算法训练营Day3
#链表 #移除链表元素 #设计链表 #翻转链表
开源学习资料
Feeling and experiences:
链表理论基础:
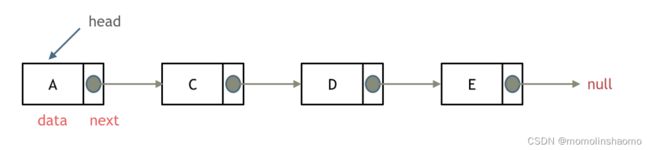
以上就是一个简单的单链表,每个节点有两个域,指针域与数据域。
每个节点的next指针指向下一个节点的地址。
当然,链表还有其他的类型,例如双链表,循环链表等。
卡哥在这里就写的很详细了——>链表理论基础
我就从题中来体会链表的细节以及用法。
移除链表元素:力扣题目链接
该题目就是数据结构中链表一章的基本删除操作,那么就关键在于怎么找到这个要删除的节点?
找到之后改怎么处理它?
在数据结构的基础学习中,我们知道要想在链表中找到要删除的节点,就要找到指向这个节点的节点,也就要从头依次遍历(而在数组中,则是随机存取的,想找到一个元素,就很简单),这也是链表的一个特性。
以下是该题的思路与代码:
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode removeElements(ListNode head, int val) {
//思路:删除目标节点,那么肯定要先找到这个节点,当它满足条件,删除,再将指向删除节点的指针指向删除节点所指向的节点
//那么首先提出特殊情况,当链表为空,则直接返回
if(head == null){
return head;
}
//在循环之前检查头节点是否要删除
while(head !=null && head.val == val){
head = head.next;
//可以理解为当头姐节点的值已经等于val则删除它,让下一个当头节点
}
//循环遍历找要删除节点
ListNode cur = head;
while(cur != null&&cur.next!=null){
//只要cur 和 cur所指向的节点不为空
if(cur.next.val == val){
//跳过这个要删除的节点,改变指针指向
cur.next = cur.next.next;
}
else{
cur = cur.next;
}
}
return head;
}
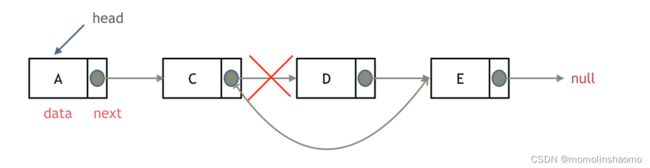
}其实大体的思路很简答,一就是先找到这个要删除的节点,然后我们跳过它,改变原本指向它的那个节点的指针,让该指针去指向删除节点所指向的节点。
以下这个图可以帮助理解:
目前也还在上数据结构,不妨用c语言再写一遍,当作复习了。
先记录一下第一次错误的提交:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* removeElements(struct ListNode* head, int val) {
if(head == NULL){
return head;
}
if(head !=NULL && head->val == val){
struct ListNode *p = head;
head = head->next;
free(p);
}
struct ListNode *node = head;
while(node != NULL && node->next != NULL){
if(node->next->val == val){
struct ListNode *p = node->next;
node->next = node->next->next;
free(p);
}
else{
node = node->next;
}
}
return head;
}其中存在有指针悬挂,内存对齐的错误.......
果然复习一下还是好的,指针确实容易出错。
Because:
如果不是自己new出来的对象不建议去delete,因为这个节点不是我们自己 new 的,就不清楚它的生命周期,力扣后台还会拿它怎么用之类的,free掉后还可能出现访问已释放内存的问题!
更改了错误:
struct ListNode* removeElements(struct ListNode* head, int val){
struct ListNode* temp;
// 当头结点存在并且头结点的值等于val时
while(head && head->val == val) {
temp = head;
// 将新的头结点设置为head->next并删除原来的头结点
head = head->next;
free(temp);
}
struct ListNode *cur = head;
// 当cur存在并且cur->next存在时
// 此解法需要判断cur存在因为cur指向head。若head本身为NULL或者原链表中元素都为val的话,cur也会为NULL
while(cur && (temp = cur->next)) {
// 若cur->next的值等于val
if(temp->val == val) {
// 将cur->next设置为cur->next->next并删除cur->next
cur->next = temp->next;
free(temp);
}
// 若cur->next不等于val,则将cur后移一位
else
cur = cur->next;
}
// 返回头结点
return head;
}
对于指针的写法,我认为更好理解。比如cur->next = temp->next; 我的理解是前面的的cur->next 就形象与一个箭头,而后面的temp->next则表示cur的下一个节点,这样连起来理解的话,就是cur伸出来一个箭头,而这个伸出来的箭头就是指向了temp的下一个节点。
设计链表:力扣题目链接
基本的链表设置
加深对指针的使用
typedef struct MyLinkedList{
int val;
struct MyLinkedList *next;
int size;
} MyLinkedList;
MyLinkedList* myLinkedListCreate() {
//初始化链表
MyLinkedList* head = (MyLinkedList *)malloc(sizeof (MyLinkedList));
head->next = NULL;
return head;
}
int myLinkedListGet(MyLinkedList* obj, int index) {
