【Python】数据可视化--基于TMDB_5000_Movie数据集
一、数据准备
tmdb_5000_movie数据集下载
二、数据预处理
观察数据集合情况
import pandas as pd
import ast
import warnings
warnings.filterwarnings('ignore')
# 加载数据集
df = pd.read_csv('tmdb_5000_movies.csv')
# 查看数据集信息
print(df.info())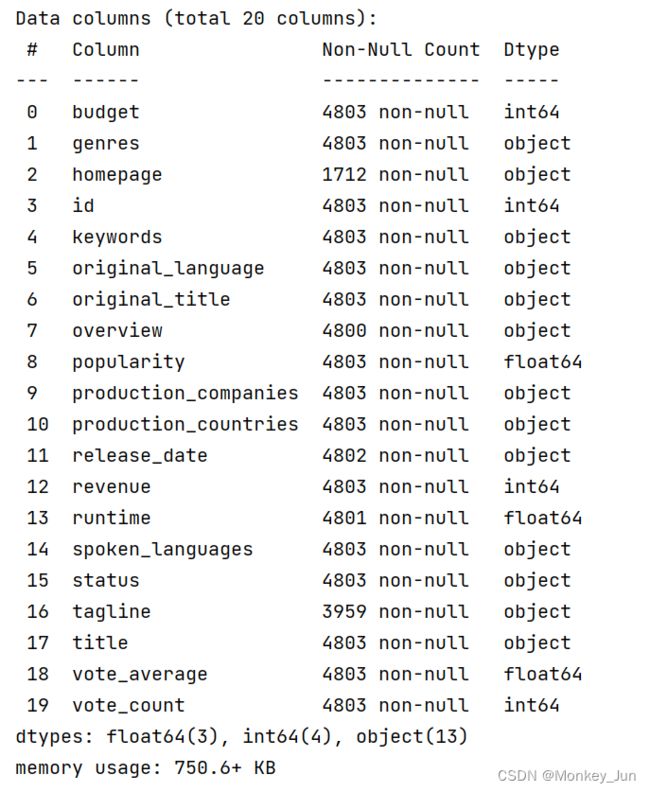 由于原数据集包含的数据信息较多,因此我们可以在每次需要分析的时候提取部分字段进行分析,比如关键字、电影类型、上映时间、生产厂家、预算、收入等等
由于原数据集包含的数据信息较多,因此我们可以在每次需要分析的时候提取部分字段进行分析,比如关键字、电影类型、上映时间、生产厂家、预算、收入等等
df = df[['keywords','genres','production_companies','release_date','budget','revenue','vote_average','vote_count']]观察过滤完的数据集和我们不难发现存在部分字段缺失值,字段类型数据形式不是我们想要的结果,因此我们对数据集进行进一步处理
import ast
# 将genres、production_companies中的字符串转换为列表
df['genres'] = df['genres'].apply(lambda x: ast.literal_eval(x))
df['production_companies'] = df['production_companies'].apply(lambda x: ast.literal_eval(x))
# 处理缺值数据
filtered_df = df[~df['release_date'].isna()]
filtered_df.dropna(inplace=True)
# 提取日期中的年份
filtered_df['year'] = pd.to_datetime(filtered_df['release_date']).dt.year
filtered_df['year'].apply(int)三、数据可视化分析
注:下面代码需要上面的预处理结果。
一)2000-2016年期间Twentieth Century Fox Film Corporation、Universal Pictures和Paramount Pictures三家影视公司每年制作的电影数量
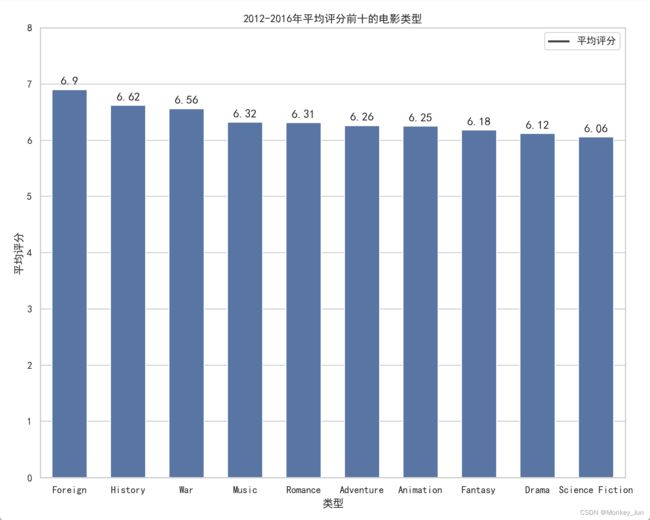
二)2012-2016年平均评分前十的电影类型
import matplotlib.pyplot as plt
import seaborn as sns
# 提取待处理字段
filtered_df = filtered_df[['year', 'genres', 'vote_average']]
def split_data(df, split_column):
# 拆分指定的列
df = df.explode(split_column)
# 过滤掉指定列值为nan的数据
df = df[~df[split_column].isna()]
# 提取出指定列的名称
df.loc[:, split_column] = df[split_column].apply(lambda x: x['name'])
return df
# 拆分genres
filtered_df = split_data(filtered_df, 'genres')
filtered_df.rename(columns={'genres':'genre'}, inplace=True)
# 筛选2012-2016年的电影
filtered_df = filtered_df[(2012 <= filtered_df['year']) & (filtered_df['year'] <= 2016)]
# 计算各电影类型平均评分和
grouped_df = filtered_df.groupby('genre')['vote_average'].mean().reset_index(name='vote_average')
grouped_df = grouped_df.sort_values(by='vote_average', ascending=False)
grouped_df = grouped_df.head(10)
# 生成可视化图表
plt.figure(figsize=(10, 8))
sns.barplot(x=list(grouped_df['genre']),
y=list(round(grouped_df['vote_average'],2)),
width=0.6)
plt.ylim(0,8)
plt.title('2012-2016年平均评分前十的电影类型')
plt.xlabel('类型')
plt.ylabel('平均评分')
plt.tight_layout()
plt.legend(['平均评分'])
# 在柱子上方显示每个柱子的值
for index, value in enumerate(list(round(grouped_df['vote_average'],2))):
plt.text(index, value + 0.08, str(value), ha='center')
plt.show()运行结果:
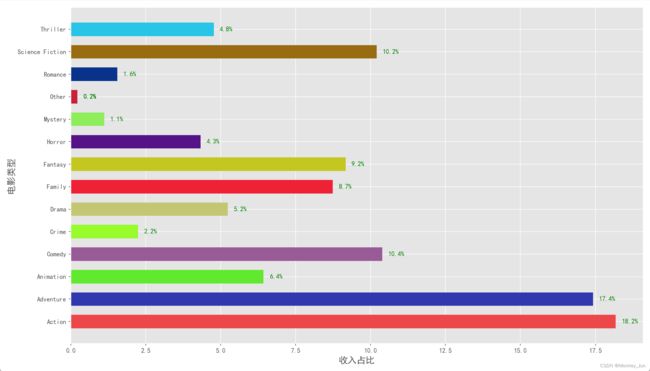
三)2016年的总利润中,各电影类型所占的比例
import random
# 提取待处理字段
filtered_df = filtered_df[['year', 'genres','budget', 'revenue']]
# 处理budget、revenue
filtered_df.reset_index(inplace=True)
total = filtered_df['genres'].str.len()
total = total.apply(lambda x: 1 if x == 0 else x)
filtered_df['budget'] = filtered_df['budget'] / total
filtered_df['revenue'] = filtered_df['revenue'] / total
def split_data(df, split_column):
# 拆分指定的列
df = df.explode(split_column)
# 过滤掉指定列值为nan的数据
df = df[~df[split_column].isna()]
# 提取出指定列的名称
df.loc[:, split_column] = df[split_column].apply(lambda x: x['name'])
return df
# 拆分genres
filtered_df = split_data(filtered_df, 'genres')
filtered_df.rename(columns={'genres':'genre'}, inplace=True)
# 筛选2016年的电影
filtered_df = filtered_df[filtered_df['year'] == 2016]
# 添加利润列
filtered_df['profit'] = filtered_df['revenue'] - filtered_df['budget']
# 过滤利润小于0的
filtered_df = filtered_df[0 <= filtered_df['profit']]
# 计算各电影类型平均利润和
grouped_df = filtered_df.groupby( 'genre')['profit'].sum().reset_index(name='profit')
# 计算各电影类型所占比例
total_scale = grouped_df['profit'].sum()
# 将scale除以整列总和并乘以100,得到每行的比例
grouped_df['scale'] = (grouped_df['profit'] / total_scale) * 100
# 将scale小于1的行的genre设置为"Other"
grouped_df.loc[grouped_df['scale'] < 1, 'genre'] = "Other"
# 计算"Other"行的"profit"和"scale"的总和
other_profit_sum = grouped_df.loc[grouped_df['genre'] == "Other", 'profit'].sum()
other_scale_sum = grouped_df.loc[grouped_df['genre'] == "Other", 'scale'].sum()
grouped_df.loc[grouped_df['genre'] == "Other", ['profit', 'scale']] = [other_profit_sum, other_scale_sum]
grouped_df = grouped_df.sort_values(by='genre')
# print(grouped_df)
# 生成随机颜色
def generate_random_colors(num_colors):
colors = []
for _ in range(num_colors):
# 生成随机的 RGB 值
r = random.random()
g = random.random()
b = random.random()
colors.append((r, g, b))
return colors
# 生成可视化图表
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.size'] = '13'
x = list(grouped_df['genre'])
y = list(round(grouped_df['scale'],2))
plt.figure(figsize=(14, 8))
plt.style.use('ggplot')
bars = plt.barh(x, y, height=0.6, color=generate_random_colors(len(x))[::-1])
plt.xlabel('收入占比', fontsize=14)
plt.ylabel('电影类型', fontsize=14)
plt.tight_layout()
for i, bar in enumerate(bars):
plt.text(bar.get_width() + 0.2, bar.get_y() + bar.get_height() / 2, f'{y[i]:.1f}%', ha='left',
va='center', color='green')
plt.title('2016年的总利润中,各电影类型所占的比例', fontsize=18, x=0.5, y=1.05)
plt.show()运行结果:
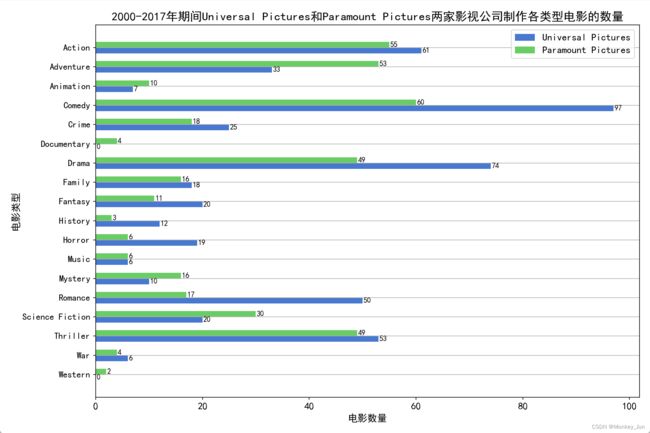
四)比较2000-2017年期间Universal Pictures和Paramount Pictures两家影视公司制作各类型电影的数量。
# 提取待处理字段
filtered_df = filtered_df[['year', 'production_companies', 'genres']]
# 筛选2000-2017年的电影
filtered_df = filtered_df[(filtered_df['year'] >= 2000) & (filtered_df['year'] <= 2017)]
def split_data(df, split_column):
# 拆分指定的列
df = df.explode(split_column)
# 过滤掉指定列值为nan的数据
df = df[~df[split_column].isna()]
# 提取出指定列的名称
df.loc[:, split_column] = df[split_column].apply(lambda x: x['name'])
return df
