对比fwrite、mmap、DirectIO 的内存、性能开销,剖析 Page Cache
背景

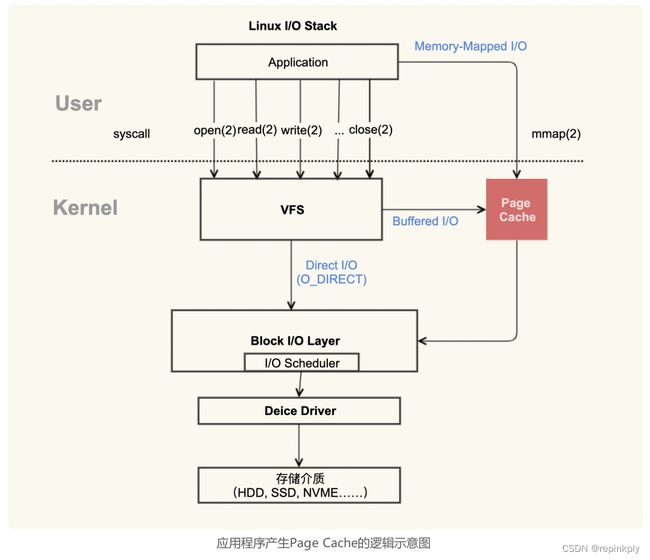
如上图所示:应用程序写文件有三种形式。
- fwrite : 应用程序 -> fwrite(Buffered IO) -> File System -> Page Cache -> Block IO Layer -> Device & Disk etc.
- mmap : 应用程序 -> mmap -> Page Cache -> Block IO Layer -> Device & Disk etc.
- Direct IO : 应用程序 -> Block IO Layer -> Device & Disk etc.
Direct IO优点:使用Direct I/O时,数据直接在应用程序和存储设备之间传输,绕过了操作系统的缓存机制。这样可以提高数据传输的效率
Direct IO缺点:其中一个限制是,Direct I/O要求数据缓冲区必须对齐到存储设备的块大小,否则会导致性能下降或者出现错误。
为了解决这个问题,通常需要使用一块内存作为中转缓冲区,将应用程序的数据先复制到中转缓冲区中,然后再使用Direct I/O将数据从中转缓冲区传输到存储设备。这样可以保证数据缓冲区对齐,并且可以避免在应用程序和存储设备之间频繁地复制数据。
这块中转缓冲区通常被称为“heap”,因为它是从堆内存中分配的。在使用Direct I/O时,heap的大小通常需要根据存储设备的块大小和应用程序的需求来确定。
测试用例
#include
#include
#include
#include
#include
#include
#include
using namespace std;
const int FILE_SIZE = 1024 * 1024 * 1024; // 1GB
const int BLOCK_SIZE = 4096; // 4KB
void test_fwrite() {
ofstream ofs("test_fwrite.bin", ios::binary);
char* buffer = new char[BLOCK_SIZE];
auto start = chrono::high_resolution_clock::now();
for (int i = 0; i < FILE_SIZE / BLOCK_SIZE; i++) {
ofs.write(buffer, BLOCK_SIZE);
}
auto end = chrono::high_resolution_clock::now();
cout << "fwrite time: " << chrono::duration_cast(end - start).count() << "ms" << endl;
delete[] buffer;
}
void test_mmap() {
int fd = open("test_mmap.bin", O_RDWR | O_CREAT, 0666);
ftruncate(fd, FILE_SIZE);
char* buffer = (char*) mmap(NULL, FILE_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
auto start = chrono::high_resolution_clock::now();
memset(buffer, 0, FILE_SIZE);
auto end = chrono::high_resolution_clock::now();
cout << "mmap time: " << chrono::duration_cast(end - start).count() << "ms" << endl;
munmap(buffer, FILE_SIZE);
close(fd);
}
void test_directio() {
int fd = open("test_directio.bin", O_RDWR | O_CREAT | O_DIRECT, 0666);
char* buffer = new char[BLOCK_SIZE];
char* heap_buffer = new char[FILE_SIZE];
auto start = chrono::high_resolution_clock::now();
for (int i = 0; i < FILE_SIZE / BLOCK_SIZE; i++) {
write(fd, buffer, BLOCK_SIZE);
}
auto end = chrono::high_resolution_clock::now();
cout << "directIO time: " << chrono::duration_cast(end - start).count() << "ms" << endl;
delete[] buffer;
delete[] heap_buffer;
close(fd);
}
int main() {
test_fwrite();
test_mmap();
test_directio();
return 0;
