python爬虫示例 | 爬取etherscan上的ERC20代币详情,清洗后写入mysql
最近需要对已收录的代币,对其合约地址查找出代币详情,并更新进数据库。爬取etherscan大陆官网实现
列表页:
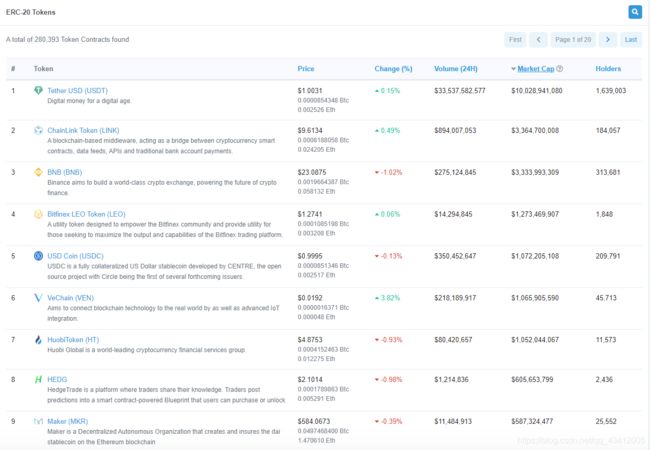
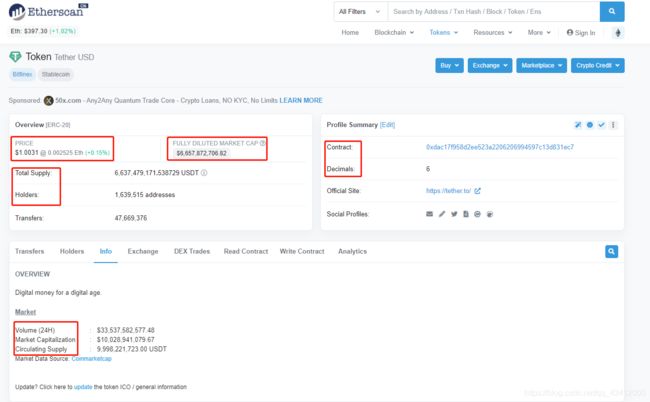
详情页及需要爬取的字段:
写入数据库后的部分结果数据:

全部代码实现如下:
import re
import requests
from bs4 import BeautifulSoup
import pymysql
from utils import utils
class getTokensDetailFromEs():
# 存储列表到详情的url
html_list_link = []
def __init__(self):
self.config = utils.config_params()
self.__db_conn()
self.get_html_list()
# self.get_html_detail(url)
def __db_conn(self):
"""
MySQL连接
:return:
"""
db_config = self.config['mysql']
self.client = pymysql.connect(host=db_config['host'], port=db_config['port'], user=db_config['user'],
password=str(db_config['password']), database=db_config['database'])
self.cursor = self.client.cursor()
mysql_list = [self.client, self.cursor]
return mysql_list
def __get_required_token(self):
'''
读取tp_uniswap_exchange_rate表中代币的合约地址
:return:
'''
sql = 'SELECT token_id FROM tp_uniswap_exchange_rate '
self.cursor.execute(sql)
token_collection = self.cursor.fetchall()
return token_collection
# 访问列表页
def get_html_list(self):
self.headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36', }
token_collection = self.__get_required_token()
for token_contract in token_collection:
token_contract_str = str(token_contract)
token_id = re.findall(r'[(](.*?)[,]', token_contract_str)[0]
getTokensDetailFromEs.html_list_link.append('https://cn.etherscan.com/token/' + str(token_id))
def get_html_detail(self, url):
'''
访问详情页,解析对应字段
:param url:
:return:
'''
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36 SLBrowser/6.0.1.6181'
}
response_1 = requests.get(url=url, headers=headers)
soup_1 = BeautifulSoup(response_1.text, 'html.parser')
# Read Contract 界面
detail_id = url.split("token/")[1]
contract_url = "https://cn.etherscan.com/readContract?m=normal&a=" + eval(detail_id) + "&v="
response_2 = requests.get(url=contract_url, headers=headers)
soup_2 = BeautifulSoup(response_2.text, 'html.parser')
try:
price_exchange_changes = soup_1.find(text="Price").find_next('span').text.replace("\n", "").replace(" ","")
except:
price_exchange_changes = None
pass
print(f'price_exchange_changes:{price_exchange_changes}')
changes_temp = re.findall(r'[(](.*?)[)]', price_exchange_changes)
if len(changes_temp) != 0:
changes = changes_temp[0]
else:
changes = None
print(f"changes: {changes}")
price_temp = re.findall(r'[$](.*?)[@]', price_exchange_changes)
if len(price_temp) != 0:
price = float(price_temp[0].replace(",", ""))
else:
price = 0.0
print(f"price:{price}")
try:
fd_market_cap = soup_1.find(text="Fully Diluted Market Cap ").find_next('span').text.replace("\n", "")
except:
fd_market_cap = 0.0
pass
fd_market_cap_temp = filter(lambda ch: ch in '0123456789.', fd_market_cap)
fully_diluted_market_cap = float(''.join(list(fd_market_cap_temp)))
print(f'fully_diluted_market_cap: {fully_diluted_market_cap}')
try:
holders_temp = soup_1.find("div", attrs={"id": "ContentPlaceHolder1_tr_tokenHolders"}).find("div", attrs={
"class": "col-md-8"}).text.replace("\n", "").replace(" ", "")
except:
holders_temp = 0
print('无法获取holders')
pass
if holders_temp != 0:
holders = int(re.sub("\D", "", holders_temp))
else:
holders = holders_temp
print(f'holders: {holders}')
try:
total_supply_temp = soup_1.find("div", attrs={"class": "col-md-8 font-weight-medium"}).text.replace("\n", "").replace(",", "").replace(" ", "")
except:
total_supply_temp = 0.0
print('无法获取total_supply')
pass
if total_supply_temp != 0.0:
t_supply = filter(lambda ch: ch in '0123456789.', total_supply_temp)
total_supply = float(''.join(list(t_supply)))
else:
total_supply = total_supply_temp
print(f'total_supply: {total_supply}')
try:
contract = soup_1.find(text="Contract:").find_next('div').text.replace("\n", "")
except:
contract = None
