postgresql_internals-14 学习笔记(五)Buffer Cache
新年的第一篇博客~
一、 Buffer Cache简介
1. 主要用途
调和内存(ns级)与磁盘(ms级)间的速度差异。
pg不仅用自己的buffer cache,也用os cache,所以它使用了“双缓存”,这也是很多文档推荐shared_buffer参数只设为内存25%(通常不超过16G)的原因。
2. os参数
-
shmall # 单个共享内存段的最大大小(字节为单位) shmmax # 服务器上所有进程可以使用的共享内存的总页数推荐设置:将shmall设置为总内存的一半,太小会导致PG服务启动报错
设置脚本 vi shmsetup.sh
#!/bin/bash
page_size=`getconf PAGE_SIZE`
phys_pages=`getconf _PHYS_PAGES`
shmall=`expr $phys_pages / 2`
shmmax=`expr $shmall \* $page_size`
echo kernel.shmmax = $shmmax
echo kernel.shmall = $shmall执行脚本
./shmsetup >> /etc/sysctl.conf
sysctl -p3. db参数
估计共享内存消耗时,最需要关注的是shared_buffers的取值(调整后需重启生效)。
在pg中,buffer cache miss不意味着一定有物理IO,它还可以用到os cache,当然os cache不会按照db buffer cache那套重置和剔除策略,是用os自己的。
通常建议是将shared_buffers初始值设置为os内存的1/4,之后根据压测和运行情况调整。
- 查看shared_buffers
show shared_buffers;
select name,setting,unit,current_setting(name) from pg_settings where name='shared_buffers';
current_setting()函数和show 命令一样,用来显示配置的基本信息,也可以在查询中使用。
所有操作系统都给予应用一种强制从高速缓存写入磁盘的方法
- wal_sync_method参数决定PG如何请求内核强制将WAL更新到磁盘

二、 Buffer Cache设计
1. Buffer Cache结构
Buffer Cache位于共享内存中,所有进程均可访问
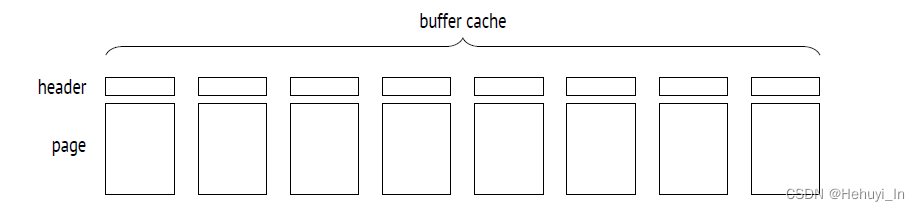
header包含以下信息:
- 页的物理位置(文件id、fork、fork中的块号)
- 该页是否为脏页
- buffer使用计数
- pin count (or reference count)
2. pg_buffercache插件
pg_buffercache插件可以实时检查共享缓冲区
CREATE EXTENSION pg_buffercache;- 共享的系统目录被显示为属于数据库0
- 缓冲区是所有数据库共享,通常会有不属于当前数据库的关系的页面
- 可以与pg_class关联,将连接限制于reldatabase等于当前数据库 OID 或零的行
注意:经常读取这个视图还是会对数据库性能产生一些影响
可以通过查看系统shared_buffers的大小来确认该模块是否工作正常(db刚启动时除外):
select setting, unit from pg_settings where name = 'shared_buffers';
select count(*) from pg_buffercache;
创建一个简单函数帮助查看
CREATE FUNCTION buffercache(rel regclass)
RETURNS TABLE(
bufferid integer, relfork text, relblk bigint,
isdirty boolean, usagecount smallint, pins integer
) AS $$
SELECT bufferid,
CASE relforknumber
WHEN 0 THEN 'main'
WHEN 1 THEN 'fsm'
WHEN 2 THEN 'vm'
END,
relblocknumber,
isdirty,
usagecount,
pinning_backends
FROM pg_buffercache
WHERE relfilenode = pg_relation_filenode(rel)
ORDER BY relforknumber, relblocknumber;
$$ LANGUAGE sql;3. 测试案例
CREATE TABLE cacheme(id integer) WITH (autovacuum_enabled = off);
INSERT INTO cacheme VALUES (1);
SELECT * FROM buffercache('cacheme');
SELECT usagecount, count(*)
FROM pg_buffercache
GROUP BY usagecount
ORDER BY usagecount;
usagecount为空代表free buffer
三、 cache命中与未命中
pg通过哈希表定位cache中的页,hash key由文件id、fork、fork中的块号(上面提到的header内容)组成。
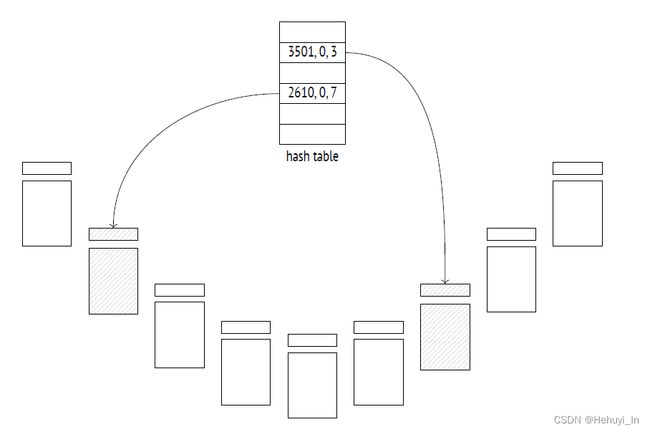
每当使用到cache中的页,usagecount会增加
EXPLAIN (analyze, buffers, costs off, timing off, summary off) SELECT * FROM cacheme;
SELECT * FROM buffercache('cacheme');
使用游标时,则会用到cache pin
BEGIN;
DECLARE c CURSOR FOR SELECT * FROM cacheme;
FETCH c;
SELECT * FROM buffercache('cacheme');
如果无法pin到该页,通常pg会跳过并选择下一个页。
vacuum操作中有时可以看到,另开一个会话
VACUUM VERBOSE cacheme;
由于游标还未关闭,这些页不能从pinned buffer中移除,因此会被跳过。
但如果是必须将这些页从pinned buffer中移除的操作(例如vacuum freeze),则会申请获得排他闩锁,被阻塞直到将这些页成功移除。

