【Spring Cloud】Nacos及Ribbon组件的使用

欢迎来到我的CSDN主页!
我是Java方文山,一个在CSDN分享笔记的博主。
推荐给大家我的专栏《Spring Cloud》。
点击这里,就可以查看我的主页啦!
Java方文山的个人主页
如果感觉还不错的话请给我点赞吧!
期待你的加入,一起学习,一起进步!

前言
这篇文章主要讲解SpringCloud中的两个组件Eureka和Ribbon,教会大家在项目的过程中如何使用这两个组件以及更加深入的了解这两个组件的作用是什么?话不多说上代码!!
✨环境配置
首先我们需要一个SpringCloud作为我们的父项目,将子项目写在父项目中并继承即可,父项目的作用就是提供公共的依赖。
创建Maven项目
直接新建一个Maven项目即可

项目定义版本
现在版本更新迭代的非常快,所以使用什么版本也需要有要求,否则就会不兼容,以下是相应Boot与Cloud的版本对照,提供大家参考

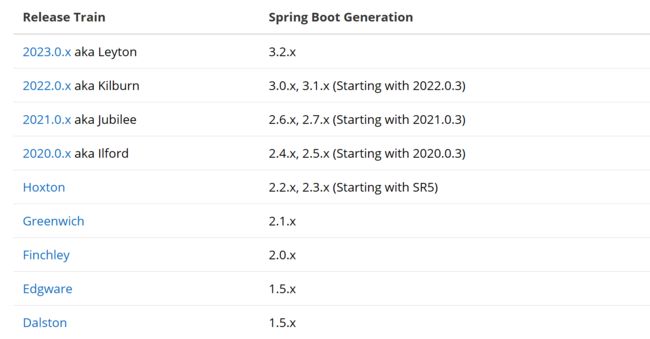
选择好自己需要的版本就可以为其定义了
4.0.0
org.example
Cloud
0.0.1-SNAPSHOT
pom
2.4.1
2020.0.0
2021.1
org.springframework.boot
spring-boot-dependencies
${spring-boot.version}
pom
import
org.springframework.cloud
spring-cloud-dependencies
${spring-cloud.version}
pom
import
com.alibaba.cloud
spring-cloud-alibaba-dependencies
${spring-cloud-alibaba.version}
pom
import
packing( 打包类型 , 默认为 jar)pom : 父级项目 (pom 项目里没有 java 代码 , 也不执行任何代码 , 只是为了聚合工程或传递依赖用的 )jar : 内部调用或者是作服务使用war : 需要部署的项目
创建子项目
这里有两个身份项目,一个是生产者另一个是消费者,分别扮演不同的模块或不同服务
生产者项目创建

现在我们的子项目创建出来了,但是它和父项目还没有任何关系,所以我们还需要让它继承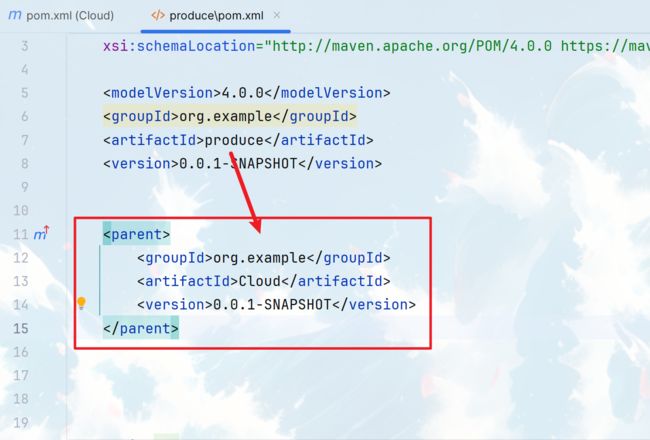
org.example
Cloud
0.0.1-SNAPSHOT
不但子项目要继承父项目,父项目那边也需要定义子项目才能双向奔赴
produce
消费者项目创建
该项目直接复制生产者项目即可,随后将“produce”改为“consume”

✨Nacos案例实操
环境我们已经搭建好了,现在我们来讲解一下我们这两个组件的使用,我们先为生产者创建一个controller编写一个方法生成鸡腿的方法
@RestController
public class ProduceController {
@RequestMapping("/run")
public String run() {
return "";
}
}然后我们消费者也创建一个controller编写一个获取鸡腿的方法
@RestController
public class ConsumeController {
@RequestMapping("/run")
public String run() {
RestTemplate restTemplate = new RestTemplate();
return restTemplate.getForObject("http://localhost:8082/run", String.class);
}
}运行测试一下

成功获取到了我们的鸡腿,但是这样的方法真的合适吗?如果在开发过程中先不谈我们如何知道对方服务的接口是什么,就算知道了在方法很多的情况下一个个写也是非常的麻烦,这就不得不提到我们的Nacos,它可以用于实现动态服务发现、服务配置和服务管理。
Nacos下载
我们使用Nacos首先需要下载Releases · alibaba/nacos · GitHub
我这里下载的windows版本的,不需要安装,下载好直接解压,然后到bin目录下,执行startup.cmd -m standalone启动即可。 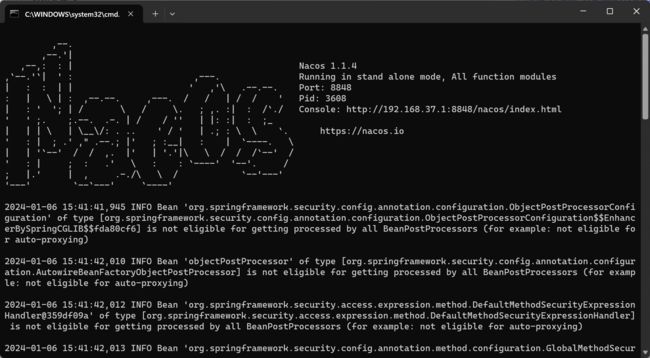
命令运行成功后直接访问http://localhost:8848/nacos默认账号密码都是nacos

文件配置
①要想我们的项目注册到nacos就需要做相应的配置,在application.yml编写一下内容,其中name就是我们项目注册到nacos中的名字
spring:
cloud:
nacos:
discovery:
server-addr: localhost:8848
application:
name: consume②文件配置了但spring怎么读取呢?我们现在还需要导入一个nacos依赖(可写在父项目)
com.alibaba.cloud
spring-cloud-starter-alibaba-nacos-discovery
③打开我们的nacos服务,需要在每个启动器上加上下面这个注解
@EnableDiscoveryClient再次启动我们的项目,就会发现项目注册到Nacos中去了
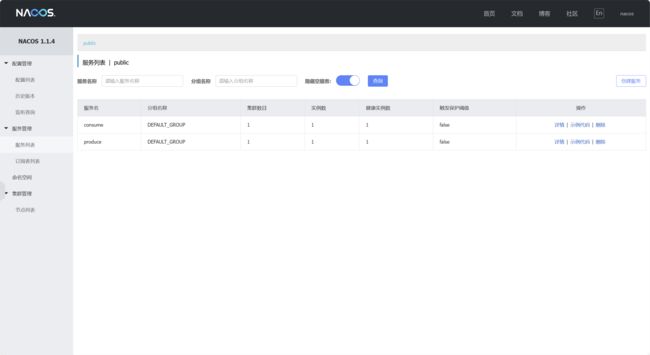
这时候我们也可以使用服务名进行服务发现与调用了

✨Ribbon案例实操
虽然我们的服务可以实现动态发现了,但还有一个问题,万一别人的服务器部署了很多呢?那我们的请求怎么知道该向那个服务发送请求呢?这时Spring Cloud Ribbon就派上用场了。Ribbon就是专门解决这个问题的。它的作用是负载均衡,会帮你在每次请求时选择一台机器,均匀的把请求分发到各个机器上。
依赖引入
org.springframework.cloud
spring-cloud-loadbalancer
负载均衡
@LoadBalanced注解表示该RestTemplate对象将使用负载均衡器来分配请求,以便在多个服务实例之间分配请求。在使用Spring Cloud的服务发现和注册功能时,这个注解通常与Ribbon负载均衡器一起使用,以确保请求被均匀地分配到不同的服务实例中。
默认情况下,RestTemplate对象不会使用负载均衡器,而是直接向指定的URL发送请求。通过添加@LoadBalanced注解,Spring将为RestTemplate对象创建一个代理,该代理会自动将请求发送到负载均衡器,并根据特定的负载均衡策略选择一个可用的服务实例来处理请求。
@Configuration
public class RestConfig {
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}
}因为RestTemplate已经加到Spring中去了,那我们也不需要new出来了,直接引用即可
@RestController
public class ConsumeController {
@Autowired
RestTemplate restTemplate;
@RequestMapping("/run")
public String run() {
return restTemplate.getForObject("http://produce:8082/run", String.class);
}
}下面我们做一个测试首先将两个服务分别打成jar包
使用我们的终端运行jar(生产服务运行多个模拟负载均衡)
 现在我们看一下nacos的服务,可以看到生产服务有三个
现在我们看一下nacos的服务,可以看到生产服务有三个

Ribbon的负载均衡默认使用的最经典的Round Robin轮询算法。这是啥?简单来说,就是如果订单服务对库存服务发起10次请求,那就先让你请求第1台机器、然后是第2台机器、第3台机器、第4台机器、第5台机器,接着再来—个循环,第1台机器、第2台机器。。。以此类推。如果其中一个挂了就不会给它发送请求了
到这里我的分享就结束了,欢迎到评论区探讨交流!!
如果觉得有用的话还请点个赞吧