第4章 介绍Python对象类型
看前须知
这里对本书中提到的不常见的内容进行了查证,举例,所以大家可以不用再费神去搜索相关内容
在Python中,我们运用“材料”来处理“事务”。
材料:操作对象,数据等
事务:加减乘除,拼接等
在Python中,数据以对象的形式出现,无论是Python提供的内置对象,还是使用Pyrhon或是像C扩展库等扩展语言工具创建的对象。对象是内存中的一部分,包含数值和相关操作的集合。
Python脚本中的一切都是对象。甚至简单的带有值(如99),或支持运算操作(加减乘除)的数字。
对象是Python中最基本的概念,这章将全面的体验Python的内置对象类型。
Python知识结构
Python的全貌:Python程序可以分解成模块、语句、表达式、对象。
· 程序由模块构成
· 模块包含语句
· 语句包含表达式
· 表达式创建并处理对象
本章将探索在编程过程使用的内置对象和表达式
在下一部分学习语句,语句是在管理对象。
在接触本书的“面向对象编程”的对象时,会发现我们是在模仿Python的内置对象类型来定义属于我们自己的对象类型。
在传统编程中,编程的三大支柱:顺序语句、选择语句、循环语句。
在Python中拥有全部这三类语句,同时也有一些相应的定义:函数和类。这些概念能帮你更早地建立思维模式,他们相对精巧和简洁。
列表推导的复杂表达式就是循环语句和选择语句的结合。而Python中的部分术语可能有多重含义。但在Python中,更为统一的原则就是对象,以及对象的操作。
为什么要使用内置类型
如果你是用过较底层的编程语言(C、C++,高级语言但对底层有良好衔接),应该知道很大一部分工作集中于使用对象(数据结构)去表现应用领域的组件。你需要部署内存结构、管理内存分配、实现搜索和读取例程等基础的操作,而Python则将这些操作整合成了内置类型,除非你有内置类型无法提供的特殊对象要处理,否则最好使用内置对象而不是用自己的实现。
· 内置对象使程序更容易编写。
对于简单的任务,内置类型往往能够表现问题领域的所有结构。Python直接提供了强大的工具,例如集合(列表)和搜索表(字典),你可以立即使用他们。仅是使用Python内置对象类型就能够完成很多工作。
· 内置对象使可扩展的组件。
对于较为复杂的任务,或许仍需要使用Python的类或C语言的接口提供你自己的对象。但我们手动实现的对象往往也是建立在内置类型的接触之上的。
· 内置对象往往比定制的数据结构更有效率。
Python的内置类型使用了已优化的用C实现的数据结构算法,尽管你可以实现属于自己的类似的数据类型,但往往很难达到内置数据类型所提供的性能水平。
· 内置对象是语言标准的一部分。
Python不但借鉴了一开内置工具的语言(如LISP),而且汲取了那些依靠程序员提供自己实现的工具或框架的语言(如C++)的优点。而且Python的内置工具使标准化的,一致的。
与我们从零开始创建的工具相比,内置对象类型不仅仅让编程变得更简单,而且他们也更强大和更高效。无论你是否实现新的对象类型,内置对象都构成了每一个Python程序的核心部分。
Python核心数据类型
内置类型,字面量(literal):字面量(literal)用于表达源代码中一个固定值的表示法(notation),整数、浮点数以及字符串等等都是字面量。字面量就是没有用标识符封装起来的量,是“值”的原始状态。
| 对象类型 | 字面量/构造示例 |
|---|---|
| 数字 | 1234,3.1415,3+4j,0b111,Decimal(),Fraction() |
| 整数、浮点数、复数、二进制、高精度浮点数、分数 | |
| 字符串 | ‘spam’,“Bob’s”,b’a\x62c’,u’sp\xc4m’,r’a\b\c’ |
| 字符串,单双引号的应用,二进制、unicode、忽略转义 | |
| 列表 | [1,[2,‘three’],4.5],list(range(10)) |
| 示例,构造,range函数 | |
| 字典 | {‘food’:‘spam’,‘taste’:‘yum’},dict(hours=10) |
| 示例,构造 | |
| 元组 | (1,‘spam’,4,‘U’),tuple(‘spam’),namedtuple |
| 示例,构造,具名元组 | |
| 文件 | open(‘egg.txt’),open(r’C:\ham.bin’,‘wb’) |
| 集合 | set(‘abc’),{‘a’,‘b’,‘c’} |
| 其他核心类型 | 类型、None、布尔型 |
| 程序单元类型 | 函数、模块、类 |
| Python实现相关类型 | 已编译代码、调用栈跟踪 |
对于一些读者来说,表中的对象类型可能比你习惯的类型更通用也更强大。
例如,列表和字典就是强大的数据表现工具,省略了在使用低层语言的过程中为了支持集合和搜索而引入的绝大部份工作。列表提供了掐他对象的有序集合,而字典通过键存储对象。列表和字典都可以嵌套,可以随需求扩展和删减,并能够包含任意类型的对象。
字面量,常量和变量之间的区别
总结:字面量就是只能是赋值表达式中,在等号右侧的量。而对应着他,在等号左侧的就是变量。在Python中,很难说常量,一些模块中给一些变量赋值,看似常量,但是很多情况这个常量的值是可以再被赋值所改变的。例如pi。
>>> import math
>>> math.pi
3.141592653589793
>>> math.pi=3.14
>>> math.pi
3.14
而在C中,定义常量是可以被保护为只读的
const int i = 5;
而在Python中没有这个功能,虽然有网友自己定义了一个
Py tricks(1): python实现不可修改的常量
上表中,像函数、模块和类这样的编程单元,在Python中也是对象。
他们由def、class、import、lambda这样的语句和表达式创建,可以在脚本间自由的传递,存储在其他对象中,等等。
Python还提供了一组与实现相关的类型,例如编译过的代码对象,他们通常更多的关系到工具生成器而不是应用程序开发者?
这里不是很明白到底表达的什么意思,说的对象是.pyc等字节码,他们无法被修改,只是拿来用,所以只是工具?
选读:python里的强大工具生成器–yield
表中的内容并不一定完整,因为在Python程序中处理的每样东西都是对象。例如,在Python中进行文本模式匹配时,创建了模式对象(例如对文本的描述,或是处理描述的算法、函数,都是对象,只要是有形之物,都是对象);进行网络脚本编程时,使用了套接字对象。
这些其他类型的对象往往都是通过模块中导入或使用函数来建立的,例如在re和socket模块中的模式和套接字。而且他们都有各自的行为。这个就像是表中提到的Decimal()和Fraction(),这两个分别是decimal和fractions模块导入后,才能实现的类型,有自己的表达和计算方法。
通常把表中的对象类型乘坐核心数据类型,因为他们是在Python语言内部高效创建的,有一些特定语法可以生成他们:
>>> 'spam'
你正在运行一个字面量表达式,这个表达式生成并返回一个新的字符串对象。
这是Python用来生成这个对象的一个特定语法。类似的:[1] 列表,{‘a’:1} 字典,{1} 集合。
Python没有类型声明,运行的表达式的语法决定了创建和使用的对象的类型。
表中,那些对象生成表达式就是这些类型起源的地方。
一旦创建了一个对象,他就和操作集合绑定了,你只能对字符串进行字符串相关的操作,对列表进行列表相关的操作:
Python是动态类型的(他自动的跟踪你的类型而不是要求声明代码),但是他也是强类型语言(你只能对一个对象进行适合该类型的有效操作)。
>>> a=1+'1'
Traceback (most recent call last):
File "" , line 1, in <module>
TypeError: unsupported operand type(s) for +: 'int' and 'str'
弱类型 js、vbs:
>>> var a=1+'1'
>>> a
'11'
【转】静态类型语言的优势究竟是什么?已经有些年头了,不过感觉还不错。:总结
1、静态语言因为定义变量类型严格,而效率高:
我需要镊子,给你镊子。我需要一个金属制品,这样的,这样的,我猜你大概需要一个镊子。
每次执行时,程序需要考虑的东西的量就不一样,而且还附带着那些量后面的一堆东西,于是无论运行速度,还是执行模式代码的占用空间都不一样。
2、静态语言因为定义变量类型严格,而出错少:
当每条语句都要求必须是这样那样的类型时,他的如果存在潜在的bug,就会越早的暴露、被抹去。这使得成品有相对动态语言更强的可靠性。
(动态类型/静态类型)、(强类型/弱类型)、(编译/解释)
数字
Python的核心对象集合包括常规的类型:
整数(没有小数部分的数字)
浮点数(有小数部分的数字)
有虚部的复数
固定精度的十进制数
带分子和分母的有理数
以及全功能集合
Python内置的数字类型足以表示从你的年龄到你的银行存款的绝大部分数值量,同时还有第三方库提供更为强大的功能。
支持的运算:+ 加、- 减、* 乘、/ 除、**幂、%取余(模)等等,下一章将详细介绍数字类型这里只是简介
>>> 123+222
345
>>> 1.5*4
6.0
>>> 2**100
1267650600228229401496703205376
>>> 2**1000
10715086071862673209484250490600018105614048117055336074437503883703510511249361224931983788156958581275946729175531468251871452856923140435984577574698574803934567774824230985421074605062371141877954182153046474983581941267398767559165543946077062914571196477686542167660429831652624386837205668069376
>>> len(str(2**1000000)) #得出结果的显示的字符串长度,即位数的个数
301030
Python 十进制转二进制
很多类型都支持str和len,如果一些数值的意思得和打印的不一样,可以使用repr,他能展示数值的真实状态
上述的len、str代码,首先将运算结果利用内嵌的str函数转换成字符串,接着用len函数得到该字符串的长度。最后的结果就是位数的个数。
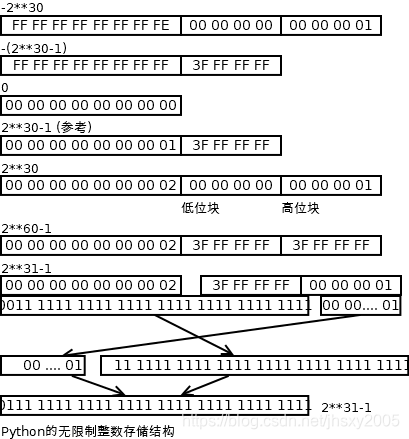
扩展阅读:Python的无限制边界的整数结构
>>> import sys
>>> t=0;i=0
>>> while t<100:
... if (s:=sys.getsizeof(2**i))>t:
... t=s
... print(i,'\t',s )
... i=i+1
...
0 28
30 32
60 36
90 40
120 44
150 48
180 52
210 56
240 60
270 64
300 68
330 72
360 76
390 80
420 84
450 88
480 92
510 96
540 100
在C和Java中,整数型都有特定长度的,整数型也因为存储长度和符号而取值范围不同。
但在Python中,整数型是没有长度限制的,限制整数长度的只有内存这个因素。
如上代码,整数的二进制长度每增加30位,存储就会增加4个字节,即32位。
def int_RAM():
大小端转换:struck !、字符串i:i+2、binascii.hexlify(binascii.unhexlify(data)[::-1])
python中如何查看指定内存地址的内容
1、读取内存中,整数相关的存储信息
随机生成整数,赋值给变量num
获取变量在内存中的地址,addr=id(num)
获取变量在内存中的占用空间,size=sizeof(num)
读取内存数据,btyes_=string_at(addr,size)
内存数据转HEX模式,btyes_.hex()
2、对HEX模式的字符串进行分割
上述整数,自1开始,每增加*2**30,存储就会增加4字节,虽然逻辑上觉得4字节是一个单位,每个字节串是小端存储,而每4个字节为一单位的单位间,也类似小端存储,但是在我写了一个模拟的转换程序后,发现其实数值部分,即这些4字节部分,是一条连贯的字节串,一个个的大小端转换后,结果就是一整条字节串的大小端转换:
l=list(range(16))
l1=[]
for i in range(0,len(l),4):
l1=l[i+3:-(len(l)-i)-1:-1]+l1
l
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]
l1
[15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
这里的l[i+3:-(len(l)-i)-1:-1]是我经过一番探究后,最兼容也最低效的写法,简单的理解,相当于l[i:i+4][::-1],即每次读取4个字节,每次又把这4个字节逆转大小端,接下来是下4个字节,而这4个字节放在之前的4个字节前面。但结果其实就是整条逆转大小端。如果不是为了展示逆转后的每4个字节的两个空比特,4字节读取的同时可以去掉两个空比特,传递给新的比特串,若带着两个空比特逆转,完全可以一次性的逆转整个字节串。
Python 整数类型的内存读取和结构分析 代码
继续
>>> 3.1415*2
6.2830000000000004
>>> print(3.1415*2)
6.283
这是Python3.1前的版本显示
>>> 3.1415*2
6.283
>>> repr(3.1415)
'3.1415'
这是之后版本的显示,但实际上,按照内存中的结构的话,差一点的
>>> 3.1415*2
6.283
>>> repr(3.1415)
'3.1415'
0100000000001001001000011100101011000000100000110001001001101111
底数区数值:1.5707500000000001
但是即便把这个数值复制出来,最后的小尾巴也是不存在的,大概是特有的舍去机制
扩展阅读:Python的float结构

我在之前的分析整数的代码中添加了暴力大小端转换数据区的部分,显示了大端序的hex和bin,和单精度浮点数并不一样!
>>> 0.5
0011 1111 1110 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000
>>> 1.0
0011 1111 1111 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000
>>> 3.1415
0100 0000 0000 1001 0010 0001 1100 1010 1100 0000 1000 0011 0001 0010 0110 1111
>>> 2.0
0100 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000
0.5在浮点数中是一个特殊的存在,因为在浮点表示时,1.0的数值区是0,指数区是‘0’,1.0是会在数指转换后,默认被加上去的
而浮点数的数值区第一个位到之后位的数值表示意义是:2**-1, 2**-2, 2**-3…,0.5正是2**-1 * 1,指数区是-1,数据区(底数)是1,而1在数据区的表示是0,所以与1.0的差别是指数区少一个1。用此可以验证该浮点数是否符合浮点数转换规则。
1.0 = 1*10**0
0011 1111 1111 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000
第一个0表示正数
后面的011 1111 1111,表示10**0,10**e,而011 1111 1111,即2**
python - 接近完美的单精度浮点数转换代码
0.5
0 0111 1110 000 0000 0000 0000 0000 0000
1.0
0 0111 1111 000 0000 0000 0000 0000 0000
这个是单精度的浮点数结构,1比特的负号,8比特的指数,23比特的底数,共32位。
指数区取值范围是2**-127 ~ 2128
数据区取值范围是0~(2-1+2**-2+…+2**-23)
那相对Python默认float,1比特的负号,11比特的指数,52比特的底数,共64位。是双精度符号位。
指数区取值范围是2**-1023 ~ 21023,即
数据区取值范围是0~(2-1+2**-2+…+2**-52)
最大取值是,12**1024(2**-1+2**-2+…+2**-52)
f=0
for i in range(0,53):
t=f
f+=2**(i*-1)
print(t,'\n',f)
1.9999999999999996
0011 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1110
1.9999999999999998
0011 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111
在码上面的一段时,我发现了之前的代码的一个bug,还发现了一个理解方式。
关于那个数值区计算后再加上个1的认知,可以理解为,二进制的数值区的那个隐性的1.0就是20,数值区第一位就是2-1,所以不需要专门的去加1,而是从2**0开始计算即可,而这个0是隐形于数值区的!