提交游标会话,可以看到vacuum freeze随即执行成功,并且pins全变为0。

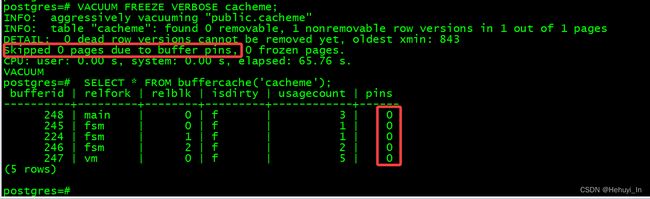
另外,插入数据并不会影响pin

重启pg,再次执行上面查询

read表示从磁盘中读取,dirtied表示页已变脏
查看命中情况
SELECT heap_blks_read, heap_blks_hit FROM pg_statio_all_tables WHERE relname = 'cacheme';
四、 buffer查找与驱逐
为一个page选择buffer有两种可能场景:
- 服务刚启动,所有buffer都是空的
- 一段时间后,没有了free buffer,此时pg就要选择一些页,将它们驱逐出buffer
每当buffer被访问,其usage count会+1,每当buffer manager尝试驱逐页时,会将buffer的usage count - 1,最先被减到0的说明最不常使用,会被驱逐。
当然,如果所有buffer的usage count都较大,buffer manager不可能一直循环去减,pg给它设了上限,最多循环5次。
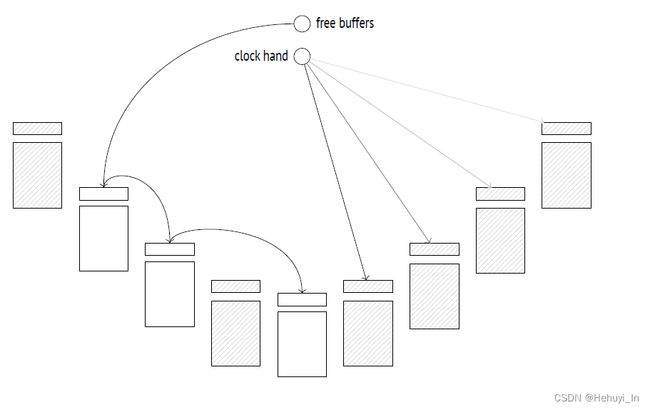
选择了要驱逐的页后,如果不是脏页,则删除该页与hash table的引用关系;如果是脏页,还需将数据写回disk。然后,buffer manager将新页读入找到的buffer。
五、 Bulk Eviction and buffer ring 大规模驱逐与环形缓冲区
1. 为什么需要buffer ring
试想按照前面的方法,如果是突然读入一个大表,可能会将buffer中的绝大多数页都驱逐走,而如果大表只是简单查询一次,这样做会得不偿失。在oracle 11g中引入了direct path read避免这种问题,而在pg中,使用的则是环形缓冲区(buffer ring)。
buffer ring由特定大小的buffer数组组成,顾名思义它是环形的,就算进行buffer驱逐也只会在这个环内进行。
2. 3种驱逐策略:
- Bulk reads strategy:用于大表(size超过1/4 buffer cache的表)的顺序扫描,使用256KB(32个标准页)的 buffer ring。这种策略不支持将脏页写入磁盘以释放buffer,而是将ring中的buffer替换为另一个,这样不需要等IO完成,速度会更快。
- Bulk writes strategy:用于COPY FROM,CTAS,CREATE MATERIALIZED VIEW等大量写入的命令,以及会造成表rewrite的ALTER TABLE语句。pg默认为这些操作分配16MB的buffer ring(2048个标准页),但不会超过buffer cache的1/8。
- Vacuuming strategy:用于需要进行全表扫描的vacuum操作,使用256KB(32个标准页)的 buffer ring。
3. 案例
shared_buffers大小默认是128MB(16384 pages),按照规则1,超过1/4即4096 pages的表在全表扫描时会采用buffer ring。
CREATE TABLE big(id integer PRIMARY KEY GENERATED ALWAYS AS IDENTITY,s char(1000)
) WITH (fillfactor = 10);
INSERT INTO big(s) SELECT 'FOO' FROM generate_series(1,4096+1);
ANALYZE big;
SELECT relname, relfilenode, relpages FROM pg_class WHERE relname IN ('big', 'big_pkey');
重启一下pg,执行全表扫描
EXPLAIN (analyze, costs off, timing off, summary off)
SELECT * FROM big;
SELECT count(*)
FROM pg_buffercache
WHERE relfilenode = pg_relation_filenode('big'::regclass);
可以看到buffer ring刚好占用32个page,256KB
再重启一下,可以看到如果单纯走索引,则不会用到buffer ring
EXPLAIN (analyze, costs off, timing off, summary off)
SELECT id FROM big;
SELECT count(*)
FROM pg_buffercache
WHERE relfilenode = pg_relation_filenode('big'::regclass);
查询各表的缓存情况
SELECT c.relname,
count(*) blocks,
round( 100.0 * 8192 * count(*) /
pg_table_size(c.oid) ) AS "% of rel",
round( 100.0 * 8192 * count(*) FILTER (WHERE b.usagecount > 1) /
pg_table_size(c.oid) ) AS "% hot"
FROM pg_buffercache b
JOIN pg_class c ON pg_relation_filenode(c.oid) = b.relfilenode
WHERE b.reldatabase IN (
0, -- cluster-wide objects
(SELECT oid FROM pg_database WHERE datname = current_database()))
AND b.usagecount IS NOT NULL
GROUP BY c.relname, c.oid
ORDER BY 2 DESC
LIMIT 10;
六、 Local Cache本地缓存
由于临时表的数据只会被单个进程看到,因此它并不使用前面提到的buffer机制,而使用local cache。其最大值是由temp_buffers参数决定的。