# 拆分production_companies
filtered_df = split_data(filtered_df, 'production_companies')
filtered_df.rename(columns={'production_companies':'company'}, inplace=True)
filtered_df = filtered_df[(filtered_df['company'] == 'Universal Pictures') | (filtered_df['company'] == 'Paramount Pictures') ]
# 拆分genres
filtered_df = split_data(filtered_df, 'genres')
filtered_df.rename(columns={'genres':'genre'}, inplace=True)
# 根据公司和类型对数据进行分组,并计算每个组的数量
grouped_df = filtered_df.groupby(['company', 'genre']).size().reset_index(name='count')
# print(grouped_df)
# 使用pivot_table函数处理数据
processed_df = pd.pivot_table(grouped_df, values='count', index='genre', columns='company', fill_value=0)
processed_df = processed_df.sort_values(by='genre', ascending=False)
# print(processed_df)
# 生成可视化结果
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.size'] = '13'
# 设置图形大小和风格
plt.figure(figsize=(12, 8))
plt.style.use('seaborn-muted')
# 数据直接提取
genres = list(processed_df.index)
universal = list(processed_df['Universal Pictures'])
paramount = list(processed_df['Paramount Pictures'])
# 绘制两家公司的数量对比图
plt.barh(np.arange(len(genres)), universal, height=0.3, label='Universal Pictures')
plt.barh(np.arange(len(genres)) + 0.3, paramount, height=0.3, label='Paramount Pictures')
plt.yticks(np.arange(len(genres)) + 0.15, genres, fontsize=12)
plt.legend()
plt.grid(axis='y')
# 添加数据标签
for i, value in enumerate(universal):
plt.text(value + 0.15, i, str(value), ha='left', va='center', fontsize=10)
for i, value in enumerate(paramount):
plt.text(value + 0.15, i + 0.3, str(value), ha='left', va='center', fontsize=10)
# 设置标题和坐标轴标签
plt.title('2000-2017年期间Universal Pictures和Paramount Pictures两家影视公司制作各类型电影的数量', fontsize=16)
plt.xlabel('电影数量')
plt.ylabel('电影类型')
plt.tight_layout()
plt.show()运行结果:
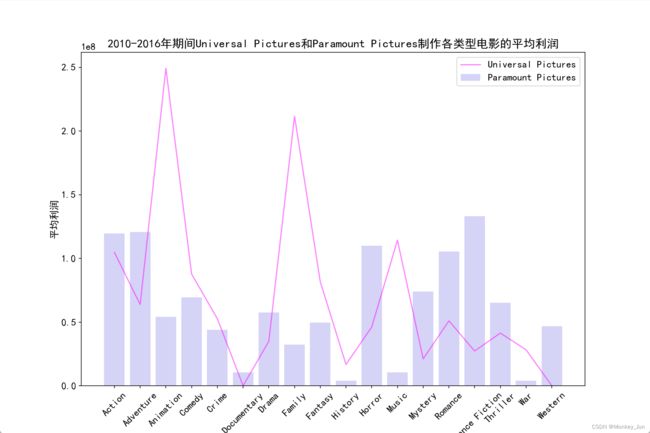
五)比较2010-2016年期间Universal Pictures和Paramount Pictures两家影视公司制作各类型电影的平均利润
# 提取待处理字段
filtered_df = filtered_df[['year', 'production_companies', 'genres', 'revenue', 'budget']]
# 筛选2010-2016年的电影
filtered_df = filtered_df[(filtered_df['year'] >= 2010) & (filtered_df['year'] <= 2016)]
def split_data(df, split_column):
# 拆分指定的列
df = df.explode(split_column)
# 过滤掉指定列值为nan的数据
df = df[~df[split_column].isna()]
# 提取出指定列的名称
df.loc[:, split_column] = df[split_column].apply(lambda x: x['name'])
return df
# 拆分production_companies
filtered_df = split_data(filtered_df, 'production_companies')
filtered_df.rename(columns={'production_companies':'company'}, inplace=True)
filtered_df = filtered_df[(filtered_df['company'] == 'Universal Pictures') | (filtered_df['company'] == 'Paramount Pictures') ]
# 处理budget、revenue
filtered_df.reset_index(inplace=True)
total = filtered_df['genres'].str.len()
