数据导入与预处理实验
在泰坦尼克号沉船事件中,船上的人员都惊恐逃生,但是救生艇数量有限,无法让所
有人都登艇,副船长命令女士和小孩优先登艇,所以是否获救并非随机的,而是基于
一些背景及外界因素来排列先后顺序。
目前,泰坦尼克号沉船事件中遇难和生还人数及其信息部分记录在文件
Titanic.csv文件中,请读入该数据并对该数据进行预处理。
已知该数据集中的乘客属性信息解释如下表所示:
表1. 泰坦尼克号乘客属性信息
序号 属性名称 属性描述
1 PassengerID 乘客的编号
2 Survived 生存的标号,数值1表示生存,数值0表示遇难
3 Pclass 船舱等级,数值1~3分别表示头等舱、二等舱和三等舱
4 Name 乘客姓名
5 Sex 乘客性别,female代表女性,male代表男性
6 Age 乘客年龄,乘客最小年龄为4个月,最大年龄为80岁
7 SibSp 兄弟姐妹的数量,最小为0,最大为8
8 Parch 父母和小孩的数量,最小为0,最大为6
9 Ticket 船票号
10 Fare 船票价格
11 Cabin 船舱号
12 Embarked 登船港口,分别为S港、C港和Q港
1、读入本地.csv文件;
将 文件“ Titanic. . csv ”存放到本地磁盘,例如“ D:\ \ data\ \ Titanic.csv” ” 。
2、根据读入文件进行数据清洗;
1 ) 初步统计: 为了更深入的了解数据,请用 describe 方法得到数据的一些统计值
2 ) : 缺失值处理: 观察数据集中每个属性的数据样本的数量及数据类型,找到缺失值,
并试着用0 0 、平均值或上一列/ /; 下一列值去填充; ( 提示:每次数据处理 后,要检查元数
据是否更改 ,并 备份 更改后的 数据 )
3 ) EDA 分析:通过数据的初步观察可以发现,获救的乘客不到总数的一半,三等舱乘
客人数最多,遇难和获救的人年龄跨度很大,3个不同等级船舱的乘客年龄总体趋势似
乎也一致,在二等舱和三等舱中,20岁乘客最多,在头等舱中,40岁的乘客最多,3个
港口登船人数按照S、C、Q的顺序递减,而且S港远多于C港和Q港。
请查看数据集并验证上述观察结果。(请验证结果进行截图粘贴到实验 报告 中。)
4) 特征因子化:数据集中的某些字符串特征值不便于下一步分析,需要转化为数值
型特征值,例如, Sex 属性的取值是 female 和 male ,需要分别转化为1 和0 , Embarked 属
性的S \ C\ Q 值需要分别转化为0 0 /1/2 ,请完成上述操作。
5) 数据集保存: 请将清洗完成的数据集保存到你的U 盘
import pandas as pd
data = pd.read_csv('E:/桌面文件/Titanic.csv')
print(data)
data.describe()| PassengerId |
Survived |
Pclass |
Age |
SibSp |
Parch |
Fare |
|
| count |
891.000000 |
891.000000 |
891.000000 |
714.000000 |
891.000000 |
891.000000 |
891.000000 |
| mean |
446.000000 |
0.383838 |
2.308642 |
29.699118 |
0.523008 |
0.381594 |
32.204208 |
| std |
257.353842 |
0.486592 |
0.836071 |
14.526497 |
1.102743 |
0.806057 |
49.693429 |
| min |
1.000000 |
0.000000 |
1.000000 |
0.420000 |
0.000000 |
0.000000 |
0.000000 |
| 25% |
223.500000 |
0.000000 |
2.000000 |
20.125000 |
0.000000 |
0.000000 |
7.910400 |
| 50% |
446.000000 |
0.000000 |
3.000000 |
28.000000 |
0.000000 |
0.000000 |
14.454200 |
| 75% |
668.500000 |
1.000000 |
3.000000 |
38.000000 |
1.000000 |
0.000000 |
31.000000 |
| max |
891.000000 |
1.000000 |
3.000000 |
80.000000 |
8.000000 |
6.000000 |
512.32920 |
data.isnull().any(axis=0)
#可以看到Age,Cabin,Embarked列存在空值
#用copy函数备份数据
df=data.copy()
#用均值填充Age空值
mean=data['Age'].mean()
data['Age']=data['Age'].fillna(mean)
copy1=data.copy()#备份本次填充的数据
print(copy1)
data.isnull().any(axis=0)#可以看到Age列的空值已经被填充
#用0填充Age列空值
data=df
data['Age']=data['Age'].fillna(0)
copy2=data.copy()
print(copy2)
data.isnull().any(axis=0)#可以看到Age列的空值已经被填充
