MySQL中函数的详细应用,优秀的你值得一看

欢迎您来到我的MySQL基础复习专栏
☆* o(≧▽≦)o *☆哈喽~我是小小恶斯法克
✨博客主页:小小恶斯法克的博客
该系列文章专栏:重拾MySQL
文章作者技术和水平很有限,如果文中出现错误,希望大家能指正
感谢大家的关注! ❤️

文章目录
MySQL的函数说明
字符串函数
案例:
数值函数
日期函数
案例
流程函数
案例:
MySQL的函数说明
函数是指一段可以直接被另一段程序调用的程序或代码。也就意味着,这一段程序或代码在MySQL中已经给我们提供了,我们要做的就是在合适的业务场景调用对应的函数完成对应的业务需求即可。
那么,函数到底在哪儿使用呢?
我们先来看两个场景:

在企业的OA或其他的人力系统中,经常会提供的有这样一个功能,每一个员工登录上来之后都能 够看到当前员工入职的天数。 而在数据库中,存储的都是入职日期,如2024-1-11,那如何快速计算出天数呢?
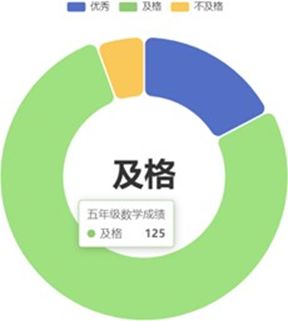
在做报表这类的业务需求中,我们要展示出学员的分数等级分布。而在数据库中,存储的是学生的分数值,如95,77,如何快速判定分数的等级呢?
其实,上述的这一类的需求呢,我们通过MySQL中的函数都可以很方便的实现 。
MySQL中的函数主要分为以下四类: 字符串函数、数值函数、日期函数、流程函数。
字符串函数
MySQL中内置了很多字符串函数,常用的几个如下:
| 函数 |
功能 |
| CONCAT(S1,S2,...Sn) |
字符串拼接,将S1,S2,... Sn拼接成一个字符串 |
| LOWER(str) |
将字符串str全部转为小写 |
| UPPER(str) |
将字符串str全部转为大写 |
| LPAD(str,n,pad) |
左填充,用字符串pad对str的左边进行填充,达到n个字符串长度 |
| RPAD(str,n,pad) |
右填充,用字符串pad对str的右边进行填充,达到n个字符串长度 |
| TRIM(str) |
去掉字符串头部和尾部的空格 |
| SUBSTRING(str,start,len) |
返回从字符串str从start位置起的len个长度的字符串 |
演示如下:
concat : 字符串拼接
select concat('Hello' , ' MySQL');执行:

lower : 全部转小写
select lower('Hello');执行:

upper : 全部转大写
select upper('Hello');执行: 
lpad : 左填充
首先传入你要操作哪个字符串,比如01,第二个参数是length,你要填充到几位,假设我需要填充10位,第三个参数是拿什么填充,假设拿问号填充
select lpad('01', 10, '?');执行:

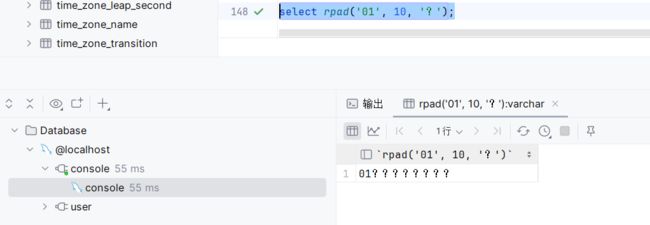
执行结果为什么是8个问号,为什么是8个?就是因为本身字符串的长度为2,填充8个问号那么字符串的长度就为10了。如果改为右填充也是一样的逻辑,只不过是会在右边填8个问号
rpad : 右填充
select rpad('01', 10, '?');执行:
trim : 去除字符串两端空格
如下字符串中有3个地方有空格,hello的前面,mysql后面,两者之间,这3个位置空格。那么trim只能去除两端的空格,不会影响中间的空格
select trim(' Hello MySQL ');执行:

substring : 截取子字符串
select substring('Hello MySQL',1,5);里面要传递的参数,首先我们要传递截取的是哪一个字符串,接着我们要传递的第二个参数,你当前要从哪个位置开始截取,比如从1开始截取,索引值是从1开始截取,也就是从H开始截取,紧接着第三个参数你需要截取几个呢?假设是5个,那么就是Hello,正好5个。
注意!我们所说的substring的截取,是截取到的东西会留下来,而不是截取的是要去除
执行:

案例:

假设由于业务需求变更,企业员工的工号,统一为5位数,目前不足5位数的全部在前面补0。比如: 1号员工的工号应该为00001。
update emp set workno = lpad(workno, 5, '0');代码思路:
1.首先确定我们要操作的字段是workno
2.你要在前面补0,要执行的肯定是update的这样一个修改的操作
3.更新操作的语法:update 表名 set 需要更新哪个字段
4.在工号前面补0,那么要用到的就是左填充lpad
5.lpad()中指定3个参数,第一个参数是你要操作的是哪个字符串,你要操作的是workno这一列,所以你填充进去的就要是workno,第二个参数是,你填充字符串要到达多少长度,最终是要5位数,所以填5,第三个参数,因为不足5为就要在前面补0,所以第三个参数是0
执行:
数值函数
常见的数值函数如下:
| 函数 |
功能 |
| CEIL(x) |
向上取整 |
| FLOOR(x) |
向下取整 |
| MOD(x,y) |
返回x/y的模 |
| RAND() |
返回0~1内的随机数 |
| ROUND(x,y) |
求参数x的四舍五入的值,保留y位小数 |
演示如下:
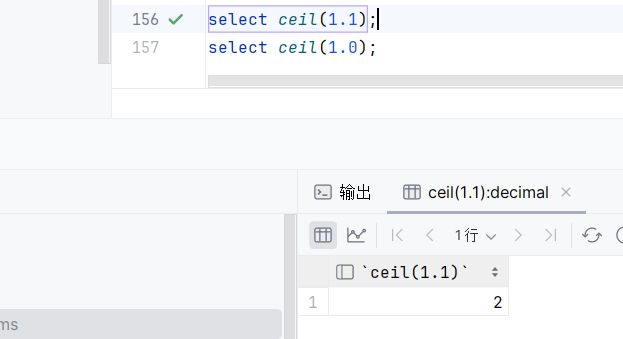
ceil:向上取整
select ceil (1.1);select ceil (1.0) ;向上取整,你只要小数位不是0,它都会向上取
执行:
执行:

floor:向下取整
select floor(1.9);执行:

mod:取模
select mod(7,4); --7/4.1余3,故为3执行:

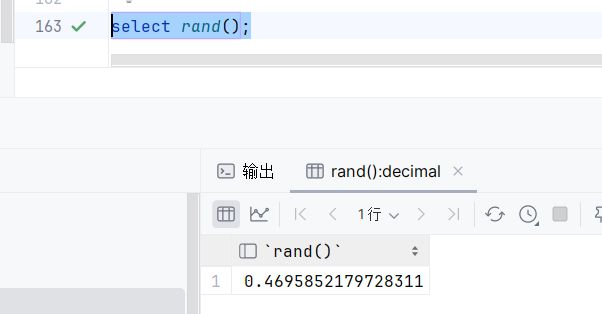
rand:获取随机数
select rand();执行:
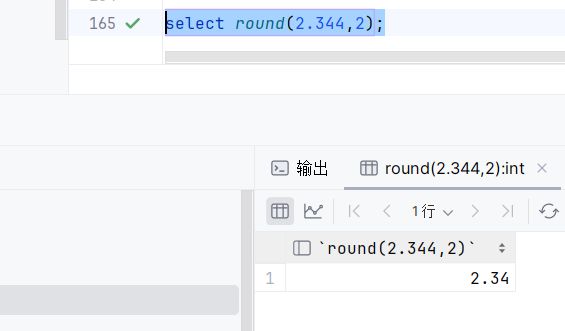
round:四舍
select round(2.344,2);执行:
案例:
通过数据库的函数,生成一个六位数的随机验证码。
select lpad(round(rand()*1000000 , 0), 6, '0');随机验证码,马上反应过来是mysql中的函数rand,但是再思考,rand所生成出来的数值是介于0-1的小数,那怎么样才能生成6位随机数
那么我们就想只要在小数的基础上×某一个值即可
1.首先执行select rand(); 执行如下:
2.那么这个数怎么变为6位数呢?直接×1000000,执行如下:
select rand()*1000000 ;
3.那么这个数我们是不是只取整数部分即可,也就意味不需要后面小数,将小数位去掉,我们的思路就是四舍五入,然后再去小数位数为0即可,也就是再套一个round函数
select round( rand()*1000000 , 0 ) ;执行如下:
4.在多执行了几次操作之后发现,有点不对,如下图:
出现了5位数的结果,那么说明还有bug,bug在哪呢?原因是生成随机数是介于0-1的,算出来0.034919是不是0-1之间的随机数,是,但此时×1000000算出来就是34919,五位数,如何解决?那么我们可以反应过来,补0,不管是在前面补0还是后面补0,代码去判断这个数有没有6位,没有满足6位的话就补0,就解决了,只要最终达到6位数即可。
select lpad(round(rand()*1000000 , 0), 6, '0'); --lpad或rpad都行执行:





日期函数
常见的日期函数如下:
| 函数 |
功能 |
| CURDATE() |
返回当前日期 |
| CURTIME() |
返回当前时间 |
| NOW() |
返回当前日期和时间 |
| YEAR(date) |
获取指定date的年份 |
| MONTH(date) |
获取指定date的月份 |
| DAY(date) |
获取指定date的日期 |
| DATE_ADD(date, INTERVAL expr type) |
返回一个日期/时间值加上一个时间间隔expr后的时间值 |
| DATEDIFF(date1,date2) |
返回起始时间date1 和 结束时间date2之间的天数 |
演示如下:
curdate:当前日期
select curdate();执行:
curtime:当前时间
select curtime();执行:
now:当前日期和时间
select now();执行:

YEAR , MONTH , DAY:当前年、月、日
select YEAR(now());
select MONTH(now());
select DAY(now());
select year(now()),month(now()),day(now()) ;
执行:

date_add:增加指定的时间间隔
select date_add(now(), INTERVAL 70 YEAR );1. 返回一个now(),也就是当前时间和日期,但是增加70年
2.指定日期的基础上增加,可以是年(此题中是增加了年),可以是月,可以是天,取决于你后面指定的单位
执行:
datediff:获取两个日期相差的天数
select datediff('2024-10-01', '2024-12-01');1.可以构造时间,时间依然用引号括起来
2.要注意,它在求取天数差异的时候,是第一个参数减去第二个参数
执行: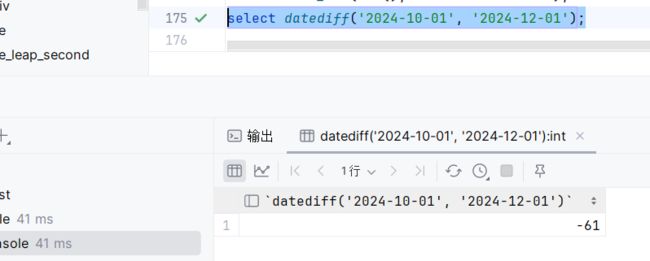
案例
查询所有员工的入职天数,并根据入职天数倒序排序。
代码思路:
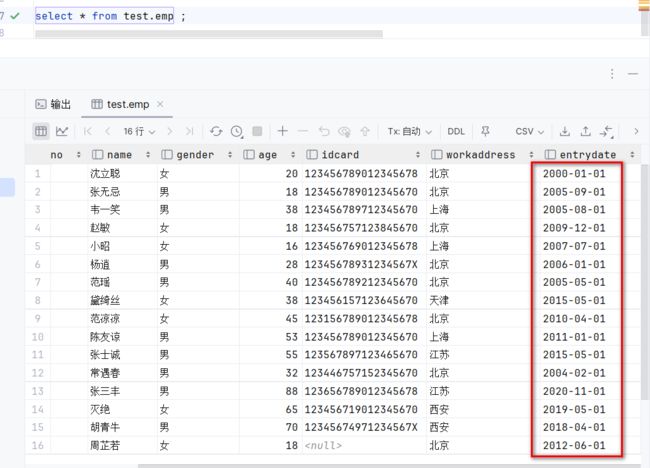
1.要查询所有员工的入职天数,我们先把所有员工的入职信息查询出来
select * from emp ;执行:
2.那么思考一个问题,需要员工的入职天数,员工的姓名我们是需要的吧。那员工的入职天数怎么计算?也就是需要用当前日期减去它的入职日期,相差的天数就有了,很明显要用到datediff函数
select name , datediff( curdate() , entrydate ) from emp ; --只需要年月日执行:

之后再根据入职天数倒序排序
那么我们肯定是需要用到order by去排序,那么order by之后的排序字段是什么呢?根据entrydate去排序嘛,这样写代码嘛?错,它是要根据入职天数排序,是根据它们的天数差排序,而不是让你又根据原本的字段entrydate排序。
select name , datediff( curdate() , entrydate ) from emp order by entrydate desc ;
但是此时用到的这个函数,最后查询出来的列名是datediff( curdate() , entrydate ),就是这个函数,十分不直观,所有我们可以给它起一个别名,别名叫做entrydates,我们去排序的时候根据这个别名去排序即可
select name , datediff( curdate() , entrydate ) as entrydates from emp order by entrydates desc ;执行:

流程函数
流程函数也是很常用的一类函数,可以在SQL语句中实现条件筛选,从而提高语句的效率。
| 函数 |
功能 |
| IF(value , t , f) |
如果value为true,则返回t,否则返回 f |
| IFNULL(value1 , value2) |
如果value1不为空,返回value1,否则返回value2 |
| CASE WHEN [ val1 ] THEN [res1] ... ELSE [ default ] END |
如果val1为true,返回res1,... 否则返回default默认值 |
| CASE [ expr ] WHEN [ val1 ] THEN [res1] ... ELSE [ default ] END |
如果expr的值等于val1,返回 res1,... 否则返回default默认值 |
演示如下:
if
第一个参数就是用来做判断的,含义就是如果第一个值为true,就返回参数二Ok,如果第一个参数为false,就返回参数三Error
select if(false, 'Ok', 'Error'); 执行:
ifnull
1.用来判定某一个值是否为空,如果不为空返回该值,如果为空返回第二个参数
2.注意' ',空字符串不为空,会返回空字符串
3.针对第3个代码,注意这个里面的null指的是你是否为null值,但是如果里面如果传递的是一个null值,它还返回null嘛,不返回,它将会使用默认值,也就是第二个参数
select ifnull('Ok','Default');
select ifnull('','Default');
select ifnull(null,'Default');
执行:

执行:

执行:

(case when then else end)
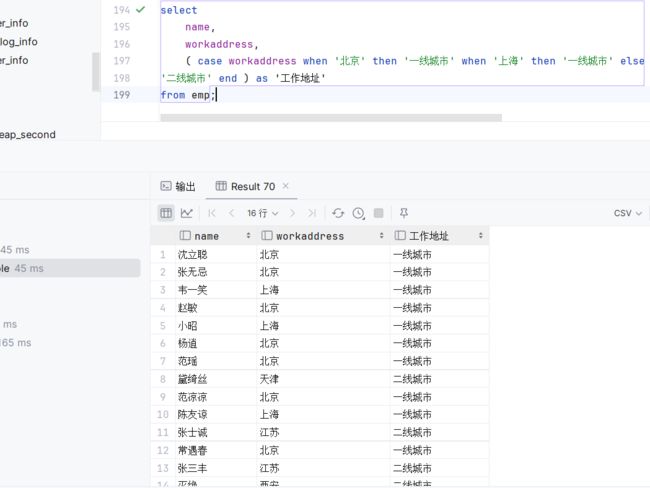
需求: 查询emp表的员工姓名和工作地址 (北京/上海 ----> 一线城市 , 其他 ----> 二线城市)
注意题目展示的工作地址是有要求的,如果员工的地址是上海或者是北京,此时要展示一线城市,如果是其他城市要展示的是二线城市
代码思路:
1.首先,要员工的姓名和工作地址
select name, workaddress from emp ;执行:
之后要做的就是把北京上海的地址换成一线城市展示,用到(case when then else end)函数
select name, workaddress, ( case workaddress when '北京' then '一线城市' when '上海' then '一线城市' else '二线城市' end ) as '工作地址' from emp;执行:

案例:
需求
统计班级各个学员的成绩,展示规则如下:
>=85,展示优秀
>=60,展示及格
否则,展示不及格
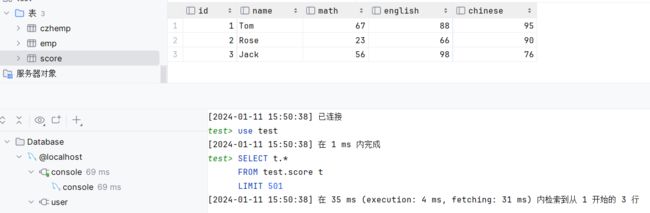
create table score(
id int comment 'ID',
name varchar(20) comment '姓名',
math int comment '数学',
english int comment '英语',
chinese int comment '语文'
) comment '学员成绩表';
insert into score (id, name, math, english, chinese) VALUES (1, 'Tom', 67, 88, 95), (2, 'Rose' , 23, 66, 90),(3, 'Jack', 56, 98, 76);将表数据成功创建
具体的SQL语句如下:
代码思路:
1.先看一整张表的数据再考虑一下怎么实现
select * from score ;2.写一下里面要展示的字段
select id, name, math, english, chinese, (case when math >= 85 then '优秀' when math >=60 then '及格' else '不及格' end ) as '数学等级', (case when english >= 85 then '优秀' when english >=60 then '及格' else '不及格' end ) as '英语等级', (case when chinese >= 85 then '优秀' when chinese >=60 then '及格' else '不及格' end ) as '语文等级' from score;执行:

小小的总结: