阿里云实时计算企业级状态存储引擎 Gemini 技术解读
本文整理自阿里云 Flink 存储引擎团队李晋忠,兰兆千,梅源关于阿里云实时计算企业级状态存储引擎 Gemini 的研究,内容主要分为以下五部分:
- 流计算状态访问的痛点
- 企业级状态存储引擎
- GeminiGemini 性能评测&线上表现
- 结语
- 参考
一、流计算状态访问的痛点
Flink 作为有状态的流计算系统,状态存储引擎在其中扮演着重要角色。Flink 中状态 (State) 用来存储计算的中间结果或者历史的事件序列(如图 1-1 所示)。 以两个最常见的场景为例:
- 聚合分析类 (Agg) 算子中,当流入的数据每次完成计算后,会将当前计算结果存储到状态中,当后续新数据到来时,可以依赖上一次的计算结果做增量计算;
- 双流/多流 Join 类算子中,每条流上的数据,会和其他几条流的历史数据做 Join 条件匹配,所以每条流需要用状态把过去一段时间流入的事件序列全部保存下来。

当 Flink 作业状态规模较大时,状态存储引擎很难把全量状态数据存储到内存中,往往会将部分冷数据保存在磁盘上。内存和磁盘在访问性能和延迟方面的差异是巨大的,IO 访问很容易成为数据处理的瓶颈,在 Flink 计算过程中如果某个算子需要频繁从磁盘上加载状态数据的话,这个算子就很容易成为整个作业吞吐的性能瓶颈。因此,状态存储引擎在很多时候是决定 Flink 作业性能的关键因素。
1. RocksDB 状态后端的问题
目前社区生产可用的状态存储引擎是基于 RocksDB 的实现。RocksDB 作为一个通用的 KV 存储引擎,并不完全适合流式计算场景。我们在实际生产使用和用户反馈中,发现其具有以下痛点:
-
Flink 周期性 Checkpoint 使得 RocksDB 性能变差, 且容易出现 CPU 尖峰,影响集群稳定性。 在 Flink 容错机制中,作业会定期触发 Checkpoint,生成全局状态快照用于故障恢复。Flink 每次触发 Checkpoint 时,会将 RocksDB 内存中的数据刷盘生成新的文件,这会带来很多负面影响:
- 造成不必要的 cache miss,读磁盘变多,性能会变差;
- 内部 Log 整理频率更高,让系统整体的 CPU 和 IO 开销更大;
- 在 Checkpoint 期间容易形成 CPU 尖峰(如图 1-2 所示),导致集群产生突发的资源争抢,用户也很难提前预估合理的集群资源。
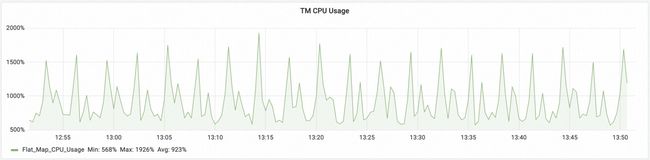
图 1-2. Flink 作业周期性 Checkpoint 导致周期性 CPU 尖峰 -
扩缩并发状态恢复很慢,特别是在缩并发的场景。
以 Flink-1.18 RocksDB 两个并发缩成一个并发为例,缩并发时需要从原先 DB 实例中将有效的 Key-Value 数据遍历出来,插入到新的 DB 实例中,整个过程会涉及很多的 IO 读写操作,速度会相对较慢(注:Flink-1.19 以后预期可以支持文件级别剪裁,对该过程有所加速);特别是对于大状态的场景,这个状态恢复过程可能会达到几十分钟级别。 -
强依赖本地盘,本地盘空间写满后,作业无法正常运行。
RocksDB 中状态数据必须存储在本地磁盘。然而本地盘容量一般是受限的,RocksDB 经常会遇到本地盘写满导致作业无法稳定运行的情况,只能通过扩容磁盘或者扩并发来解决,系统整体的扩展性较差。
二、企业级状态存储引擎 Gemini
阿里云实时计算 Flink 云服务的内核引擎内置了企业级状态存储引擎 Gemini,针对流计算状态访问的特点进行设计,能够解决开源版本状态存储引擎在性能、检查点、作业恢复上的痛点。今年随着阿里云实时计算Flink云服务的全面升级,Gemini 也迎来了全新版本,在性能与稳定性上有了新的突破。新版 Gemini 经历了阿里巴巴集团和阿里云客户的大量生产实践验证,在各场景下性能、易用性和稳定性都显著优于开源版本的状态存储引擎。
1. 核心架构
Gemini 整体架构上仍采用磁盘为主,内存作为 Cache 的方案(如图 2-1 所示)。Write Buffer 采用紧密内存结构的哈希索引,在中小状态下相比于排序索引有显著的性能优势。新版 Gemini 通过改进磁盘数据存储结构,重点优化了大状态场景下的引擎性能。它基于流计算特点重新设计文件格式,根据常见的业务场景,支持不同的状态过期清理手段,大幅优化了状态数据的压缩和编码效率,降低状态大小,有效提升了状态访问性能。
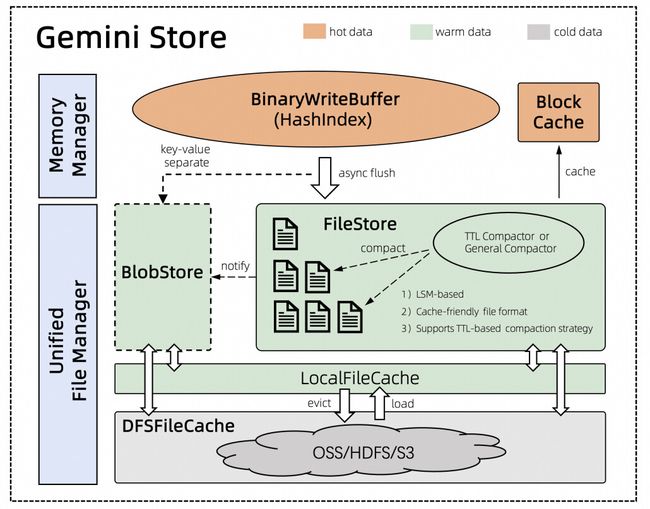
2. 存算分离与冷热分离–增强磁盘容量扩展性
在云原生部署环境下,本地磁盘容量一般是有受限的。RocksDB 在设计上需要将全量状态数据存储到本地磁盘中,扩展性较差。Gemini 支持状态数据文件的远端存储和访问,当本地磁盘容量不足时,可以将部分冷数据存储到远端分布式文件系统中,从而可以摆脱本地磁盘的容量限制。用户不必因存储用量不足而采取扩并发的方法,可以节约很多成本。
远端访问的特点是成本较低但性能较差,Gemini 使用了冷热分层的方式来解决这个问题。它会根据历史信息以及流计算特点,将访问频率高的数据保留在本地磁盘内,同时将访问频率低的数据放在远端。这种方式在现有成本开销下做到了最优的性能。
3. 状态懒加载与延迟剪裁–大幅提升启动和扩缩容速度
为了解决大状态场景下作业恢复耗时久,作业断流时间很长的问题,新版 Gemini 提供了状态懒加载(LazyRestore)的功能。如图 2-2 所示,传统的状态恢复方式下,需要等待远端检查点文件同步下载到本地后,用户作业才可以正常运行,处理业务数据。在状态懒加载模式下,状态恢复时只需要下载少量元数据,就可以让作业启动处理用户数据,然后用异步下载的方式将远端检查点文件下载到本地;下载过程中,算子可以直接读远端的状态数据完成计算。