MyLinkedList *cur = obj->next;
for (int i = 0; cur != NULL; i++){
if (i == index){
return cur->val;
}
else{
cur = cur->next;
}
}
return -1;
}
void myLinkedListAddAtHead(MyLinkedList* obj, int val) {
MyLinkedList *newNode = (MyLinkedList *)malloc(sizeof (MyLinkedList));
newNode->val = val;
newNode->next = obj->next;
obj->next = newNode;
}
void myLinkedListAddAtTail(MyLinkedList* obj, int val) {
MyLinkedList *cur = obj;
while(cur->next != NULL){
cur = cur->next;
}
MyLinkedList *ntail = (MyLinkedList *)malloc(sizeof (MyLinkedList));
ntail->val = val;
ntail->next = NULL;
cur->next = ntail;
}
void myLinkedListAddAtIndex(MyLinkedList* obj, int index, int val) {
if (index == 0){
myLinkedListAddAtHead(obj, val);
return;
}
MyLinkedList *cur = obj->next;
for (int i = 1 ;cur != NULL; i++){
if (i == index){
MyLinkedList* newnode = (MyLinkedList *)malloc(sizeof (MyLinkedList));
newnode->val = val;
newnode->next = cur->next;
cur->next = newnode;
return;
}
else{
cur = cur->next;
}
}
}
void myLinkedListDeleteAtIndex(MyLinkedList* obj, int index) {
if (index == 0){
MyLinkedList *tmp = obj->next;
if (tmp != NULL){
obj->next = tmp->next;
free(tmp);
}
return;
}
MyLinkedList *cur = obj->next;
for (int i = 1 ;cur != NULL && cur->next != NULL; i++){
if (i == index){
MyLinkedList *tmp = cur->next;
if (tmp != NULL) {
cur->next = tmp->next;
free(tmp);
}
return;
}
else{
cur = cur->next;
}
}
}
void myLinkedListFree(MyLinkedList* obj) {
while(obj != NULL){
MyLinkedList *tmp = obj;
obj = obj->next;
free(tmp);
}
}
/**
* Your MyLinkedList struct will be instantiated and called as such:
* MyLinkedList* obj = myLinkedListCreate();
* int param_1 = myLinkedListGet(obj, index);
* myLinkedListAddAtHead(obj, val);
* myLinkedListAddAtTail(obj, val);
* myLinkedListAddAtIndex(obj, index, val);
* myLinkedListDeleteAtIndex(obj, index);
* myLinkedListFree(obj);
*/后面还需要多多复习数据结构!
翻转链表:力扣题目链接
力扣上的示意图:
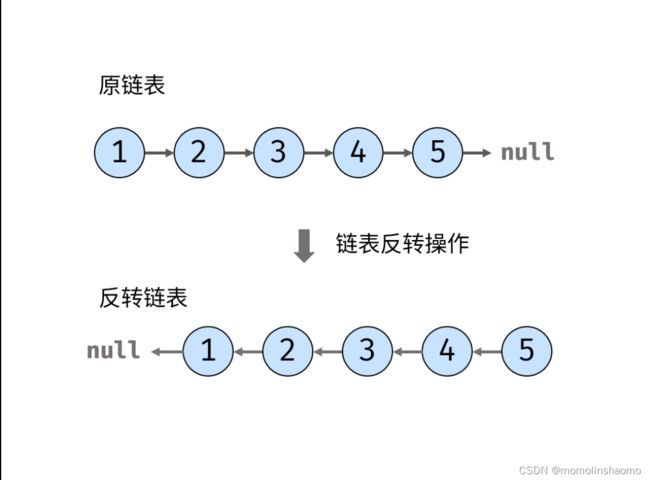
最容易想到的当然是头尾值依次交换,那么就可以用双指针。
一个指针指向头节点,一个指针指向null(为什么不指向最后一个,也就是上图中的5?)
因为要去指向最后一个节点的话,就要依次遍历,才能找到它了。(而且也达不到翻转的目的)
画了一个草图利于理解:

代码思路如下:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* reverseList(struct ListNode* head) {
struct ListNode *cur =head;
struct ListNode *pre = NULL;
while(cur != NULL){
//由于节点没有引用其前一个节点,因此必须事先存储其前一个节点。
struct ListNode *temp = cur->next;
cur->next = pre;
//这里注意:要先移动pre再移动cur
//如果先移动cur的话,pre移动过来就重合了
pre = cur;
cur = temp;
}
return pre;
}精髓和关键就在于:pre与cur指针,类似于一个在前一个在后,你追我赶,而temp相当于一个临时变量,防止进行完第一步,cur与pre这两个指针就找不到位置移动了。
有了temp,cur就可以移动到temp的位置。
还有一个关键是pre和cur的移动顺序,一定是pre先移动!
意思就是cur要等着pre,等pre到了它才移动,不然cur跑太快了,pre就要一次跳两格。(一个形象化理解,可以根据图来理解)
今天再熟悉回顾一下链表的基本抽象操作,再试一下递归解答翻转链表!
“林花谢了春红,太匆匆。
无奈朝来寒雨晚来风。
胭脂泪,留人醉,几时重。
自是人生长恨水长东。
林花谢了春红,凄凄惨惨,往事东流.....”
Fighting!