k8s集群配置NodeLocal DNSCache
一、简介
当集群规模较大时,运行的服务非常多,服务之间的频繁进行大量域名解析,CoreDNS将会承受更大的压力,可能会导致如下影响:
延迟增加:有限的coredns服务在解析大量的域名时,会导致解析结果返回慢。
业务访问异常:集群内的服务基本都是通过域名进行访问,coredns在解析压力大时会存在慢或者丢包的情况,导致服务之间解析异常。
二、原理架构
NodeLocal DNSCache 通过在集群节点上作为 DaemonSet 运行 DNS 缓存代理来提高集群 DNS 性能。 在当今的体系结构中,运行在 ‘ClusterFirst’ DNS 模式下的 Pod 可以连接到 kube-dns serviceIP 进行 DNS 查询。 通过 kube-proxy 添加的 iptables 规则将其转换为 kube-dns/CoreDNS 端点。 而借助新架构,Pod 将可以访问在同一节点上运行的 DNS 缓存代理,从而避免 iptables DNAT 规则和连接跟踪。 本地缓存代理将查询 kube-dns 服务以获取集群主机名的缓存缺失(默认为 “cluster.local” 后缀)
启用 NodeLocal DNSCache 之后,DNS 查询所遵循的路径如下,流程图取自官网:

三、与coredns对比
1、 使用当前的 DNS 体系结构,如果没有本地 kube-dns/CoreDNS 实例,则具有最高
DNS QPS 的 Pod 可能必须延伸到另一个节点。 在这种场景下,拥有本地缓存将有助于改善延迟。
2、 跳过 iptables DNAT 和连接跟踪将有助于减少 conntrack 竞争并避免 UDP DNS 条目填满 conntrack 表。
3、 从本地缓存代理到 kube-dns 服务的连接可以升级为 TCP。 TCP conntrack 条目将在连接关闭时被删除,相反 UDP 条目必须超时 (默认 nf_conntrack_udp_timeout 是 30 秒)。
4、 将 DNS 查询从 UDP 升级到 TCP 将减少由于被丢弃的 UDP 包和 DNS 超时而带来的尾部等待时间; 这类延时通常长达 30 秒(3 次重试 + 10 秒超时)。 由于 nodelocal 缓存监听 UDP DNS 查询,应用不需要变更。
5、 在节点级别对 DNS 请求的度量和可见性。
6、 可以重新启用负缓存,从而减少对 kube-dns 服务的查询数量。
四、NodeLocal DNSCache部署
1)修改kubelet.config文件,添加NodeLocal DNS的本地侦听IP。本文使用的地址为:169.254.20.10。
kind: KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
address: 0.0.0.0
port: 10250
cgroupDriver: systemd
clusterDNS: [“169.254.20.10”,“169.169.0.100”]
clusterDomain: cluster.local
failSwapOn: false
allow-privileged: true
tlsCipherSuites: [“TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256”,“TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256”,“TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305”,“TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384”,“TLS_ECDHE_R
SA_WITH_CHACHA20_POLY1305”,“TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384”,“TLS_RSA_WITH_AES_256_GCM_SHA384”,“TLS_RSA_WITH_AES_128_GCM_SHA256”]authentication:
anonymous:
enabled: false
x509:
clientCAFile: /etc/kubernetes/ssl/ca.crt
2)部署NodeLocal DNS的yaml如下:
apiVersion: v1
kind: ServiceAccount
metadata:
name: node-local-dns
namespace: kube-system
labels:
kubernetes.io/cluster-service: “true”
addonmanager.kubernetes.io/mode: Reconcile
—
apiVersion: v1
kind: Service
metadata:
name: kube-dns-upstream
namespace: kube-system
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: “true”
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: “KubeDNSUpstream”
spec:
ports:– name: dns
port: 53
protocol: UDP
targetPort: 53
- name: dns-tcp
port: 53
protocol: TCP
targetPort: 53
selector:
k8s-app: kube-dns
–
apiVersion: v1
kind: ConfigMap
metadata:
name: node-local-dns
namespace: kube-system
labels:
addonmanager.kubernetes.io/mode: Reconcile
data:
Corefile: |
cluster.local:53 {
errors
cache {
success 9984 30
denial 9984 5
}
reload
loop
bind 169.254.20.10 #NodeLocal DNS的本地侦听IP。
forward . 169.169.0.100 { #转发到coredns地址
force_tcp #转发协议
}
prometheus :9253
health 169.254.20.10:8080
}
in-addr.arpa:53 {
errors
cache 30
reload
loop
bind 169.254.20.10
forward . 169.169.0.100 {
force_tcp
}
prometheus :9253
}
ip6.arpa:53 {
errors
cache 30
reload
loop
bind 169.254.20.10
forward . PILLAR__CLUSTER__DNS {
force_tcp
}
prometheus :9253
}
.:53 {
errors
cache 30
reload
loop
bind 169.254.20.10
forward . 169.169.0.100
prometheus :9253
}
–
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-local-dns
namespace: kube-system
labels:
k8s-app: node-local-dns
kubernetes.io/cluster-service: “true”
addonmanager.kubernetes.io/mode: Reconcile
spec:
updateStrategy:
rollingUpdate:
maxUnavailable: 10%
selector:
matchLabels:
k8s-app: node-local-dns
template:
metadata:
labels:
k8s-app: node-local-dns
annotations:
prometheus.io/port: “9253”
prometheus.io/scrape: “true”
spec:
priorityClassName: system-node-critical
serviceAccountName: node-local-dns
hostNetwork: true
dnsPolicy: Default # Don’t use cluster DNS.
tolerations:
- key: “CriticalAddonsOnly”
operator: “Exists”
- effect: “NoExecute”
operator: “Exists”
- effect: “NoSchedule”
operator: “Exists”
containers:
- name: node-cache
image: 127.0.0.1:1120/panji_microservice/k8s-dns-node-cache:1.22.9
resources:
limits: #根据自己环境设置合适的资源限制
cpu: 50m
memory: 50Mi
requests:
cpu: 25m
memory: 5Mi
args: [ “-localip”, “169.254.20.10”, “-conf”, “/etc/Corefile”, “-upstreamsvc”, “kube-dns-upstream” ]
securityContext:
capabilities:
add:
- NET_ADMIN
ports:
- containerPort: 53
name: dns
protocol: UDP
- containerPort: 53
name: dns-tcp
protocol: TCP
- containerPort: 9253
name: metrics
protocol: TCP
livenessProbe:
httpGet:
host: 169.254.20.10
path: /health
port: 8080
initialDelaySeconds: 60
timeoutSeconds: 5
volumeMounts:
- mountPath: /run/xtables.lock
name: xtables-lock
readOnly: false
- name: config-volume
mountPath: /etc/coredns
- name: kube-dns-config
mountPath: /etc/kube-dns
volumes:
- name: xtables-lock
hostPath:
path: /run/xtables.lock
type: FileOrCreate
- name: kube-dns-config
configMap:
name: kube-dns
optional: true
- name: config-volume
configMap:
name: node-local-dns
items:
- key: Corefile
path: Corefile.base
–
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/port: “9253”
prometheus.io/scrape: “true”
labels:
k8s-app: node-local-dns
name: node-local-dns
namespace: kube-system
spec:
clusterIP: None
ports:
- name: metrics
port: 9253
targetPort: 9253
selector:
k8s-app: node-local-dns
**注:**1、以上配置文件中 169.169.0.100 为k8s集群中得coredns的svc地址。
169.254.20.10为本地NodeLocal dns 监听服务地址。
2、NodeLocal dns会使用主机网络监听8080端口到宿主机,防止和业务服务端口冲突。
3)NodeLocal DNS在kube-proxy不同模式下的配置
一、kube-proxy 运行在 IPTABLES 模式:
可以在kubelet的kubelet.config配置文件中添加NodeLocal dns的本地地址即可。
二、 kube-proxy 运行在 IPVS 模式:
node-local-dns Pod 会设置 PILLAR__UPSTREAM__SERVERS。
在此模式下,node-local-dns Pod 只会侦听 的地址。 node-local-dns 接口不能绑定 kube-dns 的集群 IP 地址,因为 IPVS 负载均衡使用的接口已经占用了该地址。
如果 kube-proxy 运行在 IPVS 模式,需要修改 kubelet 的 --cluster-dns 参数
NodeLocal DNSCache 正在侦听的 地址。
五、部署结果
部署node-local-dns服务。

服务访问域名解析结果如下,可以看到已经解析到本地dns:

六、压力测试
使用queryperf对NodeLocal dns 和DNS分别进行压测。
测试结果如下图,仅供参考:
| qps | 1000 | 2000 | 10000 | 50000 | 100000 |
|---|---|---|---|---|---|
| localdns | 0.0379s | 0.0030s | 0.0227s | 0.0001s | 0.0021s |
| coredns | 0.0104s | 0.0046s | 0.0026s | 0.0177s | 0.0061s |
以看到,在解析压力较大时,Node localDNS的 解析性能优于coreDNS。
使用Node localDNS压测结果截图如下:
1000qps压测截图:

2000qps压测截图:

10000qps压测截图:
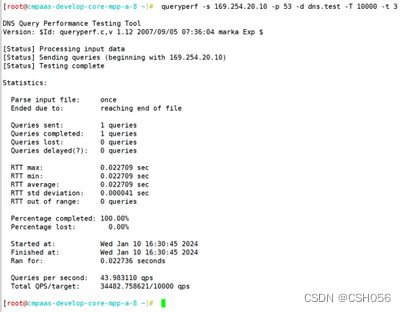
50000qps压测截图:

100000qps压测截图:
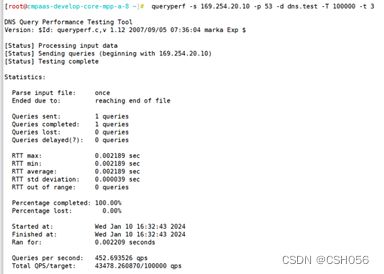
对coredns解析压测结果截图如下:
1000qps压测截图:

2000qps压测截图如下:

10000qps压测截图:

50000qps压测截图:

100000qps压测截图:
