JavaScript数据结构-散列表(哈希表)
目录
- 散列表是什么
- 散列的一些术语(可以简单的看一下)
- 常用的散列函数
- 构建散列表
- 散列表的组成
- 初始化
- 散列函数
- 添加
- 删除
- 查找
- 总结
- 补充一个小知识点
散列表是什么
散列表(Hash table,也叫哈希表),是根据键(Key)而直接访问在内存存储位置的数据结构。也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表。
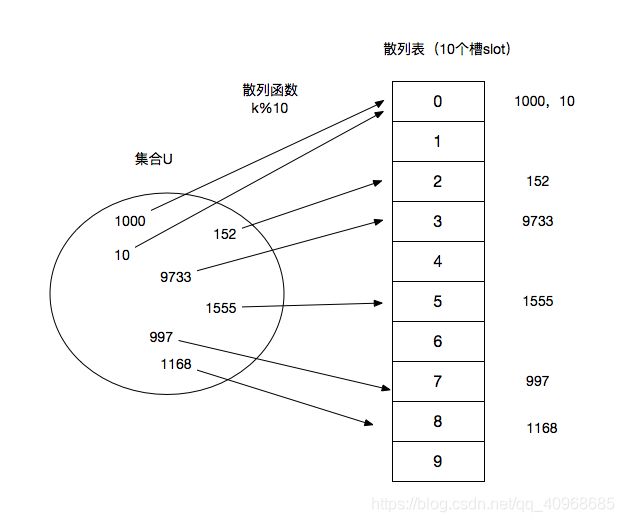
我们从上图开始分析
-
有一个集合U,里面分别是1000,10,152,9733,1555,997,1168
-
右侧是一个10个插槽的列表(散列表),我们需要把集合U中的整数存放到这个列表中
-
怎么存放,分别存在哪个槽里?这个问题就是需要通过一个散列函数来解决了。我的存放方式是取10的余数,我们对应这图来看
- 1000%10=0,10%10=0 那么1000和10这两个整数就会被存储到编号为0的这个槽中
- 152%10=2那么就存放到2的槽中
- 9733%10=3 存放在编号为3的槽中
通过上面简单的例子,应该会有一下几点一个大致的理解
- 集合U,就是可能会出现在散列表中的键
- 散列函数,就是你自己设计的一种如何将集合U中的键值通过某种计算存放到散列表中,如例子中的取余数
- 散列表,存放着通过计算后的键
那么我们在接着看一般我们会怎么去取值呢?
比如我们存储一个key为1000,value为’张三’ —> {key:1000,value:‘张三’}
从我们上述的解释,它是不是应该存放在1000%10的这个插槽里。
当我们通过key想要找到value张三,是不是到key%10这个插槽里找就可以了呢?到了这里你可以停下来思考一下。
散列的一些术语(可以简单的看一下)
1.散列表中所有可能出现的键称作全集U
2.用M表示槽的数量
3.给定一个键,由散列函数计算它应该出现在哪个槽中,上面例子的散列函数h=k%M,散列函数h就是键k到槽的一个映射。
4.1000和10都被存到了编号0的这个槽中,这种情况称之为碰撞。
看到这里不知道你是否大致理解了散列函数是什么了没。
通过例子,再通过你的思考,你可以回头在读一遍文章头部关于散列表的定义。如果你能读懂了,那么我估计你应该是懂了。
常用的散列函数
1.处理整数 h=>k%M (也就是我们上面所举的例子)
2.处理字符串:
function h_str(str,M){
return [...str].reduce((hash,c)=>{
hash = (31*hash + c.charCodeAt(0)) % M
},0)
}
hash算法不是这里的重点,我也没有很深入的去研究,这里主要还是去理解散列表是个怎样的数据结构,它有哪些优点,它具体做了怎样一件事。
而hash函数它只是通过某种算法把key映射到列表中。
构建散列表
通过上面的解释,我们这里做一个简单的散列表
散列表的组成
1.M个槽
2.有个hash函数
3.有一个add方法去把键值添加到散列表中
4.有一个delete方法去做删除
5.有一个search方法,根据key去找到对应的值
初始化
1.初始化散列表有多少个槽
2.用一个数组来创建M个槽
class HashTable {
constructor(num=1000){
this.M = num;
this.slots = new Array(num);
}
}
散列函数
处理字符串的散列函数,这里使用字符串是因为,数值也可以传换成字符串比较通用一些
1.先将传递过来的key值转为字符串,为了能够严谨一些
2.将字符串转换为数组, 例如’abc’ => […‘abc’] => [‘a’,‘b’,‘c’]
3.分别对每个字符的charCodeAt进行计算,取M余数是为了刚好对应插槽的数量,你总共就10个槽,你的数值%10 肯定会落到 0-9的槽里
h(str){
str = str + '';
return [...str].reduce((hash,c)=>{
hash = (331 * hash + c.charCodeAt()) % this.M;
return hash;
},0)
}
添加
1.调用hash函数得到对应的存储地址(就是我们之间类比的槽)
2.因为一个槽中可能会存多个值,所以需要用一个二维数组去表示,比如我们计算得来的槽的编号是0,也就是slot[0],那么我们应该往slot[0] [0]里存,后面进来的同样是编号为0的槽的话就接着往slot[0] [1]里存
add(key,value) {
const h = this.h(key);
// 判断这个槽是否是一个二维数组, 不是则创建二维数组
if(!this.slots[h]){
this.slots[h] = [];
}
// 将值添加到对应的槽中
this.slots[h].push(value);
}
删除
1.通过hash算法,找到所在的槽
2.通过过滤来删除
delete(key){
const h = this.h(key);
this.slots[h] = this.slots[h].filter(item=>item.key!==key);
}
查找
1.通过hash算法找到对应的槽
2.用find函数去找同一个key的值
3.返回对应的值
search(key){
const h = this.h(key);
const list = this.slots[h];
const data = list.find(x=> x.key === key);
return data ? data.value : null;
}
总结
讲到这里,散列表的数据结构已经讲完了,其实我们每学一种数据结构或算法的时候,不是去照搬实现的代码,我们要学到的是思想,比如说散列表它究竟做了什么,它是一种存储方式,可以快速的通过键去查找到对应的值。那么我们会思考,如果我们设计的槽少了,在同一个槽里存放了大量的数据,那么这个散列表它的搜索速度肯定是会大打折扣的,这种情况又应该用什么方式去解决,又或者是否用其他的数据结构的代替它。
补充一个小知识点
v8引擎中的数组 arr = [1,2,3,4,5] 或 new Array(100) 我们都知道它是开辟了一块连续的空间去存储,而arr = [] , arr[100000] = 10 这样的操作它是使用的散列,因为这种操作如果连续开辟100万个空间去存储一个值,那么显然是在浪费空间。
参考链接:
链接