7个向量数据库对比:Milvus、Pinecone、Vespa、Weaviate、Vald、GSI 和 Qdrant
本文简要总结了当今市场上正在积极开发的7个向量数据库,Milvus、Pinecone、Vespa、Weaviate、Vald、GSI 和 Qdrant 的详细比较。
我们已经接近在搜索引擎体验的基础层面上涉及机器学习:在多维多模态空间中编码对象。这与传统的关键字查找不同(即使通过同义词/语义进行了增强)——在许多有趣的方面:
- 对象级别的集合级别相似性。您可以使用相似度函数(距离度量)而不是稀疏关键字查找来查找查询的邻居。在带有分片的 BM25/TF-IDF 方法中,您将获得来自不兼容的分片级集合的文档分数(除非您设置全局更新的IDF缓存)。
- 将几何相似性的概念作为语义中的一个组成部分,而不仅仅是原始对象的特定属性(在文本的情况下——它的关键字/术语)。
- 多模态:编码任何对象——音频、视频、图像、文本、基因组、软件病毒、一些复杂的对象(如代码),你有一个编码器和相似性度量——并在这些对象之间无缝搜索。
同时,关键字可以以互补的方式与相似度搜索相结合,尤其是当您面临长尾零命中问题(可能相当大,例如在电子商务领域)的情况下。
这篇博文总结了 7 个向量数据库之间的共性和差异,每个都提供商业云支持。7 人中有 5 人将他们的代码作为开源代码提供给您自己的主机。这篇文章不包括神经搜索框架(如Jina.AI、FAISS或 deepset 的Haystack),这些框架应该有自己的博客文章。此外,它并不专注于大型云供应商垂直搜索引擎,例如 Bing 或 Google 的向量搜索引擎。算法基准测试超出了范围,因为您始终可以求助于https://github.com/erikbern/ann-benchmarks查找有关单个算法性能和权衡的详细信息。
我冒昧地从以下五个角度考虑了每个搜索引擎:
- 价值主张。让整个向量搜索引擎脱颖而出的独特之处是什么?
- 类型。该引擎的通用类型:向量数据库、大数据平台。托管/自托管。
- 架构。高级系统架构,包括分片、插件、可扩展性、硬件细节(如果可用)等方面。
- 算法。这个搜索引擎采用了什么算法来进行相似度/向量搜索,它提供了哪些独特的功能?
- 代码:它是开源的还是闭源的?
每个搜索引擎都附有元数据:
链接到描述该技术的主页
类型:自托管和/或托管
代码链接到可用的源代码
Milvus
链接:https ://milvus.io/
类型:自托管向量数据库
代码:开源
- 价值主张:关注整个搜索引擎的可扩展性:如何高效地对向量数据进行索引和重新索引;如何缩放搜索部分。独特的价值是能够使用多种 ANN 算法对数据进行索引,以比较它们在您的用例中的性能。
- 架构:
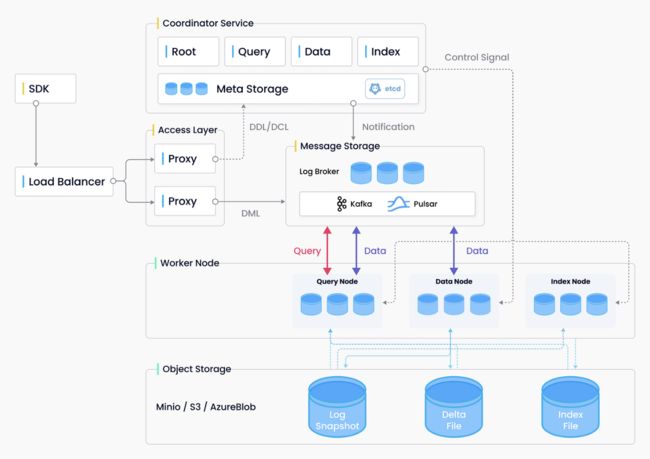
