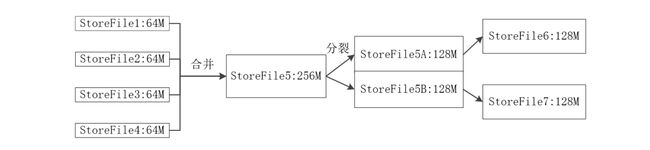
4.2.3 StoreFile的合并
每次刷写都生成一个新的StoreFile
随着StoreFile数量增多多,查找速度会受到影响
于是节点调用Store.compact()把多个StoreFile合并成一个
合并操作比较耗费资源,只有数量达到一定阈值后才会启动合并
4.3 Store工作原理
Store是Region服务器的核心,是主要存储文件的地方
例如上文提到,发现更新后要在写入StoreFile后提供服务
小的StoreFile会合并,大的StoreFile又会触发分裂
一个region中每个列族会单独构成一个store
所以说一个region有多个store,store内是storefile
StoreFile又会根据大小来分裂或者合并,维持平衡
4.4 HLog工作原理
分布式环境下要考虑到系统出错的情形,以及故障后的处理,
比如当Region服务器发生故障时,MemStore缓存中的数据会全部丢失
此时这些丢失的文件当中,可能有一部分还没有来得及写入文件
因此,HBase用HLog来保证故障后恢复到正确的状态,特点如下:
-
HBase系统为每个Region服务器配置了一个HLog文件
它是一种预写式日志(Write Ahead Log)。
-
用户更新数据必须首先写入HLog日志后,才能写入MemStore缓存
并且需要在对应的日志已经写入磁盘后,该缓存内容才能被刷写到磁盘。
-
Zookeeper会实时监测每个Region服务器的状态
当某个Region服务器发生故障时,Zookeeper会通知Master来处理
-
Master首先会处理该故障Region服务器上面遗留的HLog文件
这个遗留的HLog文件中包含了来自多个Region对象的日志记录
-
系统会根据每条日志记录所属的Region对象对HLog数据进行拆分
分别将不同的HLog日志数据放到相应Region对象的目录下
然后,再将失效服务器的Region重新分配到可用的Region服务器
并把与该Region对象相关的HLog日志记录也发送给相应的Region服务器
-
Region服务器领取到自己的Region及相关HLog以后
会重新做一遍HLog日志记录中的各种操作
把日志记录中的数据写入到MemStore缓存中
然后,刷新到磁盘的StoreFile文件中,完成数据恢复。
-
共用日志的优点是提高对表的写操作性能
其缺点是恢复时需要分拆日志。
4.5 HBase性能优化
-
行键(Row Key):
行键是按照字典序排序存储,在设计行键时要充分利用这个特点
我们可以将经常一起读取的数据利用行键存储到一块
也可以将最近可能会被访问的数据利用行键放在一块
例如:如果最近写入HBase表中的数据是最可能被访问的
那就可以考虑将时间戳作为行键的一部分来进行设计
-
InMemory:
创建表的时候,可将表放到Region服务器的缓存中
保证在读取的时候被cache命中。
-
Max Version:
创建表的时候,可设置表中数据的最大版本,这样可以弃掉过旧的版本
如果只需要保存最新版本的数据,那么可以设置setMaxVersions(1)
-
Time To Live:
创建表的时候,可设置表中数据的存储生命期,过期数据将自动被删除。
5. HBase 编程实战
5.1 实验一:HBase的安装部署和使用
5.1.1 实验准备
Linux Ubuntu 20.04,完成Java部署,完成Hadoop部署
5.1.2 实验内容
在上述的实验环境中,安装HBase并学习HBase Shell的使用。
5.1.3 实验步骤
5.1.3.1 解压安装包
master@VM-0-12-ubuntu:/opt/JuciyBigData$ ls
apache-hive-2.3.9-bin.tar.gz hbase-2.4.8-bin.tar.gz mysql-connector-java_8.0.27-1ubuntu20.04_all.deb
hadoop-3.3.1.tar.gz jdk-8u311-linux-x64.tar.gz spark-3.2.0-bin-without-hadoop.tgz
master@VM-0-12-ubuntu:/opt/JuciyBigData$ sudo tar -zxvf hbase-2.4.8-bin.tar.gz -C /opt
···
hbase-2.4.8/lib/jdk11/jakarta.xml.soap-api-1.4.1.jar
hbase-2.4.8/lib/jdk11/jakarta.jws-api-1.1.1.jar
master@VM-0-12-ubuntu:/opt/JuciyBigData$ cd /opt
master@VM-0-12-ubuntu:/opt$ ls
hadoop hbase-2.4.8 java JuciyBigData JuciyBigData.zip master
master@VM-0-12-ubuntu:/opt$
5.1.3.2 更改文件夹名和所属用户
master@VM-0-12-ubuntu:/opt$ ll | grep h
drwxr-xr-x 13 master master 4096 Mar 15 23:20 hadoop/
drwxr-xr-x 7 root root 4096 Mar 18 19:59 hbase-2.4.8/
master@VM-0-12-ubuntu:/opt$ sudo mv hbase-2.4.8/ hbase
master@VM-0-12-ubuntu:/opt$ sudo chown -R master:master hbase/
master@VM-0-12-ubuntu:/opt$ ll | grep h
drwxr-xr-x 13 master master 4096 Mar 15 23:20 hadoop/
drwxr-xr-x 7 master master 4096 Mar 18 19:59 hbase/
master@VM-0-12-ubuntu:/opt$