total = total.apply(lambda x: 1 if x == 0 else x)
filtered_df['budget'] = filtered_df['budget'] / total
filtered_df['revenue'] = filtered_df['revenue'] / total
# 拆分genres
filtered_df = split_data(filtered_df, 'genres')
filtered_df.rename(columns={'genres':'genre'}, inplace=True)
# 添加利润列
filtered_df['profit'] = filtered_df['revenue'] - filtered_df['budget']
# 过滤利润小于0的
filtered_df = filtered_df[0 <= filtered_df['profit']]
# 根据公司和类型对数据进行分组,并计算每个组的数量
grouped_df = filtered_df.groupby(['company', 'genre'])['profit'].mean().reset_index(name='average_profit')
# print(grouped_df)
# 使用pivot_table函数处理数据
processed_df = pd.pivot_table(grouped_df, values='average_profit', index='genre', columns='company', fill_value=0)
processed_df = processed_df.sort_values(by='genre', ascending=False)
# print(processed_df)
# 提取Universal Pictures和Paramount Pictures的数据
genres = list(processed_df.index)
universal = list(round(processed_df['Universal Pictures'],2))
paramount = list(round(processed_df['Paramount Pictures'],2))
# 绘制平均利润图
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.size'] = '13'
plt.figure(figsize=(12, 8))
plt.plot(genres, universal, alpha=0.5, label='Universal Pictures', color='#fa51cf')
plt.bar(genres, paramount, alpha=0.5, label='Paramount Pictures', color='#acaaf1')
plt.title('2010-2016年期间Universal Pictures和Paramount Pictures制作各类型电影的平均利润')
plt.xlabel('类型')
plt.ylabel('平均利润')
plt.legend()
plt.xticks(rotation=45)
plt.show()运行结果:
六)比较2012-2016年期间Universal和Paramount每年制作各类型电影的数量
from pyecharts import options as opts
from pyecharts.charts import Bar, Timeline
# 提取待处理字段
filtered_df = filtered_df[['year', 'production_companies', 'genres']]
# 筛选2012-2016年的电影
filtered_df = filtered_df[(filtered_df['year'] >= 2012) & (filtered_df['year'] <= 2016)]
def split_data(df, split_column):
# 拆分指定的列
df = df.explode(split_column)
# 过滤掉指定列值为nan的数据
df = df[~df[split_column].isna()]
# 提取出指定列的名称
df.loc[:, split_column] = df[split_column].apply(lambda x: x['name'])
return df
# 拆分production_companies
filtered_df = split_data(filtered_df, 'production_companies')
filtered_df.rename(columns={'production_companies':'company'}, inplace=True)
filtered_df = filtered_df[(filtered_df['company'] == 'Universal Pictures') | (filtered_df['company'] == 'Paramount Pictures') ]
# 拆分genres
filtered_df = split_data(filtered_df, 'genres')
filtered_df.rename(columns={'genres':'genre'}, inplace=True)
# 根据公司和类型对数据进行分组,并计算每个组的数量
grouped_df = filtered_df.groupby(['year', 'company', 'genre']).size().reset_index(name='count')
# print(grouped_df)
# 获取所有年份、公司和类型的组合
all_years = grouped_df['release_year'].unique()
all_companies = grouped_df['company'].unique()
# 创建空的DataFrame用于存储合并后的数据
merged_df = pd.DataFrame(columns=['release_year', 'company', 'genre', 'count'])
