Pytorch从零开始实战16
Pytorch从零开始实战——ResNeXt-50算法的思考
本系列来源于365天深度学习训练营
原作者K同学
对于上次ResNeXt-50算法,我们同样有基于TensorFlow的实现。具体代码如下。
引入头文件
import numpy as np
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Input, Dense, Dropout, Conv2D, MaxPool2D, Flatten, GlobalAvgPool2D, concatenate, \
BatchNormalization, Activation, Add, ZeroPadding2D, Lambda
from tensorflow.keras.layers import ReLU
from tensorflow.keras.optimizers import Adam
import matplotlib.pyplot as plt
from tensorflow.keras.callbacks import LearningRateScheduler
from tensorflow.keras.models import Model
分组卷积模块
# 定义分组卷积
def grouped_convolution_block(init_x, strides, groups, g_channels):
group_list = []
# 分组进行卷积
for c in range(groups):
# 分组取出数据
x = Lambda(lambda x: x[:, :, :, c * g_channels:(c + 1) * g_channels])(init_x)
# 分组进行卷积
x = Conv2D(filters=g_channels, kernel_size=(3, 3),strides=strides, padding='same', use_bias=False)(x)
# 存入list
group_list.append(x)
# 合并list中的数据
group_merage = concatenate(group_list, axis=3)
x = BatchNormalization(epsilon=1.001e-5)(group_merage)
x = ReLU()(x)
return x
残差单元
# 定义残差单元
def block(x, filters, strides=1, groups=32, conv_shortcut=True):
if conv_shortcut:
shortcut = Conv2D(filters * 2, kernel_size=(1, 1), strides=strides, padding='same', use_bias=False)(x)
# epsilon为BN公式中防止分母为零的值
shortcut = BatchNormalization(epsilon=1.001e-5)(shortcut)
else:
# identity_shortcut
shortcut = x
# 三层卷积层
x = Conv2D(filters=filters, kernel_size=(1, 1), strides=1, padding='same', use_bias=False)(x)
x = BatchNormalization(epsilon=1.001e-5)(x)
x = ReLU()(x)
# 计算每组的通道数
g_channels = int(filters / groups)
# 进行分组卷积
x = grouped_convolution_block(x, strides, groups, g_channels)
x = Conv2D(filters=filters * 2, kernel_size=(1, 1), strides=1, padding='same', use_bias=False)(x)
x = BatchNormalization(epsilon=1.001e-5)(x)
x = Add()([x, shortcut])
x = ReLU()(x)
return x
堆叠残差单元
# 堆叠残差单元
def stack(x, filters, blocks, strides, groups=32):
# 每个stack的第一个block的残差连接都需要使用1*1卷积升维
x = block(x, filters, strides=strides, groups=groups)
for i in range(blocks):
x = block(x, filters, groups=groups, conv_shortcut=False)
return x
网络搭建
# 定义ResNext50(32*4d)网络
def ResNext50(input_shape, num_classes):
inputs = Input(shape=input_shape)
# 填充3圈0,[224,224,3]->[230,230,3]
x = ZeroPadding2D((3, 3))(inputs)
x = Conv2D(filters=64, kernel_size=(7, 7), strides=2, padding='valid')(x)
x = BatchNormalization(epsilon=1.001e-5)(x)
x = ReLU()(x)
# 填充1圈0
x = ZeroPadding2D((1, 1))(x)
x = MaxPool2D(pool_size=(3, 3), strides=2, padding='valid')(x)
# 堆叠残差结构
x = stack(x, filters=128, blocks=2, strides=1)
x = stack(x, filters=256, blocks=3, strides=2)
x = stack(x, filters=512, blocks=5, strides=2)
x = stack(x, filters=1024, blocks=2, strides=2)
# 根据特征图大小进行全局平均池化
x = GlobalAvgPool2D()(x)
x = Dense(num_classes, activation='softmax')(x)
# 定义模型
model = Model(inputs=inputs, outputs=x)
return model
对于残差单元中的代码,提出一个问题:当conv_shortcut=False的时候,在执行Add操作时,理论上通道数不一致,为什么代码不报错?
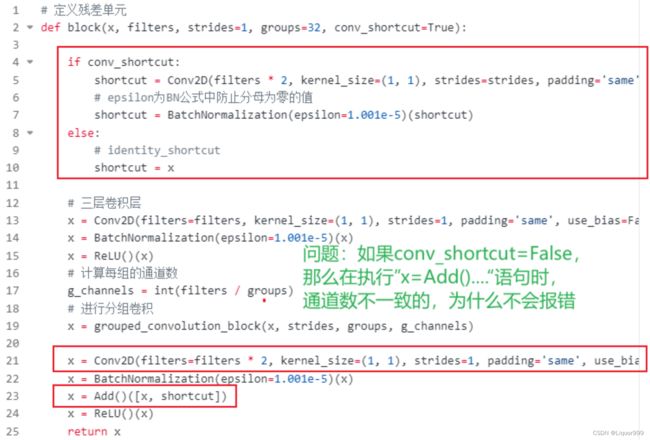
答:这主要是跟下面堆叠残差单元的代码有关系,每个stack第一轮总会令conv_shortcut为True,使得x通道数进行扩展,而后面循环的时候传入的filters还是这个函数的实参,没有发生变化,但由于conv_shortcut为False,此时shortcut的通道数是与上面的x一致,所以在Add的时候,代码不会报错。
def stack(x, filters, blocks, strides, groups=32):
# 每个stack的第一个block的残差连接都需要使用1*1卷积升维
x = block(x, filters, strides=strides, groups=groups)
for i in range(blocks):
x = block(x, filters, groups=groups, conv_shortcut=False)
return x
本文只是对ResNeXt-50算法的部分代码进行思考,学习过程中需要积极思考与探索,以提高能力和解决问题。