扩缩并发也是用户常见的操作。与简单作业恢复不同的是,扩缩并发涉及到状态的剪裁,即处理冗余数据。不同于 RocksDB 在扩缩并发时需要遍历所需 key-value 数据才能恢复作业,Gemini 可以直接用原有文件进行元数据的拼接,快速恢复 DB 实例,开始处理用户数据;而文件中的冗余数据可以异步进行清理,并且在清理过程中几乎不会对状态读写线程的性能造成影响。这一功能称为状态延迟剪裁。
Gemini 利用状态懒加载以及延迟剪裁能够在作业恢复速度上取得非常大的功效,我们对比一下三种不同的恢复方式(见图 2-3 ):
-
Rocksdb:状态恢复阶段需要下载状态文件和元数据文件,然后处理冗余数据,处理完成后作业才能成功启动,整体断流时间较长;
-
Gemini + 延迟剪裁:只需下载状态文件和元数据文件即可启动,将处理冗余数据的操作异步化,且异步处理期间对读写线程性能几乎影响,可以让作业快速启动,减少断流时间;
-
Gemini + 状态懒加载 + 延迟剪裁:进一步将下载状态文件的操作放到异步阶段执行,允许作业可以只下载少量元数据数据就可以启动处理用户数据,大大缩小作业断流时间。 异步下载状态文件过程中,作业的性能会从 0 开始逐渐提升,随着远端文件逐步下载到本地,作业性能可以逐渐恢复到正常水平。状态懒加载方式和完全阻塞的下载方式相比,由于下载状态文件期间还可以正常处理数据,作业整体吞吐要更高。

图 2-3. Rocksdb/Gemini/Gemini 状态懒加载三者断流时间对比
目前阿里云实时计算 Flink 版产品中,提供了动态更新作业参数的能力(热更新),用户无需完全停止重启作业即可完成作业参数更新。目前状态懒加载功能已经结合动态更新作业参数功能上线,极大减少更新参数场景下用户业务的中断时间(-90%以上)。
4. KV 分离–优化双流/多流 Join 性能
4.1 KV 分离核心优势
很多 Flink 双流 Join 场景中, 具备 Join 成功率较低、或者状态数据 Value 较长的特点,KV 分离可以在这类作业下发挥性能优势。 例如风控场景中,通常只有异常的数据才可能 Join 成功;在实时推荐场景中(如图 2-4 所示),只有推荐算法实际生效的情况下,才可以 Join 成功; 这类用户场景特点决定了其对应的 Flink 作业 Join 成功率会很低,同时 Value 存储的业务数据字段很长,开启 KV 分离可以获得极大的性能优势。
Join 场景下 KV 分离的优势来源于两个方面:
- Join 算子只需利用 Key 即可判断是否 Join 成功, Value 只有在 Join 成功的情况下才会参与计算;在 Join 成功率低的场景下,KV 分离可以将更多 Key 缓存在 Cache 中,状态访问性能更好;
- 将状态数据中的大 Value 分离存储,降低主存储数据结构的大小,极大地减少引擎内部冗余数据整理的 CPU 和 IO 开销。

KV 分离机制的劣势是对范围查询不太友好,以及存在一定程度的空间放大。而 Flink 场景中,状态访问操作以点查询为主,范围查询相对较少,是 KV 分离天然的适用场景;对于空间放大的劣势,Gemini 可以通过 KV 分离支持存算分离,最大程度上规避了存储空间的劣势。
4.2 KV 分离支持存算分离
GeminiKV 分离功能可以和上述存算分离以及冷热分离功能紧密结合,在本地空间不够的场景下,能够将分离的 Value 数据(冷数据)优先存储在远端,保证 Key 的读取不受性能影响。在 Value 访问概率较低的情况下,这种方案可以在成本较低的条件下提供近似纯本地磁盘存储方案的性能。
4.3 自适应 KV 分离
在流计算场景下,不同作业的数据特点(Value 长度、Key 和 Value 的访问频率等)各不相同,固定的 KV 分离参数难以让所有作业性能达到最优。为了最大程度发挥 KV 分离的性能优势,Gemini 支持自适应 KV 分离,存储引擎内部可以根据状态数据特点,识别数据冷热,动态调整发生 KV 分离的数据比例,让整体系统性能达到更优,其参数调优过程如图 2-5 所示。Gemini 自适应 KV 分离功能,在 SQL Join 场景下是默认开启的,用户无需配置的情况下即可利用 KV 分离获得作业性能提升。

三、Gemini 性能评测&线上表现
1. Flink State Benchmark
测试环境:一台阿里云 ECS i2.2xlarge 实例, 8vCPU, 64G 内存,Nvme SSD 磁盘;
测试设置:使用 Flink State Benchmark 对 Rocksdb/Gemini 纯 State 操作的性能进行对比, Rocksdb 设置 WriteBuffer 64MB (默认 2 个),blockCache 512MB, Gemini 设置总内存 (64MB * 2 + 512MB) 。
测试结果如图 3-1 所示,对于 Flink 流计算场景中占比很大的点查询 (ValueGet/ListGet/MapGet) 操作, 以及写入操作(ValueUpate/ListUpdate/MapUpdate),Gemini 的吞吐性能多数可以到达 Rocksdb 的 2~5 倍。