5.1.3.3 设置HBASE_HOME环境变量
在/etc/profile当中添加以下内容:
# hbase
export HBASE_HOME=/opt/hbase
export PATH=$PATH:$HBASE_HOME/bin
实践如下:
master@VM-0-12-ubuntu:/opt$ sudo vim /etc/profile
master@VM-0-12-ubuntu:/opt$ source /etc/profile
master@VM-0-12-ubuntu:/opt$ tail /etc/profile
export PATH=$JAVA_HOME/bin:$PATH
#hadoop
export HADOOP_HOME=/opt/hadoop
export PATH=$HADOOP_HOME/bin:$PATH
# hbase
export HBASE_HOME=/opt/hbase
export PATH=$PATH:$HBASE_HOME/bin
master@VM-0-12-ubuntu:/opt$
说起来好像可以用重定向>>追加到文件末尾啊
5.1.3.4 修改hbase-site.xml配置文件
添加下面配置到/opt/hbase/conf/hbase-site.xml中的标签之间:
<configuration>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
实践如下:
master@VM-0-12-ubuntu:/opt$ cat /opt/hbase/conf/hbase-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
<configuration>
<property>
<name>hbase.cluster.distributed</name>
<value>false</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>./tmp</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
master@VM-0-12-ubuntu:/opt$ sudo vim /opt/hbase/conf/hbase-site.xml
master@VM-0-12-ubuntu:/opt$ cat /opt/hbase/conf/hbase-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>./tmp</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
</configuration>
master@VM-0-12-ubuntu:/opt$
比较神奇,我发现有些项目是文件当中已经存在的
例如hbase.cluster.distributed从默认的false改为true
然后hbase.unsafe.stream.capability.enforce的false不变
在尾部追加hbase.rootdir的地址
5.1.3.5 修改hbase-env.sh配置文件
修改/opt/hbase/conf/hbase-env.sh当中的JAVA_HOME,HBASE_CLASSPATH,HBASE_MANAGES_ZK
master@VM-0-12-ubuntu:/opt$ sudo vim /opt/hbase/conf/hbase-env.sh
master@VM-0-12-ubuntu:/opt$ tail /opt/hbase/conf/hbase-env.sh
# export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP="true"
# Override text processing tools for use by these launch scripts.
# export GREP="${GREP-grep}"
# export SED="${SED-sed}"
export JAVA_HOME=/opt/java/ # JDK的安装目录
export HBASE_CLASSPATH=/opt/hbase/conf # 本机HBase安装目录下的conf目录
export HBASE_MANAGES_ZK=true # 由HBase自己管理zookeeper,不需要单独的zookeeper
master@VM-0-12-ubuntu:/opt$
配置文件当中应该是有这些项目的设置,只不过注释掉了
我没有去找默认的位置,而是选择在尾部进行追加
注意!注意!注意!
如果你的版本是Hadoop 3.3.1和Hbase 2.4.8,那么最好再加上这个:
export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP=true #避免SLF4J的jar包冲突
大概因为有个jar包会冲突导致一些错误…没错,就是SLF4J
在启动Hbase的时候就会报错,我还傻傻地敲了个yes,详见下文
另外,这个命令在原文当中也是存在的!只不过被注释掉了,和上面一样
5.1.3.6 启动hadoop
转到对应的目录下面,./start-all.sh,再执行jps进行检查
master@VM-0-12-ubuntu:/opt$ cd /opt/hadoop/sbin/
master@VM-0-12-ubuntu:/opt/hadoop/sbin$ ./start-all.sh
WARNING: Attempting to start all Apache Hadoop daemons as master in 10 seconds.
WARNING: This is not a recommended production deployment configuration.
WARNING: Use CTRL-C to abort.
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [VM-0-12-ubuntu]
Starting resourcemanager
Starting nodemanagers
master@VM-0-12-ubuntu:/opt/hadoop/sbin$ jps
698267 SecondaryNameNode
698685 NodeManager
699170 Jps
698050 DataNode
697894 NameNode
698532 ResourceManager
master@VM-0-12-ubuntu:/opt/hadoop/sbin$
5.1.3.7 启动HBase
转到对应的文件夹下面,但是加上./之后会报错,挺神奇的
然后就是启动过程中会暂停询问是否继续连接,还需要敲个yse
啊啊啊啊这个是报错啊报错啊,敲锤子的yes,当时没发现
最后执行jps进行检查,新增了HQuorumPeer等三个进程
教程这里给的是/opt/hadoop/sbin/,而这里没有./start-hbase.sh
但是看起来好像运行成功了,应该是这个路径加入环境变量了
理论上来说应该去/opt/hbase/bin,那里才是hbase的命令
master@VM-0-12-ubuntu:/opt/hadoop/sbin$ ./start-hbase.sh
bash: ./start-hbase.sh: No such file or directory
master@VM-0-12-ubuntu:/opt/hadoop/sbin$ start-hbase.sh
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hbase/lib/client-facing-thirdparty/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hbase/lib/client-facing-thirdparty/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
The authenticity of host '127.0.0.1 (127.0.0.1)' can't be established.
ECDSA key fingerprint is SHA256:5vRo0/nGDBuyknC2msG0n3P4a7H1LD2weTDyiIdNUhU.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
127.0.0.1: Warning: Permanently added '127.0.0.1' (ECDSA) to the list of known hosts.
127.0.0.1: running zookeeper, logging to /opt/hbase/bin/../logs/hbase-master-zookeeper-VM-0-12-ubuntu.out
running master, logging to /opt/hbase/logs/hbase-master-master-VM-0-12-ubuntu.out
: running regionserver, logging to /opt/hbase/logs/hbase-master-regionserver-VM-0-12-ubuntu.out
master@VM-0-12-ubuntu:/opt/hadoop/sbin$ jps
698267 SecondaryNameNode
700126 HQuorumPeer
698685 NodeManager
698050 DataNode
697894 NameNode
700327 HRegionServer
700215 HMaster
698532 ResourceManager
700612 Jps
master@VM-0-12-ubuntu:/opt/hadoop/sbin$
然后发现教程上面还给了一些故障处理方法:
如果HMaster启动后瞬间消失,请查看/opt/hbase/logs日志文件。
如果出现connection failed,注意虚拟机环回IP的通信问题以及防火墙是否关闭!!!
具体的处理操作如下
-
关闭防火墙,或者开放
9000端口也行,不过还是关吧systemctl disable firewalld.service然而这好像是
centos的命令,ubuntu的如下:sudo ufw status sudo ufw disable -
修改/etc/hosts文件
打开
/etc/hosts并追加以下内容:127.0.1.1 虚拟机的名称 -
修改/opt/hbase/conf/regionservers文件
打开
/opt/hbase/conf/regionservers并追加以下内容:<虚拟机的名称>
5.1.3.8 启动HBase Shell
需要进入/opt/hbase/bin,然后运行hbase shell命令:
SLF4J在报错啊报错啊啊啊啊啊,当时根本没想到是报错
教程上也有这个东西,报出了SLF4J的问题,他咋没事啊
后来我回去翻了一下,他是hbase 2.3.5,这里是2.4.8
master@VM-0-12-ubuntu:/opt/hadoop/sbin$ cd /opt/hbase/bin
master@VM-0-12-ubuntu:/opt/hbase/bin$ hbase shell
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hbase/lib/client-facing-thirdparty/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
HBase Shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell
Version 2.4.8, rf844d09157d9dce6c54fcd53975b7a45865ee9ac, Wed Oct 27 08:48:57 PDT 2021
Took 0.0083 seconds
hbase:001:0>
5.1.3.9 创建表(create命令)
在hbase的命令行模式下,创建一个student表,info和addr为该表的两个列族,创建语句如下:
create 'student','info','addr'
好了,在这里正式翻车,先给大家看看错误的现场吧,在上面hbase shell的基础上
hbase:001:0> create 'student','info','addr'
ERROR: org.apache.hadoop.hbase.ipc.ServerNotRunningYetException: Server is not running yet
at org.apache.hadoop.hbase.master.HMaster.checkServiceStarted(HMaster.java:2817)
at org.apache.hadoop.hbase.master.MasterRpcServices.isMasterRunning(MasterRpcServices.java:1205)
at org.apache.hadoop.hbase.shaded.protobuf.generated.MasterProtos$MasterService$2.callBlockingMethod(MasterProtos.java)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:392)
at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:133)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:354)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:334)
For usage try 'help "create"'
Took 10.6261 seconds
hbase:002:0>
然后我就以Server is not running yet为关键词查找博客
找到了说是HDFS安全模式没关的原因2,那就去关
尴尬的是,我去查了状态,安全模式一直都在关着
然后又想着,遇事不决就重启,于是重启了服务器
重启后问题更大了,jps后的namenode进程没了
啊,我那么大的一个namenode嘞?之前都没错啊
然后查到博客3说是关机后把临时文件给清除了
所以HDFS的格式化配置没了,可以自己建临时文件地址
行吧行吧,别管之前为啥不出错了,先用这个调回来
然后再去hbase shell,继续报同样的错误,哇,上火
然后查了其他的Hbase安装教程4,发现hbase-site.xml不同
于是就删除掉了hbase.unsafe.stream.capability.enforce再重试
然后,然后就出问题了:我是想着先关掉Hbasea再重启,重新载入配置
但是运行stop-hbase.sh之后一直在···,都打印两行了还没停,哇,好气
那就再查再试,根据博客5,先start-hbase.sh,再根据报错kill -9
杀掉已经存在的进程之后,再start-hbase.sh就是重启集群了
说起来后面也关了几次,但stop-hbase.sh没有一次成功的,离谱
但是还不行,嘿,我这暴脾气,我去试试单机版,按官网教程来
没想到按照官网的教程更惨,直接报了一个Error,找不到主机
整懵了,再回去尝试伪分布式,网站的管理页面都能打开,看起来正常
但是Hbase的shell还是不行,create报错,list也报错,就是不行
然后再折腾回去单机式,哇,这次连网站的管理页面都打不开了
最后,终于,终于想到了教程是2.3.5,但给的安装包是2.4.8
然后就以hadoop 3.3.1 hbase 2.4.8为关键词搜索,找到博客6
总之看起来就是SLF4J冲突,需要在hbase-env.sh中补充:
export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP=true #避免SLF4J的jar包冲突
搞完之后,当然要重启集群才能载入设置,按照上面的操作来一套
接下来重新cd /opt/hbase/bin,然后hbase shell,可以看到SLF4J没了
master@VM-0-12-ubuntu:/opt/hbase/bin$ hbase shell
2022-03-19 20:49:40,678 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
HBase Shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell
Version 2.4.8, rf844d09157d9dce6c54fcd53975b7a45865ee9ac, Wed Oct 27 08:48:57 PDT 2021
Took 0.0085 seconds
hbase:001:0> create 'student','info','addr'
Created table student
Took 1.6429 seconds
=> Hbase::Table - student
hbase:002:0>
当然重点是,这个表终于建成功了啊啊啊啊啊,我搞到半夜三点啊
5.1.3.10 添加数据(put命令)
向表终添加数据:
put 'student','1','info:name','zeno'
put 'student','1','info:age','22'
put 'student','1','addr:city','hefei'
put 'student','2','info:sex','man'
我们在上面说过,坐标应该是有四个维度,借此来访问value:
表名,行关键字,列族,列标识符。简单来说就是表、行、列
所以命令意即:student表第1行info族name列的值为zeno
实践如下:
hbase:002:0> put 'student','1','info:name','zeno'
Took 0.3648 seconds
hbase:003:0> put 'student','1','info:age','22'
Took 0.0099 seconds
hbase:005:0> put 'student','1','addr:city','hefei'
Took 0.0136 seconds
hbase:006:0> put 'student','2','info:sex','man'
Took 0.0095 seconds
hbase:007:0>
瞧瞧这命令运行的多快,所敲即所得,跟心情一样,畅快极了
5.1.3.11 查看表内容(scan命令)
来看看我们举例子的表里面都有些什么东西啊:
hbase:007:0> scan 'student'
ROW COLUMN+CELL
1 column=addr:city, timestamp=2022-03-19T20:53:25.410, value=hefei
1 column=info:age, timestamp=2022-03-19T20:53:18.856, value=22
1 column=info:name, timestamp=2022-03-19T20:53:12.834, value=zeno
2 column=info:sex, timestamp=2022-03-19T20:53:29.986, value=man
2 row(s)
Took 0.1397 seconds
hbase:008:0>
5.1.3.12 查询数据(get命令)
举的这个例子好像只输入了表和行,那结果应该是所有列:
get 'student','1'
实践如下:
hbase:008:0> get 'student','1'
COLUMN CELL
addr:city timestamp=2022-03-19T20:53:25.410, value=hefei
info:age timestamp=2022-03-19T20:53:18.856, value=22
info:name timestamp=2022-03-19T20:53:12.834, value=zeno
1 row(s)
Took 0.0765 seconds
hbase:009:0
5.1.3.13 修改内容(put命令)
严格来说没有修改,这实际只是追加,毕竟底层是HDFS:
hbase:008:0> get 'student','1'
COLUMN CELL
addr:city timestamp=2022-03-19T20:53:25.410, value=hefei
info:age timestamp=2022-03-19T20:53:18.856, value=22
info:name timestamp=2022-03-19T20:53:12.834, value=zeno
1 row(s)
Took 0.0765 seconds
hbase:009:0> put 'student','1','info:age','18'
Took 0.0139 seconds
hbase:010:0> get 'student','1'
COLUMN CELL
addr:city timestamp=2022-03-19T20:53:25.410, value=hefei
info:age timestamp=2022-03-19T21:02:54.320, value=18
info:name timestamp=2022-03-19T20:53:12.834, value=zeno
1 row(s)
Took 0.0139 seconds
hbase:011:0>
5.1.3.14 添加列族(alter命令)
hbase:011:0> alter 'student', 'nation'
Updating all regions with the new schema...
1/1 regions updated.
Done.
Took 2.4964 seconds
hbase:012:0> describe 'student'
Table student is ENABLED
student
COLUMN FAMILIES DESCRIPTION
{NAME => 'addr', BLOOMFILTER => 'ROW', IN_MEMORY => 'false',
VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE',
DATA_BLOCK_ENCODING => 'NONE', COMPRESSION => 'NONE', TTL =>
'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE
=> '65536', REPLICATION_SCOPE => '
0'}
{NAME => 'info', BLOOMFILTER => 'ROW', IN_MEMORY => 'false',
VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE',
DATA_BLOCK_ENCODING => 'NONE', COMPRESSION => 'NONE', TTL =>
'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE
=> '65536', REPLICATION_SCOPE => '
0'}
{NAME => 'nation', BLOOMFILTER => 'ROW', IN_MEMORY => 'false',
VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE',
DATA_BLOCK_ENCODING => 'NONE', COMPRESSION => 'NONE', TTL =>
'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE
=> '65536', REPLICATION_SCOPE =>'0'}
3 row(s)
Quota is disabled
Took 0.0684 seconds
hbase:013:0>
5.1.3.15 删除列族(alter命令)
hbase:013:0> alter 'student', NAME => 'nation', METHOD => 'delete'
Updating all regions with the new schema...
1/1 regions updated.
Done.
Took 1.9700 seconds
hbase:014:0> describe 'student'
Table student is ENABLED
student
COLUMN FAMILIES DESCRIPTION
{NAME => 'addr', BLOOMFILTER => 'ROW', IN_MEMORY => 'false',
VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE',
DATA_BLOCK_ENCODING => 'N
ONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS =>
'0', BLOCKCACHE => 'true', BLOCKSIZE => '65536',
REPLICATION_SCOPE => '
0'}
{NAME => 'info', BLOOMFILTER => 'ROW', IN_MEMORY => 'false',
VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE',
DATA_BLOCK_ENCODING => 'N
ONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS =>
'0', BLOCKCACHE => 'true', BLOCKSIZE => '65536',
REPLICATION_SCOPE => '
0'}
2 row(s)
Quota is disabled
Took 0.0423 seconds
hbase:015:0>
5.1.3.16 删除表(disable命令)
Hbase不能直接删除表,而是需要先disable禁用,然后再drop删除
hbase:015:0> disable 'student'
Took 0.4234 seconds
hbase:016:0> drop 'student'
Took 0.6891 seconds
hbase:017:0>
5.2 实验二:常用的HBase操作
5.2.1 实验准备
Ubuntu 20.04,Java,Hadoop
5.2.2 实验内容
-
新增数据
将关系型数据库格式的表和数据,转换为适合于HBase存储的表格式并插入数据
-
list命令
列出HBase所有的表的相关信息,如表名、创建时间等
-
scan命令
打印Course表的所有记录数据(按照截图,创建Course表及列族,并添加数据)
-
alter命令
向已经创建好的表添加和删除指定的列族或列
-
truncate命令
清空指定的表的所有记录数据
-
count命令
统计表的行数
5.2.3 实验步骤
5.2.3.1 构造数据
查阅博客7,发现可以先将命令写入文件,然后批量执行,文件如下:
# The 1st table 'Student' # start------------------------
create 'Student', 'S_No', 'S_Name', 'S_Sex', 'S_Age'
# The 1st column 'S_No'
put 'Student', '1', 'S_No:', '2015001'
put 'Student', '2', 'S_No:', '2015002'
put 'Student', '3', 'S_No:', '2015003'
# The 2nd column 'S_Name'
put 'Student', '1', 'S_Name:', 'Zhangsan'
put 'Student', '2', 'S_Name:', 'Mary'
put 'Student', '3', 'S_Name:', 'Lisi'
# The 3rd column 'S_Sex'
put 'Student', '1', 'S_Sex:', 'male'
put 'Student', '2', 'S_Sex:', 'female'
put 'Student', '3', 'S_Sex:', 'male'
# The 4th column 'S_Age'
put 'Student', '1', 'S_Age:', '23'
put 'Student', '2', 'S_Age:', '22'
put 'Student', '3', 'S_Age:', '24'
# The 1st table 'Student' # end------------------------
# The 2nd table 'Course' # strat------------------------
create 'Course', 'C_No', 'C_name', 'C_credit'
# The 1st column 'C_No'
put 'Course', '1', 'C_No:', '123001'
put 'Course', '2', 'C_No:', '123002'
put 'Course', '3', 'C_No:', '123003'
# The 2nd column 'C_name'
put 'Course', '1', 'C_name:', 'Math'
put 'Course', '2', 'C_name:', 'Comuputer Science'
put 'Course', '3', 'C_name:', 'English'
# The 3rd column 'C_credit'
put 'Course', '1', 'C_credit:', '2.0'
put 'Course', '2', 'C_credit:', '5.0'
put 'Course', '3', 'C_credit:', '3.0'
# The 2nd table 'Course' # end------------------------
# The 3rd table 'SC' # strat------------------------
create 'SC', 'SC_Sno', 'SC_Cno', 'SC_Score'
# The 1st column 'SC_Sno'
put 'SC', '1', 'SC_Sno:', '2015001'
put 'SC', '2', 'SC_Sno:', '2015001'
put 'SC', '3', 'SC_Sno:', '2015002'
put 'SC', '4', 'SC_Sno:', '2015002'
put 'SC', '5', 'SC_Sno:', '2015003'
put 'SC', '6', 'SC_Sno:', '2015003'
# The 2nd column 'SC_Cno'
put 'SC', '1', 'SC_Cno:', '123001'
put 'SC', '2', 'SC_Cno:', '123003'
put 'SC', '3', 'SC_Cno:', '123002'
put 'SC', '4', 'SC_Cno:', '123003'
put 'SC', '5', 'SC_Cno:', '123001'
put 'SC', '6', 'SC_Cno:', '123002'
# The 3rd column 'SC_Score'
put 'SC', '1', 'SC_Score:', '86'
put 'SC', '2', 'SC_Score:', '69'
put 'SC', '3', 'SC_Score:', '77'
put 'SC', '4', 'SC_Score:', '99'
put 'SC', '5', 'SC_Score:', '98'
put 'SC', '6', 'SC_Score:', '95'
# The 3rd table 'SC' # end------------------------
# exit
使用hbase shell在该文件的路径下执行:
master@VM-0-12-ubuntu:/opt/master$ vim db.txt
master@VM-0-12-ubuntu:/opt/master$ hbase shell db.txt
2022-03-19 21:49:45,199 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Created table Student
Took 1.7173 seconds
Hbase::Table - Student
Took 0.3328 seconds
Took 0.0049 seconds
Took 0.0141 seconds
Took 0.0145 seconds
Took 0.0045 seconds
Took 0.0108 seconds
Took 0.0067 seconds
Took 0.0101 seconds
Took 0.0056 seconds
Took 0.0054 seconds
Took 0.0083 seconds
Took 0.0074 seconds
Created table Course
Took 1.1760 seconds
Hbase::Table - Course
Took 0.0210 seconds
Took 0.0079 seconds
Took 0.0072 seconds
Took 0.0084 seconds
Took 0.0077 seconds
Took 0.0056 seconds
Took 0.0052 seconds
Took 0.0082 seconds
Took 0.0062 seconds
Created table SC
Took 0.6468 seconds
Hbase::Table - SC
Took 0.0183 seconds
Took 0.0094 seconds
Took 0.0055 seconds
Took 0.0070 seconds
Took 0.0071 seconds
Took 0.0084 seconds
Took 0.0075 seconds
Took 0.0047 seconds
Took 0.0050 seconds
Took 0.0090 seconds
Took 0.0088 seconds
Took 0.0123 seconds
Took 0.0206 seconds
Took 0.0044 seconds
Took 0.0060 seconds
Took 0.0065 seconds
Took 0.0078 seconds
Took 0.0049 seconds
HBase Shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell
Version 2.4.8, rf844d09157d9dce6c54fcd53975b7a45865ee9ac, Wed Oct 27 08:48:57 PDT 2021
Took 0.0043 seconds
hbase:001:0>
查看各个表:
hbase:001:0> list
TABLE
Course
SC
Student
3 row(s)
Took 0.0309 seconds
=> ["Course", "SC", "Student"]
hbase:002:0> scan "Course"
ROW COLUMN+CELL
1 column=C_No:, timestamp=2022-03-19T21:49:50.316, value=123001
1 column=C_credit:, timestamp=2022-03-19T21:49:50.492, value=2.0
1 column=C_name:, timestamp=2022-03-19T21:49:50.436, value=Math
2 column=C_No:, timestamp=2022-03-19T21:49:50.340, value=123002
2 column=C_credit:, timestamp=2022-03-19T21:49:50.509, value=5.0
2 column=C_name:, timestamp=2022-03-19T21:49:50.455, value=Comuputer Science
3 column=C_No:, timestamp=2022-03-19T21:49:50.407, value=123003
3 column=C_credit:, timestamp=2022-03-19T21:49:50.525, value=3.0
3 column=C_name:, timestamp=2022-03-19T21:49:50.471, value=English
3 row(s)
Took 0.1128 seconds
hbase:003:0> scan "SC"
ROW COLUMN+CELL
1 column=SC_Cno:, timestamp=2022-03-19T21:49:51.394, value=123001
1 column=SC_Score:, timestamp=2022-03-19T21:49:51.513, value=86
1 column=SC_Sno:, timestamp=2022-03-19T21:49:51.214, value=2015001
2 column=SC_Cno:, timestamp=2022-03-19T21:49:51.411, value=123003
2 column=SC_Score:, timestamp=2022-03-19T21:49:51.537, value=69
2 column=SC_Sno:, timestamp=2022-03-19T21:49:51.256, value=2015001
3 column=SC_Cno:, timestamp=2022-03-19T21:49:51.430, value=123002
3 column=SC_Score:, timestamp=2022-03-19T21:49:51.549, value=77
3 column=SC_Sno:, timestamp=2022-03-19T21:49:51.310, value=2015002
4 column=SC_Cno:, timestamp=2022-03-19T21:49:51.449, value=123003
4 column=SC_Score:, timestamp=2022-03-19T21:49:51.560, value=99
4 column=SC_Sno:, timestamp=2022-03-19T21:49:51.334, value=2015002
5 column=SC_Cno:, timestamp=2022-03-19T21:49:51.461, value=123001
5 column=SC_Score:, timestamp=2022-03-19T21:49:51.575, value=98
5 column=SC_Sno:, timestamp=2022-03-19T21:49:51.351, value=2015003
6 column=SC_Cno:, timestamp=2022-03-19T21:49:51.475, value=123002
6 column=SC_Score:, timestamp=2022-03-19T21:49:51.598, value=95
6 column=SC_Sno:, timestamp=2022-03-19T21:49:51.368, value=2015003
6 row(s)
Took 0.0848 seconds
hbase:004:0> scan "Student"
ROW COLUMN+CELL
1 column=S_Age:, timestamp=2022-03-19T21:49:48.974, value=23
1 column=S_Name:, timestamp=2022-03-19T21:49:48.842, value=Zhangsan
1 column=S_No:, timestamp=2022-03-19T21:49:48.704, value=2015001
1 column=S_Sex:, timestamp=2022-03-19T21:49:48.915, value=male
2 column=S_Age:, timestamp=2022-03-19T21:49:48.995, value=22
2 column=S_Name:, timestamp=2022-03-19T21:49:48.864, value=Mary
2 column=S_No:, timestamp=2022-03-19T21:49:48.750, value=2015002
2 column=S_Sex:, timestamp=2022-03-19T21:49:48.940, value=female
3 column=S_Age:, timestamp=2022-03-19T21:49:49.074, value=24
3 column=S_Name:, timestamp=2022-03-19T21:49:48.884, value=Lisi
3 column=S_No:, timestamp=2022-03-19T21:49:48.804, value=2015003
3 column=S_Sex:, timestamp=2022-03-19T21:49:48.955, value=male
3 row(s)
Took 0.0412 seconds
hbase:005:0>
应该是属于建造成功,但是这个格式还是传统的关系型数据库
每一个列族都只有一个列,对应关系型数据库的列
5.2.3.2 list命令
如上文演示,展示所有表
5.2.3.3 scan命令
如上文所示,展示所有数据
5.2.3.4 alter命令
修改列族,新增或者删除
hbase:005:0> # add 'nation' to column family of 'Student'
hbase:006:0> alter 'Student', 'nation'
Updating all regions with the new schema...
1/1 regions updated.
Done.
Took 2.7650 seconds
hbase:007:0> describe 'Student'
Table Student is ENABLED
Student
COLUMN FAMILIES DESCRIPTION
{NAME => 'S_Age', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => '
NONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE =>
'0'}
{NAME => 'S_Name', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING =>
'NONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE =>
'0'}
{NAME => 'S_No', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'N
ONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '
0'}
{NAME => 'S_Sex', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => '
NONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE =>
'0'}
{NAME => 'nation', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING =>
'NONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE =>
'0'}
5 row(s)
Quota is disabled
Took 0.0753 seconds
hbase:010:0> alter 'Student', 'nation', METHOD => 'delete'
ERROR: NAME parameter missing for delete method
For usage try 'help "alter"'
Took 0.0913 seconds
hbase:011:0> alter 'Student', NAME=>'nation', METHOD=>'delete'
Updating all regions with the new schema...
1/1 regions updated.
Done.
Took 1.9070 seconds
hbase:012:0> describe 'Student'
Table Student is ENABLED
Student
COLUMN FAMILIES DESCRIPTION
{NAME => 'S_Age', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => '
NONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE =>
'0'}
{NAME => 'S_Name', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING =>
'NONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE =>
'0'}
{NAME => 'S_No', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'N
ONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '
0'}
{NAME => 'S_Sex', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => '
NONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE =>
'0'}
4 row(s)
Quota is disabled
Took 0.0749 seconds
hbase:013:0>
挺神奇的,删除的时候还要加上NAME指定参数名称
应该是因为后面指定了METHOD参数'delete'吧
5.2.3.5 truncate命令
清空指定的表的所有记录数据
hbase:013:0> truncate 'Student'
Truncating 'Student' table (it may take a while):
Disabling table...
Truncating table...
Took 1.5736 seconds
hbase:014:0> describe 'Student'
Table Student is ENABLED
Student
COLUMN FAMILIES DESCRIPTION
{NAME => 'S_Age', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => '
NONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE =>
'0'}
{NAME => 'S_Name', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING =>
'NONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE =>
'0'}
{NAME => 'S_No', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'N
ONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '
0'}
{NAME => 'S_Sex', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => '
NONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE =>
'0'}
4 row(s)
Quota is disabled
Took 0.0344 seconds
hbase:015:0> scan 'Student'
ROW COLUMN+CELL
0 row(s)
Took 1.4201 seconds
hbase:016:0>
我们可以看到虽然表的结构还在,但没有任何的数据
5.2.3.6 count命令
用于统计表的行数
hbase:049:0> count 'SC'
6 row(s)
Took 0.0189 seconds
=> 6
hbase:050:0> count 'Student'
0 row(s)
Took 0.0093 seconds
=> 0
hbase:051:0> count 'Course'
3 row(s)
Took 0.0232 seconds
=> 3
hbase:052:0>
最后!最后!最后!
当然要保持良好的习惯,依次关闭Hbase和Hadoop
master@VM-0-12-ubuntu:/opt/hbase/bin$ stop-hbase.sh
stopping hbase.............
127.0.0.1: running zookeeper, logging to /opt/hbase/bin/../logs/hbase-master-zookeeper-VM-0-12-ubuntu.out
127.0.0.1: stopping zookeeper.
master@VM-0-12-ubuntu:/opt/hbase/bin$ cd /opt/hadoop/sbin/
master@VM-0-12-ubuntu:/opt/hadoop/sbin$ ./stop-all.sh
WARNING: Stopping all Apache Hadoop daemons as master in 10 seconds.
WARNING: Use CTRL-C to abort.
Stopping namenodes on [localhost]
Stopping datanodes
Stopping secondary namenodes [VM-0-12-ubuntu]
Stopping nodemanagers
Stopping resourcemanager
master@VM-0-12-ubuntu:/opt/hadoop/sbin$ jps
263237 Jps
master@VM-0-12-ubuntu:/opt/hadoop/sbin$
呜呜呜这次stop-hbase.sh竟然成功了,狠狠地感动了
我猜想是因为之前的时候没有改那个配置去解决jar的冲突
所以就导致zookeeper其实一直找不到Master服务器
所以既然数据的操作都不行,关闭集群的命令又怎么能成功
HBase轻松入门之HBase架构图解析 ↩︎
ERROR: org.apache.hadoop.hbase.ipc.ServerNotRunningYetException: Server is not running yet ↩︎
Hadoop namenode无法启动 ↩︎
单机版以及伪分布式版Hbase配置及常见问题解决办法 ↩︎
https://blog.csdn.net/cy_walker/article/details/40143211 ↩︎
hadoop问题之hbase ↩︎
HBase shell执行脚本(批量添加数据) ↩︎