Hive基础
hive的基础部分大致有四部分:Hive数据类型、Hive运算符、Hive数据存储、Hive表存储格式。这四部分是学习hive必须掌握的知识。
一、Hive数据类型
整体概述
1,hive的数据类型指的是表中列字段类型,类似于编程语言中对变量类型的定义如:浮点型、整型、布尔型等等。
2,hive的数据类型分为两大类:基本数据类型和复杂数据类型。
基本数据类型包括:数值类型、布尔类型、字符串类型、时间日期类型。
复杂数据类型包括:Array数组、Map映射、Struct结构体。
基本数据类型
2字节、4字节、8字节的有符号整数的取值范围:https://blog.csdn.net/m0_48011056/article/details/125153980
| 基本数据类型 |
描述 |
示例 |
| Tinyint |
1字节有符号整数 |
80 |
| Smallint |
2字节有符号整数 |
80 |
| Int |
4字节有符号整数 |
80 |
| Bigint |
8字节有符号整数 |
80 |
| Boolean |
布尔类型,True或者False |
True,False |
| Float |
单精度浮点数 |
3.14159 |
| Double |
双精度浮点数 |
3.14159 |
| Decimal |
任意精度的带符号小数 |
Decimal(5,2)用于存储-999.99~999.99的5位数值,小数点后2位 |
| String |
变长字符串。使用单引号或双引号 |
'now is the time',"for all good men" |
| Varchar |
变长字符串 |
"a",'b' |
| Char |
固定长度字符串 |
"a",'b' |
| Date |
日期,对应年、月、日 |
'2021-03-29' |
| TimeStamp |
时间戳 |
不包含任务的时区信息 |
| Binary |
字节数组 |
用于存储变长的二进制数据 |
复杂数据类型
| 复杂数据类型 | 描述 | 示例 |
| Array | 一组具有相同数据类型的数据的集合 | 数组friends['Bill','Linus'],第2个元素可以通过friends[1]进行访问 |
| Map | 一组键值对元组的集合 | 如果字段children的数据类型是Map,其中键值对是'Paul'->18,那么可以通过字段名children['Paul']访问这个元素 |
| Struct | 封装一组有名字的字段,其类型可以是任意的基本数据类型 | 如果字段address的数据类型是Struct{first String, last String},那么第1个元素可以通过address.first来访问 |
注意事项:
Hive SQL中,数据类型英文字母大小写不敏感;
除SQL数据类型外,还支持Java数据类型,比如字符串string;
复杂数据类型的使用通常需要和分隔符指定语法配合使用;
如果定义的数据类型和文件不一致,Hive会尝试隐式转换,但是不保证成功。
隐式转换:
与标准SQL类似,HQL支持隐式和显式类型转换。 原生类型从窄类型到宽类型的转换称为隐式转换,反之,则不允许。 下表描述了类型之间允许的隐式转换:
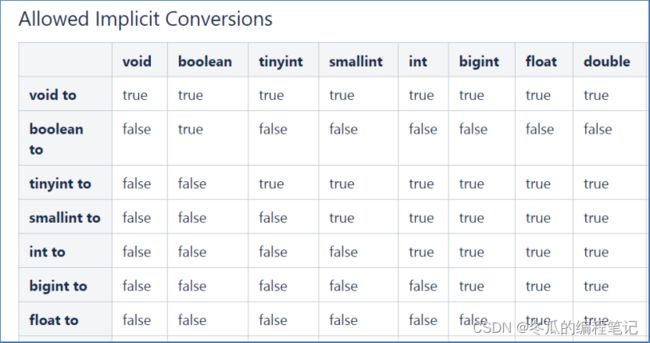
显示转换:
显式类型转换使用CAST函数。 例如,CAST(‘100’ as INT)会将100字符串转换为100整数值。 如果强制转换失败,例如CAST(‘Allen‘ as INT),该函数返回NULL。
二、Hive运算符
Hive有4种类型的运算符:算术运算符、比较运算符、逻辑运算符和复杂运算符。
算数运算符:

比较运算符:



逻辑运算符:

复杂运算符:

三、Hive存储路径
默认存储路径
Hive表默认存储路径是由 ${HIVE_HOME}/conf/hive-site.xml配置文件的hive.metastore.warehouse.dir属性指定,默认值是:/user/hive/warehouse。
Databases 数据库
Hive作为一个数据仓库,在结构上积极向传统数据库看齐,也分数据库(Schema),每个数据库下面有各自的表组成。默认数据库default。
Hive的数据都是存储在HDFS上的,默认有一个根目录,在hive-site.xml中,由参数hive.metastore.warehouse.dir指定。默认值为/user/hive/warehouse。 因此,Hive中的数据库在HDFS上的存储路径为: ${hive.metastore.warehouse.dir}/databasename.db
比如,名为itcast的数据库存储路径为: /user/hive/warehouse/itcast.db
数据模型概念
数据模型:用来描述数据、组织数据和对数据进行操作,是对现实世界数据特征的描述。
Hive的数据模型类似于RDBMS库表结构,此外还有自己特有模型。
Hive中的数据可以在粒度级别上分为三类: Table 表、 Partition 分区、 Bucket 分桶,如图:

四、Hive表存储格式
hive表的存储格式有两类:行式存储、列式存储。
对于这两种的存储格式,其查询方法也不同,基于存储格式可以分为下面这两种查询分时。
行式查询:适用于查一整行,TextFile、SequenceFile使用行存储。
列式查询:适用于查某一列,ORC、Parquet使用列存储。
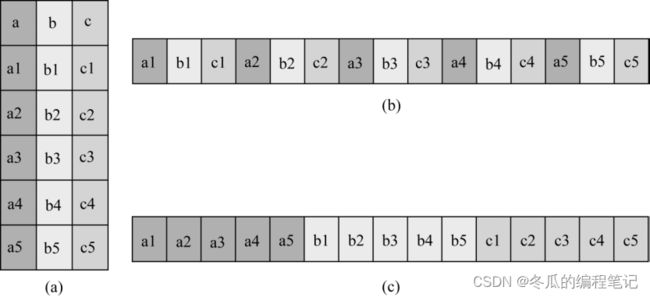
对于这两种查询方式举个简单例子:(a)为逻辑表,(b)为行式存储,(c)为列式存储
文件格式-TextFile
1、TextFile是Hive中默认的文件格式,存储形式为按行存储。
2、工作中最常见的数据文件格式就是TextFile文件,几乎所有的原始数据生成都是TextFile格式,所以Hive设计时考虑到为了避免各种编码及数据错乱的问题,选用了TextFile作为默认的格式。
3、建表时不指定存储格式即为TextFile,导入数据时把数据文件拷贝至HDFS不进行处理。

文件格式-SequenceFile
1,SequenceFile是Hadoop里用来存储序列化的键值对即二进制的一种文件格式。
2,SequenceFile文件也可以作为MapReduce作业的输入和输出,hive也支持这种格式。

文件格式-Parquet
1,Parquet是一种支持嵌套结构的列式存储文件格式,最早是由Twitter和Cloudera合作开发,2015年5月从Apache孵化器里毕业成为Apache顶级项目。
2,是一种支持嵌套数据模型对的列式存储系统,作为大数据系统中OLAP查询的优化方案,它已经被多种查询引擎原生支持,并且部分高性能引擎将其作为默认的文件存储格式。
3,通过数据编码和压缩,以及映射下推和谓词下推功能,Parquet的性能也较之其它文件格式有所提升。

Parquet的特点: 高效的数据编码和压缩
文件格式-ORC
1,ORC(OptimizedRC File)文件格式也是一种Hadoop生态圈中的列式存储格式;
2,它的产生早在2013年初,最初产生自Apache Hive,用于降低Hadoop数据存储空间和加速Hive查询速度;
3,2015年ORC项目被Apache项目基金会提升为Apache顶级项目。

1,ORC不是一个单纯的列式存储格式,仍然是首先根据行组分割整个表,在每一个行组内进行按列存储。
2,ORC文件是自描述的,它的元数据使用Protocol Buffers序列化,并且文件中的数据尽可能的压缩以降低存储空间的消耗,目前也被Hive、Spark SQL、Presto等查询引擎支持。