# 遍历所有年份、公司和类型的组合
for year in all_years:
all_genres = grouped_df[grouped_df['release_year'] == year]['genre'].unique()
all_genres.sort()
for company in all_companies:
for genre in all_genres:
# 检查是否存在对应的记录
condition = (grouped_df['release_year'] == year) & (grouped_df['company'] == company) & (
grouped_df['genre'] == genre)
if len(grouped_df[condition]) > 0:
count = grouped_df[condition]['count'].values[0]
else:
count = 0
# 添加记录到合并后的DataFrame
merged_df = pd.concat([merged_df, pd.DataFrame(
{'release_year': [year], 'company': [company], 'genre': [genre], 'count': [count]})],
ignore_index=True)
# print(merged_df)
# 创建时间轮番图
timeline = Timeline(
init_opts=opts.InitOpts(
width='1200px',
height='600px',
animation_opts=opts.AnimationOpts(
animation_delay=1000, # 动画延时
animation_easing='elasticOut'
)
)
)
# 遍历每个年份
for year in all_years:
# 提取当前年份的数据
universal_data = merged_df[(merged_df['release_year'] == year) & (merged_df['company'] == 'Universal Pictures')]
paramount_data = merged_df[(merged_df['release_year'] == year) & (merged_df['company'] == 'Paramount Pictures')]
# 创建柱状图
bar = (
Bar(init_opts=opts.InitOpts(height='500px'))
.add_xaxis(universal_data['genre'].tolist())
.add_yaxis('Universal Pictures',
universal_data['count'].tolist(),
gap=0,
itemstyle_opts=opts.ItemStyleOpts(
color='#FF4D4F')
)
.add_yaxis('Paramount Pictures',
paramount_data['count'].tolist(),
gap=0,
itemstyle_opts=opts.ItemStyleOpts(
color='#1890FF')
)
.set_global_opts(
title_opts=opts.TitleOpts(
title=f'{int(year)}年 Universal和Paramount制作各类型电影的数量',
pos_left='center',
),
xaxis_opts=opts.AxisOpts(
axislabel_opts=opts.LabelOpts(
rotate=30,
font_size=12,
)
),
yaxis_opts=opts.AxisOpts(
name='数量',
max_=max(universal_data['count'].max(), paramount_data['count'].max())+1,
axislabel_opts=opts.LabelOpts(
font_size=12
)
),
# visualmap_opts=opts.VisualMapOpts(
# min_=0,
# max_=8,
# is_show=False
# ),
# datazoom_opts=[
# opts.DataZoomOpts(
# range_start = 0,
# range_end = 100
# )
# ],
legend_opts=opts.LegendOpts(
pos_right='10%',
pos_top='12%',
orient='vertical'
),
tooltip_opts=opts.TooltipOpts(
trigger='item',
axis_pointer_type='cross'
)
)
)
# 将柱状图添加到时间轮番图中
timeline.add(bar, f'{int(year)}年')
# 调整时间轴位置
timeline.add_schema(
orient="vertical", # 垂直展示
is_auto_play=True,
play_interval=2000, # 播放时间间隔,毫秒
pos_right="2%",
pos_top="50",
height="500", # 组件高度
width="70",
label_opts=opts.LabelOpts(
is_show=True,
color="black",
position='left'
),
)
# 渲染并保存时间轮番图
timeline.render('时间轮番图.html')运行结果:(时间轮番图)
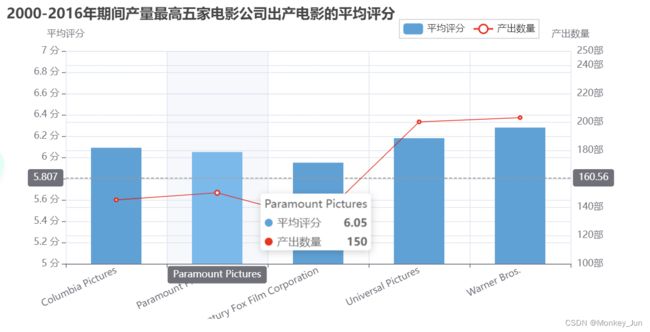
七)2000-2016年期间产量最高五家电影公司出产电影的平均评分
from pyecharts import options as opts
from pyecharts.charts import Line, Bar
