C++多线程--线程安全的哈希表(基于锁)
0 引言
此篇为本专栏的第一篇文章。本专栏主要讲解C++并发编程相关的实践。包括但不限于
- 基于锁的数据结构
- 无锁数据结构
- 并发编程的一些注意事项
- 线程池
- C++20与并发编程相关的新特性
首先,我们从基于锁的数据结构讲起。
前段时间,我某个同事面试字节某业务时,面试官让其实现一个线程安全的哈希表。本文便以此开始,分几篇来讲解基于锁的线程安全的一些数据结构
- 栈
- 队列
- 哈希表
1. 线程数据结构设计准则
并发数据的目的是要保证:
- 线程安全
- 真正并发
为了达到这两个目的,在设计基于锁的线程安全的数据结构时需要考虑
- 需要保证数据结构的一致性(没有线程可以看到数据结构的不变量被破坏)
- 防止数据接口本身接口间的race condition
- 确保数据结构在异常发生时的安全性
- 防止死锁
- 尽量达到真正的并发
2. 基于锁的的哈希表设计
当面试官要求设计一个线程安全的哈希表时,可以参考如下思路
- 是不是采用锁的?
- 需要有哪些接口?
- 是不是可以使用std::map等stl库?
等等。
我们假设是基于锁的哈希表,首先考虑一下相应的接口,不能支持哪些接口?
- 不能支持operator[] 因为这个可能修改元素
- 不支持iterator模式
2.1 基于std::map的哈希表
为了简化相应的实现,此线程安全的哈希表仅提供如下功能
- 增加一个新的key/value
- 更新相应key的value
- 移除一个key及其相应的value
- 获得一个key及其相应的value
template >
class ThreadSafeMap {
private:
std::shared_mutex mut_;
std::map> table_;
public:
ThreadSafeMap() = default;
ThreadSafeMap(const ThreadSafeMap&) = delete;
ThreadSafeMap& operator=(const ThreadSafeMap&) = delete;
std::shared_ptr valueFor(const Key& key) {
std::shared_lock lk(mut_);
auto iter = table_.find(key);
if (iter != table_.end()) return iter->second;
return nullptr;
}
void addOrUpdate(const Key& key, const Value& value) {
auto v = std::make_shared(value);
std::unique_lock lk(mut_);
auto iter = table_.find(key);
if (iter != table_.end()) iter->second = std::move(v);
table_.emplace(key, v);
}
void remove(const Key& key) {
std::unique_lock lk(mut_);
table_.erase(key);
}
};
上述代码测试用例如下
int main() {
ThreadSafeMap mp;
std::thread t1{[&mp]() {
mp.addOrUpdate(10, "hello world");
mp.addOrUpdate(1, "hello");
}};
std::thread t2{[&mp]() {
mp.addOrUpdate(11, "hello world");
std::this_thread::sleep_for(std::chrono::milliseconds{10});
auto value = mp.valueFor(1);
if (value == nullptr) return;
std::cout << "key 1 : value : " << *value << "\n";
}};
std::thread t3{[&mp]() {
std::this_thread::sleep_for(std::chrono::milliseconds{10});
auto value = mp.valueFor(10);
if (value == nullptr) return;
std::cout << "key 10 : value : " << *value << "\n";
}};
t1.join();
t2.join();
t3.join();
return 0;
} 基于map的实现中,将map的value设置为std::shared_ptr
此外由于map会涉及到读写操作,因此使用std::shared_mutex, 读写锁的方式来对数据进行加锁,提高程序的并发能力。
2.2 非基于std::map的哈希表
也许面试官会让你实现一个性能更高的线程安全的哈希表,那么此刻便需要更改上述实现。首先需要考虑的是,怎样选择底层数据结构。此处我们选择
- std::vector
- std::list
来构造地层的哈希表。其大概形式如下图所示
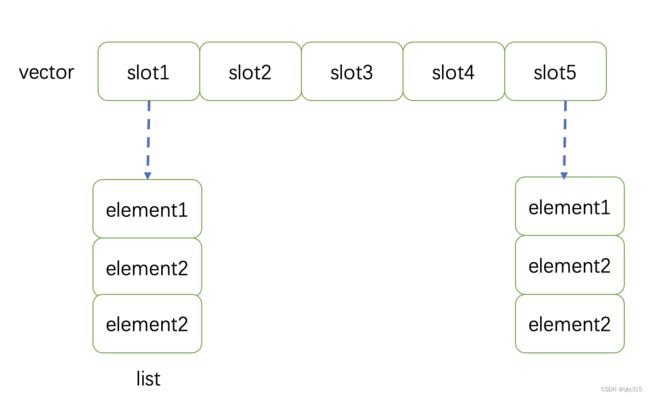
首先来看一下,完整的线程安全的hashtable的实现
template >
class ThreadSafeMap {
private:
struct Bucket {
using BucketValue = std::pair>;
using Data = std::list;
mutable std::shared_mutex mut_;
Data data_;
decltype(auto) findEntry(const Key& key) const {
return std::find_if(data_.begin(), data_.end(), [&key](const auto& item) {
return item.first == key;
});
}
std::shared_ptr valueFor(const Key& key) {
std::shared_lock lk(mut_);
auto iter = findEntry(key);
if (iter != data_.end()) return iter->second;
return nullptr;
}
void addOrUpdate(const Key& key, const Value& value) {
auto v = std::make_shared(value);
std::unique_lock lk(mut_);
auto iter = findEntry(key);
if (iter != data_.end()) {
auto iter1 = data_.begin();
std::advance(iter1, std::distance(data_.cbegin(), iter));
iter1->second = std::move(v);
return;
}
data_.push_back({key, v});
}
void remove(const Key& key) {
std::unique_lock lk(mut_);
auto iter = findEntry(key);
data_.erase(iter);
}
};
private:
std::vector> buckets_;
Hash hasher_;
Bucket& getBucket(const Key& key) const {
std::size_t const bucket_index= hasher_(key) % buckets_.size();
return *buckets_[bucket_index];
}
public:
ThreadSafeMap(unsigned bucket_nums = 19, const Hash& hasher = Hash{})
: buckets_(bucket_nums), hasher_(hasher) {
for (auto& bucket : buckets_) {
bucket.reset(new Bucket);
}
}
ThreadSafeMap(const ThreadSafeMap&) = delete;
ThreadSafeMap& operator=(const ThreadSafeMap&) = delete;
std::shared_ptr valueFor(const Key& key) {
return getBucket(key).valueFor(key);
}
void addOrUpdate(const Key& key, const Value& value) {
return getBucket(key).addOrUpdate(key, value);
}
void remove(const Key& key) {
return getBucket(key).remove(key);
}
}; 上述线程安全的哈希表实现需要进行如下说明
- 利用vector和list实现地层的map
- vector中的每个slot为一个Bucket类型
- 在Bucket类中存放一个list,该list中存放正在的key/value
- 在addOrUpdate接口中使用的std::advance(iter1, std::distance(data_.cbegin(), iter)); 主要是为了将const_iterator转换为iterator,以更新相应key的value
现在在每个Bucket中有一个读写锁,其粒度比基于std::map的更小,因此该哈希表能获得更大的并发。
3. 总结
本篇博客为该专栏的第一篇博客,主要讲解了如何利用C++标准库提供的读写锁实现线程安全的哈希表。
此外本篇博客也总结了一些设计并发数据结构的一些准则。
下一篇将讲解线程安全的堆栈的实现。