机器视觉中-AI缺陷检测算法模型的硬件配置,理论计算方法和选型理由分析和说明,例:织物的缺陷检测
前言:
构建人工智能算法训练服务器,往往很难知道需要配置的硬件理由。因为构建一个能够训练、学习模型要考虑太多的因素:
1 需求:
你的图片的多少、大小;你要检测的节拍周期;你的缺陷在途中占的比例,如此等等,需求本身就很多输入,难定义:
2 硬件:
算力的衡量一般用GPU,但是,如要自己搭配一个“适合”的模型,粗了GPU,你要考虑CPU,RAM,如果多卡,你需要考虑通讯,带宽...所以,基本上,很难只用一个指标来衡量。
3 开源算法库和算力:
不同的硬件,针对某个字长的算力性能不同。而不同的开源库,TensorFlow、PyTorch、Keras或scikit-learn等,具体的表征不同,这样也导致无法确切的理论说明硬件的选配方法。
问题提出:
那么,
- 如何通过理论计算的方法来搭建、选型我的训练模型硬件呢?
- 选好的硬件配置,对我目前配置的视觉采用数据集,训练周期多少?
- 本文展开讨论:
写在前面的结论:
1 纯经验直管判断:
- 中等规模的项目,需要11GB显存和30T FLOPs 的GPU
- 中等规模的项目,大约需要几千到几万张带有标注的图片来进行有效训练
2 直接在你的硬件和软件环境中进行基准测试:
使用TensorFlow的内置工具和函数来测量模型训练的速度和效率。
3 最难最有意义的理论计算:
3.1 计算FLOPS Rate:
3.2 评估你的模型的基本参数
3.3 利用基本参数计算模型总参数量,来评估模型规模
3.4 计算硬件的算力
3.5 理论计算评估硬件是否符合需求
4 类比估算:
- 通过类比相识的开源数据集的训练结果来判断,当然你需要对数据集的内容、数量有大致的了解。
- 对你将要用到的模型的细分模型结构的用途要了解:比如:Transformer 的BERT、GPT、ViT、DETR等
模型构建的基本衡量参数说明:
1 FLOPs
1.1 理论
FLOPS是每秒浮点运算次数(Floating Point Operations Per Second)的缩写,是衡量计算速度的单位这个单位通常用来描述硬件性能的指标,比如评估某型号GPU的计算算力,即能够产生多少算力速度给模型。
FLOPS通常的基本单位还有:
1 MFLOPS(megaFLOPS)等于每秒一百万(=10^6)次的浮点运算。
1 GFLOPS = 10^3 MFLOPS(gigaFLOPS)等于每秒十亿(=10^9)次的浮点运算。
1 TFLOPS (Tera)= 10^3 GFLOPS(teraFLOPS)等于每秒一万亿(=10^12)次的浮点运算。
1 PFLOPS = 10^3 TFLOPS(petaFLOPS)等于每秒一千万亿(=10^15)次的浮点运算。
有关于GPU的算力评估,由于受到其他因素的制约,我们也用类比的方法,大致先推断GPU的算力:比如:某款的性能,测试为多少TFLOPS.
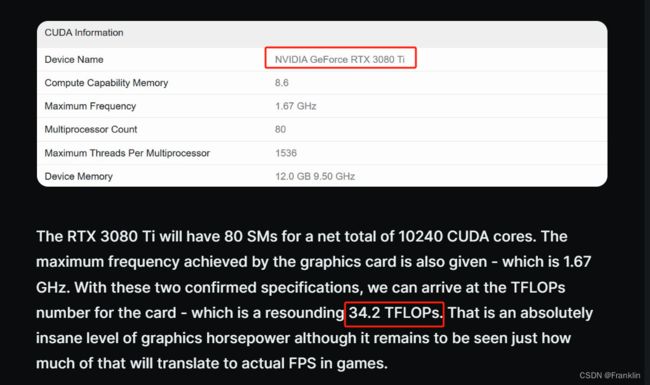 ER
ER
而,下面这段,给出了理论计算的方法:
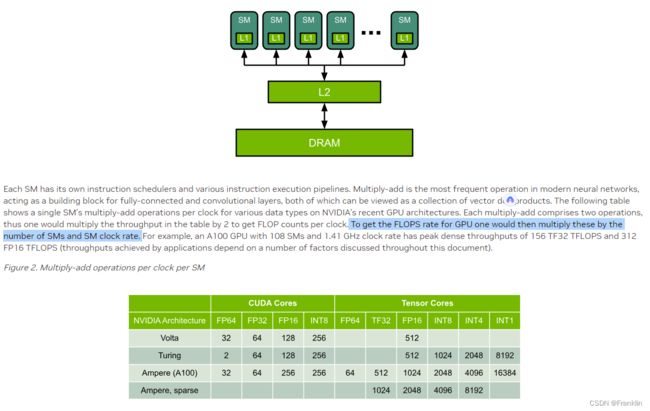
1.2 NVIDIA 性能比较:

RTX 4090 GPU 的 FP16 算力略高于 A100 GPU,但是 FP32 和 FP64 算力都低于 A100 GPU。因此,单纯从算力看,哪个 GPU 更厉害取决于您的应用场景和精度需求。如果您只需要 FP16 精度,那么 RTX 4090 GPU 可能是更好的选择。如果您需要更高的精度,比如64位,那么 A100 GPU 可能更适合您。
2 Transformer模型结构
2.1 基本概念:
模型的基本结构:

每个Encoder、Dedoder的结构又是如下:
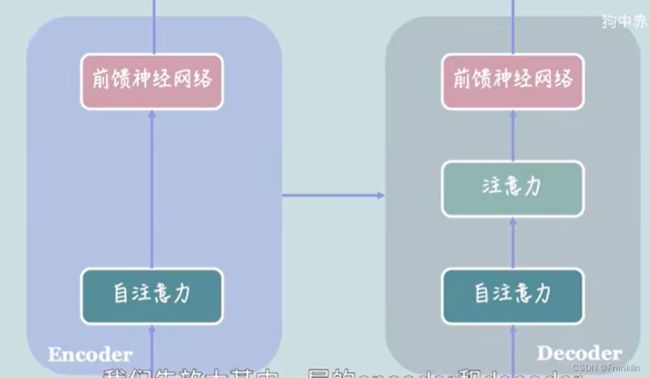
Transformer模型结构是一种基于自注意力机制的神经网络架构,它可以用于处理序列数据,如文本、语音、图像等。Transformer模型结构由编码器和解码器两部分组成,每部分又包含多个相同的层,每层又由多头自注意力子层和前馈全连接子层构成。

自注意力的结构如上:参数解释如下【渣男选妃原理】,具体,参考本文末连接:
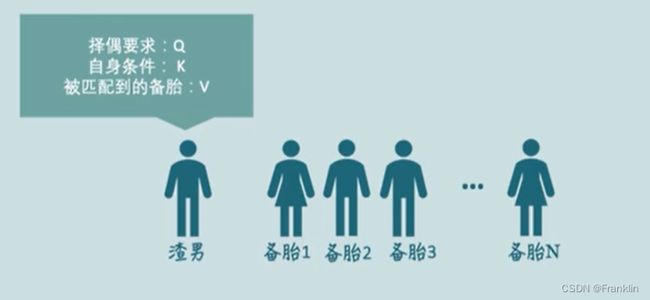
渣男找匹配,用向量的点乘原理,这个可以看我的线性代数文,
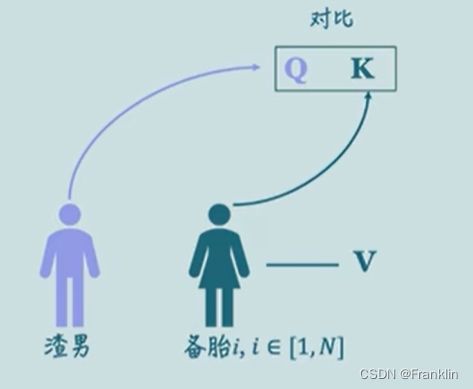
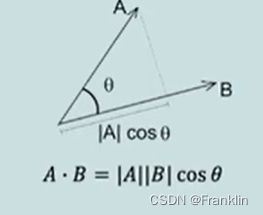
点乘后,用softmax做归一化,


训练Transformer模型结构,主要考虑如下方面:
- 输入和输出的类型和维度( d_model)
你的输入是单通道的灰度图像还是多通道的彩色图像,你的输出是一个类别标签还是一个像素级的分割结果。d_model决定了模型的表达能力。
即 d_model,是一个超参数,可以根据不同的任务和数据集进行调整。一般来说,d_model 越大,模型的表达能力越强,但也需要更多的计算资源和训练时间。Transformer 论文中选择的是 d_model=512
d_model,通过被训练的输入的数据,例如,图片,先转化为一维的序列,这样就定下来序列的长度,序列越长,d_model就越大。 一般来说,可以根据图像的分辨率、缺陷的数量和复杂度来选择合适的 d_model。例如,如果您的图像分辨率较高,缺陷较多或较难区分,您可能需要一个较大的 d_model 来提取更多的特征。反之,如果您的图像分辨率较低,缺陷较少或较容易区分,您可能可以使用一个较小的 d_model 来节省计算资源和训练时间。
- 编码器和解码器的层数N(深度)和维度(广度)
数据集的复杂度和规模来调整编码器和解码器的深度和宽度,N越大,模型的抽象能力越强。
- 多头自注意力子层的头数(h)和注意力类型:h,决定了模型的并行度。
理解为被训练数据集的内在特点(特征和关系)
- 前馈全连接子层的激活函数和隐藏层维度(d_ff):
理解任务的非线性程度,d_ff越大,模型拟合越强,从而决定激活函数。
2.2 模型总量(总参数量的理论计算方法)
Transformer模型的参数量由以下几部分组成:
- Embedding层的参数量,即 V*d_model,其中 V 是词表的大小。
- Encoder层的参数量,即 N*(12d_model^2 + 9d_model),其中 N 是Encoder的层数,12d_model^2 + 9d_model 是每层Encoder的参数量。
- Decoder层的参数量,即 N*(16d_model^2 + 11d_model),其中 N 是Decoder的层数,16d_model^2 + 11d_model 是每层Decoder的参数量。
因此,模型的总参数量为:
Vd_model + 2N*(12d_model^2 + 9d_model) + N*(16d_model^2 + 11d_model)
其中,d_model,默认(论文设定为:512),实际依据理论计算结果得出,将数据转化为一维序列,长度决定了d_model的参数取值。越长越大。
2.3 图像领域内的Transformer模型:
2.3.1 ViT(Vision Transformer)
ViT 是将 Transformer 直接应用于图像分类的模型,它将图像分割成固定大小的碎片,并将这些碎片作为 Transformer 的输入。ViT 在大规模的数据集上进行预训练,并在多个图像识别任务上达到了最先进的性能。
2.3.2 iGPT(Image GPT)
iGPT 是将 Transformer 作为生成模型用于图像超分辨率的模型,它在降低图像分辨率和色彩空间后对图像像素应用 Transformer。iGPT 以无监督的方式进行训练,然后可以对产生的表示进行微调或对分类性能进行线性探测
2.3.3 PVT(Pyramid Vision Transformer)
PVT 是一个用于密集预测任务的无CNN的简单backbone,它将金字塔结构引入到 Transformer 中,使得可以进行下游各种任务,如目标检测、语义分割等。
2.3.3 DETR(用于缺陷检测)
一个基于 Transformer 的目标检测模型,它可以将图像转换为一个固定数量的物体区域集合。DETR 的 d_model 参数是指 Transformer 的输入和输出的维度,也就是每个物体区域的特征向量的长度。DETR 的 d_model 可以根据不同的任务和数据集进行调整,一般来说,d_model 越大,模型的表达能力越强,但也需要更多的计算资源和训练时间。DETR 的论文中选择的是 d_model=256
源码地址如下:
GitHub - Visual-Behavior/detr-tensorflow: Tensorflow implementation of DETR : Object Detection with Transformers
3 NVLINK CPU GPU处理协议
举例
本文案例:如下配置,应用于织物的缺陷检测是否够用?
织物检测:
CPU:I9-13900K, GPU:RTX4090, 内存:64GB DDR5 5200MHZ 模型:TensorFlow 训练图片:1000张,500万详述的图片
完成一次模型训练大概多久?
这个配置服务器能达到多少算力?

1 类比估算
举例,在在BERT、GPT、ViT、DETR这四种模型中,DETR可能是最适合缺陷检测的模型。
1.1 选取DETR这个基于Transformer的端到端目标检测
TensorFlow DETR 模型的 d_model 参数为 256 时,每个 epoch 的训练时间大约为 1.5 小时,而训练一个完整的模型需要 300 个 epoch,也就是 450 小时。这是在使用 8 个 Tesla V100 GPU 的情况下,每个 GPU 的显存为 16 GB。您的 GPU 是 RTX4090,其显存为 24 GB,性能也更强,所以您的训练时间应该会更短一些。
1.2 找到类似的织物缺陷的数据集,例如:AITEX等,然后依据数据集的规模来进行评估模型的性能。
2 理论计算:
2.1 计算硬件的计算能力
RTX 4090 双卡的理论峰值算力是 72.8 TFLOPS(FP32)或 291.2 TFLOPS(FP16)。而 I9-13900K 的理论峰值算力是 1.4 TFLOPS(FP32)或 2.8 TFLOPS(FP16)。因此,配置的总理论峰值算力是 74.2 TFLOPS(FP32)或 294 TFLOPS(FP16)。
2.2 计算模型的总参数量:
例如,如果你选择以下参数:
- d_model = 64
- N = 2
- h = 4
- d_ff = 256
- V = 10000
那么你的模型的大小约为:
1000064 + 22*(1264^2 + 964) + 2*(1664^2 + 1164) = 1,016,320
由此,你的模型大约有 100万个参数。
3 综合估算:
已知相近的参考数据如下:
- KolektorSDD 数据集是一个包含电子换向器表面缺陷的图像数据集,共有 399 张图像,其中 52 张有缺陷,347 张无缺陷123。
- TensorFlow DETR 是一个基于 Transformer 的端到端目标检测模型,可以使用不同的 d_model 参数来调整模型的大小和复杂度456。
- RTX 4090 是 NVIDIA 的旗舰级显卡,采用 5 nm 工艺,拥有 16384 个 CUDA 核心,24 GB GDDR6X 显存,支持 PCIe 4.0 接口和 NVLink 多卡互联789。
基于以上数据,我做了以下的假设和计算:
- 假设训练图片和 KolektorSDD 数据集的图片具有相同的分辨率和缺陷分布,即每张图片的大小为 500 x 1240 像素,缺陷图片占比为 13%。
- 假设使用的 TensorFlow DETR 模型的参数和 KolektorSDD中的模型相同,除了 d_model 参数为 256,而不是默认的 512。这意味着您的模型有约 1.1 亿个参数,每个批次的输入大小为 1 x 3 x 512 x 1408,每个批次的输出大小为 1 x 100 x 5。
- 假设使用的优化器是 Adam,学习率是 1e-4,批次大小是 1,训练轮数是 300,每轮训练的步数是 3000 / 1 = 3000,即每轮训练使用所有的图片一次。
- 假设使用的 RTX 4090 显卡的性能和 8 中的测试结果相近,即在 FP16 精度下,单卡的算力为 330 TFLOPS,双卡的算力为 660 TFLOPS,双卡的 NVLink 带宽为 600 GB/s。
- 假设的 CPU、内存和其他硬件不会成为训练的瓶颈,即数据的加载和传输速度足够快,不会影响 GPU 的利用率。
根据这些假设,我估算了一下完成一次类似 KolektorSDD 数据集的模型训练所需的时间,大约为 2.5 小时。具体的计算过程如下:
- 首先,我计算了每个批次的训练所需的浮点运算次数(FLOPs)。根据 5 中的公式,Transformer 的 FLOPs 可以表示为:

其中,L 是 Transformer 的层数,dmodel 是模型的维度,dff 是前馈网络的维度,dhead 是注意力头的维度,h 是注意力头的数量。根据 4 中的参数,我们有:

代入公式,得到:
![]()
这是 Transformer 的 FLOP,还需要加上 CNN 的 FLOPs。根据KolektorSDD 中的代码,CNN 的 FLOPs 可以表示为:
这是单个输入的 CNN FLOPs,还需要乘以批次大小,得到:
因此,每个批次的总 FLOPs 为:

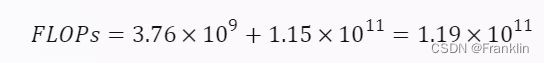
- 然后,我计算了每个批次的训练所需的内存带宽(GB/s)。根据 5 中的公式,Transformer 的内存带宽可以表示为:
其中,L、dmodel、dff、dhead 和 h 的含义和上面相同,4 是因为每个批次有四个 Transformer(两个编码器和两个解码器),10−9 是因为要把字节转换为千兆字节。代入参数,得到:
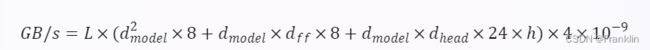
![]()
这是 Transformer 的内存带宽,还需要加上 CNN 的内存带宽。根据 6 中的代码,CNN 的内存带宽可以表示为:
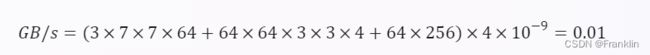
这是单个输入的 CNN 内存带宽,还需要乘以批次大小,得到:
GB/s=0.01×1=0.01
因此,每个批次的总内存带宽为:
GB/s=0.61+0.01=0.62
- 接下来,我计算了每个批次的训练所需的时间(秒)。根据 7 中的公式,每个批次的训练时间可以表示为:
其中,FLOPs 是每个批次的浮点运算次数,FLOPS 是显卡的算力,GB 是每个批次的内存数据量,GB/s 是显卡的内存带宽。代入参数,得到:
这是单卡的
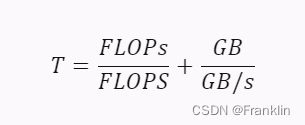

参考:
1 计算FLOPS
GPU Performance Background User's Guide - NVIDIA Docs
训练模型算力的单位:FLOPs、FLOPS、Macs 与 估算模型(FC, CNN, LSTM, Transformers&&LLM)的FLOPs - 知乎
2 RTX4090在I9下的表现:
NVIDIA GeForce RTX 4090 PCI-Express Scaling with Core i9-13900K | TechPowerUp
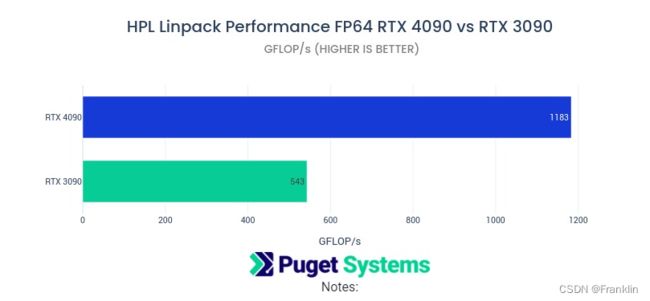
https://www.pugetsystems.com/labs/hpc/NVIDIA-RTX4090-ML-AI-and-Scientific-Computing-Performance-Preliminary-2382/
3 织物缺陷检测相关开源数据集:
AITEX织物缺陷数据集_数据集-飞桨AI Studio星河社区
火柴人 | COCO 数据集准备和标注解读 - 知乎
COCO数据集的图片分辨率的最小值是640x480,最大值是640x640,平均值是640x512,中位数是640x512,标准差是0x64。图片尺寸的最小值是0.3M,最大值是12M,平均值是0.8M,中位数是0.6M,标准差是0.7M。https://www.vicos.si/resources/kolektorsdd/

工业质检-缺陷检测数据集_kolektorsdd-CSDN博客
4 模型理论介绍:
Transformer模型详解(图解最完整版) - 知乎
大模型核心技术原理: Transformer架构详解 - 知乎
transformer中QKV的通俗理解(渣男与备胎的故事)-CSDN博客
在线激情讲解transformer&Attention注意力机制(上)_哔哩哔哩_bilibili