Milvus 实现了四层:接入层、协调服务、工作节点和存储。这些层是独立的,以实现更好的可扩展性和灾难恢复
3.算法:允许多个基于 ANN 算法的索引:FAISS、ANNOY、HNSW、RNSG。
Pinecone
链接:https ://www.pinecone.io/
类型:托管向量数据库
代码:封闭源代码
- 价值主张:完全托管的向量数据库,以支持您的非结构化搜索引擎之旅。最近的2.0 版本带来了单阶段过滤功能:在一个查询中搜索您的对象(毛衣)并按元数据(颜色、尺寸、价格、可用性)进行过滤。
- 架构:
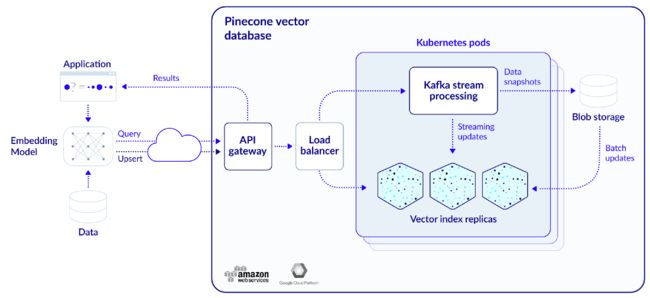
Pinecone 是一个托管向量数据库,使用 Kafka 进行流处理,使用 Kubernetes 集群实现高可用性以及Blob 存储(向量和元数据的真实来源,用于容错和高可用性)
3.算法:由 FAISS 提供支持的 Exact KNN;ANN 由专有算法提供支持。支持所有主要距离度量:余弦(默认)、点积和欧几里得。
Vespa
链接:https ://vespa.ai/
类型:托管/自托管向量数据库
代码:开源
- 价值主张:引用官方文档:“Vespa 是在大型数据集上进行低延迟计算的引擎。它存储和索引您的数据,以便可以在服务时执行对数据的查询、选择和处理。可以使用托管在 Vespa 中的应用程序组件来定制和扩展功能。” Vespa 提供了面向深度学习的深度数据结构,例如数据科学,例如张量。
- 架构:
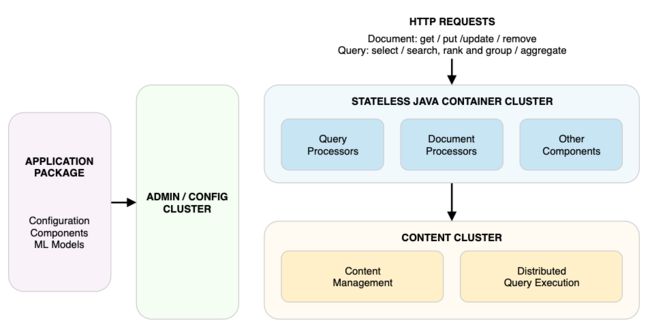
Vespa 架构图
3.算法:HNSW(针对实时CRUD和元数据过滤进行了修改);一套重新排序和密集检索方法。
Weaviate
链接:https ://www.semi.technology/developers/weaviate/current/
类型:托管/自托管向量数据库
代码:开源
- 价值主张:类 Graphql接口支持的表达查询语法。这允许您对丰富的实体数据运行探索性数据科学查询。该产品最重要的元素是向量搜索、对象存储和用于布尔关键字搜索的倒排索引的组合,以避免存储与对象/倒排索引分开的向量数据的不同数据库之间的数据漂移和延迟。Wow-effect:有一个令人印象深刻的问答组件——它可以带来一个令人惊叹的元素来演示作为现有或新产品的一部分的新搜索功能。
- 架构:
这是Weaviate的系统级架构图。它显示了索引组合:您可以存储向量、对象和倒排索引数据,以混合和匹配适合您用例的搜索功能。支持用于不同任务的模块,例如问答。
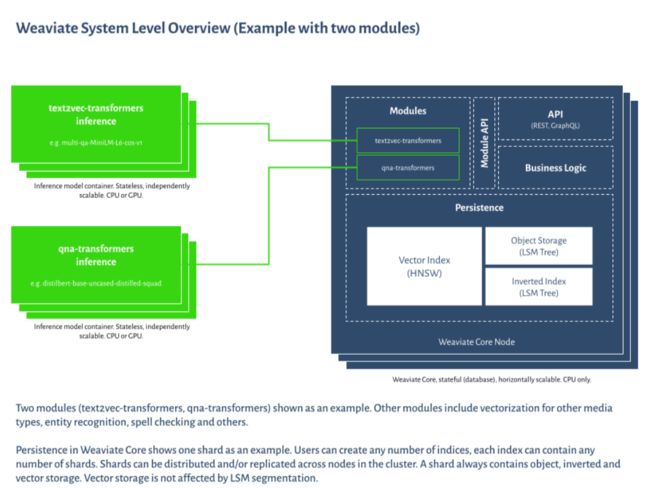
系统级概览
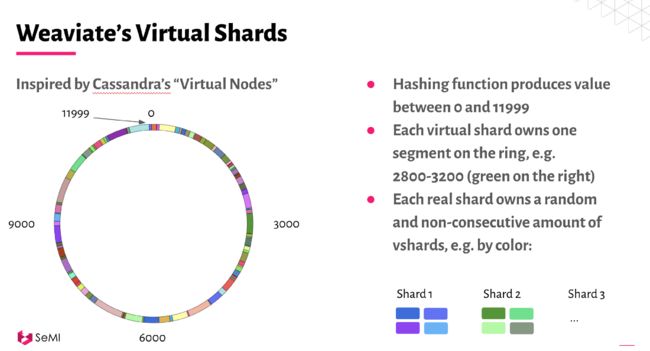
使用虚拟分片将分片分布到节点上(受Cassandra 分片启发)
3.算法:自定义实现的 HNSW,调整到规模,并支持完整的 CRUD。只要能做CRUD ,系统就支持插件ANN算法。
Vald
链接:https ://vald.vdaas.org/
类型:自托管向量搜索引擎
代码:开源
- 价值主张:Vald 用于十亿向量规模,提供云原生架构。来自官方文档:“Vald 具有自动向量索引和索引备份,以及用于从数十亿特征向量数据中进行搜索的水平缩放。” 该系统还允许使用 Egress 过滤器插入您的自定义重新排序/过滤算法。奖励:可以直接安装在 macOS 上。
- 架构:
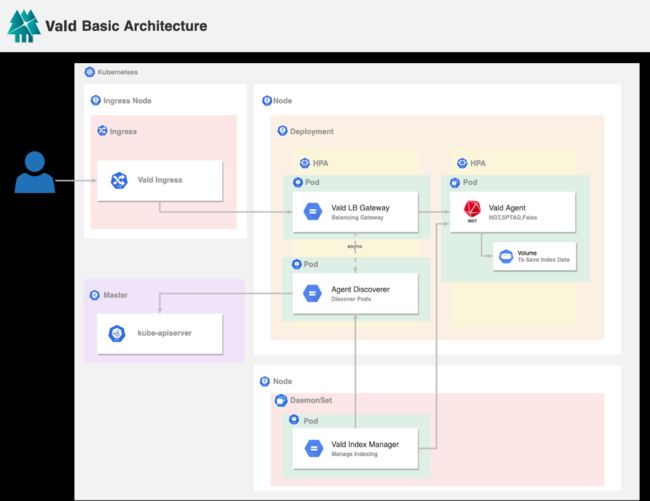
Vald 在 Kubernetes 集群之上运行以利用其 HPA 和分布式功能
3.算法:基于最快算法:NGT,比很多强算法,如Scann和HNSW都要快。
用于 Elasticsearch 和 OpenSearch 的 GSI APU 板
链接:https ://www.gsitechnology.com/APU
类型: Elasticsearch / OpenSearch的向量搜索硬件后端
代码:封闭源代码
- 价值主张:十亿规模的搜索引擎后端,将您的Elasticsearch / OpenSearch功能扩展到相似性搜索。您可以实施高效节能的多模式搜索,增强关键字检索。它以本地APU 板和托管云后端的形式提供,通过插件与您的 Elasticsearch / OpenSearch 部署连接。
- 架构:
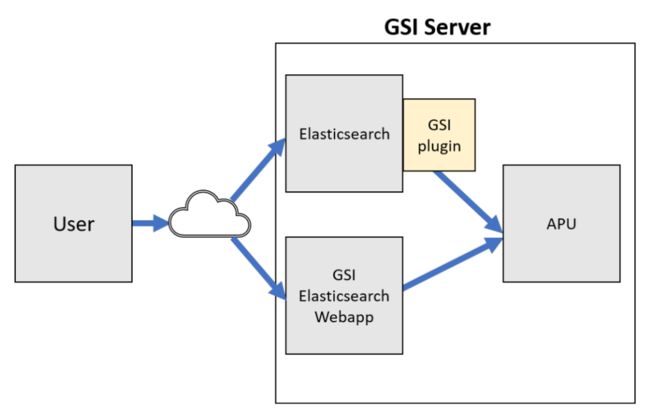
GSI APU 驱动的 Elasticsearch 架构的架构(GSI Technology提供的屏幕截图)

APU板特点
3.算法:保持神经散列的汉明空间局部性。
Qdrant
链接:https ://qdrant.tech/
类型:托管/自托管向量搜索引擎和数据库
代码:开源
- 价值主张:具有扩展过滤支持的向量相似度引擎。Qdrant 完全用 Rust 语言开发,实现了动态查询计划和有效负载数据索引。向量负载支持多种数据类型和查询条件,包括字符串匹配、数值范围、地理位置等。有效负载过滤条件允许您构建几乎任何应该在相似性匹配之上工作的自定义业务逻辑。
- 架构:
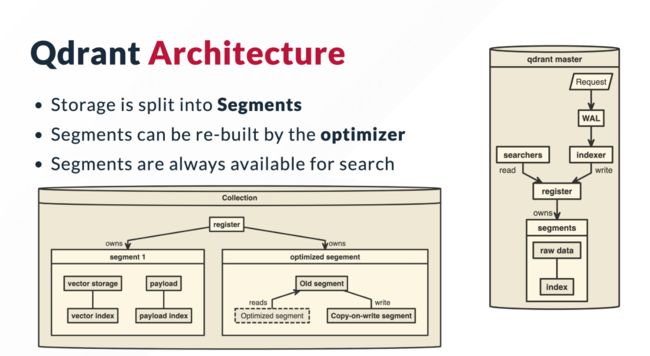
集合级架构
3.算法: Rust 中的自定义HNSW 实现。
原文标题:Not All Vector Databases Are Made Equal
原文作者:Dmitry Kan
原文链接:https://towardsdatascience.com/milvus-pinecone-vespa-weaviate-vald-gsi-what-unites-these-buzz-words-and-what-makes-each-9c65a3bd0696