如果你在执行计划中看到了local,就说明它使用了local cache。
CREATE TEMPORARY TABLE tmp AS SELECT 1;
EXPLAIN (analyze, buffers, costs off, timing off, summary off) SELECT * FROM tmp;
七、 缓存预热 Cache Warming
预热功能使用pg_prewarm模块,将数据缓存至os或pg缓冲区
1. 安装与简介
CREATE EXTENSION pg_prewarm;
-- 注意先show查看下有没设置别的插件
ALTER SYSTEM SET shared_preload_libraries = 'pg_prewarm';
-- 重启db生效
show shared_preload_libraries;
如果没有修改过pg_prewarm.autoprewarm设置,在pg启动时会自动启动一个auto-prewarm leader。如果设置了pg_prewarm.autoprewarm_interval,该进程会间隔指定秒数将cache的page刷入磁盘。

如果没有设置,默认不会预热表
SELECT count(*)
FROM pg_buffercache
WHERE relfilenode = pg_relation_filenode('big'::regclass);
2. pg_prewarm函数
pg_prewarm(
regclass,
mode text default 'buffer',
fork text default 'main',
first_block int8 default null,
last_block int8 default null) RETURNS int8- 参数1:要预热的表
- 参数2:要使用预热的方法(3种)
- 对操作系统发出异步prefetch请求
- 读取块的请求范围,但可能会较慢
- 缓冲区将请求的块范围(执行的查询)读入数据库缓冲区缓存中。
- 参数3:relation fork被预热
- 参数4:预热的第一个块号
- 参数5:预热的最后一个块号
- 返回值:prewarm块的数量
最简单的用法
SELECT pg_prewarm('big');
这些数据会被dump到$PGDATA/autoprewarm.blocks文件中,可以等待autoprewarm leader进程完成,也可以手动dump。
SELECT autoprewarm_dump_now();
这个数字大于4097是因为所有用到的buffer都dump了,文件是文本格式,可以查看,包含了database,tablespace,file,segment ID

重启,再查看big表预热情况


预热数据也没有对缓存驱逐的特殊保护,其他系统活动可能会在读取后不久将预热块驱逐出去;反之,预热也可能从buffer中驱逐其他数据。因此,预热通常在启动时(当缓存大部分为空时)最有用。
3. os缓存插件pgfincore
pgfincore用于查看os cache中的对象信息,以及将db中的表或索引直接缓存到os cache中,具体可以参考:https://github.com/klando/pgfincore
参考
PGCE课程《高速缓存》