2. Nexmark
测试环境:5 台阿里云 ecs.c7.16xlarge 实例 (1个JM,4个TM), 每台实例 64 vCPU, 128GB 内存,ESSD PL1 云盘;
测试设置:选取了 Nexmark 中有状态用例,利用 Nexmark 标准配置(8个并发、8个 TaskManager、每个 TaskManager 8G 内存),默认数据量 EventsNum=100M, 对比 Rocksdb 和 Gemini 的性能差异。
测试结果如表 3-1 所示,Gemini 对作业效能(单核吞吐能力)的优化效果显著,所有用例的性能都要比 Rocksdb 更优,约一半用例的性能领先 Rocksdb 70% 以上。
| Rocksdb TPS/core | Gemini TPS/core | Gemini vs Rocksdb | |
|---|---|---|---|
| Q4 | 84.84 | 146.34 | +72.49% |
| Q5 | 97.28 | 120.89 | +24.27% |
| Q7 | 23.83 | 27.57 | +15.69% |
| Q8 | 566.36 | 597.17 | +5.44% |
| Q9 | 40.02 | 92.57 | +131.31% |
| Q11 | 79.5 | 138.41 | +74.10% |
| Q12 | 437.69 | 475.82 | +8.71% |
| Q16 | 51.01 | 63.6 | +24.68% |
| Q17 | 439.89 | 497.94 | +13.20% |
| Q18 | 132.06 | 236.62 | +79.18% |
| Q19 | 161.81 | 278.96 | +72.40% |
| Q20 | 36.09 | 114.39 | +216.96% |
3. 状态恢复速度测试
测试环境:阿里云实时计算 Flink 版中开通按量付费Flink全托管产品;
测试设置:利用 WordCount Benchmark , 作业总状态大小约为 4G,Source 数据生成符合正态分布,每个 TaskManager 分配 1CPU+4G 内存资源,分别测试 Rocksdb/Gemini/Gemini 状态懒加载的作业恢复表现。
测试结果如图 3-2 所示,在改并发的场景下,Gemini 默认作业的断流时间会比 Rocksdb 更少(扩并发情况减少 47%, 缩并发情况减少 78%); Gemini 开启状态懒加载后,作业断流时间相比 Rocksdb 可以进一步减少(扩并发情况减少 94%,缩并发情况减少 96%)。Gemini 作业恢复到正常性能所需的时间相比 Rocksdb 也大幅减少,尤其是在缩并发的场景下减少 70% 以上。

与此同时,状态懒加载功能还和动态更新作业参数的功能(热更新)进行了联合测试,在测试作业 128 并发,每个并发 State size 5G 的场景下,开启状态懒加载+热更新功能后,作业扩缩并发的断流时间可以减少 90% 以上(扩并发 579s -> 13s, 缩并发 420s -> 11s)。
4. KV 分离效果测试
测试设置:选择 Nexmark Q20 Join 作业作为 KV 分离的性能测试 Benchamark,并适当扩大数据规模 (EventsNum=400M/800M) , 使得其更贴合双流 Join 大状态场景的情况,其他测试环境和设置与 3.2 Nemark 保持一致,分别测试 Gemini 在关闭/开启 KV 分离情况下的性能表现。
测试结果如图 3-3 所示,在 Q20 双流 Join 场景下,Gemini 开启 KV 分离后性能优化效果显著,作业吞吐能力可以提升 50% ~ 70% 以上。

5. 线上表现
- Gemini 作为阿里云实时计算 Flink 引擎的默认状态后端,经历了三年多的不断优化和打磨,性能、稳定性和易用性不断提升,截至目前,阿里巴巴集团内部的实时计算平台和公有云的实时计算 Flink 服务中,有共计超 50WCU 的有状态作业使用 Gemini 存储引擎,助力实时计算用户高效完成业务目标;
- 自 VVR-8.X 版本起我们对 Gemini 架构进行了全新升级,截至目前,在阿里巴巴集团内部的实时计算平台,有 53%+ 的有状态 Flink 任务使用了新版 Gemini 引擎,性能和稳定性表现优异,据估算整体作业资源相对于旧版引擎进一步节省约 27%;在公有云实时计算 Flink 版中,截止目前也有 24%+ 的有状态作业使用了新版 Gemini 引擎。
四、结语
Flink 企业级状态存储引擎 Gemini 基于流计算场景特点设计,经历了三年多的不断优化和打磨,性能、稳定性和易用性不断提升。自 VVR-8.X 版本起,新版 Gemini 在旧版本的基础上,对核心架构和功能都进行了改造升级,相比于 RocksDB , 新版 Gemini 拥有更优的状态访问性能,更快速的扩缩容机制,同时支持 KV 分离、存算分离和状态懒加载;其作为阿里云实时计算 Flink 版的默认状态存储引擎,也经历了阿里巴巴集团和阿里云用户大规模生产实践的考验。在未来,Gemini 引擎仍将持续地进行优化和改进,提升流计算产品的性能、易用性和稳定性,打造成为最适合流计算场景的状态存储引擎。
五、参考
[1] https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/concepts/stateful-stream-processing
[2] https://help.aliyun.com/zh/flink/user-guide/dynamically-update-deployment-parameters
[3] https://github.com/apache/flink-benchmarks/tree/master/src/main/java/org/apache/flink/state/benchmark
[4] https://github.com/nexmark/nexmark
[5] https://help.aliyun.com/zh/flink/