} - 这个 demo 分别测试了 fwrite、mmap 和 DirectIO 的性能,其中 fwrite 和 mmap 都是直接写入文件,而 DirectIO 则需要使用 heap_buffer 作为内存中转。
-
在测试 DirectIO 时,我们使用了 O_DIRECT 标志来打开文件,这会禁用文件系统缓存,从而确保数据直接从内存写入磁盘。但是,由于 DirectIO 要求内存对齐,因此我们需要使用 heap_buffer 来确保内存对齐。这个 heap_buffer 的大小与文件大小相同。
运行这个 demo,我们可以得到以下输出:
wj@wj:~/WORK/Learning/Learning/DirectIO$ ./test.out
fwrite time: 649ms
mmap time: 267ms
directIO time: 1191ms
wj@wj:~/WORK/Learning/Learning/DirectIO$实验结论
从输出可以看出,mmap 的性能远远优于 fwrite,而 DirectIO 的性能比 fwrite 差一些。
这表明,mmap 可以映射文件到内存中,从而避免了数据的复制,因此性能更高。
而 DirectIO 需要使用 heap_buffer 作为内存中转,因此存在一定的内存开销,目前来看这个开销还是非常大的,不能忽略不计。
DirectIO的内存开销
DirectIO 的内存开销主要取决于两个因素:每个请求的大小和并发请求数量。由于 DirectIO 使用 heap_buffer 作为内存中转,因此每个请求都需要分配一定大小的内存。并且,由于 DirectIO 是异步的,因此在高并发情况下,可能会有大量的请求同时进行,从而导致内存开销增加。
具体来说,假设每个请求的大小为 `request_size`,并发请求数量为 `concurrency`,则 DirectIO 的内存开销可以估算为: ``` memory_overhead = request_size * concurrency ```
例如,如果每个请求的大小为 4KB,同时有 1000 个请求在进行,则 DirectIO 的内存开销大约为 4MB。
需要注意的是,这只是一个粗略的估算,实际的内存开销可能会受到其他因素的影响,例如操作系统的内存管理策略、硬件配置等。
实验demo
#include
#include
#include
#include
#include
#include
#define BUF_SIZE 4096
int main(int argc, char *argv[]) {
int fd;
char *buf;
struct stat st;
off_t offset = 0;
ssize_t nread;
if (argc != 2) {
fprintf(stderr, "Usage: %s \n", argv[0]);
exit(EXIT_FAILURE);
}
//使用 `open` 函数打开一个文件,并指定 `O_DIRECT` 标志以启用 DirectIO
fd = open(argv[1], O_RDONLY | O_DIRECT);
if (fd == -1) {
perror("open");
exit(EXIT_FAILURE);
}
//使用 `fstat` 函数获取文件的信息,包括块大小
if (fstat(fd, &st) == -1) {
perror("fstat");
exit(EXIT_FAILURE);
}
//使用 `aligned_alloc` 函数分配一个对齐到块大小的缓冲区
buf = (char*)aligned_alloc(st.st_blksize, BUF_SIZE);
if (buf == NULL) {
perror("aligned_alloc");
exit(EXIT_FAILURE);
}
//使用 `pread` 函数读取文件,并在读取过程中计算内存开销
while ((nread = pread(fd, buf, BUF_SIZE, offset)) > 0) {
offset += nread;
}
if (nread == -1) {
perror("pread");
exit(EXIT_FAILURE);
}
printf("offset : %ld\n",offset);
free(buf);
close(fd);
return 0;
} wj@wj:~/WORK/Learning/Learning/DirectIO$ g++ directIO.cpp -o directIO.out
wj@wj:~/WORK/Learning/Learning/DirectIO$ ./directIO.out test_mmap.bin
offset : 1073741824
wj@wj:~/WORK/Learning/Learning/DirectIO$ 注意,该程序只是一个简单的示例,实际的内存开销可能会更复杂,需要根据具体情况进行测试和分析。
fwrite 和 mmap 都需要经过 Page Cache,再到 Block IO Layer,那么Linux系统为什么要这样设计呢?
什么是Page Cache?
思考一个问题:Page Cache 到底是属于内核空间还是属于用户空间呢?
参考:如何用数据观测Page Cache?_如何查看page cache-CSDN博客