数据分析师面试必备,数据分析面试题集锦(五)
大家好,今天整理数据分析面试题集锦,经常会被问到,“互联网大厂数据分析需要学习什么技能?”,“针对实际的业务场景,如何使用数据分析工具去分析?”基于此作者总结数据分析面试常用的问题,面试内容包括技能应用篇:EXCEL、SQL、Python、BI工具等,业务思维篇:常用的数据分析方法与业务思维等。
其中大部分问题点,没有绝对标准答案,所有问题点都是为了解决问题,大家如果有更好的问题答案,也可以提出,对于其中的问题也可以提出,共同解答,欢迎点赞、转发、评论,下面一起来学习,学习一线大厂数据分析大佬的技能总结。
本文讲解内容:Excel、SQL、Python面试必备
适用范围:多种数据分析实用技巧
Excel篇
1、自定义数据格式代码
如何自定义数据格式,比如这里8月销售大于7月销售,将其显示为绿色并添加向上的箭头,8月销售小于7月销售,将其显示为红色并添加向下的箭头。
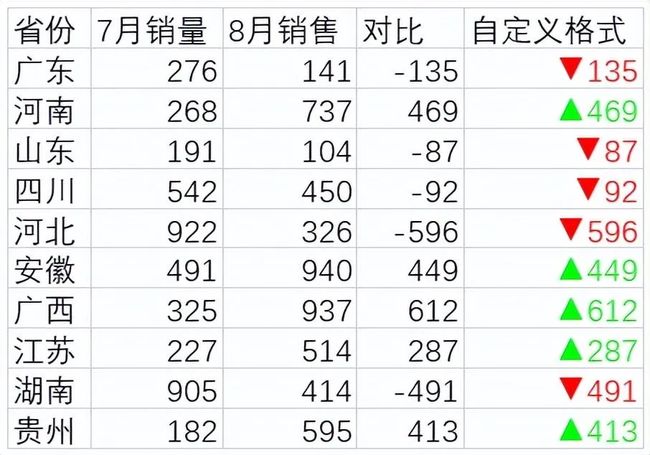
选择需要设置数据格式的区域,右键点击设置单元格格式输入如下的格式代码,该代码可分为两部分,用分号隔开,第一部分是对大于0的值设置格式:[绿色][>0]▲0,表示字体颜色为绿色,显示▲,0表示原数,第二部分是对小于0的值设置格式:[红色][<0]▼0,表示字体颜色为红色,显示▼,0表示原数。
[绿色][>0]▲0;[红色][<0]▼0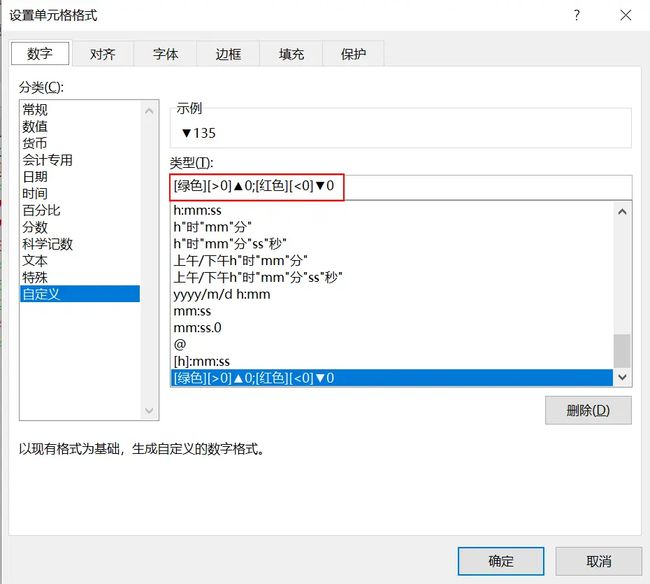
另外在PowerBI中,可以使用如下的DAX函数设置如上的自定义数据格式,感兴趣可以尝试一下。
环比_颜色 = SWITCH(TRUE(),
[环比]>0,UNICHAR(9650)&FORMAT([环比],"0.0%"),
[环比]<0,UNICHAR(9660)&FORMAT([环比],"0.0%"),"")除此之外,还有自定义数据格式用来设置单位,如下也可设置单元格式,自定义设置。
0!.0,"万"
0!.00,,"亿"比如这里使用0!.0,"万"表示万,先使用千分位符,将数据缩小1000倍,然后设置数据格式为0!.0将数据缩小10倍,小数点前的 ! 是用于强制显示小数点,将数据缩小10倍,最后再加一个万字即可,需要加双引号。
2、批量生成销售个人明细
要批量生成销售个人明细,比如生成每一个销售每一天的销量和销售额情况,可以先数据透视,注意要将销售员拖入到筛选器中。
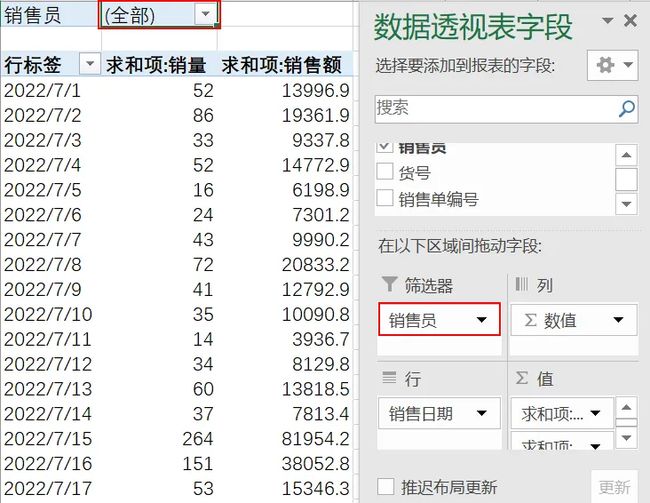
然后在数据透视表工具中选择分析,点击选项下面的显示报表筛选页。
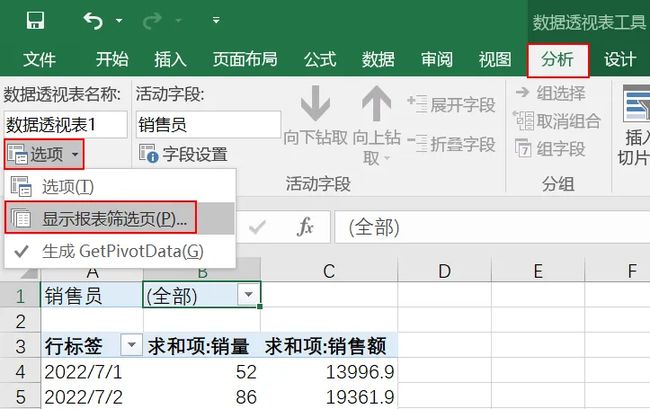
在显示报表筛选页下选择销售员,点击确定即可。
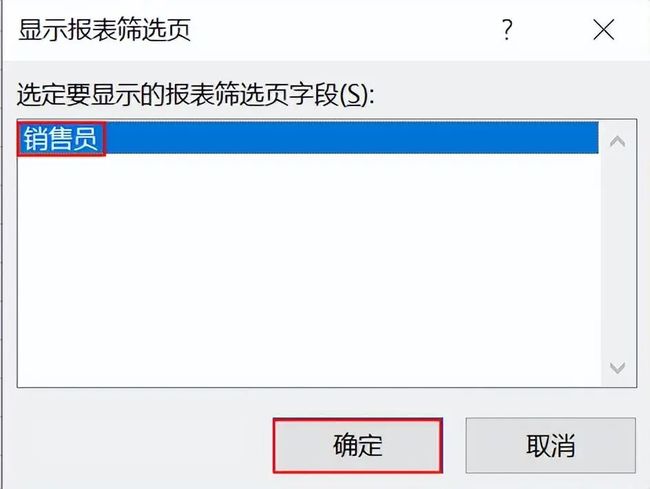
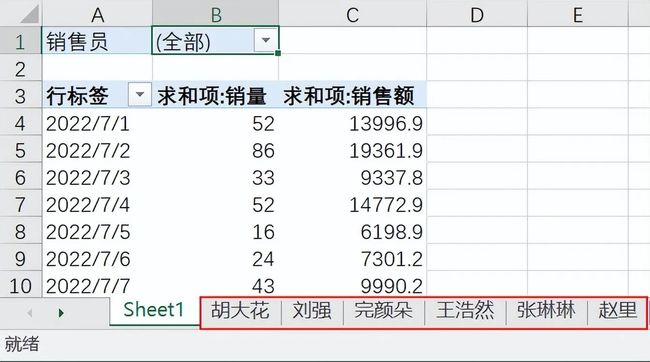
如下将我们所有的销售员每一天的销量和销售额进行了拆分,拆分为每一个销售个人的具体情况。
SQL篇
表之间的关联
如下考察表格之间的关联关系,比如表与表之间的合并,表与表之间的相交等等,考查表格关联的逻辑。

第一问、表A和表B的交集:
SELECT a.cus_id from `表a` as a
INNER JOIN `表b` as b
on a.cus_id=b.cus_id;第二问、表A和表B的并集:
SELECT * from `表a`
UNION
SELECT * from `表b`;第三问、表A和表B的对称差:
SELECT * from `表a` where cus_id not in (SELECT * from `表b`)
UNION
SELECT * from `表b` where cus_id not in (SELECT * from `表a`);第四问、表A中存在但表B中不存在:
SELECT * from `表a`
WHERE cus_id not in (SELECT cus_id from `表b`);Python篇
1、np.where分组用法
首先创建案例数据,创建一个DataFrame。
import pandas as pd
df=pd.DataFrame(data={'语文': [50,90,70,78,60],
'数学': [59,80,60,75,69],
'英语': [61,95,65,80,59]},
index=['小明','小红','小丽','小刚','小东'])
df['总分']=df['语文']+df['数学']+df['英语']
df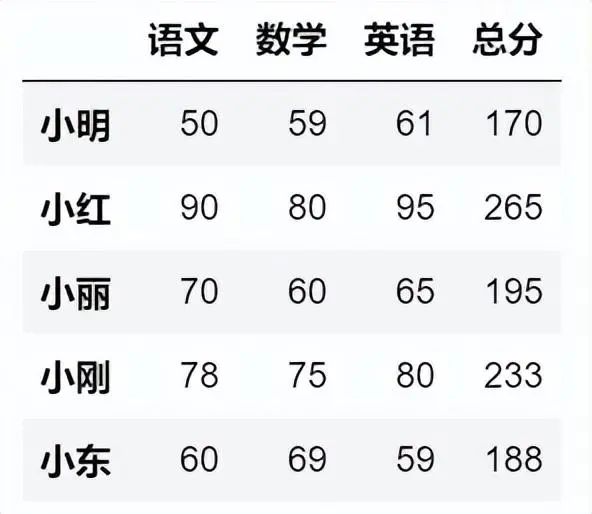
导入numpy库,调用np.where的用法。
#np.where的用法
import numpy as np
df['总分评级']=np.where(df['总分']>200,'A等','B等')
df
np.where也用于两个字段之间的比较,比如这里的语文成绩与数学成绩之间的比较。
df['语文评级']=np.where(df['语文']>df['数学'],'✔','✘')
df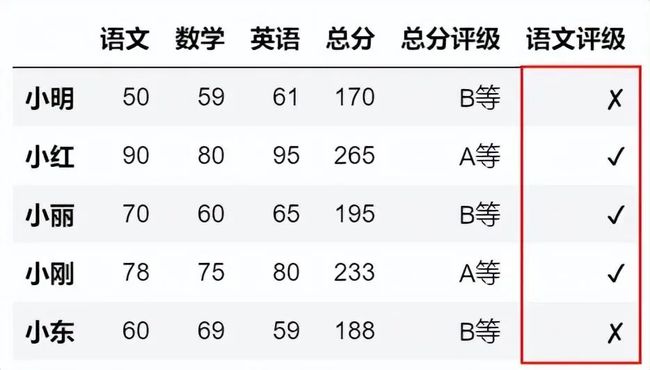
2、多条件赋值用法
使用loc函数,选择确定条件区域的数据,直接使用“=”号进行赋值,从而达到多条件赋值的用处。
#多条件赋值用法
df['数学评级']=''
df.loc[df['数学']<60,'数学评级']='不及格'
df.loc[df['数学']>=60,'数学评级']='及格'
df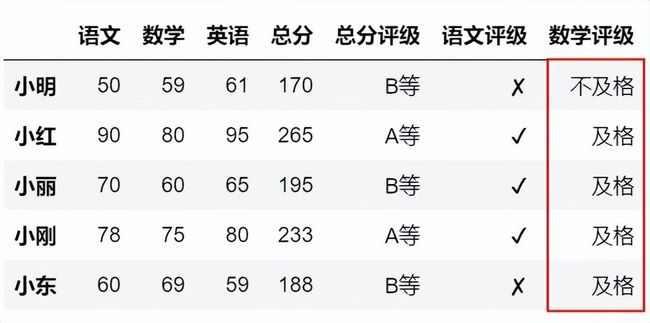
3、apply用法
首先定义一个GetScore函数,该函数中用来写入不同的条件,然后使用apply函数应用到该行即可。
def GetScore(df):
if df['英语']<60:
return '不及格'
elif df['英语']<70:
return '及格'
elif df['英语']<80:
return '中等'
elif df['英语']<90:
return '良好'
elif df['英语']<100:
return '优秀'
df.loc[:,'英语评级']=df.apply(GetScore,axis=1)
df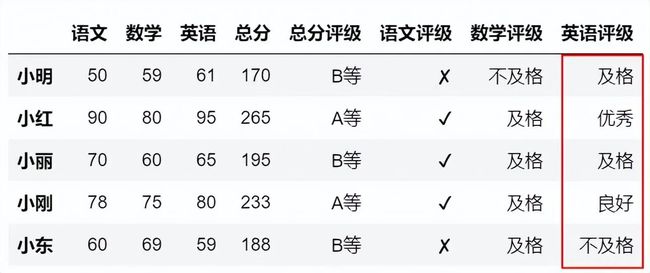
4、np.select用法
有多个条件可以使用np.select函数,这种适用于多个字段之间设置比较条件,比如这里语文、数学、英语同时大于60分就设置为及格,其他用法类似。
#多条件判断,有多个条件可以使用
np.selectconditions=[(df['语文']>=60)&(df['数学']>=60)&(df['英语']>=60),
(df['语文']<60)&(df['数学']>60)&(df['英语']>60),
(df['语文']>60)&(df['数学']<60)&(df['英语']>60),
(df['语文']>60)&(df['数学']>60)&(df['英语']<60)]
results=['合格','不合格','不合格','不合格']
df['多重评级']=np.select(conditions,results,default='不合格')
df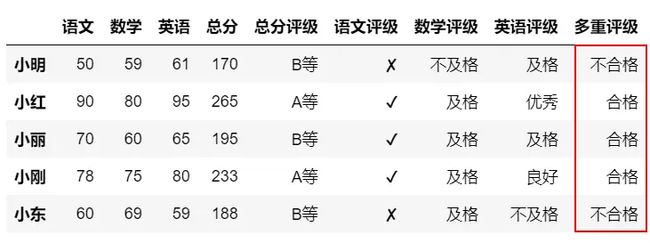
多列合并为一列可以使用map函数转为字符型,用加号进行连接。
#将多列合并为一列
df['评级合并']=df['语文评级'].map(str)+df['数学评级'].map(str)+df['英语评级'].map(str)
df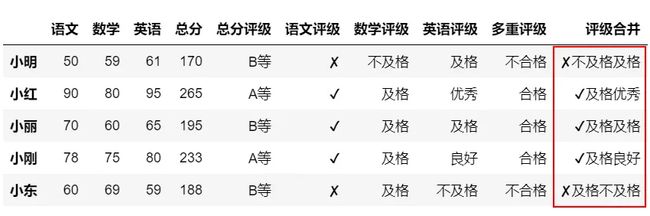
三年互联网数据分析经验,擅长Excel、SQL、Python、PowerBI数据处理工具,数据可视化、商业数据分析技能,统计学、机器学习知识,持续创作数据分析内容,点赞关注,不迷路。