print('无法获取contract')
pass
market_cap = ''
try:
market_cap_list = soup_1.find("div", attrs={"id": "tokenInfo"}).findAll("div", attrs={
"class": "table-responsive mb-2"})
for m in market_cap_list:
if 'Market Capitalization' in m.text:
market_cap = float(soup_1.find(text="Market Capitalization").find_next('td').find_next('td').text.replace(
"\n", "").replace(',', '').replace('$', ''))
else:
market_cap = 0.0
except:
market_cap = 0.0
print(f"market_capitalization: {market_cap}")
try:
decimal_temp = soup_1.find("div", attrs={"id": "ContentPlaceHolder1_trDecimals"}).find("div", attrs={
"class": "col-md-8"}).text.replace("\n", "")
except:
decimal_temp = 0
print('无法获取decimal')
pass
if decimal_temp != 0:
decimal = int(re.sub("\D", "", decimal_temp))
else:
decimal = decimal_temp
print(f'decimal: {decimal}')
# decimal = soup_1.find("div", attrs={"id": "ContentPlaceHolder1_trDecimals"}).find("div", attrs={
# "class": "col-md-8"}).text.replace("\n", "")
# decimals = re.sub(r'[^0-9]', '', decimal)
# print(f'decimal: {decimal}')
symbol = ''
try:
symbol_list = soup_2.find("div", attrs={"id": "readContractAccordion"}).findAll("div",
attrs={"class": "card mb-3"})
for s in symbol_list:
if 'symbol' in s.text:
symbol = s.find("div", attrs={"class": "form-group"}).text.replace(
s.find("span", attrs={"class": "text-monospace text-secondary"}).text, "").replace("\x00", "")
except:
symbol = None
pass
if not symbol.isalpha():
symbol = re.sub(r'[^A-Za-z]', '', total_supply_temp)
print(f'symbol:{symbol}')
try:
volume_list = soup_1.find("div", attrs={"id": "tokenInfo"}).findAll("div", attrs={
"class": "table-responsive mb-2"})
for v in volume_list:
if 'Volume (24H)' in v.text:
volume_temp = soup_1.find(text="Volume (24H)").find_next('td').find_next('td').text.replace("\n", "")
else:
volume_temp = 0.0
except:
volume_temp = 0.0
pass
if volume_temp != 0.0:
volume = float(volume_temp.replace(',', '').replace('$', ''))
else:
volume = volume_temp
print(f"volume: {volume}")
try:
circulating_supply_list = soup_1.find("div", attrs={"id": "tokenInfo"}).findAll("div", attrs={
"class": "table-responsive mb-2"})
for cs in circulating_supply_list:
if 'Circulating Supply' in cs.text:
circulating_supply_temp = soup_1.find(text="Circulating Supply").find_next('td').find_next('td').text.replace("\n", "").replace(",", "").replace(" ", "")
else:
circulating_supply_temp = 0.0
except:
circulating_supply_temp = 0.0
pass
if circulating_supply_temp != 0.0:
c_supply = filter(lambda ch: ch in '0123456789.', circulating_supply_temp)
circulating_supply = float(''.join(list(c_supply)))
else:
circulating_supply = circulating_supply_temp
print(f'circulating_supply: {circulating_supply}')
factory_info = {
"Symbol": symbol, # 代币简称
"Contract": contract, # 合约地址
"Price": price, # 价格
"Changes": changes,
"FD_Market_Cap": fully_diluted_market_cap, # 全面摊薄市值
"Market_Cap": market_cap, # 市值
"Total_Supply": total_supply, # 总供给
"Circ_Supply": circulating_supply, # 供应量
"Holders": holders, # 持有人数
# "Transfers": transfers, # 总转账
"Decimal": decimal, # 代币精度
"Volume_24H": volume, # 24小时成交量
}
print(factory_info)
print("---------")
# 写入数据库
mysqlconn_list = self.__db_conn()
conn = mysqlconn_list[0]
cursor = self.client.cursor(pymysql.cursors.DictCursor)
sql = "UPDATE tp_uniswap_exchange_rate SET `price`=%s, `changes`=%s, `fully_diluted_market_cap`=%s, " \
"`market_cap`=%s, `total_supply`=%s, `circulating_supply`=%s, `holders`=%s, `decimals`=%s, `volume`=%s " \
" WHERE token_id = %s"
par = (price, changes, fully_diluted_market_cap, market_cap, total_supply, circulating_supply, holders, decimal, volume, contract)
print(sql % par)
cursor.execute(sql, par)
conn.commit()
if __name__ == '__main__':
td = getTokensDetailFromEs()
td.get_html_list()
for url in td.html_list_link:
td.get_html_detail(url)