web自动化之基础内容(全网最详细,selenium环境准备和selenium工具操作)-第一天
1.环境准备
(1)pycharm中要安装selenium
也可用pip指令安装pip install selenium


(2)安装chromedriver
根据你自己的chrome的版本,下载对应的chromedriver
chrome版本在114前,下载的链接
http://chromedriver.storage.googleapis.com/index.html
chrome版本超过114,下载的链接
Chrome for Testing availability
本人的chrome版本为120.0.6099.110
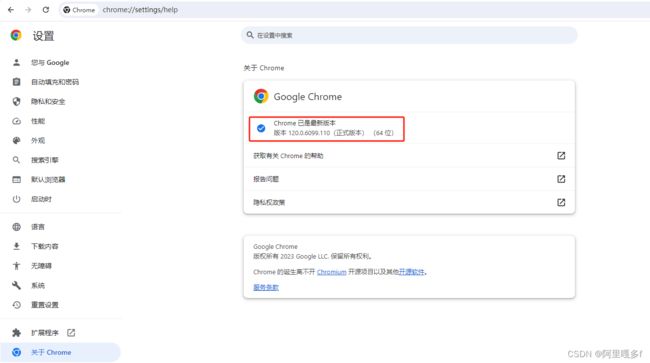
进入这个链接Chrome for Testing availability
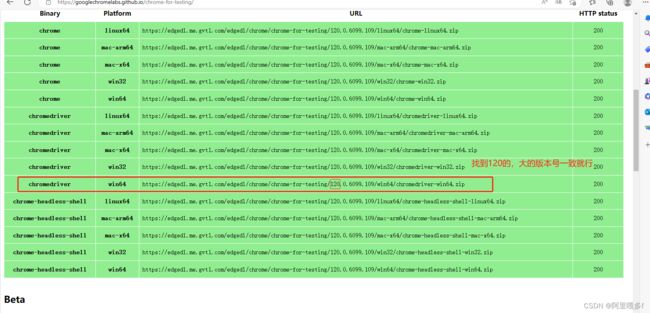

把下载的chromedriver解压,复制你解压的目录(后面代码会用到)
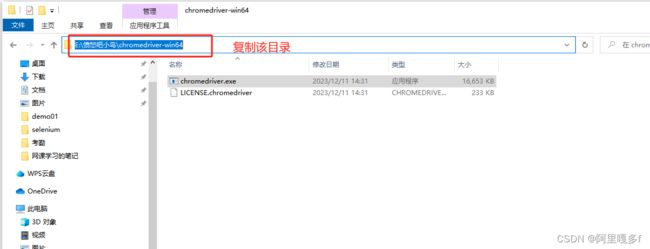
(4)验证
win + r 输入 cmd
输入chromedriver --version

2.什么是selenium?
web测试工具,运行在浏览器当中,像真正的用户在手工操作一样
支持主流的浏览器,其功能包括:
1、浏览器的兼容性
2、创建回归测试
3.什么是webdriver?
对浏览器提供的原生API进行封装,用这套 API l可以操作浏览器
总结:
selenium是python的一个库,我们写selenium代码,也是在写python代码
python代码不能直接操作浏览器,但可以操作webdriver
webdriver 可以操作浏览器,所以,我们间接的可以用python操作浏览器
4.ui自动化操作流程
选择界面元素
根据元素的特征进行选择:ID、Name、Class、TagName 等
根据元素的特征及关系:css、xpath
操作界面元素
输入操作:点击、输入文字、拖拽元素
输出操作:获取元素的各种属性
5.实战练习
注意:网页登录前和网页后的html标签可能不一样,所以定位元素可能不一样,所以你在实操的时候,要保持一致性
5.1访问百度并搜索
代码示例
from selenium import webdriver
# 创建浏览器驱动对象,这里是打开浏览器
driver = webdriver.Chrome("E:\愤怒吧小鸟\chromedriver-win64\chromedriver.exe")
#这种写法是在配置了chromedriver环境变量之后,可不写chromedriver的路径
# driver=webdriver.Chrome()
# 访问网址
driver.get('http://www.baidu.com')
# 找到元素
ele = driver.find_element_by_id("kw") #找到元素,找百度的输入框
# 操作元素,输入内容
ele.send_keys("小苏") #输入文本
# 找到元素,找到 百度一下 按钮
ele = driver.find_element_by_id("su")
# 操作元素,点击按钮
ele.click()
#quit()是直接退出浏览器
# driver.quit()
#close()是关闭当前标签页
driver.close()找百度网页的输入框(通过id)
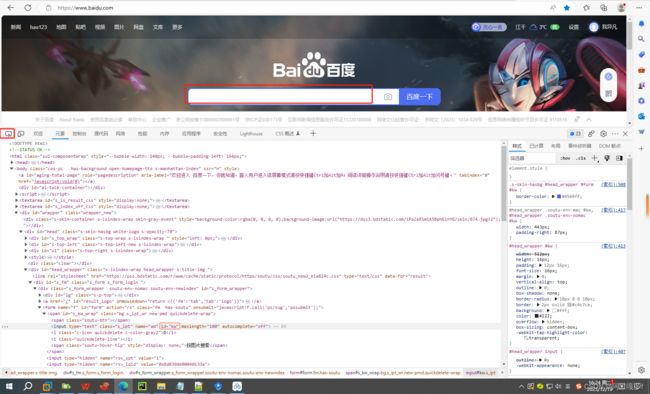
找百度网页的按钮“百度一下”(通过id)跟上面的方法一样
注意:
driver=webdriver.Chrome()中括号里面写不写chromedriver的路径,就看你有没有配置chromedriver环境变量
5.2元素定位的方法
# 根据 id 属性进行定位, 只返回找到的第一个元素
ele = driver.find_element_by_id("abc")
# 获取元素的文本值并打印出来
print(ele.text)
# 根据 name 属性定位, 只返回找到的第一个元素
ele = driver.find_element_by_name("abd")
print(ele.text)
# 根据链接文本进行定位, 只返回找到的第一个元素
ele = driver.find_element_by_link_text("点击进入百度")
ele.click()
# 根据链接文本进行定位, 模糊定位, 只返回找到的第一个元素
ele = driver.find_element_by_partial_link_text("点击进入")
ele.click()
# 根据 tag_name 进行定位, 只返回找到的第一个元素
ele = driver.find_element_by_tag_name("span")
print(ele.text)
# 根据 class 属性进行定位, 只返回找到的第一个元素
ele = driver.find_element_by_class_name("hello")
print(ele.text)
# 根据 xpath 进行定位, 只返回找到的第一个元素
ele = driver.find_element_by_xpath("/html/body/div/ul/li[2]")
print(ele.text)
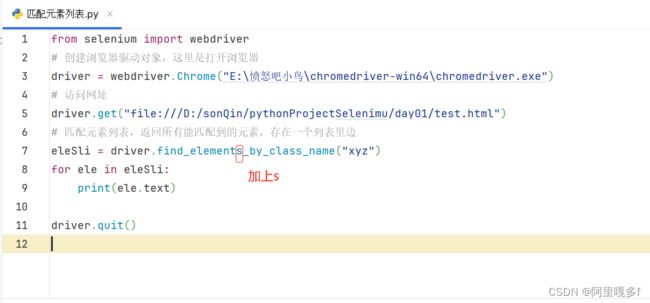
# 根据css定位,匹配元素列表,返回所有能匹配到的元素,存在一个列表里边
ele = driver.find_element_by_css_selector("html > body > div > ul > li:nth-child(2)")
print(ele.text)
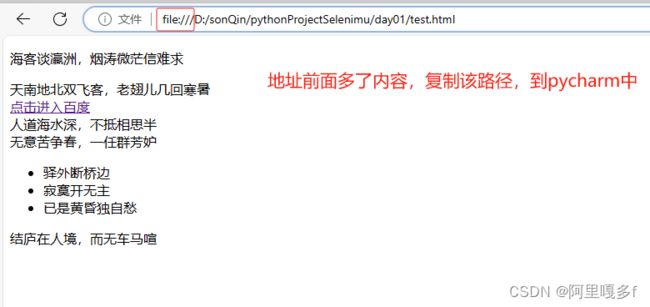
环境准备,再day01下新建test.html(自己写的界面,简单,方便初学者学习)
test.html资源可在资源中自行下载,如有疑问,可在评论区留言

把复制的路径,复制粘贴到浏览器中

代码示例
from selenium import webdriver
# 创建浏览器驱动对象,这里是打开浏览器
driver = webdriver.Chrome("E:\愤怒吧小鸟\chromedriver-win64\chromedriver.exe")
# 访问网址
driver.get("file:///D:/sonQin/pythonProjectSelenimu/day01/test.html")
"""
# 根据 id 属性进行定位, 只返回找到的第一个元素
ele = driver.find_element_by_id("abc")
# 获取元素的文本值并打印出来
print(ele.text) #海客谈瀛洲,烟涛微茫信难求
"""
"""
# 根据 name 属性定位, 只返回找到的第一个元素
ele = driver.find_element_by_name("abd")
print(ele.text) #天南地北双飞客,老翅儿几回寒暑
"""
"""
# 根据链接文本进行定位, 只返回找到的第一个元素
ele = driver.find_element_by_link_text("点击进入百度")
#点击
ele.click()
"""
"""
# 根据链接文本进行定位, 模糊定位, 只返回找到的第一个元素
ele = driver.find_element_by_partial_link_text("点击进入")
ele.click()
"""
"""
# 根据 tag_name(标签名称) 进行定位, 只返回找到的第一个元素
ele = driver.find_element_by_tag_name("span")
print(ele.text) #人道海水深,不抵相思半
"""
# 根据 class 属性进行定位, 只返回找到的第一个元素
ele = driver.find_element_by_class_name("xyz")
print(ele.text) #无意苦争春,一任群芳妒
"""
# 根据 xpath 进行定位, 只返回找到的第一个元素
#/html/body/div/ul/li[2]是绝对路径
ele = driver.find_element_by_xpath("/html/body/div/ul/li[2]")
print(ele.text) #寂寞开无主
"""
"""
# 匹配元素列表,返回所有能匹配到的元素,存在一个列表里边
ele = driver.find_element_by_css_selector("html > body > div > ul > li:nth-child(2)")
print(ele.text) #寂寞开无主
"""
driver.quit()
xpath定位图解

css定位图解

注意:如果class属性名称有空格,driver.find_element_by_class_name("hello nice world")这样定位就会报错
举例


总结css和xpath定位:
web中80%都会用到css定位,必须要学xpath是因为appium没有css定位方法,只有xpath
元素定位注意事项(一定注意,并牢记)
1、当你想要操作某个确定的元素的时候,一定保持自己的表达式唯一定位
2、当你需要操作一组元素的时候,你必须保证自己的表达式
a.能匹配到所有想要操作的元素
b.不会匹配到任何其他不想操作的元素
5.3匹配元素列表
代码示例