C++模板初阶
文章目录
- 前言
- 1.泛型编程
- 2. 函数模板
-
- 2.1 函数模板概念
- 2.2 函数模板格式
- 2.3 函数模板的原理
- 2.4 函数模板的实例化
- 2.5 模板参数的匹配原则
- 3. 类模板
-
- 3.1 类模板的定义格式
- 3.2 类模板的实例化
- 总结
前言
假设当我们要实现一个交换函数时,面对不同的数据类型,我们可以通过函数重载来一个一个去书写:
void Swap(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}
void Swap(double& left, double& right)
{
double temp = left;
left = right;
right = temp;
}
void Swap(char& left, char& right)
{
char temp = left;
left = right;
right = temp;
}
我们会发现这会先的十分冗余,那么有没有什么方便的方式来实现这个功能呢?因此C++就引入了应对这种情况的方法 ------模板。
1.泛型编程

以上图为例,我们可以提前弄好一个模具,有了模具我们就可以浇筑一个个不同颜色的物品。如果在C++中,也能够存在这样一个模具,通过给这个模具中填充不同材料(类型),来获得不同材料的铸件(即生成具体类型的代码),那将会节省许多功夫。巧的是前人早已将树栽好,我们只需在此乘凉。
泛型编程:编写与类型无关的通用代码,是代码复用的一种手段。模板是泛型编程的基础。
2. 函数模板
2.1 函数模板概念
函数模板代表了一个函数家族,该函数模板与类型无关,在使用时被参数化,根据实参类型产生函数的特定类型版本。
2.2 函数模板格式
template<typename T1, typename T2,......,typename Tn>
返回值类型 函数名(参数列表){}
eg:
template<typename T>
//template 使用方式就是在函数前面加上template< typename T>或者template< class T>,将参数类型写成T(这里的T就时< class T>中的T,这个可以随便写),传参时用引用传参,因为我们不知道进来的参数是内置类型还是自定义类型,如果是自定义类型而没有用引用传参就会引发无穷递归。
注意:typename是用来定义模板参数关键字,也可以使用class(切记:不能使用struct代替class)
2.3 函数模板的原理
那么如何解决上面的问题呢?大家都知道,瓦特改良蒸汽机,人类开始了工业革命,解放了生产力。机器生产淘汰掉了很多手工产品。本质是什么,重复的工作交给了机器去完成。有人给出了论调:懒人创造世界。
函数模板是一个蓝图,它本身并不是函数,是编译器用使用方式产生特定具体类型函数的模具。所以其实模板就是将本来应该我们做的重复的事情交给了编译器。
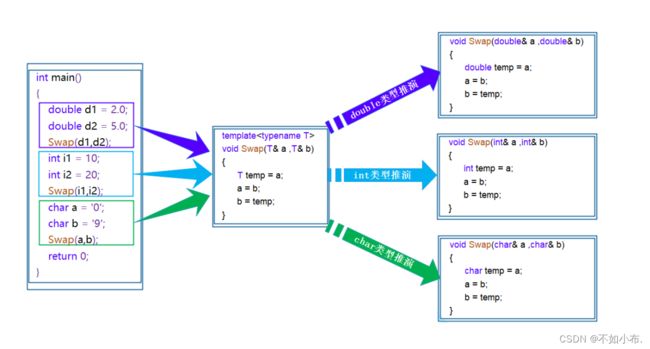
在编译器编译阶段,对于模板函数的使用,编译器需要根据传入的实参类型来推演生成对应类型的函数以供调用。比如:当用double类型使用函数模板时,编译器通过对实参类型的推演,将T确定为double类型,然后产生一份专门处理double类型的代码,对于字符类型也是如此。
2.4 函数模板的实例化
用不同类型的参数使用函数模板时,称为函数模板的实例化。模板参数实例化分为:隐式实例化和显式实例化。
- 隐式实例化:让编译器根据实参推演模板参数的实际类型
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
int main()
{
int a1 = 10, a2 = 20;
double d1 = 10.0, d2 = 20.0;
Add(a1, a2);
Add(d1, d2);
/*
该语句不能通过编译,因为在编译期间,当编译器看到该实例化时,需要推演其实参类型
通过实参a1将T推演为int,通过实参d1将T推演为double类型,但模板参数列表中只有一个T,
编译器无法确定此处到底该将T确定为int 或者 double类型而报错
注意:在模板中,编译器一般不会进行类型转换操作,因为一旦转化出问题,编译器就需要背黑锅
Add(a1, d1);
*/
// 此时有两种处理方式:1. 用户自己来强制转化 2. 使用显式实例化
Add(a1,(int)d1);
return 0;
}
- 显式实例化:在函数名后的<>中指定模板参数的实际类型
int main(void)
{
int a = 10;
double b = 20.0;
// 显式实例化
Add<int>(a, b);
return 0;
}
如果类型不匹配,编译器会尝试进行隐式类型转换,如果无法转换成功编译器将会报错。
2.5 模板参数的匹配原则
- 一个非模板函数可以和一个同名的函数模板同时存在,而且该函数模板还可以被实例化为这个非模板函数。
// 专门处理int的加法函数
int Add(int left, int right)
{
return left + right;
}
// 通用加法函数
template<class T>
T Add(T left, T right)
{
return left + right;
}
void Test()
{
Add(1, 2); // 与非模板函数匹配,编译器不需要特化
Add<int>(1, 2); // 调用编译器特化的Add版本
}
这是因为函数模板它实际上只是一个工具,并没有被实例化出来,可以理解为函数模板是是一个虚幻的存在,而实例化出来的东西才是真正存在的,因此它们可以共存。
- 对于非模板函数和同名函数模板,如果其他条件都相同,在调动时会优先调用非模板函数而不会从该模板产生出一个实例。如果模板可以产生一个具有更好匹配的函数, 那么将选择模板。
// 专门处理int的加法函数
int Add(int left, int right)
{
return left + right;
}
// 通用加法函数
template<class T1, class T2>
T1 Add(T1 left, T2 right)
{
return left + right;
}
void Test()
{
Add(1, 2); // 与非函数模板类型完全匹配,不需要函数模板实例化
Add(1, 2.0); // 模板函数可以生成更加匹配的版本,编译器根据实参生成更加匹配的Add函数
}
可以理解为已经有现成的了,编译器就不会去再实例化一个出来。编译器是遵循最优匹配的,如果实例化出来的函数更加匹配,那么就会进行实例化。
- 模板函数不允许自动类型转换,但普通函数可以进行自动类型转换。
3. 类模板
3.1 类模板的定义格式
template<class T1, class T2, ..., class Tn>
class 类模板名
{
// 类内成员定义
};
eg:
// 动态顺序表
// 注意:Vector不是具体的类,是编译器根据被实例化的类型生成具体类的模具
template<class T>
class Vector
{
public:
Vector(size_t capacity = 10)
: _pData(new T[capacity])
, _size(0)
, _capacity(capacity)
{}
// 使用析构函数演示:在类中声明,在类外定义。
~Vector();
void PushBack(const T& data);
void PopBack();
// ...
size_t Size() { return _size; }
T& operator[](size_t pos)
{
assert(pos < _size);
return _pData[pos];
}
private:
T* _pData;
size_t _size;
size_t _capacity;
};
// 注意:类模板中函数放在类外进行定义时,需要加模板参数列表
template <class T>
Vector<T>::~Vector()
{
if (_pData)
delete[] _pData;
_size = _capacity = 0;
}
有了类模板,它就可以存储任意类型的数据了,就不需要像C语言一个顺序表只能存储一种类型,如果要存储第二个类型就需要再实现一个顺序表,C++有了模板就只需要进行显式实例化就可以了。
3.2 类模板的实例化
类模板实例化与函数模板实例化不同,类模板实例化需要在类模板名字后跟<>,然后将实例化的类型放在<>中即可,类模板名字不是真正的类,而实例化的结果才是真正的类。
// Vector类名,Vector才是类型
Vector<int> s1;
Vector<double> s2;
而在C语言中,要在同一个文件中同时存在存储两种类型的顺序表,就需要实现两个顺序表才可以实现,C++只需要进行显式实例化就可以了。
总结
关于模板这一部分,目前这些内容比较简单,这让我们对模板有了大概的理解,这用来应对一般情况已经足够了,后续我还会继续讲解模板的进阶部分。
如果大家发现有什么错误的地方,可以私信或者评论区指出喔(虚心请教,希望得到大佬帮助)。我会继续深入学习C++,希望能与大家共同进步,那么本期就到此结束,让我们下期再见!!觉得不错可以点个赞以示鼓励!!