inf: 7ff0000000000000 0111 1111 1111
nan: 7ff8000000000000 0111 1111 1111 1
-inf: fff0000000000000 1111 1111 1111
Python中定义7ff为正无穷:float(‘inf’)
所以最大指数只能到111 1111 1110,即2**1023
而nan只不存在的书,即比正无穷大的数是不存在的
inf带上符号就是负无穷了
以上是只能用float函数生成的特殊数值,无法用表达式赋值,而实际上如果手动修改数据的话
7ff8000000000001 : nan
float(2**1023) # 最大指数
7fe0000000000000
2**-1022
0010000000000000
2**-1023
0008000000000000 1000
2**-1024
0004000000000000 0100
2**-1025
0002000000000000 0010
2**-1023*1.5
000c000000000000 1100
2**-1023*1.75
000e000000000000 1110
2**-1022*1.5
0018000000000000 0001 1000
2**-1024*1.5
0006000000000000 0110
2**-1024*1.25
0005000000000000 0101
从2**-1023,规则变了,如果规则不练,则2**-1023就和0的结构一样,都是一串0
变了之后,可以有很多理解,我的逻辑是,一定出现的第一个1可以当作一个竖杠,前面多出来的x个0,当作2**-x,第一个1后面才开始按之前的逻辑处理。
仅看第一个1,指数最小的情况,就是这个1在末尾,即前面有51个0,即2**-51,此时指数位2**-1074
f=2**-1074
ctypes.string_at(id(f),24)[:15:-1].hex()
Out[276]: '0000000000000001'
2**-1074*0.5
0.0
-2**-1074
8000000000000001
-2**-1074*0.5
-0.0
8000000000000000
此时是无法再添加任何数值了,
即最小的数值是2**-1074,最小的正数是2**-1074,最大的负数是-2**-1074,0不是正数,于是-0也不是负数。
f=0
for i in range(0,-53,-1):
f=2**i+f
>>> f
1.9999999999999998
3fffffffffffffff
2**1023*1.9999999999999998
1.7976931348623157e+308
7fefffffffffffff
最大的数值是21023*(20+2**-1+2**-52)
继续
除了表达式外,随Python一起安装的还有一些常用的数学模块,模块只不过是我们导入以供使用的一些额外工具包。
>>> import math
>>> math.pi
3.141592653589793
>>> math.sqrt(85)
9.219544457292887
math模块包括更高级的数学工具,如函数,而random模块可以作为随机数字的生成器和随机选择器:
>>> import random
>>> random.random()
0.11326180328885771
>>> random.choice([1,2,3,4]) #列表,一个可包含任意类型元素的可变序列
2
Python还包括一些较为少见的数学对象:负数、固定精度十进制数、有理数、集合、布尔值等
和第三方开源扩展领域等:矩阵、向量、可扩展精度的数字、Decimal(高精度浮点数)、Fraction(分数)
到现在为止,我们已经把Python作为简单的计算器来使用。想要更好的利用内置类型,就来看一下字符串
字符串
字符串用来记录文本信息(你的名字)和任意的字节集合(如图片文件的内容)。
书中对字符串的定义包括字符字节串bytes,甚至还有第三方模块bitstring所使用的比特串。无论是str类型的变量还是bytes类型的变量,还是其他基于字符的类型。广义上都是字符串。
字符串是字符序列,它是一种抽象的概念,不能直接存储在硬盘;字节字符串是字节序列,它可以直接存储在硬盘。它们之间的映射被称为编码/解码。在Python中,程序中的文本都用字符串表示。
字节对象在内部是机器可读的形式,字符串仅是人类可读的形式。
我习惯的认为字符串是Python可以自动编解码识别的串,而无法被编解码的串,我习惯称之为字节串,甚至前面扩展内容的代码中还有比特串。但这里意味着所有单一连续的对象都是字符串。而不单一连续的,例如列表,他的实际内容存放的是元素地址,也就是说一串内存并不能完全展示列表的内容。所以不单一,因为通过地址连接元素,所以不连续。
他们是我们在Python中提到的第一个作为[不可变]序列(一个包含其他对象[字符/字节]的有序集合)的例子。序列中的元素包含了一个从左到右的顺序:序列中的元素根据他们的相对位置进行存储和读取。字符串是由单字符所组成的序列。其他更一般的序列类型好包括列表和元组。
序列操作
作为序列,字符串支持假设其中各个元素包含位置顺序的操作。
>>> S='Spam'
>>> len(S)
4
>>> S[0]
'S'
>>> S[1]
'p'
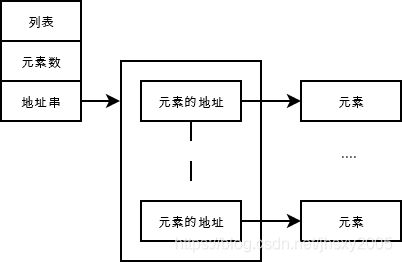
字符串具有不可变性,可变指的是存在改变变量内容而不改变变量地址的方法。而字符串的变量地址,直接包含了字符串的内容,而且不存在方法使得改变字符串内容而不改变地址。
相对可变内容的列表,他的地址中,数据区第一组记录元素数量,第二组指向元素们的地址串,在这个另外的地址中,元素们的地址挨个排列,可变的列表在增加、减少元素时,会改变元素记录数、生成对应的元素、将元素的地址添加入地址组中
在Python中,索引是按照从最前面的偏移量进行编码的,也就是从0开始,第一项索引为0,第二项索引为1,依此类推。
在Python中,不需要提前声明变量,可以直接给变量赋值,给一个变量赋值时就创建了他,可能赋值的是任何类型的对象。之后变量出现在表达式中的时候,就用其值替换它。
在使用变量之前,必须对其赋值。我们需要把一个对象赋值给一个变量,一边保存他供随后使用。
在Python中,我们能够反向索引,从最后一个开始(正向索引是从左边开始,反向索引是从右边开始)
>>> S[-1]
'm'
>>> S[-2]
'a'
负的索引号会与字符串的长度相加:
!!!
>>> S[-1]
'm'
>>> S[len(S)-1]
'm'
我之前在研究逆序的时候,这样思考过,但是个人向的这样思考只是一种思考方式,而老师这么说了,万一Python真的就是这么做的呢,于是就变成了定理
方括号中可以是:字面量、变量、表达式,只要结果能够表示正数,甚至于布尔值都可以
除了索引,序列也支持分片(slice,切片)操作:
>>> S[1:3]
'pa'
从一个字符串中依次就提取出一部分的方法。
X[I:J] 表示“取出在X中,从偏移量为I,直到但不包括偏移量为J的内容”。
结果就是返回一个新的对象。如上,获得了1、2两个字符(1到3的所有字符)作为一个新的字符串。效果就是切片或“分理出”中间的两个字符
在分片操作中,左边界默认为0,又便捷默认为分片序列的长度,于是就有了以下写法:
S[:]
'Spam'
S[1:]
'pam'
S[0:3]
'Spa'
S[:3]
'Spa'
S[:-1]
'Spa'
作为一个序列,字符串也支持使用加号进行拼接(Concatenation),将两个字符串合并成一个新的字符串,或者重复,通过再重复依次创建一个新的字符串。
>>> S
'Spam'
>>> S+'xyz'
'Spamxyz'
>>> S*8
'SpamSpamSpamSpamSpamSpamSpamSpam'
扩展阅读
生成指定内存大小的变量
import mem
mem.mem()
s=' '*2**20*100
mem.mem()
list(s[::-1])
mem.mem()
input()
我写了一段代码,查看切片对于内存的占用,这里的打印结果
内存占用:14.32 MB
内存占用:114.33 MB
内存占用:114.33 MB
我对于切片的写法从s[:],到list(s[:]),因为我很确信切片其实是占用了内存的,只不过因为之上语句上下并没有多出的变量,python迅速清空了无用数据,所以在语句处理完后,内存也被清理,看似内存一样,但使用list语句后,耗时很长,在任务管理器中看到内存一度占用1GB以上。
我有个新想法,于是将上面list语句赋值给变量l,当内存不再增长后,也不会倒退,说明其实list语句从执行到赋值变量,他的空间没有变过。
我的电脑,剩余内存有4G,我生成一个2G的数据,再切片,看看过程变化,再生成一个4G的看看!
如果切片写法是s[:],python是不进行任何处理的,他会把他当作s看待,当指定索引且片段不是整个s时,这个的过程是会生成一个副本的。
如果逆序输出,更是如此。而同一个片段,逆序操作耗时更多。
另,以上操作,例如生成2G大小的字符串,python会先升到2.5G,再落到2G。如果使用s=b’\x00’2**302,生成2G的字节,会先升到3G再落下。如果改写成i=2**30*2;s=b’\x00’*i,则会恰到好处,于是原因应该是运算过程的中间量,学到了!
索引、切片、逆序的关系
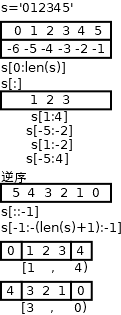
正向索引:len(s)+反向索引坐标,len(s)-|反向索引坐标|
反向索引:len(s)+反向索引坐标,len(s)-|反向索引坐标|
书中提到正向索引,s[:] 默认的两端数值是0、len(s)
这一点在逆序时极为重要
s[::-1] 默认的两端数值就是-1、-(len(s)+1)
如果不使用逆向索引,去写逆序时,s[0]只能用默认的空来表示,这个在数据处理时很不友好,而使用了逆向索引,一切问题迎刃而解。
至于那种写法更效率,我之前写了一堆,貌似用if判断是否是0,拎出来单独一个写法,其他写法则是很普通的过程,反而是最效率的,而搞成很兼容的方法去写,反而不高效,关键是兼容的写法的数值换算。
我一会再对其深入下。
逆向写法的记忆思路:
1、逆向的第一个冒号两边,冒号右侧的索引位置在冒号左侧的索引位置的右边
2、想得到123的逆序,即321,这样在脑中一念叨,自然逆序写法的起始在3,终止在0,而这样想的话,方法1反而没必要了。但这个是写什么,而方法1是怎么写对。
步进,从起点开始,每隔个步进,输出一个对应位置上的元素
索引和range是一致的
range可以当作整数序列,其实他的本质只是一个类型,只存储了元素数、起始、终止、步进这四个元素,但他的写法和索引是差不多的
list(range(0,10))
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> list(range(0,10,-1))
[]
>>> list(range(10,0,-1))
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
range的逆序输出和索引一样,左侧的索引在右侧的索引的实际右侧,记录从左侧的索引开始,不包含第一个逗号右侧索引的元素
索引和二进制转十进制
另外,索引的思路很适合二进制换算,虽然自然看来,二进制的低位是右侧
例如:1010,即8421中的8+2=10
但是我经常误认为,应该是24+22,但应该是23+21
所以先把二进制绑定为索引的思维模式:
1 0 1 0
3 2 1 0
二进制低位到高位,在索引看来,就是从0开始,这也是从0开始的妙处!
多态
加号对于不同的对象有不同的意义:用于数字,表示加法;用于字符串,表示拼接。
这是Python的一般特性,即多态,即一个操作的意义取决于被操作的对象。正如将在学习动态类型时看到的那样,这种多态的特性给Python代码带来了很大的简洁性和灵活性。
由于类型并不受约数,Python编写的操作通常可以自动的适用于不同类型的对象,只要他们支持一种兼容的接口。
寻求帮助
尽管序列操作是通用的,但是方法不通用(虽然某些类型共享某些方法名,字符串的方法只能用于字符串)。
Python的工具库是呈层级分布的:可作用于多种类型的通用操作都是以内置函数或表达式的形式出现的(如len(X)、X[0]),但类型特定的操作是以方法调用的形式出现的(如aString.upper())。如果经常使用Python,你会更顺利的从这些分类中找到你所需要的工具。
本书并不会详尽的介绍对象方法,对于更多细节,你可以调用内置的dir函数。
这个函数列出了在调用者作用域内,形式参数的默认值;他会返回一个列表,其中包含了对象的所有属性。由于方法是函数属性,他们也会在这个列表中。假设S是一个字符串:
每个版本的类中的函数,都可能有所不同,例如我用的3.9.1就比书中版本多了了’__init_subclass__’、‘isascii’、‘removeprefix’、‘removesuffix’
>>> dir(S)
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__',
'__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__',
'__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__',
'__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__',
'__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__',
'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs',
'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isascii', 'isdecimal',
'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle',
'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition',
'removeprefix', 'removesuffix', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition',
'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title',
'translate', 'upper', 'zfill']
也许只有在本书的稍后部分你才会对这个列表的变量名中有双下划线的部分感兴趣,那时我们将在类中学习重载:他们代表了字符串对象的实现方式,并支持定制。例如字符串的__add__方法是真正执行字符串拼接的函数。虽然Python内部将前者映射到后者,但是你也应当尽量避免直接使用第二种形式。
'Spam'+'NI!' # 15.5 ns
'Spam'.__add__('NI!') # 199 ns
s1+s2 # 129 ns
s1+'NI!' # 118 ns
s1.__add__(s2) # 228 ns
行3相对行1是从变量中读取的数据,而行4只有一个数据来自于变量,于是看来,行1全是在核心层的操作,无论是数据还是方法,而其他的都调用了相对较外的操作,例如读取变量内容、读取函数。于是可以推测,即便字符串+的方法却是来自于str.add,但是在Python进程初始化的时候,这些操作就已经从__add__加载到核心中了,所以只有数据和+的操作飞起。同样飞起的操作还有:
if False:pass # 15.5 ns
len(S) # 110 ns
len('Spam') # 91.7 ns
S.__len__() # 126 ns
'Spam'.__len__() # 112 ns
str.__len__(S) # 163 ns
str.__len__('Spam') # 151 ns
一般来说,以双下划线开头并结尾的变量名用来表示Python实现细节的命名模式。而这个列表中没有下划线的属性是字符串对象能够调用的方法。
dir函数简单的给出了方法的名称,要查询他们是做什么的,可以将其传递给help函数:
>>>help(S.replace)
Help on built-in function replace:
replace(old, new, count=-1, /) method of builtins.str instance
Return a copy with all occurrences of substring old replaced by new.
count
Maximum number of occurrences to replace.
-1 (the default value) means replace all occurrences.
If the optional argument count is given, only the first count occurrences are
replaced.
就像PyDoc(一个从对象中提取文档并生成html的工具)意义,help是一个随Python一起安装的面向系统代码的接口。
dir和help,命令都可以作用于一个真实对象(比如这里的字符串变量S或者字符串’Spam’)或是一种数据类型(如str、list和dict)。
其中help命令相对于dir命令而言,在返回相同的函数列表的同时,还提供了完整的类型细节,并允许你使用类名查询一个具体的方法(例如str.replace)。
想获得更多的细节,可以参考Python的标准库参考手册或者商业出版的参考书,但是dir和help提供了Python中最原生的文档。
虽然int和str下都有__add__,他们的说明也一模一样,但是他们的操作过程和意义是不一样的,int的意义是十进制加法,过程是把整数结构转化成二进制并进行二进制加法运算,再返回二进制运算的结果,转化成十进制,其中过程可能比描述的更为复杂。
而str.__add__,是把两个字符串的内容依照次序,复制到一个新的空间中,形成一个新的字符串。当然这个字符串可能立刻就用,然后被清理掉,也可能赋值给一个新的变量,方便重复使用。
因为有时需要int的二进制长度,所以需要len的方法,但是len这个词对于整数没有明确的意义,是指整数的位数(个十百千),还是对应的二进制长度,还是整数结构的长度,作为高级语言,我也不鼓励大家研究类型在内存中的结构,因为我为此前后被坑过一周多了,虽然现在玩的比较遛,但是Python的其中一个目的就是不需要我们关注类型和内存的细节,但我忍不住…
咳咳~ 所以int中,没有__len__,但是有一个专属的bit_length。而sys模块中有一个相对于python系统的getsizeof来获取变量的所占空间,计算方法貌似是设计双层结构,例如列表,一层结构是固定的大小,但是二层结构是变动的等等,但这都是细节,真的不要深究了,不然你更适合学C。
这类方法可以自定义中被覆盖掉,很好用的样子。
不可变性
在之前的例子中,没有通过任何操作对原始的字符串进行改变。每个字符串操作都生成了新的字符串,因为字符串在Python中具有不可变性:在创建后,不能原位置(in place)改变。
即,你永远不能覆盖不可变对象的值(正常操作下)。例如不能通过对其某一个位置进行赋值而改变字符串,但你总是可以建立一个新的字符串并以同一个变量名对其进行赋值。而Python在运行过程中会清理旧的对象。
>>> S
'Spam'
>>> id(S)
1845606364400
>>> S[0]='z'
Traceback (most recent call last):
File "" , line 1, in <module>
TypeError: 'str' object does not support item assignment
>>> S='z'+S[1:]
>>> S
'zpam'
>>> id(S)
1845606364144
其中id(S),返回S变量在内存中的地址
看到后面使用运算表达式对S赋值后,S的地址变了
至于S改变的过程,
>>> a=666 >>> id(a) 1566707025552 >>> del a >>> a=' '*2**30*4我获取id(a)的数值后,在计算器中计算出其十六进制数值 16CC7040690 然后在HxD中搜索python进程的对应小端字符串,很容易就能找到地址,这个地址不是固定的,如下
在这里del a后,对应位置会清零,在这里创建其他变量,会生成变量名和变量地址,假设这就是变量名储存区域。我写一个耗时较长的表达式,当表达式运算时,这里并没有变量生成,于是确定,是先生成的数值,再根据数值的地址生成了变量。

Python中的每一个对象都可以归类为不可变的或者可变的。
在核心类型中,数字、字符串、元组,是不可变的;列表、字典、集合,是可变的,他们可以跟你用类创造出的对象一样,完全自由的改变。
你可以在原位置改变基于文本的数据,这需要你将它扩展成一个独立字符构成的列表,然后不加入其它字符重新把它拼接起来。另一种方法是bytearray。
>>> S='Spam'
>>> L=list(S)
>>> L
['S', 'p', 'a', 'm']
>>> L[0]='z'
>>> ''.join(L)
'zpam'
>>> B=bytearray(b'spam')
>>> B.extend(b'eggs')
>>> B
bytearray(b'spameggs')
>>> B.decode()
'spameggs'
>>> bytearray('香'.encode())
bytearray(b'\xe9\xa6\x99')
bytearray存放的是字节,但str存放的中文通常是以unicode ord实现的,而非UTF编码。
但我刚想到,unicode的长度是不定的,有1字节的,如ascii;有2字节的,如中文;还有3字节的,如哥特字母,但这类集序大于2字节的统一用4字节表示。
那他肯定有辅助区来标记这些unicode的占位长度,而不是单纯的一串unicode>>> data('aa') 02 00 00 00 00 00 00 00 38 7b d2 ea dc 13 50 17 e5 51 93 11 5f 11 52 11 00 00 00 00 00 00 00 00 61 61 00 >>> data('慡慡') 02 00 00 00 00 00 00 00 b4 11 f2 7f c1 66 29 83 a8 00 00 00 00 00 00 00 b8 75 cd 7d 49 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 02 00 00 00 00 00 00 00 61 61 61 61 00 00 >>> data('\U00016161\U00016161慡aa') 05 00 00 00 00 00 00 00 02 b1 cf 5f 8a 8f 6f 15 b0 00 00 9f 00 12 51 77 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 61 61 01 00 61 61 01 00 61 61 00 00 61 00 00 00 61 00 00 00 00 00 00 00 >>> bin(0xa8) '0b10101000' >>> bin(0xb0) '0b10110000' >>> s='\U00016161\U00016161慡aaaa' >>> s '\U00016161\U00016161慡aaaa' >>> id(s) 1415155147136 #之后使用HxD将b0改成a8 >>> s '慡\x01慡\x01慡\x00a' # 用HxD将字符数修改为9 >>> s '慡\x01慡\x01慡\x00a\x00a'经过多次对比,包含中文字符的会在第二行有a8的标记,包含超级unicode字符的,会有b0的标记,就是利用这个标记记录字符串中最大unicode占用字节数的,如果用这个思路去拼接几个字符串,可以先获取这几个字符串中最大字符的字节占用,直接读取标记,然后都转换成对应字节长度的unicode,拼接,而因为暂时无法获知解码方法,就走旁门左道,生成一个对应长度的字符串,覆盖其数据。但是我现在并未知晓写入内存数据的方法,而且我也真的懒得搞了~
b=bytearray(b'')
for i in range(1000):
b.extend('香'.encode())
280 µs ± 1.53 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
b=bytearray(b'')
x='香'.encode()
for i in range(1000):
b.extend(x)
140 µs ± 2.72 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
l=[]
for i in range(1000):
l.append('香')
102 µs ± 592 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
''.join(l)
20.4 µs ± 316 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
b.decode()
6.16 µs ± 42.6 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
l=['香'*500,'香'*500]
''.join(l)
487 ns ± 2.95 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
列表转字符串相对来说慢一点,但是间隔符的可操作性强,而且带上之前的追加操作,列表更省性能。
bb=bitstring.BitArray()
for i in range(1000):
bb.append(b)
5.77 ms ± 26.8 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
bb.bytes.decode()
10.8 µs ± 183 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
首先bit的操作数是bytes的8倍,加之这是个第三方的软件,效率不高是常见的。
所以最好的方法就是最常用的方法,这大概也是为什么我是第一次见到bytearray这个类型吧!