from pyecharts.globals import ThemeType
from pyecharts.render import make_snapshot
from snapshot_selenium import snapshot
# 提取待处理字段
filtered_df = filtered_df[['year', 'production_companies', 'vote_average']]
# 2000-2016年期间产量最高五家电影公司出产电影的平均评分
filtered_df = filtered_df[(2000 <= filtered_df['year']) & (filtered_df['year'] <= 2016)]
def split_data(df, split_column):
# 拆分指定的列
df = df.explode(split_column)
# 过滤掉指定列值为nan的数据
df = df[~df[split_column].isna()]
# 提取出指定列的名称
df.loc[:, split_column] = df[split_column].apply(lambda x: x['name'])
return df
# 拆分production_companies
filtered_df = split_data(filtered_df, 'production_companies')
filtered_df.rename(columns={'production_companies':'company'}, inplace=True)
grouped_df = filtered_df.groupby('company').agg(
count=('company', 'size'),
vote_average=('vote_average', 'mean')).reset_index()
grouped_df = grouped_df.sort_values(by='count', ascending=False)
grouped_df = grouped_df.head(5)
grouped_df = grouped_df.sort_values(by='company')
print(grouped_df)
x_index = grouped_df['company'].tolist()
y_value1 = round(grouped_df['vote_average'],2).tolist()
y_value2 = grouped_df['count'].tolist()
bar = (
Bar(
init_opts=opts.InitOpts(
width="800px",
height="400px",
theme=ThemeType.LIGHT
)
)
.add_xaxis(xaxis_data=x_index)
.add_yaxis(
series_name="平均评分",
y_axis=y_value1,
category_gap="50%",
label_opts=opts.LabelOpts(is_show=False)
)
.extend_axis( # 第二坐标轴
yaxis=opts.AxisOpts(
name="产出数量",
type_="value",
min_=100,
max_=250,
interval=20,
axislabel_opts=opts.LabelOpts(formatter="{value}部") # 设置坐标轴格式
)
)
.set_global_opts(
title_opts=opts.TitleOpts(
title="2000-2016年期间产量最高五家电影公司出产电影的平均评分",
),
tooltip_opts=opts.TooltipOpts(
is_show=True, trigger="axis", axis_pointer_type="cross"
),
legend_opts=opts.LegendOpts(
pos_right='15%',
pos_top='5%',
),
xaxis_opts=opts.AxisOpts(
type_="category",
axispointer_opts=opts.AxisPointerOpts(is_show=True, type_="shadow"),
axislabel_opts=opts.LabelOpts(rotate=25)
),
yaxis_opts=opts.AxisOpts(
name="平均评分",
type_="value",
min_=5,
max_=7,
interval=0.2,
axislabel_opts=opts.LabelOpts(formatter="{value} 分"), # 设置坐标轴格式
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
)
)
line = (
Line()
.add_xaxis(xaxis_data=x_index)
.add_yaxis(
series_name="产出数量",
yaxis_index=1,
y_axis=y_value2,
itemstyle_opts=opts.ItemStyleOpts(color="red"),
label_opts=opts.LabelOpts(is_show=False),
z=2 # 使折线图显示在柱状图上面
)
)
title = '2000-2016年期间产量最高五家电影公司出产电影的平均评分'
make_snapshot(snapshot, bar.overlap(line).render(title+'.html'), title+'.png')
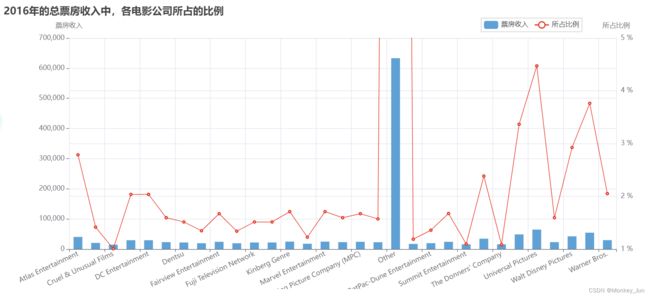
八)2016年的总票房收入中,各电影公司所占的比例
from pyecharts import options as opts
from pyecharts.charts import Line, Bar
from pyecharts.globals import ThemeType
from pyecharts.render import make_snapshot
from snapshot_selenium import snapshot
# 提取待处理字段
filtered_df = filtered_df[['year', 'production_companies', 'revenue']]
# 2016年的总票房收入中,各电影公司所占的比例
filtered_df = filtered_df[(filtered_df['year'] == 2016)]
# 处理收入列
total = filtered_df['production_companies'].str.len()
total = total.apply(lambda x: 1 if x == 0 else x)
# print(total)
filtered_df['revenue'] = filtered_df['revenue'] / total
def split_data(df, split_column):
# 拆分指定的列
df = df.explode(split_column)
# 过滤掉指定列值为nan的数据
df = df[~df[split_column].isna()]
# 提取出指定列的名称
df.loc[:, split_column] = df[split_column].apply(lambda x: x['name'])
return df
# 拆分production_companies
filtered_df = split_data(filtered_df, 'production_companies')
filtered_df.rename(columns={'production_companies': 'company'}, inplace=True)
# print(filtered_df.head(10).to_string())
# 按公司分组
grouped_df = filtered_df.groupby( 'company')['revenue'].sum().reset_index(name='revenue')
# 计算总票房收入
total_revenue = grouped_df['revenue'].sum()
# 添加比例列
grouped_df['scale'] = (grouped_df['revenue'] / total_revenue) * 100
grouped_df['revenue'] = round(grouped_df['revenue']/10000,2)
# 将scale小于2的行的company设置为"Other"
grouped_df.loc[grouped_df['scale'] < 1, 'company'] = "Other"
# 计算"Other"行的"revenue"和"scale"的总和
other_revenue_sum = grouped_df.loc[grouped_df['company'] == "Other", 'revenue'].sum()
other_scale_sum = grouped_df.loc[grouped_df['company'] == "Other", 'scale'].sum()
grouped_df.loc[grouped_df['company'] == "Other", ['revenue', 'scale']] = [other_revenue_sum, other_scale_sum]
# 删除重复行
grouped_df = grouped_df.drop_duplicates()
# 按比例排序
grouped_df = grouped_df.sort_values(by='company')
# print(grouped_df.head(20).to_string())
# 提取绘图数据集合
x_index = grouped_df['company'].tolist()
y_value1 = grouped_df['revenue'].tolist()
y_value2 = grouped_df['scale'].tolist()
bar = (
Bar(
init_opts=opts.InitOpts(
width="1200px",
height="500px",
theme=ThemeType.LIGHT
)
)
.add_xaxis(xaxis_data=x_index)
.add_yaxis(
series_name="票房收入",
y_axis=y_value1,
category_gap="50%",
label_opts=opts.LabelOpts(is_show=False)
)
.extend_axis( # 第二坐标轴
yaxis=opts.AxisOpts(
name="所占比例",
type_="value",
min_=1,
max_=5,
# interval=200,
axislabel_opts=opts.LabelOpts(formatter="{value} %") # 设置坐标轴格式
)
)
.set_global_opts(
title_opts=opts.TitleOpts(
title="2016年的总票房收入中,各电影公司所占的比例",
),
tooltip_opts=opts.TooltipOpts(
is_show=True, trigger="axis", axis_pointer_type="cross"
),
legend_opts=opts.LegendOpts(
pos_right='15%',
pos_top='5%',
),
xaxis_opts=opts.AxisOpts(
type_="category",
axispointer_opts=opts.AxisPointerOpts(is_show=True, type_="shadow"),
axislabel_opts=opts.LabelOpts(rotate=25)
),
yaxis_opts=opts.AxisOpts(
name="票房收入",
type_="value",
# min_=5,
# max_=7,
# interval=0.2,
# axislabel_opts=opts.LabelOpts(formatter="{value} $"), # 设置坐标轴格式
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
)
)
line = (
Line()
.add_xaxis(xaxis_data=x_index)
.add_yaxis(
series_name="所占比例",
yaxis_index=1,
y_axis=y_value2,
itemstyle_opts=opts.ItemStyleOpts(color="red"),
label_opts=opts.LabelOpts(is_show=False),
z=2 # 使折线图显示在柱状图上面
)
)
title = '2016年的总票房收入中,各电影公司所占的比例'
make_snapshot(snapshot, bar.overlap(line).render(title+'.html'), title+'.png')运行结果:
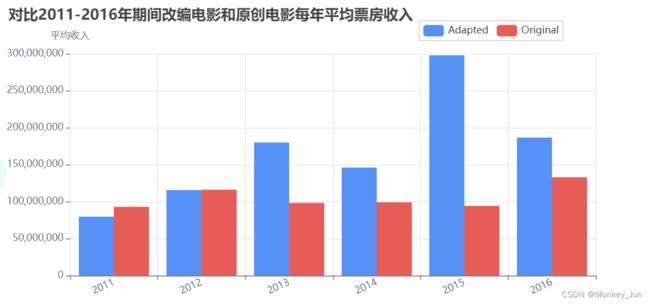
九)对比2011-2016年期间改编电影和原创电影每年平均票房收入
import json
from pyecharts import options as opts
from pyecharts.charts import Line, Bar
from pyecharts.globals import ThemeType
from pyecharts.render import make_snapshot
from snapshot_selenium import snapshot
# 提取待处理字段
filtered_df = filtered_df[['year', 'keywords', 'revenue']]
# 对比2011-2016年期间改编电影和原创电影每年平均票房收入,电影的其中一个keywords为“based on novel”,则它为改编电影,否则为原创电影
filtered_df = filtered_df[(2011 <= filtered_df['year']) & (filtered_df['year'] <= 2016)]
# 定义函数来判断电影是否为改编电影
def is_adapted_movie(keywords_json):
try:
keywords = json.loads(keywords_json.replace("'", '"'))
return any(keyword['name'] == 'based on novel' for keyword in keywords)
except json.JSONDecodeError:
return False
# 为数据集添加一列以标记改编电影
filtered_df['is_adapted'] = filtered_df['keywords'].apply(is_adapted_movie)
# print(filtered_df['is_adapted'])
# print(filtered_df.groupby(['year', 'is_adapted'])['revenue'].mean().head(10).to_string())
grouped_df = filtered_df.groupby(['year', 'is_adapted'])['revenue'].mean().unstack()
print(grouped_df.head(10).to_string())
# 准备数据用于绘图
x_index = grouped_df.index.tolist()
y_value1 = grouped_df[True].tolist()
y_value2 = grouped_df[False].tolist()
bar = (
Bar(
init_opts=opts.InitOpts(
width="800px",
height="400px",
theme=ThemeType.LIGHT
)
)
.add_xaxis(xaxis_data=x_index)
.add_yaxis(
'Adapted',
y_axis=y_value1,
gap=0,
label_opts=opts.LabelOpts(is_show=False),
itemstyle_opts=opts.ItemStyleOpts(
color='#1890FF')
)
.add_yaxis(
'Original',
y_axis=y_value2,
gap=0,
label_opts=opts.LabelOpts(is_show=False),
itemstyle_opts=opts.ItemStyleOpts(
color='#FF4D4F')
)
.set_global_opts(
title_opts=opts.TitleOpts(
title="对比2011-2016年期间改编电影和原创电影每年平均票房收入",
),
tooltip_opts=opts.TooltipOpts(
is_show=True, trigger="axis", axis_pointer_type="cross"
),
legend_opts=opts.LegendOpts(
pos_right='15%',
pos_top='5%',
),
xaxis_opts=opts.AxisOpts(
type_="category",
axispointer_opts=opts.AxisPointerOpts(is_show=True, type_="shadow"),
axislabel_opts=opts.LabelOpts(rotate=25)
),
yaxis_opts=opts.AxisOpts(
name="平均收入",
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
)
)
title = '对比2011-2016年期间改编电影和原创电影每年平均票房收入'
make_snapshot(snapshot, bar.render(title + '.html'), title + '.png')运行结果: