分布式定时任务(二) Elastic Job 开发使用篇(结合Spring Boot开发分布式任务调度)
文章目录
- 分布式定时任务(二) Elastic Job 开发使用篇(结合Spring Boot开发分布式任务调度)
-
- 0. 前言
- 1. 作业开发
-
- 1.1. Simple 类型作业
- 1.2. Dataflow 类型作业
-
- 任务实体类
- 新建任务类 DataFlowTask
- 模拟数据库类
- 任务配置类
- 执行结果
- 1.3. Script 类型作业
-
- 新建脚本
- 任务配置类
- 执行结果
- 2. 作业配置
-
- 2.1. JobCoreConfiguration
- 2.2. JobTypeConfiguration
- 2.3. JobRootConfiguration
- 3. 结语
分布式定时任务(二) Elastic Job 开发使用篇(结合Spring Boot开发分布式任务调度)
0. 前言
在上一篇中我们已经学会了部署ElasticJob,本文将以上一篇部署的项目为基础,讲解有关定时任务作业开发的代码实战。
⚠️ 以下所有案例在测试定时任务之前,请先启动ZK。
在进行开发之前,需要读者掌握 Ideal 同一项目启动多个实例的能力。具体操作方法如下:
- 首先点击启动类下拉框,选择 Edit Configurations…
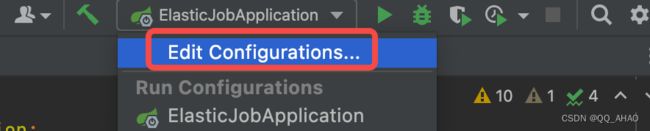
- 选择ElasticJobApplicaiton启动类,点击左上角的复制按钮
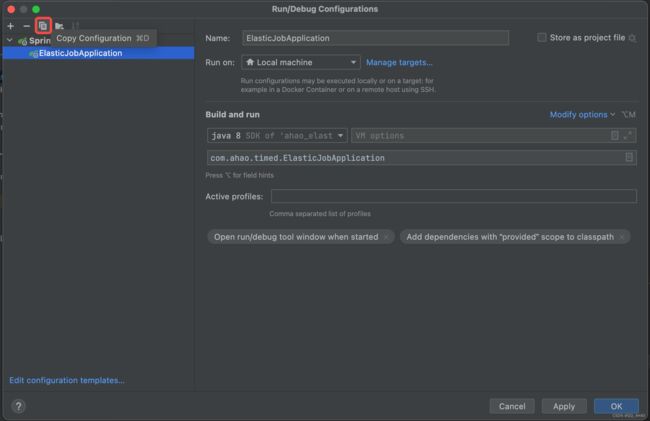
- 在新增的启动配置中,添加启动参数
-Dserver.port=9932(设置端口号为9932)
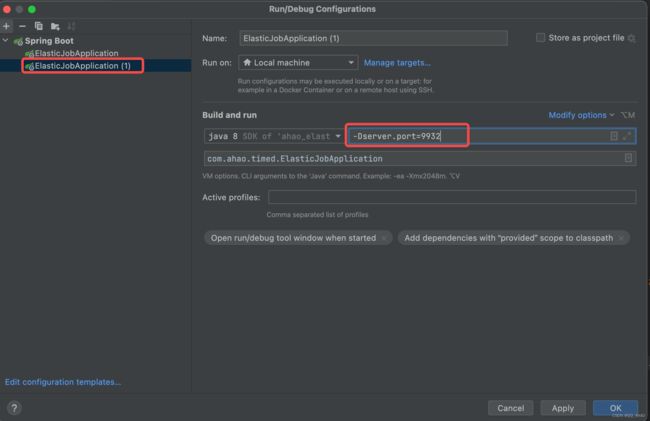
- 以相同的操作,新增启动配置ElasticJobApplicaiton (2),并设置端口号为 9933
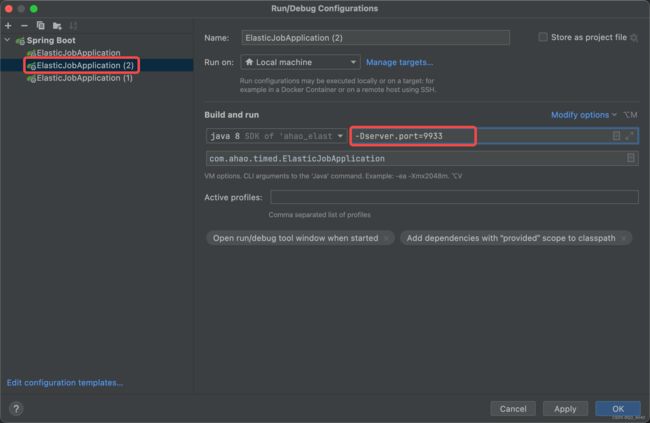
至此我们相当于新建了3个客户端,以便接下来测试分布式定时任务的执行状况。
1. 作业开发
Elastic-Job提供Simple、Dataflow和Script 3种作业类型。 方法参数shardingContext包含作业配置、片和运行时信息。可通过getShardingTotalCount(), getShardingItem()等方法分别获取分片总数,运行在本作业服务器的分片序列号等。
1.1. Simple 类型作业
意为简单实现,未经任何封装的类型。需实现SimpleJob接口。该接口仅提供单一方法用于覆盖,被覆盖的方法将用于定时执行。
我们仍然以上一篇中的任务类为例。
/**
* @Name: SpringTask
* @Description: SimpleJob类型作业样例
* @Author: ahao
* @Date: 2023/12/15 11:31 AM
*/
@Log4j2
@Component
public class SpringTask implements SimpleJob {
@Override
public void execute(ShardingContext shardingContext) {
log.info("Spring整合ElasticJob。任务信息:{}", shardingContext.getShardingParameter());
}
}
先安装并启动ZK,具体步骤请看上一篇文章 分布式定时任务(一) Elastic Job 开发部署实战。
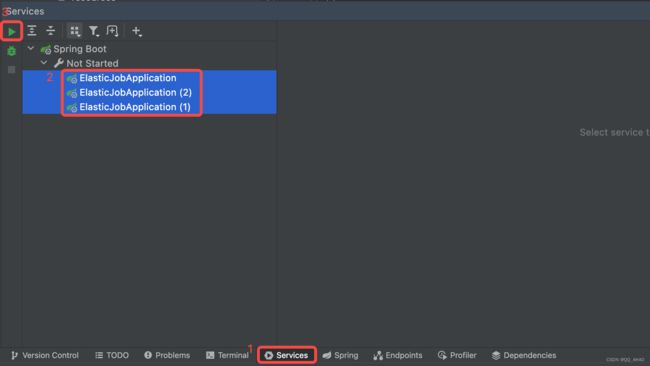
首先选择Services,勾选之前配置好的3个服务启动实例,然后点击启动。
观察结果可知,6个分片任务(Monday、Tuesday、Wednesday、Thursday、Friday、Saturday)都被均匀分配到了3个实例了:
- ElasticJobApplicaiton

- ElasticJobApplicaiton (2)

- ElasticJobApplicaiton (1)

假如我们现在停掉其中一个实例 ElasticJobApplicaiton (2)

再观察结果,在下一次定时任务执行时直接6个分片任务仍然均分到了剩下的实例中:
- ElasticJobApplicaiton

- ElasticJobApplicaiton (1)

1.2. Dataflow 类型作业
任务实体类
/**
* @Name: PersonDao
* @Description: 实体类
* @Author: ahao
* @Date: 2023/12/21 11:32 AM
*/
@Data
public class PersonDao {
private String id;
/**
* 工作日
* 枚举值:Monday,Tuesday,Wednesday,Thursday,Friday,Saturday
*/
private String workDate;
/**
* 工作是否排期
*/
private Boolean isScheduler;
}
新建任务类 DataFlowTask
继承DataflowJob 接口,重写fetchData和processData方法。
/**
* @Name: DataFlowTask
* @Description: 作业流任务
* @Author: ahao
* @Date: 2023/12/21 11:31 AM
*/
@Log4j2
@Component
public class DataFlowTask implements DataflowJob<PersonDao> {
/**
* 用于抓取定时任务中作业列表
* @param shardingContext 分片上下文
* @return
*/
@Override
public List<PersonDao> fetchData(ShardingContext shardingContext) {
String shardingParameter = shardingContext.getShardingParameter();
return MockDB.query(shardingParameter,50);
}
/**
* 处理fetchData方法中的抓取的作业,如果返回结果为null或者空列表,则定时任务执行完成
* @param shardingContext 分片上下文
* @param data 待处理数据集合(fetchData方法中的抓取的作业列表)
*/
@Override
public void processData(ShardingContext shardingContext, List<PersonDao> data) {
log.info("抓取的作业类型:{},数量为:{}",shardingContext.getShardingParameter(),data.size());
// 如果采用流式作业处理方式,建议processData处理数据后更新其状态,避免fetchData再次抓取到,从而使得作业永不停止
// 设置已排期(如果不设置这一步,会陷入任务执行死循环)
for (PersonDao datum : data) {
datum.setIsScheduler(true);
}
}
}
模拟数据库类
为了简单方便,创建了一个模拟数据库Class,通过调用query方法替代数据库查询操作。
/**
* @Name: MockDB
* @Description: 模拟数据库
* @Author: ahao
* @Date: 2023/12/21 11:37 AM
*/
public class MockDB {
private static List<PersonDao> list = new ArrayList<>();
/**
* 生成模拟数据
* 1000条数据,根据id%6的余数来决定工作排期
*/
static {
String dateStr = "Monday,Tuesday,Wednesday,Thursday,Friday,Saturday";
String[] dates = dateStr.split(",");
for (int i = 1000; i < 2000; i++) {
PersonDao personDao = new PersonDao();
personDao.setId(String.valueOf(i));
personDao.setIsScheduler(false);
personDao.setWorkDate(dates[i%6]);
list.add(personDao);
}
}
/**
* 查询 workDate 上班的人
* @param workDate 星期几
* @param n 数量
* @return
*/
public static List<PersonDao> query(String workDate,long n){
return list.stream().filter(e -> workDate.equals(e.getWorkDate()) && !e.getIsScheduler()).limit(n).collect(Collectors.toList());
}
}
任务配置类
此处任务类实例没有通过@Autowired注入,而是直接 new DataFlowTask()。
/**
* @Name: ElasticJobConfig
* @Description: ElasticJob配置类
* @Author: ahao
* @Date: 2023/12/15 1:51 PM
*/
@Log4j2
@Configuration
public class ElasticJobConfig {
@Autowired
private CoordinatorRegistryCenter registryCenter;
@Bean(initMethod = "init")
public SpringJobScheduler springFlowJobScheduler(){
LiteJobConfiguration jobConfiguration = createFlowJobConfiguration(DataFlowTask.class,
"1 * * * * ?",
6,
"0=Monday,1=Tuesday,2=Wednesday,3=Thursday,4=Friday,5=Saturday");
SpringJobScheduler jobScheduler = new SpringJobScheduler(new DataFlowTask(),registryCenter, jobConfiguration);
return jobScheduler;
}
private LiteJobConfiguration createFlowJobConfiguration(final Class<? extends DataflowJob>
jobClass,
final String cron,
final int shardingTotalCount,
final String shardingItemParameters) {
//创建JobCoreConfiguration
JobCoreConfiguration.Builder builder = JobCoreConfiguration.newBuilder(jobClass.getName(), cron, shardingTotalCount);
if(StringUtils.isNotEmpty(shardingItemParameters)){
builder.shardingItemParameters(shardingItemParameters);
}
// 开启失效转移
JobCoreConfiguration configuration=builder.failover(true).build();
//todo 注意此处:创建DataflowJobConfiguration,第三个构造器参数表示是否流式处理
DataflowJobConfiguration dataflowJobConfiguration = new DataflowJobConfiguration(configuration,jobClass.getCanonicalName(),true);
//启动任务
LiteJobConfiguration liteJobConfiguration = LiteJobConfiguration.newBuilder(dataflowJobConfiguration).overwrite(true).build();
return liteJobConfiguration;
}
}
执行结果
6个分片任务被均匀分给了3个服务实例,并且每个任务都不断拉取数据直至拉取的数据为空。(由于没有连接数据库,3个服务实例共享的不是同一份数据,而是从自身的内存获取的数据,所以每次重启实例,仍然会触发定时任务的执行)
- ElasticJobApplicaiton
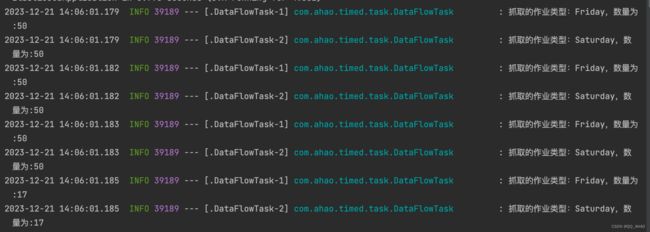
- ElasticJobApplicaiton (2)
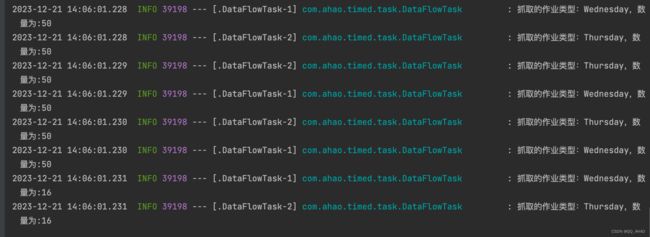
- ElasticJobApplicaiton (1)
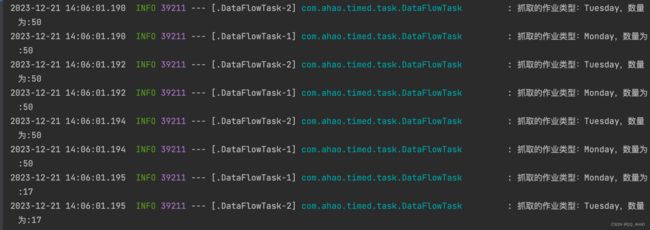
1.3. Script 类型作业
参考官方文档,创建一个脚本文件,用于定时任务执行。
新建脚本
如下图所示,在/Users/admin/Desktop目录下建立了 test.sh 脚本文件(Windows后缀用.bat),内容和官方文档的样例内容一样:echo sharding execution context is $*
任务配置类
以相同的方式装载任务类,只不过此时不需要构造任务类,只需要设置cron表达式。并且在创建配置时,指定脚本文件的路径地址。
(注意:此时的任务类型是JobScheduler)
@Bean(initMethod = "init")
public JobScheduler springFlowJobScheduler() {
LiteJobConfiguration jobConfiguration = createScriptJobConfiguration("1/20 * * * * ?");
JobScheduler jobScheduler = new JobScheduler(registryCenter,jobConfiguration);
return jobScheduler;
}
private LiteJobConfiguration createScriptJobConfiguration(final String cron) {
//创建JobCoreConfiguration
JobCoreConfiguration.Builder builder = JobCoreConfiguration.newBuilder("ScriptJob", cron, 1);
// 开启失效转移
JobCoreConfiguration configuration = builder.failover(true).build();
//todo 注意此处:创建scriptJobConfiguration,第二个构造器参数为 脚本文件路径地址
ScriptJobConfiguration scriptJobConfiguration = new ScriptJobConfiguration(configuration, "/Users/admin/Desktop/test.sh");
//启动任务
LiteJobConfiguration liteJobConfiguration = LiteJobConfiguration.newBuilder(scriptJobConfiguration).overwrite(true).build();
return liteJobConfiguration;
}
执行结果

2. 作业配置
Elastic-Job配置分为3个层级,分别是Core, Type和Root。
Core对应JobCoreConfiguration,用于提供作业核心配置信息,如:作业名称、分片总数、CRON表达式等。
Type对应JobTypeConfiguration,有3个子类分别对应SIMPLE, DATAFLOW和SCRIPT类型作业,提供3种作业需要的不同配置,如:DATAFLOW类型是否流式处理或SCRIPT类型的命令行等。
Root对应JobRootConfiguration,有2个子类分别对应Lite和Cloud部署类型,提供不同部署类型所需的配置,如:Lite类型的是否需要覆盖本地配置或Cloud占用CPU或Memory数量等。
2.1. JobCoreConfiguration
// 通过Bulider模式构造,构造器参数:String jobName,String cron,int shardingTotalCount
JobCoreConfiguration.Builder builder = JobCoreConfiguration.newBuilder("JobName", cron, 1);
// 其他属性
JobCoreConfiguration config = builder.failover(true).build();
属性详细说明如下:
| 属性名 | 类型 | 构造器参数 | 缺省值 | 描述 |
|---|---|---|---|---|
| jobName | String | 是 | 作业名称 | |
| cron | String | 是 | cron表达式,用于控制作业触发时间 | |
| shardingTotalCount | int | 是 | 作业分片总数 | |
| shardingItemParameters | String | 否 | 分片序列号和参数用等号分隔,多个键值对用逗号分隔 分片序列号从0开始,不可大于或等于作业分片总数 如: 0=a,1=b,2=c | |
| jobParameter | String | 否 | 作业自定义参数 作业自定义参数,可通过传递该参数为作业调度的业务方法传参,用于实现带参数的作业 例:每次获取的数据量、作业实例从数据库读取的主键等 | |
| failover | boolean | 否 | false | 是否开启任务执行失效转移,开启表示如果作业在一次任务执行中途宕机,允许将该次未完成的任务在另一作业节点上补偿执行 |
| misfire | boolean | 否 | true | 是否开启错过任务重新执行 |
| description | String | 否 | 作业描述信息 | |
| jobProperties | Enum | 否 | 配置jobProperties定义的枚举控制Elastic-Job的实现细节 JOB_EXCEPTION_HANDLER用于扩展异常处理类 EXECUTOR_SERVICE_HANDLER用于扩展作业处理线程池类 |
2.2. JobTypeConfiguration
SimpleJobConfiguration
// 通过构造器创建
SimpleJobConfiguration simpleJobConfig = new SimpleJobConfiguration(config,jobClass.getCanonicalName());
属性详细说明
| 属性名 | 类型 | 构造器注入 | 缺省值 | 描述 |
|---|---|---|---|---|
| coreConfig | JobCoreConfiguration | 是 | ||
| jobClass | String | 是 | 作业实现类,需实现ElasticJob接口 |
DataflowJobConfiguration
// 通过构造器创建
DataflowJobConfiguration dataflowJobConfig = new DataflowJobConfiguration(config,jobClass.getCanonicalName(),true);
属性详细说明
| 属性名 | 类型 | 构造器注入 | 缺省值 | 描述 |
|---|---|---|---|---|
| coreConfig | JobCoreConfiguration | 是 | ||
| jobClass | String | 是 | 作业实现类,需实现ElasticJob接口 | |
| streamingProcess | boolean | 否 | false | 是否流式处理数据 如果流式处理数据, 则fetchData不返回空结果将持续执行作业 如果非流式处理数据, 则处理数据完成后作业结束 |
ScriptJobConfiguration
// 通过构造器创建
ScriptJobConfiguration scriptJobConfig = new ScriptJobConfiguration(config, "filepath");
属性详细说明
| 属性名 | 类型 | 构造器注入 | 缺省值 | 描述 |
|---|---|---|---|---|
| coreConfig | JobCoreConfiguration | 是 | ||
| scriptCommandLine | String | 是 | 脚本型作业执行命令行 |
2.3. JobRootConfiguration
LiteJobConfiguration
// Builder模式构造
LiteJobConfiguration liteJobConfiguration = LiteJobConfiguration.newBuilder(scriptJobConfig).build();
属性详细说明
| 属性名 | 类型 | 构造器注入 | 缺省值 | 描述 |
|---|---|---|---|---|
| jobConfig | JobTypeConfiguration | 是 | ||
| monitorExecution | boolean | 否 | true | 监控作业运行时状态 每次作业执行时间和间隔时间均非常短的情况,建议不监控作业运行时状态以提升效率。因为是瞬时状态,所以无必要监控。请用户自行增加数据堆积监控。并且不能保证数据重复选取,应在作业中实现幂等性。 每次作业执行时间和间隔时间均较长的情况,建议监控作业运行时状态,可保证数据不会重复选取。 |
| monitorPort | int | 否 | -1 | 作业监控端口 建议配置作业监控端口, 方便开发者dump作业信息。 使用方法: echo “dump” | nc 127.0.0.1 9888 |
| maxTimeDiffSeconds | int | 否 | -1 | 最大允许的本机与注册中心的时间误差秒数 如果时间误差超过配置秒数则作业启动时将抛异常 配置为-1表示不校验时间误差 |
| jobShardingStrategyClass | String | 否 | -1 | 作业分片策略实现类全路径 默认使用平均分配策略 详情参见:作业分片策略 |
| reconcileIntervalMinutes | int | 否 | 10 | 修复作业服务器不一致状态服务调度间隔时间,配置为小于1的任意值表示不执行修复 单位:分钟 |
| eventTraceRdbDataSource | String | 否 | 作业事件追踪的数据源Bean引用 |
3. 结语
下篇博客将剖析有关定时任务注册和启动的源码。