指定类型的方法
目前我们学过的每一个字符串操作都是一个真正序列操作。也就是说这些操作在Python中的其他序列也能使用,包括列表和元组。
除了一般的序列操作,字符串还有独有的一些作为方法存在的操作。方法指的是依赖并作用于对象上的函数,并通过一个调用表达式触发。
例如,字符串的find方法是一个基本的子字符串查找的操作(返回一个传入子字符串的偏移量,没找到的情况下返回-1)。
而字符串的replace方法对全局进行搜索和替换。
这两种操作都针对他们所依赖和被调用的对象而进行。
>>> S='Spam'
>>> S.find('pa')
1
>>> S.replace('pa','XYZ')
'SXYZm'
>>> S
'Spam'
尽管这些字符串方法的命名有改变的含义,但在这里都不会改变原始的字符串,而是会创建一个新的字符串作为结果,因为字符串具有不可变性,这种做法是唯一存在的一种可能。
字符串方法是Python中文本处理的头号工具。其他的方法还能够实现:
大小写变换,检测字符串的内容(数字、字母等)、去掉字符串后的空格字符、通过分隔符将字符拆分为子字符串(推导式comprehensions(又称解析式),是Python的一种独有特性。推导式是可以从一个数据序列构建另一个新的数据序列的结构体。)
>>> line='a,bb,cc,d'
>>> line.split(',')
['a', 'bb', 'cc', 'd']
>>> S='Spam'
>>> S.upper()
'SPAM'
>>> S.isalpha()
True
>>> line='a,bb,cc,d \t \n'
>>> line.rstrip()
'a,bb,cc,d'
>>> line.rstrip().split(',')
['a', 'bb', 'cc', 'd']
这里的最后一行命令,他在调用split()方法前调用了rstrip()方法。Python遵循从左到右的执行顺序,每次前一步方法调用结束,都会为后一部方法调用产生一个临时对象。
上述从左到右,但是还有个东西叫做优先级,例如表达式中包含算术运算幂**的话,他会优先算幂,再把得出的结果和后面或前面的变量一起算的。而赋值符号=,也可以把他看作最低优先级。如果不确定优先级或者有需求的话,可以无脑加圆括号括起来。
字符串还支持一个叫做格式化的高级替代操作,可以以一个表达式的形式(最初的)和一个字符串方法调用形式使用:
'%s, eggs, and %s'%('spam', 'SPAM!')
'spam, eggs, and SPAM!'
>>> '{0}, eggs, end {1}'.format('spam', 'SPAM!')
'spam, eggs, end SPAM!'
>>> '{}, eggs, end {}'.format('spam', 'SPAM!')
'spam, eggs, end SPAM!'
{}自动对应后面字符串或变量,{0}为手动指定,不能同时用
>>> '{:,.2f}'.format(296999.2567)
'296,999.26'
>>> '%.2f | %+05d'%(3.14159, -42)
'3.14 | -0042'
扩展:str的所有方法分类归纳???
字符串编程的其他方式
到目前为止,我们学习了字符串对象的序列操作方法和类型特定的方法。
Python还提供了各种便携字符串的方法,转义字符:
>>> S='A\nB\tC'
>>> len(S)
5
>>> ord('\n')
10
>>> S='A\0B\0C'
>>> len(S)
5
>>> S
'A\x00B\x00C'
Python允许字符串包括在单引号或双引号中,他们是相同的,而采用不同的引号可以让另外一种引号被包含在其中(大多数程序员倾向于使用单引号)。
Python也允许在三个引号(单引号或双引号)中包括多行字符串字面量。当采用这种形式的时候,所有的行都合并在一起,并在每一行的末尾增加换行符。这是一个语法上微妙的便捷方式,当在Python脚本中嵌入像多行HTML、XML或JSON这样的代码时十分有用。这种方式能暂时减少代码行数,仅需要在代码段上都加上三个双引号。
1、自动在每行增加\n
2、支持括注的内容内的其他引号,只要不与开始的三个引号造成配对结束
3、在shell中,三个引号后回车,会不执行语句而继续输入
>>> s='''
... aaa
... b'""''b
... ccc
... '''
>>> s
'\naaa\nb\'""\'\'b\nccc\n'
>>> len(s)
17
>>> print(s)
aaa
b'""''b
ccc
>>> repr(s)
'\'\\naaa\\nb\\\'""\\\'\\\'b\\nccc\\n\''
>>> for i in s:
... print(repr(i),end='|')
...
'\n'|'a'|'a'|'a'|'\n'|'b'|"'"|'"'|'"'|"'"|"'"|'b'|'\n'|'c'|'c'|'c'|'\n'|
>>> for i in s:
... print(hex(ord(i))[2:].rjust(2,'0'),end=' ')
...
0a 61 61 61 0a 62 27 22 22 27 27 62 0a 63 63 63 0a
>>> ctypes.string_at(id(s)+48,sys.getsizeof(s)-49).hex(' ')
'0a 61 61 61 0a 62 27 22 22 27 27 62 0a 63 63 63 0a'
最后一行是我根据str类的结构获取的在内存中的形态,其实就是unicode字序,之上代码。
Python也支持原始(raw)字符字面量,即去掉反斜线转移机制。这样的字符串字面量是以字母’r’开头,并对注入Windows下的文件路径的表示十分有用(如r’C:\text\new’)
>>> 'C:\code\temp.txt'
'C:\\code\temp.txt'
>>> open('C:\code\temp.txt','rb')
OSError: [Errno 22] Invalid argument: 'C:\\code\temp.txt'
>>> open(r'C:\code\temp.txt','rb')
<_io.BufferedReader name='C:\\code\\temp.txt'>
>>> open('C:/code/temp.txt','rb')
<_io.BufferedReader name='C:/code/temp.txt'>
Unicode字符串
Unicode 字符百科 这个界面很友好
Unicode compart 这个给出
font space 这个更方便查字体
字客网 这个可以显示包含的子集了更多的字符信息
Unicode的文本处理二三事
字符编码简明教程
每一个程序员必须掌握的知识,字符集与字符编码
一图弄懂ASCII、GB2312、GBK、GB18030编码
各种编码格式(GB2312,GBK,GB18030,unicode,utf-8)之间的关系
刨根究底字符编码
Python的标准编码
如何以编程方式查找Python已知的编解码器列表?
标准编码文件所在目录:Python\Lib\encodings
中文字符集与字符编码的基础知识
GB 2312-1980 信息交换用汉字编码字符集基本集
常用信息编码
字符集是标准,字符编码是实现。
补充:GB2312
一级汉字:按拼音排,若音同,按笔画排
二级汉字:按部首排,再按笔画排
'你'.encode('gb2312')
Out[3]: b'\xc4\xe3'
'尼'.encode('gb2312')
Out[4]: b'\xc4\xe1'
for i in range(0xc4e1-10,0xc4e1+10):
print(i.to_bytes(length=2,byteorder='big').decode('gb2312'),end=' ')
淖 呢 馁 内 嫩 能 妮 霓 倪 泥 尼 拟 你 匿 腻 逆 溺 蔫 拈 年
for i in range(b:=int.from_bytes('镧'.encode('gb2312'),byteorder='big')-10,b+10):
print((bytes.fromhex(hex(i)[2:])).decode('gb2312'),end=' ')
镙 镛 镞 镟 镝 镡 镢 镤 镥 镦
for i in range(int.from_bytes('阿'.encode('gb2312'),byteorder='big')):
try:s=int.to_bytes(i,length=2,byteorder='big').decode('gb2312')
except:pass
else:
if s.isprintable():print(hex(i)[2:],s,end='\t')
7e7e ~~ a1a2 、
bin(0xa1a2)
Out[50]: '0b1010000110100010'
上面最后一段代码,表示的是本地编码中,除了ascii首位是0的(0~7f),其他部分字符的每个字节都以1开头。
机内码=国标码+0x8080
国标码=区位码+0x2020
机内码=区位码+0xa0a0
通用编码字符集:UCS、Unicode、CJK(中日韩)
汉字字形码、汉字地址码(字体、字库)




Font 是从 character 到 glyph 的桥梁。
Font 根据 character 这一抽象输入提供 glyph 这一具象输出。
Font 的本质是个存储了 character 与 glyph 的映射方式(程序的一面)以及 glyph 图形(设计的一面)的数据库。
'\u4e00'
Out[8]: '一'
如果记事本等软件都是Unicode标准的话,文件打开是个很复杂的过程!
例如,我现在打开一个用ANSI(gb2312)保存的文件的话,加载到内存中的字符串是Unicode集序(UCS-2/UTF-16 编码),字体的显示也是Unicode字符集。
UCS-2和UTF-8是Unicode的实现方式。而gb2312编码保存的文件,存储字节是机器码,是内码的实现方式(+a0a0)。
for i in range(20320-10,20320+10):
print(chr(i),end=' ')
佖 佗 佘 余 佚 佛 作 佝 佞 佟 你 佡 佢 佣 佤 佥 佦 佧 佨 佩

而我试了下,日语,一个字符居然占8个字节…
for i in '原因この現象は':
print(i,'\t',i.encode('ISO-2022-JP'))
原 b'\x1b$B86\x1b(B'
因 b'\x1b$B0x\x1b(B'
こ b'\x1b$B$3\x1b(B'
の b'\x1b$B$N\x1b(B'
現 b'\x1b$B8=\x1b(B'
象 b'\x1b$B>]\x1b(B'
は b'\x1b$B$O\x1b(B'
'123原因こ456の現象abcは'.encode('ISO-2022-JP')
Out[8]: b'123\x1b$B860x$3\x1b(B456\x1b$B$N8=>]\x1b(Babc\x1b$B$O\x1b(B'
无语
'香香'.encode("raw_unicode_escape")
Out[183]: b'\\u9999\\u9999'
print('香香'.encode("raw_unicode_escape").decode())
\u9999\u9999
特殊的编码
Unicode 13.0 字符代码图表 chardet -
Python中的字符编码自动检测模块
Code Page Identifiers
比较全的字符编码
关于Windows记事本的ANSI编码:美国国家标准学会( American National Standards Institute)ANSI本身的意思并非是本地编码,而在Windows上是被当作本地编码的原因,ANSI在美国当地是本地编码,可能是翻译上或者编码繁杂等原因,ANSI就对应了系统语言的编码。
在cmd上查看和修改cmd的本地编码:
C:\Users\Jone>chcp
活动代码页: 936
C:\Users\Jone>chcp
65001 Active code page: 65001表 A.5. ANSI和OEM共有的DBCS Code Page 代码页Code Page 对应的字符集Character Set Code
Page 932 Japanese Code
Page 936 GBK - Simplified Chinese Code
Page 949 Korean Code
Page 950 BIG5 - Traditional Chinese

Python还支持完整的Unicode字符串形式,从而支持处理国际化的字符文本,例如日文和俄文的基本字符,并没有被编码在ASCII字符集中。这种非ASCII字符能够在网页、Email、图形界面、JSON和XML等情形下被展示。处理这样的字符需要Unicode的支持。
>>> 'sp\xc4m'
'spÄm'
>>> b'sp\xc4m'
b'sp\xc4m'
>>> '\x0'
truncated \xXX escape
>>> '\xFF'
'ÿ'
>>> '\XFF'
'\\XFF'
>>> 'sp\u00c4m'
'spÄm'
>>> '\x6161'
'a61'
>>> '\x61'
'a'
>>> '\u6161'
'慡'
>>> '\u61'
truncated \uXXXX escape
>>> '\u0061'
'a'
>>> '\u0001'
'\x01'
>>> '\U00000061'
'a'
str字符串在内存中是以Unicode字符集顺序存储的,用bytes字符串类型表示原始字节值。
当字符串中仅有ascii等用8比特表示的字符时,所有字符都只有8比特即1字节的长度。
如果存在一个16bit的字符,那么所有的字符就用16bit表示。
同样存在一个32bit的字符,所有字符就都扩展为32bit表示。
1、\x16进制会自动转换成字符,且后面必须有两个16进制的数字,X必须是大写,但是后面的十六进制不分大小写
2、bytes显示,只有可显示的ascii会显示为字符
3、\u,u小写,后面必须带4个十六进制(2个字节),不分大小写
4、\U,U大写,后面必须带8个十六进制(4个字节),不分大小写
\x、\u、\U都是Unicode的表示方式,分别支持2位、4位、8位的Unicode
字符集总结
关于字符集和字符编码:字符集是一种统一标准,变量存储在内存中的是字符集的顺序。
字符编码是一种实用标准,Python3默认使用utf16作为默认字符编码,当读取源代码,写入文件时,都默认使用utf16,也可以指定其他编码。
'spam'
Out[1]: 'spam'
'spam'.encode() # 不填即是默认值'utf8'
Out[2]: b'spam'
'spam'.encode('utf16')
Out[3]: b'\xff\xfes\x00p\x00a\x00m\x00'
'香spam香'.encode()
Out[6]: b'\xe9\xa6\x99spam\xe9\xa6\x99'
下面代码中内存形态是字符串变量在内存中的存储
ctypes.string_at(id(d)+16,sys.getsizeof(d)-16).hex(' ')
内存形态('spam') # 不做任何处理,在第三行开始记录unicode
04 00 00 00 00 00 00 00 b8 37 f4 de 45 60 96 0f
e5 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
73 70 61 6d 00
内存形态('香spam香') # 标记为a8,每隔字符长度为2字节,在第二行后面记录字符所在内存地址,虽然通常在第四行后面就开始记录unicode
06 00 00 00 00 00 00 00 cb f7 c0 46 61 c1 9b a3
a8 00 00 00 00 00 00 00 18 a6 ec 3d dc 02 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
06 00 00 00 00 00 00 00 99 99 73 00 70 00 61 00
6d 00 99 99 00 00
'\U0001f606香spam香'
Out[18]: '香spam香'
内存形态('\U0001f606香spam香') # 超级unicode,4字节长度,标记为b0,在第四行后面开始记录
07 00 00 00 00 00 00 00 25 92 73 67 fe 57 ba 7d
b0 22 6d 73 67 5f 69 64 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 06 f6 01 00 99 99 00 00
73 00 00 00 70 00 00 00 61 00 00 00 6d 00 00 00
99 99 00 00 00 00 00 00
bytes.fromhex('06 f6 01 00 99 99 00 00\
73 00 00 00 70 00 00 00 61 00 00 00 6d 00 00 00\
99 99 00 00')
