互联网的智算架构设计
前言
什么是人工智能?当被问到这个问题时,我们很容易联想到一个例子:给计算机发一张图片,计算机根据图片中的一些特征,判断图片中这个动物是猫还是狗。说到AIphaGo,我想你也不会陌生,“17年3:0完胜世界冠军柯洁”让大家真切感受到AI的威力。这两个看似天差地别的例子,其实可以用一种模型来表述,那就是分类。不同的是前面的结果队列只有两个参数:猫/狗,要么是[1,0],要么是[0,1],而AIphaGo的结果队列,可以有19*19个参数之多。2017年人工智能首次被提升到国家战略层面,随后几年各地更是围绕人工智能开展了诸多技术化、产业化布局。
在互联网行业,人工智能更是涉及方方面面:人脸识别、语言处理、自动驾驶、智能推荐…承载AI集群的基础设施我们称之为“智算中心”,本文我将为大家介绍互联网智算架构的一些知识。
大模型
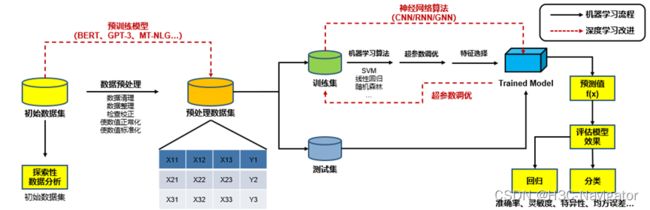
机器学习(ML)是人工智能中很重要一部分,而深度学习(DL)则是机器学习中很重要的组成。但是在2020年以后,越来越多的业务开始应用Foundation Models,也被称为“大模型”。
下图是ML/DL的处理流程示例:
对比ML,DL将诸多算法统一成神经网络算法,包括CNN(卷积神经网络)、RNN(循环神经网络)以及GNN(图形神经网络)等,不同的神经网络模型在不同的训练场景能带来不一样的效果。
DL的另外一个升级点就在于数据预处理阶段:业务产生的带标签的数据是极其缺乏的,更多的数据是来自互联网上的无标签数据,此时我们需要一个模型进行数据的预处理或者无标签训练,我们熟知的BERT、GPT-3、MT-NLG…就是这种预训练模型。
大模型往往以模型参数多、神经元数量多、神经网络层数多而著名,在这些因素的加持下,“大规模数据+大模型”的模式越来越多得被应用到诸多互联网公司的智算架构中。
分布式部署
“大模型”究竟有多大?我们通过一个例子来感受一下:
OpenAI发布的GPT-3,一经面世震惊AI界,它包含1750亿个参数,这让神经网络之父Geoffrey Hinton不禁感叹“鉴于 GPT-3 在未来的惊人前景,可以得出结论,生命、宇宙和万物的答案,就只是 4.398 万亿个参数而已”。然而完整训练一次GPT-3所耗费的算力也是惊人的,按照NVIDIA的数据:训练一次大型GPT-3,使用2w颗A100需要消耗5天时间,使用2w颗H100也需要消耗19个小时,整体消耗算力可达10EFlops-Days!这显然不是一颗GPU或者一台GPU节点所能承载的,因此分布式成为AI集群的主流部署模式。
梯度下降是AI训练中进行参数迭代的最常用手段,正常来讲我们会把所有资料集N计算一次算出一个Loss,但是这样的做法耗时耗力且结果一般。因此实际训练中,我们会把N划分成若干的子集,我们称之为Batch。通过一次Batch运算计算出一个Loss,根据这个Loss完成一次参数迭代,然后进行下一个Batch运算,依次进行…直到所有Batch运算完成。这样所有的Batch都过完一次,我们称之为1 epoch。整个过程如下图所示:
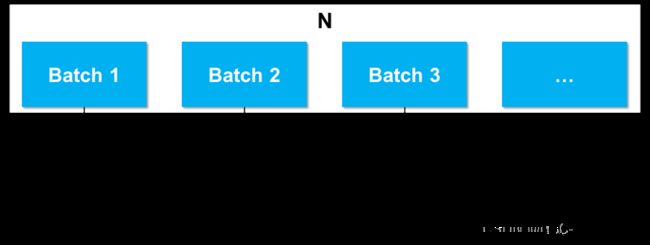
以上是模型训练的一个逻辑思路,然而实际的集群中需要充分利用好GPU资源,以高效率、高利用率以及高准确率的准则完成AI训练。
那么真实的AI分布式集群是怎样的呢,请看下图:
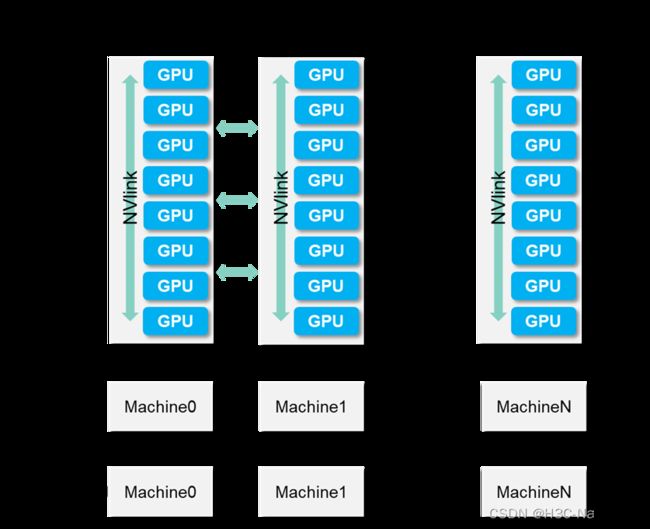
这里边涉及三个概念:模型并行、数据并行以及流水并行。根据算法的大小,可以选择性得采用其中一种或两种并行方式,但是“大模型”训练往往都会应用到三种并行方式。我们会将这个AI集群划分为若干Stage,每个Stage对应一个逻辑上的Batch,每个Stage由若干台GPU节点组成。
数据并行:相同的模型分布在同一个Stage的不同GPU节点上,在不同的节点上使用不同的数据进行训练。模型并行:在某GPU节点将模型切分到不同的GPU卡上,减少单卡参数量。流水并行:基于模型并行,一个batch结束前开始下一个batch,以充分利用计算资源,减少时间空隙。
数据通信
在一个GPU节点内部,不同GPU卡上的张量切片需要汇总,这部分数据通信依靠Nvlink进行;在一个Stage集群中,不同GPU节点之间的模型参数需要同步,这部分数据通信需要依靠外部网络;不同Stage之间需要进行Forward pass和Backward pass的梯度传递,也需要依靠外部网络。接下来我们依次介绍一下不同阶段的数据通信情况。
1. GPU节点内部通信
GPU节点内部的通信分为两种情况,一种是GPU卡之间的通信,这部分数据通信当前主要是通过NVlink实现。

上图展示的是HGX A100 8-GPU 的GPU Baseboard,8块A100 GPU通过NVlink实现高速互通。
GPU节点内部通信另外一种情况是GPU与CPU、内存、硬盘、网卡之间的通信,此时就需要对整个GPU节点架构进行多方维度的考虑和设计。我们以H3C R5500 G5为例进行介绍:

H3C UniServer R5500 G5是H3C推出的基于HGX A100 8-GPU模块完全自主研发的6U、2路GPU服务器,该服务器适用于虚拟化、高性能计算(HPC)、内存计算、数据库、深度学习和超大规格并行训练等计算密集型场景,具有计算性能高、功耗低、扩展性强和可靠性高等特点,易于管理和部署,可满足高性能超大规模并行训练应用。
我们一起看一下该GPU服务器的拓扑设计:
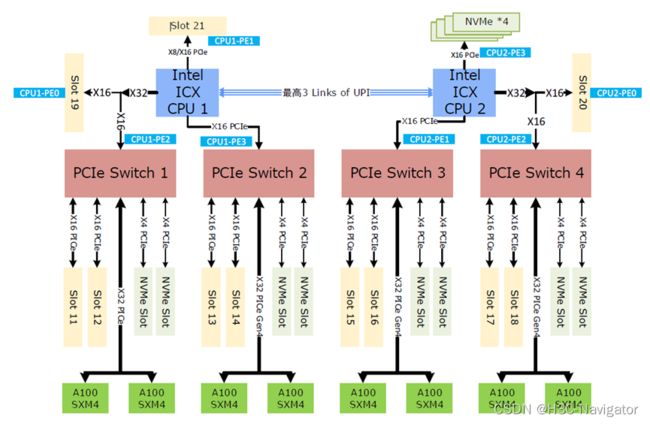
服务器节点中内嵌多组PCIe Switch,可以实现GPU卡与其他组件的高速互联:与Slot 11-18的网卡互联、与NVMe Slot的硬盘的高速互联,GPU卡能够快速访问到放置在NVMe硬盘中的Batch信息。如此一套架构设计,实现了GPU节点内各组件的高速互联,也正因如此,该产品在互联网主流AI场景中的算力表现极为优秀:
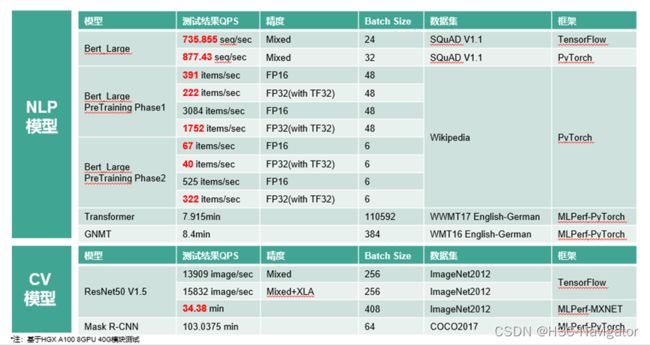
H3C可以为互联网公司提供多样化、定制化的AI解决方案:

2. GPU节点外部通信
上边我们谈到的AI分布式部署集群里,数据并行以及流水并行都需要不同GPU节点之间数据的高速互访。数据并行主要解决的是梯度汇总的问题,流水并行则解决的是梯度传播的问题。
梯度汇总比较好理解,在Stage内部是采用不同的数据对同一个模型分段进行训练,训练完成后该Stage输出的是所有GPU节点汇总的参数信息。
说到梯度传播,就必须要说一下模型训练中常用的反向传播:

如图所示,在模型训练中我们会首先定义Loss函数,θ则是所有参数的合集,因此模型的训练就相当于我们找到一个θ集,可以让Loss函数值最小。我们将模型切分若干个C,因此找到所有C的最小值求和便是L的最小值。求最小值的过程也可以看成微分计算的过程:以θ中的w参数为例,∂C/∂w便是微分计算,我们将∂C/∂w拆分成∂z/∂w*∂z/∂w,此时∂z/∂w就是一个正向梯度的过程,而∂z/∂w则是一个反向梯度的过程。之所以这样做,是因为正常计算流程需要把多层神经网络计算完成后才能进行一次正向求导,这样会极大降低效率,而反向梯度的应用,会使得我们求解Loss函数变得更为高效。
以上就是反向梯度的一个简介,我们可以看到,整个过程中同层神经网络或者不同层神经网络之间一直都在进行数据传输或者参数传输,这些数据通信大部分都是跨计算节点进行的。因此,为了保障模型训练效率,需要给AI集群构建一个低延时的高性能网络。在以太网领域,这个高性能网络就是RoCE网络,由于篇幅原因,就不在这展开RoCE的介绍了。
结合在网络领域的探索,我们设计了一套智算中心无损网络整体拓扑:
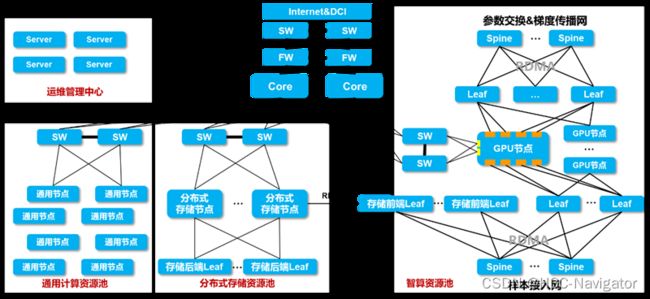
该架构整体可分为以下几个区域:智算资源池、分布式存储资源池、通用计算资源池、数据传输网以及运维管理中心。其中智算资源池又分为参数交换&梯度传播网、样本接入网,这两部分都需要使能RoCE,打造低延时无丢包高性能网络,从而保障AI集群的高效率。
在互联网行业中,大规模、高吞吐是主流,因此在智算资源池的网络设计中,互联网有其独到的设计:
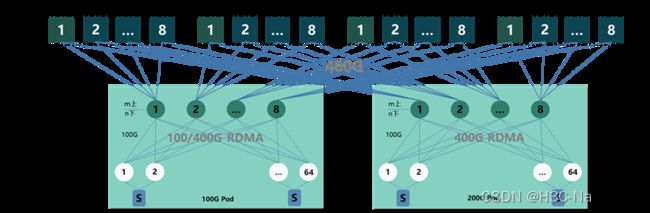
整体组网分为Spine/Leaf/TOR三层:在100G Pod中,Spine采用S9825-64D设备,TOR采用S9820-8C/S9820-8M/S9855-48CD8D设备,Leaf采用S9825-64D/S9820-8C/S9820-8M设备;在200G Pod中,Spine和Leaf采用S9825-64D设备,TOR采用S9820-8C/S9820-8M/S9855-24B8D设备,S9820款型采用400G一分二的形式。
与此同时,部署一个RoCE网络也绝非易事,需要结合不同的业务流特征灵活调整Buffer水线,否则难以达到最佳效果,为此H3C推出了SeerFabric智能无损解决方案,除了解决基本的RoCE自动化、RoCE可视、RoCE分析以及RoCE调优问题,还提供AI ECN智能调优模块:
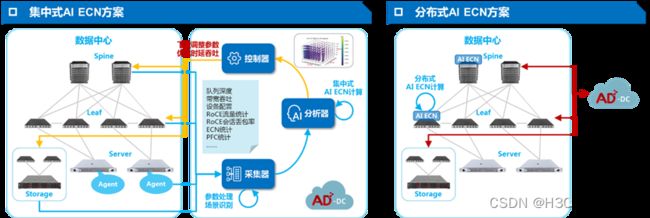
通过SeerFabric可以降低部署RoCE网络的门槛,提高部署效率,配合H3C丰富多样的400G/200G/100G网络产品,可以最大的释放网络的潜力,提高AI集群的运行效率。
3. AI框架
前边我们聊完了整个AI集群的大致架构,然而要知道,充分调动如此庞大规模的AI集群绝非易事。整个系统的高效运行如果都需要我们自己去考虑,这会占用开发人员太多精力,如同云计算时代出现OpenStack、容器时代出现kubernetes一样,AI时代也拥有它专属的操作系统:AI框架。
AI框架是 AI算法模型设计、训练和验证的一套标准接口、特性库和工具包,集成了算法的封装、数据的调用以及计算资源的使用,同时面向开发者提供了开发界面和高效的执行平台,是现阶段AI算法开发的必备工具。信通院给出了一个标准的AI框架应该具备的能力:
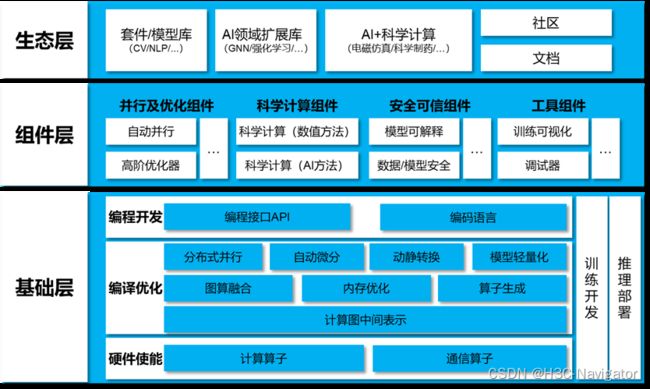
业内比较知名的AI框架有TensorFlow和PyTorch,产业界倾向于TensorFlow,学术界则倾向于PyTorch。这两个框架并非完美的,业界为了补充某些领域的缺陷还在不断推出各种各样的AI框架,我们期待最终能够有这样一个AI框架可以一统江湖,可以将各种能力场景都集合在内。这部分的知识大家感兴趣也可以自己去探索,能够更容易让我们理解AI的运行过程。
展望
人工智能发展至今,虽然在算法、算力、数据这三大马车方面的发展趋势猛进,然而AI真正要赋能产业、赋能社会还有许多路要走。比如在工程层面:需要考虑各企业框架的适用性、需要考虑全生命周期的维护、需要考虑AI的自动化运维。再比如在安全层面:需要考虑AI领域的可信计算、需要考虑安全与性能的平衡…