#用上一行相邻值填充空值
data=df
data['Age']=data['Age'].fillna(method='ffill')
data['Cabin']=data['Cabin'].fillna(method='ffill')
data['Embarked']=data['Embarked'].fillna(method='ffill')
copy3=data.copy()
print(copy3)
data.isnull().any(axis=0)
#用下一行相邻值填充空值
data=df
data['Age']=data['Age'].fillna(method='bfill')
data['Cabin']=data['Cabin'].fillna(method='bfill')
data['Embarked']=data['Embarked'].fillna(method='bfill')
copy4=data.copy()
print(copy4)
data.isnull().any(axis=0)#可以看到所有空值已经被填充
3 EDA 分析:通过数据的初步观察可以发现,获救的乘客不到总数的一半,三等舱乘客人数最多,遇难和获救的人年龄跨度很大,3个不同等级船舱的乘客年龄总体趋势似乎也一致,在二等舱和三等舱中,20岁乘客最多,在头等舱中,40岁的乘客最多,3个港口登船人数按照S、C、Q的顺序递减,而且S港远多于C港和Q港。请查看数据集并验证上述观察结果。(请验证结果进行截图粘贴到实验报告中。)
基于第二问结果,采用均值填充Age列空值,采用向下填充填充Cabin,Emnarked列空值
data=copy1
data['Cabin']=data['Cabin'].fillna(method='bfill')
data['Embarked']=data['Embarked'].fillna(method='bfill')
count=data['Survived'].value_counts(1)
print(count)
#1表示获救,说明只有38.38%获救
count_class=data['Pclass'].value_counts()
print(count_class)
#三等舱人数为491,乘客最多
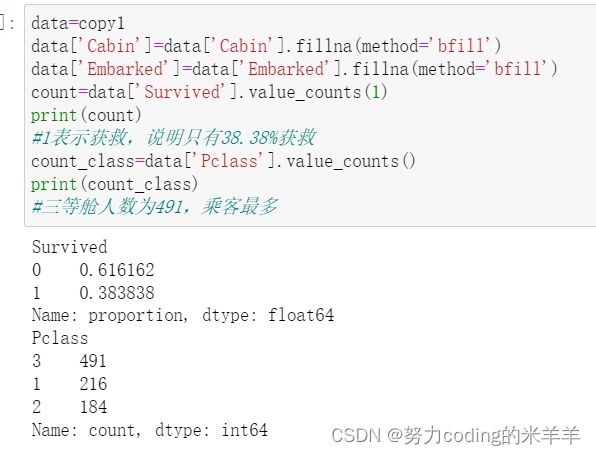
统计获救人数,只有38.38%获救,不足一半,统计船舱人数,三等舱人数为491乘客最多
cal=data.groupby(['Survived','Pclass'])['Age'].agg(['max','min','mean'])
print(cal)
| max |
min |
mean |
||
| Survived |
Pclass |
|||
| 0 |
1 |
71.0 |
2.00 |
40.896074 |
| 2 |
70.0 |
16.00 |
33.266947 |
|
| 3 |
74.0 |
1.00 |
27.417500 |
|
| 1 |
1 |
80.0 |
0.92 |
34.784615 |
| 2 |
62.0 |
0.67 |
26.076166 |
|
| 3 |
63.0 |
0.42 |
23.232689 |
按照舱等级和存活分组,通过均值可以看到遇难和获救的人年龄跨度很大,年轻的人生还的占比更大
import matplotlib.pyplot as plt
grouped= data.groupby('Pclass')
plt.boxplot([grouped.get_group(name)['Age'] for name in grouped.groups])
plt.xticks(range(1, len(grouped.groups) + 1), grouped.groups.keys())
plt.show()
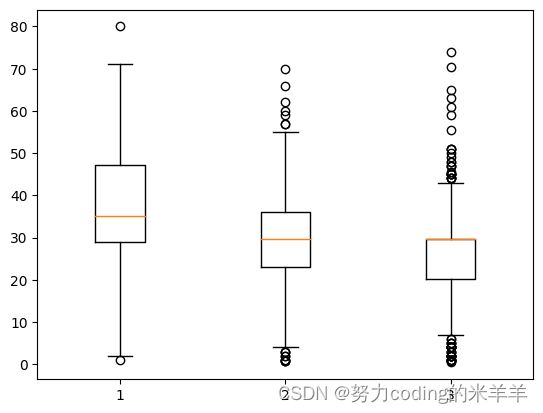
按船舱分组,绘制有关Age列的箱线图,以观察不同船舱的年龄分布规律,在二等舱和三等舱中,20岁乘客较多,在头等舱中,40岁的乘客较多
embarked_count=data['Embarked'].value_counts()
print(embarked_count)

QCS港口登船人数为645,169,77,依次递减,且Q港口远大于C,S港口
4特征因子化:数据集中的某些字符串特征值不便于下一步分析,需要转化为数值型特征值,例如,Sex 属性的取值是 female 和 male ,需要分别转化为1和0 , Embarked 属性的S \C \Q 值需要分别转化为0/1/2,请完成上述操作。
sex_encoding = {'male': 0, 'female': 1}
embarked_encoding = {'S': 0, 'C': 1, 'Q': 2}
data['sex_encoded'] = data['Sex'].map(sex_encoding)
print(data['sex_encoded'])
data['embarked_encoded'] = data['Embarked'].map(embarked_encoding)
print(data['embarked_encoded'])

数据集保存: 请将清洗完成的数据集保存到你的U 盘
data.to_csv('E:/桌面文件/Tantic(已清洗).csv',encoding="GBK")