Out[37]: b'\x06\xf6\x01\x00\x99\x99\x00\x00s\x00\x00\x00p\x00\x00\x00a\x00\x00\x00m\x00\x00\x00\x99\x99\x00\x00'
hex(ord('0'))
Out[40]: '0x30'
bytes.fromhex('003030')
Out[41]: b'\x0000'
bytes的显示方式,当可以显示为ascii的字节,觉对不用\x的方式显示,所以有时就会出现\x00s\x00m
unicode是国际通用字符标准,utf16是国际字符编码,但是很多地方用的字符编码都是本地的编码,例如中文用gbk,繁体中文用的是big5,很多有自己语言的国家都有自己的字符编码,所以有时我们打开其他国家的文本或是软件,会有乱码,因为我们默认用本地或者utf尝试去解码,但是文件字符却用的当地的编码。
'大魔王'.encode('euc_jp').decode('gbk')
Out[50]: '络蒜拨'
'阿依西铁路'.encode('euc_jp').decode('gbk')
UnicodeEncodeError: 'euc_jp' codec can't encode character '\u94c1' in position 3: illegal multibyte sequence
如果字节无法被解码,就会报错,好在windows、记事本等无法识别的会用其他字符替换掉,所以还能显示内容。
'sp\xc4\u00c4\U000000c4m'
Out[52]: 'spÄÄÄm'
书中有这么一个有意思的例子:
>>>'\u00A3','\u00A3'.encode('latin1'),b'\xA3'.decode('latin1')
Out[72]: ('£', b'\xa3', '£')
里面提到的latin1编码,拉丁-1编码,0x00-0xff 256个,相对ascii 0x00-0x7f 128个,扩展了1倍,在unicode中,ascii叫做基本拉丁字母,latin1比ascii多出来的那部分叫做拉丁文补充1。
ascii-codes
美国信息交换标准码(American Standard Code for Information
Interchange,简称ASCII)是1963年引入的一种广泛使用的字符编码系统。
原来的字符集,现在称为标准字符集,最初由128个字符(7位代码)组成。前32个字符是控制字符(也称为非打印字符),用于控制数据流以及打印机等设备。后来,它被扩展到支持256个字符(8位代码),以提供特定语言字符、各种符号以及框画字符:用于表示目的的元素,允许绘制不同类型的框架和框。128
~ 255之间的字符称为扩展ASCII码。 Code page 850 (Latin-1 - Western European
languages)
代码页850是用来编写西欧语言的代码页:丹麦语、荷兰语、英语、法语、德语、冰岛语、意大利语、挪威语、葡萄牙语、西班牙语和瑞典语。只有扩展字符集与原始代码页不同,控制字符和标准字符集都是纯ASCII。
Code page 852 (Latin-2 - Central European languages)
代码页852是用来编写中欧语言的代码页:波斯尼亚语、克罗地亚语、捷克语、匈牙利语、波兰语、罗马尼亚语和斯洛伐克语。只有扩展字符集与原始代码页不同,控制字符和标准字符集都是纯ASCII。
相当于latin-1就是unicode的那个,而latin-2应该类似于gbk的本地编码,在上表中,latin1和latin2,每一个字序都对应一个字符,主要是扩展不一样,于是我经过一大圈的尝试,得到了latin2的所有字符。两个集合的可打印元素都是188个,于是两个集合确实是数量一样的。
for i in range(0x110000):
try:
chr(i).encode('latin1')
except:pass#print('□',end='')
else:
if chr(i).isprintable():print(chr(i),end='')
#else:print('■',end='')
!"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~¡¢£¤¥¦§¨©ª«¬®¯°±²³´µ¶·¸¹º»¼½¾¿ÀÁÂÃÄÅÆÇÈÉÊËÌÍÎÏÐÑÒÓÔÕÖ×ØÙÚÛÜÝÞßàáâãäåæçèéêëìíîïðñòóôõö÷øùúûüýþÿ
for i in range(0x110000):
try:
chr(i).encode('latin2')
except:pass#print('□',end='')
else:
if chr(i).isprintable():print(chr(i),end='')
#else:print('■',end='')
!"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~¤§¨°´¸ÁÂÄÇÉËÍÎÓÔÖ×ÚÜÝßáâäçéëíîóôö÷úüýĂ㥹ĆćČčĎďĐđĘęĚěĹ弾ŁłŃńŇňŐőŔŕŘřŚśŞşŠšŢţŤťŮůŰűŹźŻżŽžˇ˘˙˛˝
在http://www.postgres.cn/docs/9.3/multibyte.html中
LATIN1 ISO 8859-1, ECMA 94 西欧语
LATIN2 ISO 8859-2, ECMA 94 中欧语
LATIN3 ISO 8859-3, ECMA 94 南欧语
LATIN4 ISO 8859-4, ECMA 94 北欧语
LATIN5 ISO 8859-9, ECMA 128 土耳其语
LATIN6 ISO 8859-10, ECMA 144 日耳曼语
LATIN7 ISO 8859-13 波罗的海语
LATIN8 ISO 8859-14 凯尔特语
LATIN9 ISO 8859-15 带有欧洲语系和语调的LATIN1
LATIN10 ISO 8859-16, ASRO SR 14111 罗马尼亚语
同理可以得出以上字符,前提是不知道在unicode中的范围,知道的话就不用这样试了。
for i in range(0xffff):
print(chr(i).encode('latin1'),end=' ')
b'\x00' b'\x01' b'\x02' b'\x03' b'\x04' b'\x05' b'\x06' b'\x07' b'\x08' b'\t' b'\n' b'\x0b' b'\x0c' b'\r' b'\x0e' b'\x0f' b'\x10' b'\x11' b'\x12' b'\x13' b'\x14' b'\x15' b'\x16' b'\x17' b'\x18' b'\x19' b'\x1a' b'\x1b' b'\x1c' b'\x1d' b'\x1e' b'\x1f' b' ' b'!' b'"' b'#' b'$' b'%' b'&' b"'" b'(' b')' b'*' b'+' b',' b'-' b'.' b'/' b'0' b'1' b'2' b'3' b'4' b'5' b'6' b'7' b'8' b'9' b':' b';' b'<' b'=' b'>' b'?' b'@' b'A' b'B' b'C' b'D' b'E' b'F' b'G' b'H' b'I' b'J' b'K' b'L' b'M' b'N' b'O' b'P' b'Q' b'R' b'S' b'T' b'U' b'V' b'W' b'X' b'Y' b'Z' b'[' b'\\' b']' b'^' b'_' b'`' b'a' b'b' b'c' b'd' b'e' b'f' b'g' b'h' b'i' b'j' b'k' b'l' b'm' b'n' b'o' b'p' b'q' b'r' b's' b't' b'u' b'v' b'w' b'x' b'y' b'z' b'{' b'|' b'}' b'~' b'\x7f' b'\x80' b'\x81' b'\x82' b'\x83' b'\x84' b'\x85' b'\x86' b'\x87' b'\x88' b'\x89' b'\x8a' b'\x8b' b'\x8c' b'\x8d' b'\x8e' b'\x8f' b'\x90' b'\x91' b'\x92' b'\x93' b'\x94' b'\x95' b'\x96' b'\x97' b'\x98' b'\x99' b'\x9a' b'\x9b' b'\x9c' b'\x9d' b'\x9e' b'\x9f' b'\xa0' b'\xa1' b'\xa2' b'\xa3' b'\xa4' b'\xa5' b'\xa6' b'\xa7' b'\xa8' b'\xa9' b'\xaa' b'\xab' b'\xac' b'\xad' b'\xae' b'\xaf' b'\xb0' b'\xb1' b'\xb2' b'\xb3' b'\xb4' b'\xb5' b'\xb6' b'\xb7' b'\xb8' b'\xb9' b'\xba' b'\xbb' b'\xbc' b'\xbd' b'\xbe' b'\xbf' b'\xc0' b'\xc1' b'\xc2' b'\xc3' b'\xc4' b'\xc5' b'\xc6' b'\xc7' b'\xc8' b'\xc9' b'\xca' b'\xcb' b'\xcc' b'\xcd' b'\xce' b'\xcf' b'\xd0' b'\xd1' b'\xd2' b'\xd3' b'\xd4' b'\xd5' b'\xd6' b'\xd7' b'\xd8' b'\xd9' b'\xda' b'\xdb' b'\xdc' b'\xdd' b'\xde' b'\xdf' b'\xe0' b'\xe1' b'\xe2' b'\xe3' b'\xe4' b'\xe5' b'\xe6' b'\xe7' b'\xe8' b'\xe9' b'\xea' b'\xeb' b'\xec' b'\xed' b'\xee' b'\xef' b'\xf0' b'\xf1' b'\xf2' b'\xf3' b'\xf4' b'\xf5' b'\xf6' b'\xf7' b'\xf8' b'\xf9' b'\xfa' b'\xfb' b'\xfc' b'\xfd' b'\xfe' b'\xff'
UnicodeEncodeError: 'latin-1' codec can't encode character '\u0100' in position 0: ordinal not in range(256)
for i in range(0xff+1):
if (c:=chr(i)).isprintable():
print(chr(i),end=' ')
else:print(hex(i),end=' ')
0x0 0x1 0x2 0x3 0x4 0x5 0x6 0x7 0x8 0x9 0xa 0xb 0xc 0xd 0xe 0xf 0x10 0x11 0x12 0x13 0x14 0x15 0x16 0x17 0x18 0x19 0x1a 0x1b 0x1c 0x1d 0x1e 0x1f ! " # $ % & ' ( ) * + , - . / 0 1 2 3 4 5 6 7 8 9 : ; < = > ? @ A B C D E F G H I J K L M N O P Q R S T U V W X Y Z [ \ ] ^ _ ` a b c d e f g h i j k l m n o p q r s t u v w x y z { | } ~ 0x7f 0x80 0x81 0x82 0x83 0x84 0x85 0x86 0x87 0x88 0x89 0x8a 0x8b 0x8c 0x8d 0x8e 0x8f 0x90 0x91 0x92 0x93 0x94 0x95 0x96 0x97 0x98 0x99 0x9a 0x9b 0x9c 0x9d 0x9e 0x9f 0xa0 ¡ ¢ £ ¤ ¥ ¦ § ¨ © ª « ¬ 0xad ® ¯ ° ± ² ³ ´ µ ¶ · ¸ ¹ º » ¼ ½ ¾ ¿ À Á Â Ã Ä Å Æ Ç È É Ê Ë Ì Í Î Ï Ð Ñ Ò Ó Ô Õ Ö × Ø Ù Ú Û Ü Ý Þ ß à á â ã ä å æ ç è é ê ë ì í î ï ð ñ ò ó ô õ ö ÷ ø ù ú û ü ý þ ÿ
记事本与unicode的关系,当记事本打开编辑时,他的编辑区域就是在7FFFB6DB5470(系统运行时,位置固定,但不知哪些原因,这次地址是7FFE62155580)的地址上,在内存中是以unicode字序的形式存在
s='\U0001F606'
s
Out[152]: ''
s.encode()
Out[153]: b'\xf0\x9f\x98\x86'
s.encode('UTF16')
Out[154]: b'\xff\xfe=\xd8\x06\xde'
s.encode('UTF16').hex()
Out[155]: 'fffe3dd806de'
'香'.encode('UTF16').hex()
Out[160]: 'fffe9999'
'香香'.encode('UTF16').hex()
Out[161]: 'fffe99999999'


ASCII,Unicode和UTF-8终于找到一个能完全搞清楚的文章了

据说windows的记事本,unicode就是UTF16,即便文本中只有ascii,同样是用两个字节表示一个字符,只有超级Unicode字符时,才会用四个字节表示一个字符。而在内存中,也是以UTF16的编码形态存在的
但上面的文章提到,notepad.exe的unicode使用的是 UCS-2 编码方式
而在UTF8中,ascii只占一个字节,即UTF8是可变长度,笑脸是4个字节,ascii与笑脸的值都与unicode一样,但是中文却是三个字节
bin(0xe9a699)
Out[162]: '0b111010011010011010011001'
bin(0x9999)
Out[163]: '0b1001100110011001'
111010011010011010011001
1001 1001 10011001
喵,于此异曲同工的是Python的整数无限扩展
这里值得一提的Python2.X与3.X的差别。
2.X允许字符串与字节串在一个表达式中,字节串默认解码为ascii,非ascii混用。
2.X
>>>u'x'+b'y'
u'xy'
3.X
>>> u'x'+b'y'
TypeError: can only concatenate str (not "bytes") to str
b'x'+b'y'
Out[3]: b'xy'
u'x'+u'y'
Out[4]: 'xy'
'x'+b'y'.decode()
Out[6]: 'xy'
'x'.encode()+b'y'
Out[7]: b'xy'
Python对字符的操作:
文本在存入文件时,会被编码成字节。
从文件读入内存时,会被解码成字符。
我们通常只处理文本解码后的字符串。
在Python中,字符串是按字符中最高序字符长度而扩展的
仅ascii,1个字节
最大常规unicode,2个字节
超级unicode,4个字节
>>>mem.data('\xff')
01 00 00 00 00 00 00 00 61 a2 a2 ec a2 63 b4 30
a4 92 86 60 ff 7f 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 ff 00
>>>mem.data('\x7f')
01 00 00 00 00 00 00 00 f0 52 c0 bb 6a 63 31 c7
e4 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
7f 00
之前知道了latin1这个字符集,在Python中确实用的是4个字节存储。
在记事本中,编辑时,在内存中是按照Unicode(UCS-2 little)存在
ANSI:3F ? 会把无法识别的字符每一个字节,转成一个?
Unicode:FF FE FF 00 FF FE是Unicode的标识,Python也是这样转的,字符扩展为两个字节
Unicode big:FE FF 00 FF 记事本的Unicode其实是UCS-2,无论什么字符,都用两个字节
UTF-8:EF BB BF C3 BF EFBBBF 标识符,C3BF字节码,按照之前图片中的转换方案:
>>>bin(0xff)
Out[12]: '0b11111111'
bin(0xc3bf)
Out[13]: '0b1100001110111111'
11000011 10111111
11 111111

本书之后章节还会更加深入的讲解Unicode,届时再遇
模式匹配,正则表达式,re
str类提供了一些字符串的操作方法,但是模式匹配是更进一步的高级工具,可以自己定义规则。
这里导入一个名为re的模块,这个模块包含了累死搜索、分割和替换等调用,我们可以利用模式定义子字符串从而可以进行更通用的匹配。
我这次看完了一个小节,在其中有一些思考,好再这次我并没因此做更多的探索,当我看完整个小结时,发现对于正则的探索就到这里,那就完成这节的部分,不再扩展了!
re - Support for regular expressions (RE).
regular expressions:正则表达式
regular:规则的
expressions:表达式
正则:
【直观详解】什么是正则化
来来来,有没有人总结过什么是“正则”
古文中很少有符合正则表达式之意的,但是正则却是不少,不知道第一个在数学和计算机领域使用正则该词的是何意思。
总结上面两个链接:正有对称的意思,正则表示规则和其表示的内容对称,即完全等价。
在叶典中的解释:[regular] 具有全等正多边形各面的以及多面体的所有角均相等的
我开始倒是以为正是一个动词,即矫正
这里大家只需要了解re的各种方法都是用来做什么的,后面的章节将会详细介绍:
在python中使用正则表达式
正则表达式 re.search re.findall re.finditer返回匹配内容、下标或索引
这里举例的match仅从字符串首开始匹配,而search可以从任意位置匹配,都是返回一个结果,findall返回所有结果,finditer返回一个迭代器。sub替换,subn返回一个元组,等等
import re
match=re.match('Hello[ \t]*(.*)world','Hello Python world')
match
Out[3]: <re.Match object; span=(0, 21), match='Hello Python world'>
match.group()
Out[4]: 'Hello Python world'
match.group(1)
Out[5]: 'Python '
match.groups()
Out[6]: ('Python ',)
这个例子的目的是搜索子字符串:
这个字字符串以’Hello’开始,后面跟着零个或几个制表符或空格,接着任意字符(不包括\n)并将其保存至匹配数组中,最后以单次’world’结尾。
如果找到这样的子字符串,与模式中括号包含的部分匹配的子字符串的对应部分保存为组。
例如,下面的模式取出了三个备斜线所分割的组,你也可以类似的将它们替换成其他模式:
match=re.match('[/:](.*)[/:](.*)[/:](.*)','/usr/home/:lumberjack')
match.groups()
Out[8]: ('usr/home', '', 'lumberjack')
re.split('[/:]','/usr/home/lumberjack')
Out[9]: ['', 'usr', 'home', 'lumberjack']
模式匹配本身是一个相当高级的文本处理工具,但是在Python中还支持更高级的语言处理工具,包括XML、HTML解析和自然语言处理等。后面章节会学到。
列表
Python的列表对象,是Python提供的最通用的序列。
列表是一个任意类型的对象的位置相关的有序集合,他没有固定的大小。
与字符串不同,列表时可变的,通过对应偏移量进行赋值可以定位的对列表进行修改,另外还有其他一系列的列表操作。
相应的,他们提供了一种灵活的表示任意集合的工具,例如一个文件夹中的文件,一个公司里的员工,或你的收件箱中的邮件等。
序列操作
由于列表时序列的一种,它支持所有我们对字符串所讨论过的序列操作。
唯一区别的就是其结果是列表而不是字符串。
我们能够对列表进行索引、切片等操作,就相对字符串所做的那样。
L=[123,'spam','123']
len(L)
Out[12]: 3
L[0]
Out[13]: 123
L[:-1]
Out[14]: [123, 'spam']
L+[4,5,6]
Out[15]: [123, 'spam', '123', 4, 5, 6]
L*2
Out[16]: [123, 'spam', '123', 123,
'spam', '123']
L
Out[17]: [123, 'spam', '123']
扩展模块collections 这个模块实现了特定目标的容器,以提供 Python 标准内建容器dict , list , set , 和tuple 的替代选择。
namedtuple() 创建命名元组子类的工厂函数
deque 类似列表 (list) 的容器,实现了在两端快速添加 (append) 和弹出 (pop)
ChainMap 类似字典 (dict) 的容器类,将多个映射集合到一个视图里面 Counter 字典的子类,提供了可哈希对象的计数功能 OrderedDict 字典的子类,保存了他们被添加的顺序 defaultdict 字典的子类,提供了一个工厂函数,为字典查询提供一个默认值 UserDict 封装了字典对象,简化了字典子类化 UserList 封装了列表对象,简化了列表子类化 UserString 封装了列表对象,简化了字符串子类化
特定类型的操作
Python的列表与其它语言中的数组有些类似,但是要强大得多。
列表没有固定类型的约束,几乎可以存放任何对象。上例中,包含了三个不同类型的对象:整数、字符串、浮点数
列表没有固定大小,能够按照需要增加或建学校列表大小,用来响应其特定的操作:
L=[123,'spam',1.23]
L.append('NI')
L
Out[3]: [123, 'spam', 1.23, 'NI']
L.pop(2)
Out[4]: 1.23
L
Out[5]: [123, 'spam', 'NI']
del L[1]
L
Out[9]: [123, 'NI']
L.extend([1,2,3])
L
Out[56]: [123, 'NI', 1, 2, 3]
这里,列表的append方法增大了列表的大小,并在列表的尾部插入一项;
pop方法(或者等效的del语句)一出给定偏移量的一项,从而让列表减小。
dir(list)
Out[10]:
['__add__',
'__class__',
'__class_getitem__',
'__contains__',
'__delattr__',
'__delitem__',
'__dir__',
'__doc__',
'__eq__',
'__format__',
'__ge__',
'__getattribute__',
'__getitem__',
'__gt__',
'__hash__',
'__iadd__',
'__imul__',
'__init__',
'__init_subclass__',
'__iter__',
'__le__',
'__len__',
'__lt__',
'__mul__',
'__ne__',
'__new__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__reversed__',
'__rmul__',
'__setattr__',
'__setitem__',
'__sizeof__',
'__str__',
'__subclasshook__',
'append',
'clear',
'copy',
'count',
'extend',
'index',
'insert',
'pop',
'remove',
'reverse',
'sort']
其他的列表方法可以在任意位置插入(insert)元素,并按照值移除(remove)元素,在尾部添加多个元素(extend)等。
因为列表是河边的,大多数列表的方法都会原位置改变列表对象,而不是创建一个新的列表:
M=['ba','ab','ccc']
M.sort()
M
Out[14]: ['ab', 'ba', 'ccc']
M.reverse()
M
Out[16]: ['ccc', 'ba', 'ab']
这里的列表sort方法,默认按照升序对列表进行排序,而reverse对列表进行翻转,这些方法都直接改变了列表
常称之为原地操作
print(M.reverse()) None sorted(M) Out[18]: ['ab', 'ba', 'ccc'] reversed(M) Out[19]: <list_reverseiterator at 0x205f9bbc970> M.__reversed__() Out[24]: <list_reverseiterator at 0x205f1b82f40> list(reversed(M)) Out[20]: ['ab', 'ba', 'ccc'] M Out[23]: ['ccc', 'ba', 'ab'] M=[1,2,3]*1000 M.__reversed__() # 115 ns M=[1,2,3] M.__reversed__() # 116 ns reversed(M) # 225 ns原地操作是没有返回值的,而sorted和reversed不是原地操作。操作对象并没有改变,而是生成一个新的对象。值得一提的是reversed返回的并不是我们想要的数值:
m=M.__reversed__() mem.data(m) 02 00 00 00 00 00 00 00 80 88 87 fa 05 02 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 m Out[39]: <list_reverseiterator at 0x205f9baf070> hex(id(m)) Out[40]: '0x205f9baf070' type(m) Out[36]: list_reverseiterator hex(id(M)) Out[38]: '0x205fa878880'他返回了一个地址,意思是说,在地址0x205f9baf070是一个list_reverseiterator,而这个地址的内容只有两个数据,一个是说他是list_reverseiterator类型,另一个数据是他所调用的对象的地址,即id(M)
这里我更愿意称之为是一个实现。这里之所以不是一个最终结果,因为这个实现其实是太简单了,真正调用的时候只需要倒着把数据输出,所以没必要现在就立刻生成一个倒序列表,除非你现在就需要,可以使用list等处理迭代数据的函数调实现这个实现!
边界检查
尽管列表没有固定的大小,Python仍不允许引用不存在的元素。
超出列表末尾之外的索引总会导致错误,对列表末尾范围之外赋值也是如此:
L=[123,'spam','NI']
L[99]
IndexError: list index out of range
L[99]=1
IndexError: list assignment index out of range
L[1:]
Out[44]: ['spam', 'NI']
L[1:99]
Out[45]: ['spam', 'NI']
L[1:3]
Out[46]: ['spam', 'NI']
之前切片中提过,引号两端分别默认0和len()(逆序的话就是-1,-len()-1),如果这里使用了超界的数值,无效并等使用默认值,但不会报错。
这里有意向一个超界的索引赋值,会得到一个错误(而在C语言中,情况比较糟糕,因为它不会像Python这样进行错误检查)。
在Python中,并不是默默地增大列表作为响应,而时会提示错误。为了让一个列表增大,我们可以调用append、extend等这样的列表方法。
嵌套
M=[1,2,3] M.insert(0,M) M Out[4]: [[...], 1, 2, 3] ... Out[5]: Ellipsis这是之前看到的一个奇怪的写法,展示于此,但这个是用方法添加的,主动写成这样,是无效地
Python核心数据类型的一个优秀特性就是他们支持任意的嵌套。
能够以任意的组合对其进行嵌套,并可以多个层次进行嵌套。
例如,能够让一个列表包含一个字典,并在这个字典中包含另一个列表等。
>>>[{1:[]}]
Out[6]: [{1: []}]
这种特性的一个直接应用就是实现矩阵,或者Python中的“多维数组”。
一个嵌套列表的列表能够完成这个基本的操作(你将会在某些应用界面中看到第二行、
第三行开头部位的“…”续航符,但却不会在IDLE等直接基于python的显示功能中得到这样的结果)
M=[[1,2,3],
[4,5,6],
[7,8,9]]
M
Out[14]: [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
这里,我们编写了一个包含3个其他列表的列表,其效果就是表示一个3×3的数字矩阵。
M[1]
Out[15]: [4, 5, 6]
M[1][2]
Out[16]: 6
这里的第一个操作读取了整个第二行,第二个操作读取了那行的第三个元素(正如之前字符串的strip和split方法的连续调用,Python从左向右依次执行代码)。串联起索引操作可以逐层深入的获取嵌套的对象结构。
看了这段话后,我突然悟了,我之前总以为这个层层嵌套的调用,是整整齐齐的列表嵌套列表,于是:
l=[123,'spam']
l[1]
Out[19]: 'spam'
l[1][2]
Out[20]: 'a'
字符串也可以的。
这种矩阵结构适用于小规模的任务,但是对于处理更大量的数据,你会希望使用Python提供的数值扩展,如开源的NumPy和SciPy系统。这些工具小比喻我们自己的嵌套列表结构,能更高效的存储和处理大矩阵。NumPy已经被称为能够将Python变成一个和MATLAB系统意义自由甚至更加强大的系统。而且例如NASA、Los Alamos、JPL和其他的许多机构都将这一工具用于科学和金融领域的任务。
Numpy为什么可以用C语言写
为什么numpy运行速度会很快
以上两个链接分别从语言和架构上解释了NumPy为何如此高效
而我看了其目录,52.1MB,其中.py 5.11MB,.pyc,其他配置文件(.csv、.ini、.f),和疑似C源码(.c、.h)和编译的文件(.pyd、.pxd、.dll),可以说C占绝大部分
推导
处理序列的操作和列表的方法中,Python还包括了一个更高级的操作,称作列表推导表达式(list comprehension expression),从而提供了一种出理想矩阵这样结构的强大工具。例如,假设我们需要从列表的矩阵中提取出第二列。因为矩阵是按照行进行存储的,所以通过简单的索引即可获取行,使用列表推到同样可以简单的获得列:
col2=[row[1] for row in M]
col2
Out[26]: [2, 5, 8]
对比一些其他的写法:
numpy.array(((1,2,3),(4,5,6),(7,8,9))) Out[28]: array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) n[:,1] # 435 ns Out[32]: array([2, 5, 8]) [row[1] for row in M] # 479 ns [2, 5, 8] {row[1] for row in M} # 545 ns {2, 5, 8} set(row[1] for row in M) # 916 ns {2, 5, 8} {row[0]:row[1] for row in M} # 669 ns Out[78]: {1: 2, 4: 5, 7: 8} M=[[1,2,3]]*1000 (row[1] for row in M) # 522 ns [row[1] for row in M] # 63.6 µs {row[1] for row in M} # 53.2 µs {row[1] for row in M} Out[55]: {2} N=numpy.array(M) N[:,1] # 462 ns Out[60]: array([2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])NumPy效率,并没有因为对象长度的增加而增加多少,但是推导式是呈简单的直线增加的。
而推导式除了[]推倒成列表,还可以用{}推导成集合,{:}推导成字典。而一个单独的式子括起来,就是单纯的类似于reversed、range一样的生成器对象,而不会生成元组,1、我认为这里需要一个对象需求,所以用()来描述这是一个对象。2、在这里我很疑惑,定义上,元组是不可变的,那么使用tuple()来转换成元组的意义是否对呢,经过一波折腾,最后看内存消耗确定,tuple()不是一个独立的存在,他是一个生成器触发,无论是列表还是元组,他们的结构是很单纯的,所以生成器有自己的方法去生成元组和列表,还有集合,例如如果是迭代一个很长的重复的字符串,生成集合时的内存是几乎没有增长的。所以这里是变输出,变赋予。但是元组定义上是不可变的,如果按照这个定义来看,元组应该是在生成器生成一个完整的对象后再交给tuple去处理,但从内存上看,并非如此,上图!。如果用一个推导式既要推导列表,又要推导集合,或者需要在列表发生变化的情况下多次推导列表,那么就可以先把推导式用()的方式赋值给一个变量,之后只需要调用这个变量即可。
python列表推导式、字典推导式、集合推导式
Python 推导式的内存变化m=(row[1] for row in M) list(m)实际应用中的列表推导可以更加复杂:
[row[1]+1 for row in M]
Out[80]: [3, 6, 9]
[row[1] for row in M if row[1]%2==0]
Out[81]: [2, 8]
1:把它搜集到的每一个元素都加1
2:使用if条件分句,通过使用%取模表达式(取余数)过滤了结果中的奇数。
列表推导创建了新的列表作为结果,能够在任何可迭代对象上进行迭代。
diag=[M[i][i] for i in [0,1,2]] # 对角线
diag
Out[83]: [1, 5, 9]
doubles=[c*2 for c in 'spam']
doubles
Out[85]: ['ss', 'pp', 'aa', 'mm']
这些表达式同样可以用于存储多个数值,只要将这些值包在一个嵌套的集合中。
[i**2 for i in (1,2,4,8,9)]
Out[1]: [1, 4, 16, 64, 81]
也可以使用原生函数range生成连续整数的功能。在Python 3.X中,需要将其包在list()中来显示,在Python 2.X中,直接显示。
我一直以为range是一个类,但书中描述其是一个函数,当然也可以当作我们在写range(10)的时候,是调用range类中的默认函数生成一个range类型的数值。而且上面提到在2.X中,他直接显示列表结果,那就毋庸置疑的是函数了,在3.X进化为类,他偏向生成器,但生成器没有实体,例如上面的推导式就是一个生成器,但是他的解释暴力到极致!而且根本查不到他的信息,这害得我…
r=range(10) r.count(4) # 1 r.index(3) # 3 r.start # 0 r.step # 1 r.stop # 10 M=[] (row[1] for row in M) Out[15]: <generator object <genexpr> at 0x0000027967338430> r Out[16]: range(0, 10)
list(range(4))
Out[17]: [0, 1, 2, 3]
list(range(-6,7,2))
Out[18]: [-6, -4, -2, 0, 2, 4, 6]
list(range(7,-6,2))
Out[19]: []
list(range(7,-6,-2))
Out[20]: [7, 5, 3, 1, -1, -3, -5]
[[x**2,x**3] for x in range(4)]
Out[21]: [[0, 0], [1, 1], [4, 8], [9, 27]]
[[x,x/2,x*2] for x in range(-6,7,2) if x>0]
Out[22]: [[2, 1.0, 4], [4, 2.0, 8], [6, 3.0, 12]]
除了列表推导式,还有相关内容的函数map和filter,将在之后章节讨论。
这里简要说明的目的是告诉你,Python中既有简单的工具,也有高级的工具,列表推导是一种可选的特性,在实际中非常有用,并常常具有处理速度上的优势(比传统for语句中执行append要更高效)他们也能够在Python的任何序列类型中发挥作用,甚至一些不属于序列的类型。之后讲解。
推导式是生成器,他拥有自己对序列处理的方法,可以说是是突破了传统for语句,不只是优化,例如他可以生成元组,直接生成的那种,在上面链接的文章中,从内存上看,元组和列表的生成过程是不一样的,内存申请的周期更长,这可能和元组的结构有关,元组的数据地址就在元组本体中,而列表是单独的一块区域被链接在本体中,总之元组的推导式不是列表推导式的副产物。而生成器大概是记录了常规生成写法的工作原理并优化,所以tuple(i for i in s),他可能并不是一个tuple函数,也可能这个函数内有推导式的算法,也可能解释器看到元组和推导式的组合,直接交给推导式处理,必定有一个处理语法关联了推导式,例如[]关联了列表,但是[]可能并不是又列表触发,而是解释器上的某一部分,只不过[]被注册进去。
而且,元组被定义为不可变序列,是否和推导式有冲突,至少数据很大的时候,推导式会有明显的时长,而解释器可能把推导式一个过程的,而怎么去生成元组,交给推导式内部完成,内部怎样去做,不受解释器对元组的定义,而只有尝试使用通用操作方法去赋值时,例如切片、索引赋值,系统才会提示元组为不可变序列
在Python最近的版本中,推导式被赋予了更一般的用法:它不仅仅只用作生成列表,好好中的推倒语法也可以用来创建产生所需结果的生成器。
M=[[1,2,3],[4,5,6],[7,8,9]]
G=(sum(row) for row in M)
next(G)
Out[3]: 6
next(G)
Out[4]: 15
next(G)
Out[5]: 24
next(G)
Error:StopIteration
G
Out[7]: <generator object <genexpr> at 0x0000025879C92430>
R=range(10,-10,-2)
next(R)
TypeError: 'range' object is not an iterator
next(...)
next(iterator[, default])
这里书中解释为他是一个生成器,type也却是是说生成器,但next的异常显示他是迭代器。range不能当作迭代器用,依稀记得最近写过迭代相关的代码,finditer、list.__reversed(),而next()也可以当作验证迭代器的工具,但谨慎使用,毕竟迭代一项少一项
m=M.__reversed__() next(m) Out[12]: [7, 8, 9] next(m) Out[13]: [4, 5, 6] next(m) Out[14]: [1, 2, 3] type(m) Out[16]: list_reverseiterator # 这里直接带着iterator 迭代生成器内置的map可以通过一个函数,按照请求一次生成一个项目,也是一个迭代器。list()可以让迭代器一次性输出并生成列表。迭代器每输出一个元素,下次就输出下一个元素,直到为空,如果用next()强制输出,就回报错,下面展现了两次list(),一次迭代器已经空了,一次迭代器被next()出一个后。
map(sum,M)
Out[17]: <map at 0x25879c82be0>
m=map(sum,M)
next(m)
Out[19]: 6
next(m)
Out[20]: 15
next(m)
Out[21]: 24
type(m)
Out[22]: map
list(m)
Out[24]: []
m=map(sum,M)
next(m)
Out[27]: 6
list(m)
Out[28]: [15, 24]
推导语法也可以用来创建列表、集合、字典、生成器:
{sum(row) for row in M}
Out[29]: {6, 15, 24}
{i:sum(M[i]) for i in range(3)}
Out[32]: {0: 6, 1: 15, 2: 24}
[ord(x) for x in 'spaam']
Out[33]: [115, 112, 97, 97, 109]
{ord(x) for x in 'spaam'}
Out[34]: {97, 109, 112, 115}
{x:ord(x) for x in 'spaam'}
Out[35]: {'s': 115, 'p': 112, 'a': 97, 'm': 109}
(ord(x) for x in 'spaam')
Out[36]: <generator object <genexpr> at 0x0000025879D7FC10>
书中这里用到推导语法这个词,意味着推导式是基于解释器核心的内容。这里并没有提到tuple,我突然又有一个想法/笑哭
但如果是一个列表直接转换为元组,还是被秒的,但是推导式之类的还是发生之前的情况,两者区别在于,无论推导式是迭代还是序列,都是很惨的,但如果直接tuple(list),就是秒。差别原因有两个:for需要时间,最关键的是内存来回复制数据需要时间。
列表解析比手动的for循环运行速度往往会快一倍,因为迭代在解释器内部以C语言的速度执行。
字典
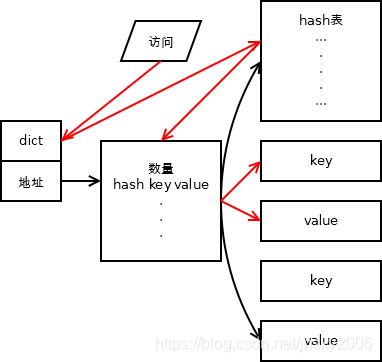
我很确定字典产生了哈希表,用HxD也很容易搜索到他,但是我没能找到他们地址之间的联系
字典早Python3.6以前,是无序的,但自3.6版,是按照创建、添加的顺序输出的,但请不要把此当作为特性
在collections模块中还有三个与字典相关的类,其中有支持元素移动到字典首部或尾部,支持多类型源数据创建指定values形式,以及基类
Python中的字典则是一种完全不同的东西:他们不是序列,而是一种映射(mapping)。映射同样是一个其他对象的集合,但是他们通过键(key)而不是相对位置来存储对象的。实际上,映射并没有为湖人和可靠的从左至右的顺序。他们简单地将键映射到相应的值上。弟子按时Python核心对象集合中唯一的一种映射类型,也是具有可变性:同列表一样,可以就地改变并随着需求增大或减小。和列表一样,字典是表示集合的一个灵活的工具,但他们更易于记忆的键更适用于集合中的元素被命名或被标记时的情况,就像数据库中的字段和记录的关系一样。
映射操作
字典作为常量编写时,编写在大括号中,并包含一系列的“键:值”对。在需要将键与一系列值相关联(例如,为了表述某物的某属性)的事后,字典是很有用的。
作为一个例子,请思考下面包含三个元素的字典(键分别为“food”食物 “quantity”数量 “color”颜色,说不定是一张假象菜单细节!):
在Unicode小结中,我将字典作为存放集合和方法的地方,而key来自我预先设定的list或者手动输入,这样的字符串变成key,而不是变成变量名,避免了使用exec,而且数据都集中在字典中,使用起来也比较方便。网友说过一句话,用exec就错了,探究的结果表示,用dict和eval要比exec高效、安全。
D={'food':'Spam','quantity':4,'color':'pink'}
D['food']
Out[2]: 'Spam'
D['quantity']+=1
D
Out[4]: {'food': 'Spam', 'quantity': 5, 'color': 'pink'}
在书中的举例中,还有之前的一段代码,结果确实是逆序的,但是我实际操作是写入顺序,即便类似于:
d=dict() d[1]=1 d[3]=3 d[2]=2 d Out[9]: {1: 1, 3: 3, 2: 2}他也并没有改变顺序,我只能说归功于独立的哈希表,字典的元素顺序是不变的,虽然也带着hash,但是因为有了另一个单独的hash表,字典数据输入并不需要改变顺序,只需要在末尾追加,即便删除操作,数据区的hash不会消失,key和value地址清零,这样从哈希表到数据区,发现没有key,照样报没有元素。而之前稍微探究过集合的排序,那是另一回事!等到了集合的小结,分析下集合的结构。
尽管可以使用大括号这种字面量形式,最好还是见识一下不同的创建字典的方法,这种方法无需知道字典的当前情况:
下面开始一个空的字典,然后每次以一个键来填写他。与列表中禁止边界外的赋值不同,对一个新的字典的键的赋值会创建该键,若已有该键,则会覆盖写入。
D={}
D['name']='Bob'
D['job']='dev'
D['age']=40
D
Out[5]: {'name': 'Bob', 'job': 'dev', 'age': 40}
print(D['name'])
Bob
这里,我们有效的使用了字典中的键,就如同一张记录表中来描述某个人的名字字段。
在另一个应用中,字典也可以用来代替搜索操作。通过键来索引一个字典往往是Python中编写搜索的最快方法。
我们用另外几种方法传递键值参数对,创建字典,与之前{}字面量形式等价。
bob1=dict(name='Bob',job='dev',age=40)
bob1
Out[25]: {'name': 'Bob', 'job': 'dev', 'age': 40}
bob2=dict(zip(['name','job','age'],['Bob','dev',40]))
bob2
Out[27]: {'name': 'Bob', 'job': 'dev', 'age': 40}
字典的键的顺序是被打乱的,除非你特别幸运,通常会返回一个和输入顺序不同的次序。具体情况视Python版本而不同,但不要过于依赖此顺序。
zip(('name'),('Bob')) Out[9]: <zip at 0x18162bf61c0> z=zip(('name'),('Bob')) next(z) Out[11]: ('n', 'B') next(z) Out[12]: ('a', 'o') next(z) Out[14]: ('m', 'b') next(z) Error:StopIteration z=zip(('name',),('Bob',)) next(z) Out[17]: ('name', 'Bob') for i,j in zip([1,2,3],[4,5,6,7]): print(i,j) 1 4 2 5 3 6 dict(zip([1,2,3],[4,5,6,7])) Out[29]: {1: 4, 2: 5, 3: 6} a=['name','job','age'] b=['Bob','dev',40] {a[i]:b[i] for i in range(3)} Out[22]: {'name': 'Bob', 'job': 'dev', 'age': 40} dict(a[i]=b[i] for i in range(3)) SyntaxError: expression cannot contain assignment, perhaps you meant "=="? dict('name'='Bob') SyntaxError: expression cannot contain assignment, perhaps you meant "=="?zip是个迭代器,单独使用时,他并不会检查被操作元素的长度(元素个数),只要有一方空了,就结束迭代!
在推导表达式中,使用dict(a=b)的方式失败。使用dict(a=b),注意a符合变量名命名规则,而dict中的key必须是个不可变量,因为hash。而之后在函数的数据传递时,会遇到差不多的一个规则(*args, **kwargs)。{a:1} TypeError: unhashable type: 'list' {c:1} NameError: name 'c' is not defined c='123' {c:1} Out[34]: {'123': 1} i=123 {i:1} Out[36]: {123: 1} {(1,2,3):[1,2,3]} Out[38]: {(1, 2, 3): [1, 2, 3]}
重访嵌套
现在,假设信息更复杂一些,我们需要去记录名(first name)和姓(last name),并有多个工作(job)的头衔。
这产生了另一个Python对象嵌套的应用:
rec={'name':{'first':'Bob','last':'Smith'},
'job':['dev','mgr'],
'age':40.5}
rec
Out[41]: {'name': {'first': 'Bob', 'last': 'Smith'}, 'job': ['dev', 'mgr'], 'age': 40.5}
在顶层再次使用了三个键的字典(键分别是“name” “job” “age”),但是值更复杂了:一个嵌套的字典作为name的值,支持了多个部分。
一个嵌套的列表作为job的值,从而支持多个角色和未来的扩展。我们可以获取这个结构的每个元素,就像之前基于列表的矩阵那样,但是这里索引的是字典的键而非列表的偏移量。
rec['name']
Out[42]: {'first': 'Bob', 'last': 'Smith'}
rec['name']['first']
Out[44]: 'Bob'
rec['job']
Out[46]: ['dev', 'mgr']
rec['job'][-1]
Out[47]: 'mgr'
rec['job'].append('janitor')
rec
Out[49]:
{'name': {'first': 'Bob', 'last': 'Smith'},
'job': ['dev', 'mgr', 'janitor'],
'age': 40.5}
这里的最后一个操作是扩展迁入的jobs列表的,因为jobs列表时字典所包含的一部分独立的内存,他可以自由的增加或减少(对象的内存部署之后会学)
但,其实dict的key和value,本身是独立的数据,拥有独立的地址,只要a=d[key],这个value就可以同时被a和d[key]所调用,于是我并不是很认同value在dict的内部这种说法,话说目前语法上,貌似只能迭代获取key的内存内容,不能直接调用得到key。
for i in d: print(hex(id(i))) 0x1814ce75c70 0x18162c7e590 0x18162c7ed10
之前提到过del d[0x9999]后,只是key和value的地址以及内容被情况,而再次写入一个d[0x9999],不会在原地写入,我之前写错一个数据,删了再写,原位置不在最后方,而他出现了最后方。另外hash表应该是当元素达到一定量后出现的,当前就5个元素,进程中没有其他的hash标记。
我悟了,为什么变量不能用数字开头,是因为数字就是数字,首字符是数字的话,就会把他当作一个数字来看待,而不是变量。例如这里提到了value是列表。那其实也可以是变量,在之前的dict(a=b)赋值中,我把视角放在了a上,那么现在看看b!b=123 c='123' a='a' {a:b} Out[53]: {'a': 123} {b:c} Out[54]: {123: '123'} dict(b=c) Out[55]: {'b': '123'} dict(c=b) Out[56]: {'c': 123} dict('123'=c) SyntaxError: expression cannot contain assignment, perhaps you meant "=="? dict(123=c) SyntaxError: expression cannot contain assignment, perhaps you meant "=="? dict(c=123) Out[59]: {'c': 123} dict(c=e) NameError: name 'e' is not defined dict(c='e') Out[61]: {'c': 'e'}这里如果是字面量的话,会自动把相关变量替换成数据,但是如果使用dict(a=b),就完全要符合a=b的语法,a符合变量名规则,并转换成str当作dict的key,而b:变量名,如果不存在,报错,存在这使用其数据,'b’字符串。与a=b不同的是,如果不符合规则,不会报a不符合变量命名,而是==
这里的例子是为了说明Python核心数据类型的灵活性,正如所见,嵌套允许直接并轻松的建立复杂的信息结构。
使用C这样的底层语言,建立一个类似的结构,将会很枯燥并会使用更多的代码:将不得不去事先安排并声明结构和数组,填写值,将每一个都连接起来等。
在Python中,所有这一切都是自动完成的,运行表达式即创建了整个嵌套对象结构。这是Python的主要优点之一。
在底层语言中,当不再需要该对象时,需要小心地释放掉所有对象空间。在Python中,会自动清理对象所占的内存空间:
rec=0
rec之前的数据就会被释放并清理掉。
不存在的键:if 测试
字典只支持他哦难过键访问对象。也支持通过方法调用进行指定类型的操作。
例如:
我要写入一个键,但是如果这个键存在,那就不写入了,之前的数据可能有用,可能需要其他操作等。
我要读取一个键,但是如果这个键不存在,读取则会发生异常。
D={'a':1,'b':2,'c':3}
D
Out[75]: {'a': 1, 'b': 2, 'c': 3}
D['e']=99
D
Out[77]: {'a': 1, 'b': 2, 'c': 3, 'e': 99}
D['f']
KeyError: 'f'
访问一个并不存在的东西,往往是一个程序错误。
而Python提供字典的in关系表达式允许我们查询字典中一个键是否存在,并可以通过if语句对查询的结果进行分值处理。
'f' in D
Out[79]: False
if not 'f' in D:
print('missing')
missing
if后面是一个判断真假的表达式,若真,则执行包含的代码(相对if语句,向后缩进一个的代码块),配套的还有elif、else等操作。
除了in测试,还有其他方法查询键的存在:get方法、try语句、if/else三元表达式(缩写)
value=D.get('x',0)
value
Out[103]: 0
value=D['x'] if 'x' in D else 0
value
Out[105]: 0
python通过字典选择调用的函数(类似于SwitchCase语句)
在这里我第一次看到get方法
Python字典常用函数方法总结
这里建议开发中优先使用get方法,相比[]来说help(dict.get) get(self, key, default=None, /) Return the value for key if key is in the dictionary, else default.如果key在dict中,返回他的value,否则返回预设,预设可以设置成别的
v=d[k],如果k不在d中,则会报错,v=d.get(k),如果k不在d中,返回预设。
另外dict有一个内置方法__contains__,他应该是in,但是in比他效率高,所以除非是编写自己的方法,否则不要用它。
6666 in d # 90.1 ns d.get(6666) # 113 ns d.__contains__(6666) # 125 ns if v:=d.get(6666):v # 140 ns if 6666 in d:d[6666] # 161 ns if d.get(6666):d.get(6666) # 237 ns这里如果使用get同时需要一个判断的话,用了一个海象运算符,运算时间大大缩短,超过if k in d
书中用了not k in d,这个语句,我印象中一直是k not in d,觉得这样语义更顺,实际上,这两个效率差不多!
'x' not in D # 71.4 ns Out[118]: True not 'x' in D # 71.4 ns Out[119]: True not D.__contains__('x') # 114 ns Out[117]: True
键的排序:for循环
因为字典不是序列,无序且不可直接访问key,那么如何按照顺序输出其元素呢?
利用keys方法收集一个键的列表,使用列表的sort方法进行排序,然后使用for循环逐个显示:
D={'c':3,'a':1,'b':2}
D
Out[10]: {'c': 3, 'a': 1, 'b': 2}
D.keys()
Out[11]: dict_keys(['c', 'a', 'b'])
Ks=list(D.keys())
Ks
Out[13]: ['c', 'a', 'b']
Ks.sort()
Ks
Out[16]: ['a', 'b', 'c']
for key in Ks:
print(key,'=>',D[key])
a => 1
b => 2
c => 3
在最近的Python中,增加了新的函数sorted内置函数可以一步完成。sorted调用返回结果并对各种对象类型进行排序。
sorted(D)
Out[20]: ['a', 'b', 'c']
for key in sorted(D):
print(key,'=>',D[key])
a => 1
b => 2
c => 3
这里用到的for循环,是遍历一个序列中所有元素,并按顺序对每一个元素进行一些代码操作的简单有效的方法。
遍历:走遍、经过,游遍,有都走一遍的意思。遜令塞耳休聽,不許出迎,親自遍歷諸關隘口,撫慰將士,皆令堅守。
用户定义的循环变量(i,key),用作每次运行过程中当前元素的参考量,这里就是用排好序的key打印无序的字典。
s=set((1,2,3)) sorted(s) Out[26]: [1, 2, 3] s=set((10,10000,100000000)) s Out[28]: {10, 10000, 100000000} print(s) {10000, 100000000, 10} for i in s: print(i) 10000 100000000 10 for i in sorted(s): print(i) 10 10000 100000000这是立刻要讲到的集合,至少这个集合是很好得到无序输出的。
for循环与其作用相近的的while循环,是在脚本中编写重复性任务语句的的主要方法。
for循环可以遍历迭代器、序列甚至非序列的对象。
for c in 'spam':
print(c.upper())
S
P
A
M
while循环是一种更为常见的排序循环工具,它不局限于逐一访问序列,但通常需要更多的代码来实现:
x=4
while x>0:
print('spam!'*x)
x-=1
spam!spam!spam!spam!
spam!spam!spam!
spam!spam!
spam!
以后详解。
我通常是能够使用for就绝不使用while,而很多程序、游戏的主架构是基于while的,不断地检查,不断地战斗,不断地重来。
通常没有逻辑误区,for的效率比while高。
迭代和优化
迭代:更迭换代,一波波。存亡以之迭代,政亂從此周復,天道常然之大數也。
如果上一节中的for循环看起来就像之前介绍的列表推导式一样,那也没错。因为他们都是真正的通用迭代工具。他们能够工作于遵守迭代协议的任意可迭代对象。
迭代协议:Python中无处不在的一个概念,是所有迭代器工具的基础。
我之前看的教材,都是先介绍for,再提到推导式,甚至推导式很少用,于是我之前的概念是推导式是简写的for,是生成列表的一个方式,仅此而已。上面链接中,经测试,推导式是比for快上近一倍,是不可不掌握的一个语法。
l=[1,2,3]
next(l)
TypeError: 'list' object is not an iterator
一个可迭代对象是在内存中物理存储的序列,也可以是一个在迭代操作情况下每次产生一个元素的对象——一种虚拟的序列。
可迭代对象,拥有__iter__方法,迭代器拥有__next__方法,生成器拥有yield方法。之前的推导式是迭代器,常见的数据类型列表等是可迭代对象,可以使用推导式组成迭代器。他们都是可迭代的(iterable),因为他们支持迭代协议——他们在响应next之前先用一个对象对iter内置函数作出响应,并在结束时触发一个异常。
生成器 ⫋ \subsetneqq⫋ 迭代器 ⫋ \subsetneqq⫋ 可迭代对象
使用dir(builtins)查看内置的方法、类等
可迭代对象(iter):bytearray、bytes、dict、frozenset(冻结,不可变set)、list、range、set、str、tuple
迭代器(next):enumerate、filter、map、reversed、zip、iter、reversed
迭代器语法:*zip、lambda、for in
生成器:yield
其他可迭代对象相关方法:
all(iterable) 不存在Flase、0为假,空和其他为真
any(iterable) 存在非Flase非0为真
len(s) 统计元素个数
max(iterable) 得出最大元素
min(iterable) 得出最小元素
next(iterable) 实现迭代输出
sorted(iterable,key=None, reverse=False) 得出排序结果,可以添加参照,可以逆序
sum(iterable,start=0) 求和,可以附加数值
还有很多类型和方法分别放在了外置模块的collections和functools中。
本书稍后会详细介绍迭代协议,任何一个从左到右扫描一个对象的Python工具都使用了迭代协议。
正如之前,无需用keys,直接使用next、sorted迭代得到字典的key。
同理,列表推导式能够编写成一个等效的for循环。
squares=[x**2 for x in [1,2,3,4,5]]
squares
Out[144]: [1, 4, 9, 16, 25]
squares=[]
for x in [1,2,3,4,5]:
squares.append(x**2)
squares
Out[147]: [1, 4, 9, 16, 25]
两种工具在迭代协议内部发挥作用,并产生相同的结果。尽管如此,推导式和相关函数(map、filter)在某些代码上通常运行的比for循环快(设置快了两倍):这是对有大数据集合的程序有重大影响的特性之一。
Python中的一个主要原则:首先为了简单和可读性去编写代码,在程序可以工作并证明了确实有必要考虑性能后,再考虑该问题。
稍后会介绍Python一些性能分析相关的工具
这里我推荐我一直在用的IPython的%%timeit、%%time
元组
元组对象(tuple),几本书就像一个不可以改变的列表,元祖师序列,具有不可变性,和字符串类似。存放在圆括号中,支持任意类型、任意嵌套以及常见的序列操作。
关于任意类型,相对于字典的key和集合的元素,是不支持例如列表这类可变序列的,因为unhashable type: ‘list’,列表可变,所以不能hash。
T=(1,2,3,4)
len(T)
Out[6]: 4
T+(5,6)
Out[7]: (1, 2, 3, 4, 5, 6)
T[0]
Out[8]: 1
而且元组并没有列表如此多的内置方法,仅有index和count
T.index(4)
Out[17]: 3
T.count(4)
Out[18]: 1
元组是不可变序列,所以向元组的索引赋值是错误的。而当元组仅有一个元素时,需要添加逗号来声明这是个元组。
T[0]=2
TypeError: 'tuple' object does not support item assignment
(2,)
Out[20]: (2,)
(2)
Out[21]: 2
id(T)
Out[22]: 3146873086656
T=(2,)+T[1:]
T
Out[24]: (2, 2, 3, 4)
id(T)
Out[25]: 3146873185120
这里使用了id()这个方法,他是显示当前变量在内存中的地址,一旦地址改变,说明该变量已经不是之前的变量了。不是变量变了,而是变量不是了。
与列表和字典一样,元组支持回合的类型和嵌套,但不能增长或缩短,因为他们是不可变的。
T='spam',3.0,[11,22,33]
T[1]
Out[27]: 3.0
T[2][1]
Out[28]: 22
T.append(4)
AttributeError: 'tuple' object has no attribute 'append'
append是list专属的方法,例如set专属的方法是add,而元组除了index和count之外,没有任何方法
为什么要使用元组
元素累死列表,而且支持更少的操作,那为什么需要他?
元组在实际中不像列表那样常用,但是他的关键是不可变性。
如果是列表,用一处传递给另一处,在相互调用中可能会发生改变,而元组则不会,远足提供了一种完整性的约束,这对于编写更大的程序来说是方便的。之后还会介绍模块collections中的named tuples(这里书中称其为插件)
为什么元组可以被约束,而列表不会被约束

元组在生成的时候,就已经是不可变的,他固定在内存的地址和空间中。这是被Python定义好了的。
而列表,他的内容中,是一个地址,指向一个数据区域,这个区域可以被增加删减,当这连续的区域用完时,系统会申请新的区域,内容会把复制到那一处,列表包含的这个地址就会改变,总之,列表内的元素是不固定的。而元组一开始就固定死了。但严格地说被完全的约束也是不对的,因为如果元组的元素是列表的话,列表地址(变量)没有变,但是列表的内容就不一定了,看程序员如何去使用这个可变的元素!
l=[1,2,3]
t=(0,l,4)
t
Out[56]: (0, [1, 2, 3], 4)
l.append(4)
t
Out[58]: (0, [1, 2, 3, 4], 4)
l=[]
t
Out[60]: (0, [1, 2, 3, 4], 4)
list(range(100)) # 1.3 µs
tuple(range(100)) # 1.74 µs
大致来说,列表生成速度比元组快,功能比元组多,所以一般情况下还是建议使用列表
collection模块(具名元组、队列、有序字典、默认值字典)、time 模块、随机模块:random、os模块、sys模块、序列化模块
Python进阶之具名元组collections.namedtuple
具名元组是collection模块中的功能,这个模块中的几个数据类型属于默认数据类型的扩展,不是经常用得到,但是考虑到程序员使用到相关功能的可能性,而扩展了一些功能,例如队列,支持双向操作,可以从后面读写数据。其原理是与默认的列表上,存储结构就不相同。
而具名元组是我今天刚接触到的,大致类似于类,一般的元组使用索引数来读取内部元素,但具名元组给每个索引都起了名,为每个索引位置上的数赋予解释,告我程序员,他是做什么的,可以用具名去读取对应索引上的数据。从这点说,很像字典,但字典支持读写,这个元组不支持。还有这称之为工厂函数,即他就像是给流水线起名,之后生产出来的元组,他就对应其流水线位置上的起名。相比一般元组的单纯结构:我是元组,变成了有这么一种元组,他的每个元素的意思是,这是一个某种元组。去掉“某种”,这两类元组应该是一样的。所以称之为工厂函数。
>>> import collections
>>> User=collections.namedtuple('User','name age id')
>>> user=User('tester','22','46464646')
>>> user
User(name='tester', age='22', id='46464646')
>>> user1=User('tester1','22','46464646')
>>> user1
User(name='tester1', age='22', id='46464646')
>>> Users=collections.namedtuple('User','name age id')
>>> user2=Users('tester1','22','46464646')
>>> user2
User(name='tester1', age='22', id='46464646')
>>> user2=Users('tester1','22','46464646','')
Traceback (most recent call last):
File "" , line 1, in <module>
TypeError: <lambda>() takes 4 positional arguments but 5 were given
字符串:
>>> b'a\x62c'
b'abc'
>>> u'sp\xc4m'
'spÄm'
文件
文件对象是Python代码调用电脑上存放的外部文件的主要接口。
他们能够用左读取和写入文本、音频灯任何你保存在电脑上的东西。虽然文件是核心类型,但是他没有特定的字面量语法来创建,要创建一个文件对象,需要调用内置的open函数以字符串的形式传递给他一个外部的文件以及一个表示处理模式的字符串。
f=open('data.txt','w')
f.write('Hello\n')
Out[79]: 6
f.write('world\n')
Out[80]: 6
f.close()
f
Out[87]: <_io.TextIOWrapper name='data.txt' mode='w' encoding='cp936'>
import os
os.getcwd()
Out[92]: 'C:\\Users\\Jone'
这里创建一个文件对象并以’w’处理模式来写入数据,每次写入数据,回返回一个写入字符数,如果有必要的话,可以接收该数并处理,虽然一般并用不到。
如果不写完整的路径,默认将文件在工作目录读取和写入,使用os.getcwd()获取当前工作目录
f=open('data.txt')
text=f.read()
text
Out[101]: 'Hello\nworld\n'
print(text)
Hello
world
text.split()
Out[106]: ['Hello', 'world']
这里在没有标注处理模式的情况下,默认以’r’(仅读取文件)处理,使用read方法读取文件内容,返回字符串。无论文件包含的数据是什么类型,文件的内容总是字符串。
这里不在深入讨论,例如读写模式,read可以添加一个字符数的参数,readline每次读取一行,seek移动文件地址,文件对象提供一个迭代器(iterator)在for循环逐行读取——open()提供__iter__、__next__等方法。
for line in open('data.txt'):print(line)
Hello
world
之后章节会看到文件方法的完整列表。
如果仙子啊想要快速预览下,可以运行dir以及help
dir(f)
Out[110]:
['_CHUNK_SIZE',
'__class__',
'__del__',
'__delattr__',
'__dict__',
'__dir__',
'__doc__',
'__enter__',
'__eq__',
'__exit__',
'__format__',
'__ge__',
'__getattribute__',
'__gt__',
'__hash__',
'__init__',
'__init_subclass__',
'__iter__',
'__le__',
'__lt__',
'__ne__',
'__new__',
'__next__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__setattr__',
'__sizeof__',
'__str__',
'__subclasshook__',
'_checkClosed',
'_checkReadable',
'_checkSeekable',
'_checkWritable',
'_finalizing',
'buffer',
'close',
'closed',
'detach',
'encoding',
'errors',
'fileno',
'flush',
'isatty',
'line_buffering',
'mode',
'name',
'newlines',
'read',
'readable',
'readline',
'readlines',
'reconfigure',
'seek',
'seekable',
'tell',
'truncate',
'writable',
'write',
'write_through',
'writelines']
help(f.seek)
Help on built-in function seek:
seek(cookie, whence=0, /) method of _io.TextIOWrapper instance
Change stream position.
Change the stream position to the given byte offset. The offset is
interpreted relative to the position indicated by whence. Values
for whence are:
* 0 -- start of stream (the default); offset should be zero or positive
* 1 -- current stream position; offset may be negative
* 2 -- end of stream; offset is usually negative
Return the new absolute position.
type(f)
Out[113]: _io.TextIOWrapper
文件对象是一个迭代对象,也是一个迭代器。
_io.TextIOWrapper:文本输入输出包装
二进制字符串
Python 2.X和3.X的文件写入编码是有区别的,也就是说文件接口可以同时根据内容和Pyrhon版本而改变。
Python在文件中的文本和二进制数据之间画出了一条清晰的界限,文本文件把内容显示为正常的str字符串,并且在写入和读取数据时,自动执行Unicode对应的编码和解码(文件对象中的字符串写入操作,在未指定编码的情况下,默认是以系统的默认语言编码,例如上面的encoding=‘cp936’)。
而二进制文件把内容显示为一个特性的字节串,并且允许你不修改的访问文件内容。
生成字节串的方法有很多,例如直接用字节字面量生成字节:b’123’,或者编码字符串’123’.encode(),这里默认使用UTF-8进行编码。或者一些类的方法,int.to_bytes,bytes.fromhex等。这里介绍的是一个C标准的结构体的打包二进制编解码的模块:struct
import struct
packed=struct.pack('>i4sh',7,b'spam',8)
packed
Out[46]: b'\x00\x00\x00\x07spam\x00\x08'
file=open('data.bin','wb')
file.write(packed)
Out[48]: 10
file.close()
struct:以大端的字节序,将4字节长度整数编码第一个数值,以字符串编码第二个数值,以十六进制编码第三个数值
生成文件对象,以写入二进制模式
读取并还原二进制数据是一个对称的过程:
data=open('data.bin','rb').read()
data
Out[63]: b'\x00\x00\x00\x07spam\x00\x08'
data[4:8]
Out[64]: b'spam'
list(data)
Out[65]: [0, 0, 0, 7, 115, 112, 97, 109, 0, 8]
struct.unpack('>i4sh',data)
Out[66]: (7, b'spam', 8)
type(data)
Out[67]: bytes
type(data[0])
Out[68]: int
这里直接使用了open(‘data.bin’,‘rb’).read()这个一气呵成的语句,因为文件对象并未被赋值给某个变量,所以执行完语句后,文件对象就被释放,相当于自动close()。在’w’模式中可以看到结果,因为如果不close(),因为缓冲区的原因,是不会被写入文件的。
另外我第一次看到iter(bytes)的写法,虽然想象得到同为串的字节串(书中称之为字节字符串),肯定可以迭代,但是字符串迭代得到的元素是一个个的字符,而字节串迭代的结果是一个字节对应的int值。
[i for i in b] # 1.71 µs
[c for c in s] # 1.83 µs
iter(data)
Out[97]: <bytes_iterator at 0x1a3aa2182b0>
字节串迭代的速度更快,另外iter或者推导式,他们产生的迭代器确实是如同定义的一般,不去接收执行,就不会执行迭代。
Unicode文本文件
文本文件用于处理各种基于文本的数据,从备忘录到邮件内容到JSON再到XML。
凡是使用文本的地方,就会用到编码,所以编码是任何计算机操作都会接触到的地方。
Windows历代内核字符编码
如果一个文件的文本没有采用我们所用平台的默认编码,为了访问该文件中非ASCII编码的Unicode文本,我们可以传入一个编码名参数。在这种模式下,Python文本文件自动在读取和写入的时候采用你所指定的编码范式进行编解码。
S='sp\xc4m'
S
Out[2]: 'spÄm'
S[2]
Out[3]: 'Ä'
file=open('unidata.txt','w',encoding='utf-8')
file.write(S)
Out[5]: 4
file.close()
text=open('unidata.txt',encoding='utf-8').read()
text
Out[13]: 'spÄm'
len(text)
Out[14]: 4
这些自动编码和解码能够满足你的需求。
pen('unidata.txt').read() Out[8]: 'sp脛m' open('unidata.txt',encoding='gbk').read() Out[11]: 'sp脛m' '\xc4'.encode('ascii',errors='namereplace') Out[15]: b'\\N{LATIN CAPITAL LETTER A WITH DIAERESIS}' '\xc4'.encode('ascii',errors='namereplace').decode('raw_unicode_escape') Out[17]: '\\N{LATIN CAPITAL LETTER A WITH DIAERESIS}' eval("'\\N{LATIN CAPITAL LETTER A WITH DIAERESIS}'") Out[19]: 'Ä'因为上面有使用到\xc4,于是我整理了下转义字符,同时发现了\N{…}这种写法
转义字符
namereplace \N{…}
Unicode blocks 统计
因为文件在仅传输时处理编码事务,所以你可以直接把文本当作内存中的一个由字符构成的简单字符串进行处理,而不必担心其中的Unicode编码原型。如果有需要,你同样可以通过进入二进制模式来查看文件中真正存储的内容。
字符串在内存中的模式与系统、程序所使用的核心字符编码有关,例如Python3使用Unicode高位扩充为字符编码,Windows简体中文版在早期使用GB2312(Win 3.2)、GBK(Win95~ME)、UCS-2(Win NT 3.51~NT 5.2 XP),现在使用UTF-16(Win NT 6.0 Vista~NT 10)
Windows历代内核字符编码
raw=open('unidata.txt','rb').read()
raw
Out[12]: b'sp\xc3\x84m'
len(raw)
Out[13]: 5
text=open('unidata.txt',encoding='utf-8').read()
text
Out[15]: 'spÄm'
text.encode('utf-8')
Out[16]: b'sp\xc3\x84m'
raw.decode('utf-8')
Out[18]: 'spÄm'
text.encode('latin-1')
Out[19]: b'sp\xc4m'
text.encode('utf-16')
Out[20]: b'\xff\xfes\x00p\x00\xc4\x00m\x00'
len(text.encode('latin-1')),len(text.encode('utf-16'))
Out[21]: (4, 10)
b'\xff\xfes\x00p\x00\xc4\x00m\x00'.decode('utf-16')
Out[22]: 'spÄm'
更多内容注入walkers、listers等工具,之后章节讨论
其他类文件工具
open函数能够实现在Python中对绝大多数文件进行处理。
对于更高级的任务,Python还有额外的类文件工具:
管道、先进先出队列(FIFO)、套接字、按键值访问的文件、持久化对象shelve、基于描述符的文件、关系型数据库接口、面向对象数据库接口等。
例如,描述符文件(descriptor file)支持文件加锁和其他的底层工具
套接字提供网络和进程间通信的接口。
其它核心类型
集合
PEP 218 – Adding a Built-In Set Object Type
PEP: 218 Title: Adding a Built-In Set Object Type Author: gvwilson at ddj.com (Greg Wilson), python at rcn.com (Raymond Hettinger) Status: Final Type: Standards Track Created: 31-Jul-2000 Python-Version: 2.2 集合是在相对较新的内置类型,他不是映射也不是序列,是唯一的不可变的对象的无序集合。
集合可以通过调用内置set函数创建,或者使用集合字面量和表达式创建,它支持一般的数学集合操作。
X=set('spam')
Y={'h','a','m'}
X,Y
Out[3]: ({'a', 'm', 'p', 's'}, {'a', 'h', 'm'})
X&Y
Out[4]: {'a', 'm'}
X|Y
Out[5]: {'a', 'h', 'm', 'p', 's'}
X-Y
Out[6]: {'p', 's'}
X>Y
Out[7]: False
{n**2 for n in [1,2,3,4]}
Out[8]: {1, 4, 9, 16}
print({n**2 for n in [1,2,3,4]})
{16, 1, 4, 9}
集合的无序性:他在生成和插入数值的时候,是会使用hash对元素进行排列的,而如果是一串相邻的数,看似是顺序的,只是因为他们的hash是邻近的,从而顺序的放在了一起,如果一个远离他们的数值,我并不确定他们是如何对hash进行排列,但我确定他们不是一定顺序输出的。
Python 关于set的数字元素的顺序问题

set的元素插入可视化
至于算法,自己领悟一下,不可变的是到达预定空间,就会移至新的空间,此时会进行一次排序。排序结果,每几个有关联性的元素,主要是元素的hash值间隔长度与分配空间之间的关系。可能有几组关联,也可能一个关联也没有,几组关联交叉存入,当输入在其区间的元素时,就存储至某个固定位置,若此位置被占用,则向后移动至空位。因为有锚点,所以之后元素插入位置被占用,他所需要搜索的长度也并不是很长。不知住了锚点,是否还有其他关联位置的方法。例如我没有找到标记锚点的数据区域,如果该区域还有一个类似字典结构的话!?
集合id:3011062226048 数据id:3011061983280 数值是:12 数字:指定数值,字符:跳出,回车:继续48 __ __ __ __ __ __ __ __ 40 __ 10 __ 76 __ __ __ 48 __ __ __ 20 __ __ __ __ __ __ __ 60 __ __ __ 集合id:3011062226048 数据id:3011061983280 数值是:62 数字:指定数值,字符:跳出,回车:继续16 __ __ __ __ __ __ __ __ 40 __ 10 __ 76 __ __ __ 48 16 __ __ 20 __ __ __ __ __ __ __ 60 __ __ __ 集合id:3011062226048 数据id:3011061983280 数值是:51 数字:指定数值,字符:跳出,回车:继续19 __ __ __ __ __ __ __ __ 40 __ 10 __ 76 __ __ __ 48 16 __ 19 20 __ __ __ __ __ __ __ 60 __ __ __ 集合id:3011062226048 数据id:3011061983280 数值是:4 数字:指定数值,字符:跳出,回车:继续18 __ __ __ __ __ __ __ __ 40 __ 10 __ 76 __ __ __ 48 16 18 19 20 __ __ __ __ __ __ __ 60 __ __ __
集合可以当作处理例如过滤重复对象,分离集合间差异,进行非顺序的等价判断等任务的利器
list(set([1,2,1,3,1]))
Out[1]: [1, 2, 3]
set('spam')-set('ham')
Out[2]: {'p', 's'}
set('spam')==set('asmp')
Out[3]: True
'p' in set('spam'),'p' in 'spam','ham' in ['eggs','spam','ham']
Out[4]: (True, True, True)
19 in range(10,30)
Out[5]: True
集合同时支持in函数的成员测试操作。
集合的意义
对比集合的结构图和列表的结构图,判断一个元素是否存在:
列表:列表id-数据区id-遍历数据id-读取数据内容
集合:元素hash-集合id-数据区id-遍历hash
加之貌似集合的hash是有阶段性重新排序和锚点等特性,使得寻找一个指定hash更加高效
固定精度浮点数 & 分数
PEP 327 – Decimal Data Type
PEP: 327 Title: Decimal Data Type Author: Facundo Batista Status: Final Type: Standards Track Created: 17-Oct-2003 Python-Version: 2.4 并未查到Fraction的PEP信息,但是看到一篇文章,Fraction就是建立在decimal基础上的:
Fraction(1,2): Decimal(1) / Decimal(2)
Python最近添加了一些新的数值类型:
十进制数(固定精度浮点数),decimal:小数,十分之一,十进制分数,小数分数,十进制数
这里表示用十进制表示的浮点数,而不是二进制表示的浮点数。
分数(有一个分子和一个分母的有理数),fraction:打碎的,分裂的。分数。integer:完整的数,整数。
mem.data(decimal.Decimal(9999999999999999999)) ff ff ff ff ff ff ff ff 30 ff ff ff ff ff ff ff 00 00 00 00 00 00 00 00 13 00 00 00 00 00 00 00 01 00 00 00 00 00 00 00 04 00 00 00 00 00 00 00 18 aa 05 39 86 02 00 00 ff ff e7 89 04 23 c7 8a 20 27 70 72 65 5f 72 75 6e 5f 63 6f 64 65 5f 68 6f 6f 6b 27 00 00 00 00 mem.data(decimal.Decimal(10000000000000000000)) ff ff ff ff ff ff ff ff 30 ff ff ff ff ff ff ff 00 00 00 00 00 00 00 00 14 00 00 00 00 00 00 00 02 00 00 00 00 00 00 00 04 00 00 00 00 00 00 00 98 ad 05 39 86 02 00 00 00 00 00 00 00 00 00 00 01 00 00 00 00 00 00 00 6e 5f 63 6f 64 65 5f 68 6f 6f 6b 27 00 00 00 00 mem.data(decimal.Decimal(3.14)) ff ff ff ff ff ff ff ff 30 ff ff ff ff ff ff ff cd ff ff ff ff ff ff ff 34 00 00 00 00 00 00 00 03 00 00 00 00 00 00 00 04 00 00 00 00 00 00 00 78 ee e8 79 a6 01 00 00 e3 65 4a dd 6c 4b 13 23 99 f6 d8 24 1c 2d 2c 00 00 90 d8 e1 8e 1c 00 00 6f 6f 6b 27 00 00 00 00 mem.data(decimal.Decimal('3.14')) ff ff ff ff ff ff ff ff 30 ff ff ff ff ff ff ff fe ff ff ff ff ff ff ff 03 00 00 00 00 00 00 00 01 00 00 00 00 00 00 00 04 00 00 00 00 00 00 00 48 fc 5f 7a a6 01 00 00 3a 01 00 00 00 00 00 00 20 27 70 72 65 5f 72 75 6e 5f 63 6f 64 65 5f 68 6f 6f 6b 27 00 00 00 00 decimal.Decimal(3.14) Out[5]: Decimal('3.140000000000000124344978758017532527446746826171875')这里Decimal(3.14)不是个正确的使用方式,他是传递给Decimal一个float,而Decimal将float的真实内容存储起来。于是显示出来的结果是float的真实结果。如果传递的是字符串’3.14’则存储的是3.14
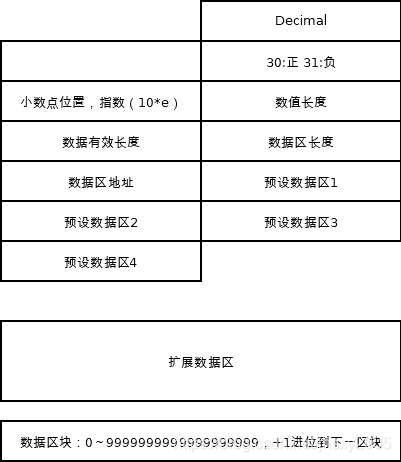
IPython 7.20.0 -- An enhanced Interactive Python.
1/3
Out[1]: 0.3333333333333333
(2/3)+(1/2)
Out[2]: 1.1666666666666665
import decimal
d=decimal.Decimal('3.141')
d+1
Out[5]: Decimal('4.141')
decimal.getcontext().prec=2
decimal.Decimal('1.00')/decimal.Decimal('3.00')
Out[7]: Decimal('0.3333333333333333333333333333')
decimal.getcontext().prec=2
decimal.Decimal('1.00')/decimal.Decimal('3.00')
Out[8]: Decimal('0.33')
from fractions import Fraction
f=Fraction(2,3)
f+1
Out[11]: Fraction(5, 3)
f+Fraction(1,2)
Out[12]: Fraction(7, 6)
这里我专门把IPython的信息带上,因为书中decimal.getcontext().prec=2,在IPython中,不同行上无法生效
而Python和BPython中,可以两次输入而生效

float(f)
Out[19]: 0.6666666666666666
Fraction.from_decimal(decimal.Decimal(3.14))
Out[20]: Fraction(7070651414971679, 2251799813685248)
Fraction.from_float(3.14)
Out[21]: Fraction(7070651414971679, 2251799813685248)
Fraction(3.14)
Out[22]: Fraction(7070651414971679, 2251799813685248)
Fraction.from_decimal(decimal.Decimal('3.14'))
Out[23]: Fraction(157, 50)
Fraction('3.14')
Out[24]: Fraction(157, 50)
Fraction(1,2)
Out[25]: Fraction(1, 2)
float(d)
Out[28]: 3.141
f*2
Out[30]: Fraction(4, 3)
d*2
Out[31]: Decimal('6.282')
decimal.Decimal('nan')
Out[36]: Decimal('NaN')
decimal.Decimal('inf')
Out[37]: Decimal('Infinity')
decimal.Decimal('-inf')
Out[38]: Decimal('-Infinity')
decimal和fraction的数值化,只能使用float
fraction在生成的时候可以使用float和decimal
decimal和fraction,同类型内可以进行运算
decimal支持特殊数值:nan、inf、-inf
decimal 类型存储为一个 12 字节的整数部分、一个 1 位的符号和一个刻度因子。
decimal 类型可以精确地表示非常大或非常精确的小数。大至 1028(正或负)以及有效位数多达 28 位的数字可以作为 decimal 类型存储而不失其精确性。该类型对于必须避免舍入错误的应用程序(如记账)很有用。
而且Decimal()和Fraction(),他们的产生需要导入对应的模块,只能通过函数的方法生成,赋值给一个变量后,其参与的计算拥有了相应的属性,而print的时候也是显示对应的整数、浮点数、分数的常见形式,而非Decimal()和Fraction(),想打印出来,需要使用repr显示出它的真实形态。
>>> from decimal import *
>>> Decimal.from_float(12.222)
Decimal('12.2219999999999995310417943983338773250579833984375')
>>> float(Decimal('12.2219999999999995310417943983338773250579833984375'))
12.222
>>> float(Decimal('12.222222222222222222222'))
12.222222222222221
>>> float(Decimal('12.222222222222222222222222222222222'))
12.222222222222221
>>> Decimal('12.222222222222222222222222222222222')
Decimal('12.222222222222222222222222222222222')
Python decimal模块使用方法详解
fractions类型就是分数
import fractions
>>> fractions.Decimal('1111.22222')
Decimal('1111.22222')
>>> fractions.Decimal(1111.22222)
Decimal('1111.22222000000010666553862392902374267578125')
>>> fractions.Fraction(11)
Fraction(11, 1)
>>> fractions.Fraction(11.5)
Fraction(23, 2)
>>> fractions.Fraction(11.05)
Fraction(3110298492652749, 281474976710656)
>>> import decimal
>>> decimal.Decimal()
Decimal('0')
>>> fractions.Decimal()
Decimal('0')
>>> Fraction(1, 2)+Fraction(1, 3)+Fraction(1, 4)
Fraction(13, 12)
>>> fractions.Fraction('5/6')
Fraction(5, 6)
>>> fractions.Fraction(5/6)
Fraction(7505999378950827, 9007199254740992)
python中进行分数(fraction)运算
Python——Fraction类处理分数
将Fraction完美的转换成Decimal
>>> fractions.Fraction(5/6)
Fraction(7505999378950827, 9007199254740992)
>>> fractions.Decimal(float(fractions.Fraction(5/6)))
Decimal('0.83333333333333337034076748750521801412105560302734375')
>>> 5/(fractions.Decimal(6))
Decimal('0.8333333333333333333333333333')
>>> 5/(fractions.Decimal(1)*6)
Decimal('0.8333333333333333333333333333')
没有函数能够将Fraction直接转换成Decimal,而借助float做中间值则会出现偏差。
但如果在有Decimal的运算中,全部数值都尽可能地进行Decimal化,而达到尽可能高的精度,于是网友有思路将分子分母当作一个除式的一部分,而且加入Decimal元素,于是就达成了尽可能高精度的运算,从而得到从Fraction到Decimal的转换。
若想使用:
>>>Decimal('0')
>>>Fraction(0, 1)
这样的写法
需要:
>>> from decimal import *
>>>Decimal('0')
Decimal('0')
from fractions import *
>>>Fraction(0, 1)
Fraction(0, 1)
这里其实写入的是函数,而非数值,就例如如果不加载模块,无论是函数和数值,Python解释器是无法认可的。这些都是模块扩展的功能,无论是数据类型还是计算处理方式。
bool
PEP 285 – Adding a bool type
PEP: 285 Title: Adding a bool type Author: guido at python.org (Guido van Rossum) Status: Final Type: Standards Track Created: 08-Mar-2002 Python-Version: 2.3 Post-History: 8-Mar-2002, 30-Mar-2002, 3-Apr-2002
1>2,1<2
Out[42]: (False, True)
bool('spam')
Out[43]: True
bool(0)
Out[44]: False
bool(0.0)
Out[45]: False
bool('0')
Out[46]: True
bool('')
Out[47]: False
bool(b'\x00')
Out[48]: True
bool(b'')
Out[49]: False
之前分析decimal结构的时候,我把一串00当作False,搞错了。只有数字0和空时,才是False
None
X=None
print(X)
None
L=[None]*100
L
Out[53]:
[None,
None,
。。。。
None]
书中的结尾是…a list of 100 Nones…],不知是否是真实打印还是也是编辑的缩写。
如何破坏代码的灵活性 检测数据类型的方法
type(L)==type([])
Out[54]: True
type(L)==list
Out[55]: True
isinstance(L,list)
Out[56]: True
我之前也使用过检测类型对一些数据进行判断,如下
type(1)
Out[57]: int
type([1])
Out[58]: list
L=[]
type(L)
Out[60]: list
type(type(L))
Out[61]: type
print(type(L))
<class 'list'>
str(type(L))
Out[63]: ""
repr(type(L))
Out[64]: ""
因为我并不知道type()输出的结果到底是什么,我只能确信同等类型的数据,type结果相同,所以我使用了三个方法中的第一个
但这里书中的意思,在Python中,类型是多态的,既然使用Python,也要用Python的思维去编程,而对类型的检测,不是Python的思维。但有时又确实是需要去做类型检测。这里作者想提示多态这个Python的核心概念之一。
用户定义的类
class Worker:
def __init__(self,name,pay):
self.name=name
self.pay=pay
def lastName(self):
return self.name.split()[-1]
def giveRaise(self,percent):
self.pay*=(1.0+percent)
bob=Worker('Bob Smith',50000)
sue=Worker('Sue Jones',60000)
bob.lastName()
Out[72]: 'Smith'
sue.lastName()
Out[73]: 'Jones'
sue.giveRaise(.10)
sue.pay()
TypeError: 'float' object is not callable
sue.pay
Out[76]: 66000.0
我这里在最后写错了,这个类或者说实例中,存在两个变量和两个方法,方法使用()调用,变量后面不需要加()
Python中,内置的类,即之前介绍的这些类型:str、list等,当内置类无法满足用户的需求时,就需要自定义类,自定义类是建立在内置类的基础上的,例如上面变量的类型,例如上面的变量仍是字符串、整数、浮点数等。
并且Python有类的继承机制,可以让自定义类继承已有的甚至内置的类的特性。这也使得我们无序修改当前的类,只需要继承、扩展、修改即可。
自定义类是Python可选的一个特性,而内置类往往是更简单、更好的工具。毕竟他们是经过严格设计和C语言编译的。
剩余的内容
Python,能够处理的所有事情,都是某种类型的对象。
我们目前所见的那些对象类型只是Python核心类型集合中的一部分。
其他还有与程序执行相关的对象:函数、模块、类、编译过的代码
有的是由导入的模块函数实现的,而不是Python的语法:文本模式、数据库接口、网络连接等
此前学过的部分中,对象仅是对象,并不一定是面向对象。面向对象要求有继承和类声明的概念。
Python的核心对象是可能碰到的每一个Python脚本的重点,是更多非核心类型的基础。
本章小结
本章初步介绍了Python的核心类型对象,以及通用操作(索引、分片的序列操作),特定操作(字符串分割、列表增加)。一些关键术语,入不可变性、序列、多态。
Python的核心类型,比C这样底层语言中的对应不凡,有更好的灵活性也更强大。
列表和字典省去了底层语言的细节。
列表是其他对象的有序结合。
字典是通过键而不失位置进行索引。
字典和列表都能够嵌套,能够增大或减小,可以包含任意类型的对象。
他们的内存空间在不用后会被自动清理。
字符串和文件联手支持者二进制和文本文件的多样性
本章习题
1、列举4个Python中核心数据类型的名称
2、为什么我们把他们称作“核心”数据类型
3、“不可变性”代表了什么,哪三种Python的核心类型被认为是具有不可变性的
4、“序列”是什么意思,哪三种Python的核心类型被认为是这个分类中的
5、“映射”是什么意思,哪三种Python的核心类型是映射
习题解答:
1、数字、字符串str、列表list、字典dict、元组tuple、文件open、集合set
类型type、NoneType、布尔bool
数字:整数int(integer)、浮点数float(浮动的)、复数complex(1+1j)、分数Fraction、十进制数Decimal
多种字符串:字节串bytes
2、他们被认作是“核心”类型是因为他们是Python语言自身的一部分,且总是有效的。
其他的对象通常需要导入模块,而核心类型是用特定的语法创建。
除了open(),尽管他通常也被认为是一种核心类型
Python 内置方法、类型 小归纳
3、不可变性的对象是在其创建后不能被改变的对象。
数字、字符串(包含字节串)、元组都属于这个分类。
对于不可变类型的分析
而数字、字符串是核心类型中的核心类型,其他的核心类型也是在其基础上建立的。
所以他们定义为不可变的,更加安全,元组同理。
4、序列是系列具有位置顺序的对象的集合体。
字符串、列表、和元组都是Python中的序列。
他们拥有一般的序列操作:索引、合并、分片等;又各自有自己的类型特定的方法调用
可迭代性意味着任何一个能够按需提供他的内容的物理或虚拟序列
另外还有二进制序列类型 — bytes, bytearray, memoryview
可迭代性iterable,可迭代对象 能够逐一返回其成员项的对象。可迭代对象的例子包括所有序列类型 (例如list, str 和tuple) 以及某些非序列类型例如dict, 文件对象 以及定义了 iter() 方法或是实现 了序列 语义的 getitem() 方法的任意自定义类对象。
5、映射,表示将键与相关值相互关联映射的对象。
字典是核心类型集中,唯一的映射类型。映射没有从左到右的未知顺序,他们支持通过键获取数据,并包含了类型特定的方法调用
6、多态意味着一个运算符(如‘+’)的意义取决于包操作的对象。
这是让你用好Python的关键思想
之一。不要把代码限制在特定的类型上,使代码自动适用于多种类型。之前书中提到不建议使用type的时候,貌似指不只是运算符是多态的,还是不容易理解。
iterable
这些问题中没有提到集合。
严格地说,我认为集合不该称之为序列,因为是无序的,但通常会看到无序序列这个说法
在一些文章中提到一些词:可迭代对象、可迭代的,多项集,容器。
“容器”是指:字符串、列表、元组、字典等,指能包含内容的集合
Python基础-字符串操作和“容器”的操作
所有(有序)序列,支持索引、切片、重复、大小比较
所有可变容器都支持合并、删除元素、追加元素
所有容器支持len、max、min、in、not in、==、!=
集合的大小比较是包含等意思
max('123香')
Out[16]: '香'