云原生分布式多模架构:华为云多模数据库 GeminiDB 架构与应用实践
文章目录
- 前言
- 一、GeminiDB 总体介绍
-
- 1.1、华为云数据库全景图
- 1.2、GeminiDB 发展历程
- 1.3、GeminiDB 全球分布情况
- 二、GeminiDB 云原生架构
-
- 2.1、核心设计:存算分离&多模扩展
- 2.2、存算分离&多模扩展核心优势
- 2.3、高可用:秒级故障接管
- 2.4、弹性扩展:扩计算,业务仅秒级抖动
- 2.5、弹性扩展:扩存储,业务“0”感知
- 2.6、分级存储:自动化冷热交替,应用“0”改造
- 2.7、高可靠:Region 内 3AZ 容灾,跨 Region 双活
- 三、GeminiDB 多模融合引擎
-
- 3.1、生态兼容,层次解耦,数据融合
- 3.2、GeminiDB Redis 接口:提供稳定低时延
- 3.3、GeminiDB Mongo 接口:大容量&强一致
- 3.4、GeminiDB Cassandra 接口:类 SQL 语法
-
- 3.4.1、增强索引
- 3.4.2、数据通道
- 3.4.3、全局索引
- 3.5、GeminiDB DynamoDB 接口:助力 DynamoDB 客户平滑迁移
- 3.6、GeminiDB Influx 接口:时空数据存、算、析一体平台
- 四、GeminiDB 典型应用场景
-
- 4.1、GeminiDB 携手迷你创想开启全民创作的新时代
- 4.2、GeminiDB 支撑 RTA 广告业务快速上线
- 4.3、GeminiDB 助力数字娱乐巨头客户 DynamoDB 迁移
- 4.4、GeminiDB 助力华为终端云打造体验天花板
- 4.5、GeminiDB 助力 loT 场景数据分析实现万物互联
- 总结
前言
在本文中我们联合华为云 NoSQL 数据库研发总监余汶龙,与您一起探讨华为云多模数据库 GeminiDB 的技术架构,以及它们如何革新当代应用的数据处理方式,内容包括介绍云原生分布式多模架构,四种数据模型接口及其竞争力特性,GeminiDB 的应用场景:游戏、监控、智慧生活、无损迁移。一、GeminiDB 总体介绍
1.1、华为云数据库全景图
华为云数据库目前在各行各业得到了市场上的广泛认可,包括中国一汽其 ERP 核心系统使用的是华为云数据库,永安保险理赔系统使用的是华为云数据库,其他如电商平台、游戏厂商等等,当然也有银行的一些核心系统,如信用卡等,那么华为云数据库主要分成哪几个部分呢?具体如下图所示:
华为云数据库主要分成三个部分,首先底层是迁移工具,能够支持用户平滑上云,上一层是开源托管数据库,最上层是自研数据库,其中 GeminiDB 是我们本文内容的重点,它是一款由 KV、文档、宽表和时序组成的一个超融合的多模数据库。
1.2、GeminiDB 发展历程
GeminiDB 引领 NoSQL 存算分离架构,持续战略投入,打造世界级数据库,GeminiDB 发展历程具体如下图所示:

结合 GeminiDB 发展历程,我们将其成就归纳为以下几点:
- 国内第一款:存算分离架构 NoSQL 数据库。
- 100% 兼容:5 款最热门生态,Redis、MongoDB、Cassandra、DynamoDB、InfluxDB。
- 0 秒 RPO:3AZ 高可用实例,0 秒 RPO,数据“0”丢失。
- RTO 10 秒:实例故障恢复,RTO 10 秒内完成。
- 99.995% SLA:高可用双活实例承诺,99.995% SLA,服务可用性保证远超国内其他厂商。
1.3、GeminiDB 全球分布情况
GeminiDB 全球一张网布局,服务全球客户,具体如下图所示:
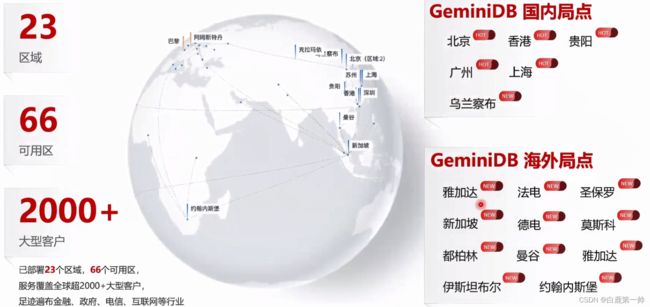
如上图所示,当前 GeminiDB 已经分布在全球 23 个 Region,有 66 个可用区,共服务了全球 2000 多家大型企业,包括那个互联网金融、政府、电信等,当前在国内主要局点涵盖北、上、广、深等主流 Region,在海外主要有中东、亚太、欧洲及美洲。
二、GeminiDB 云原生架构
2.1、核心设计:存算分离&多模扩展
GeminiDB 云原生架构设计的核心分为存算分离和多模扩展两个部分,具体如下图所示:
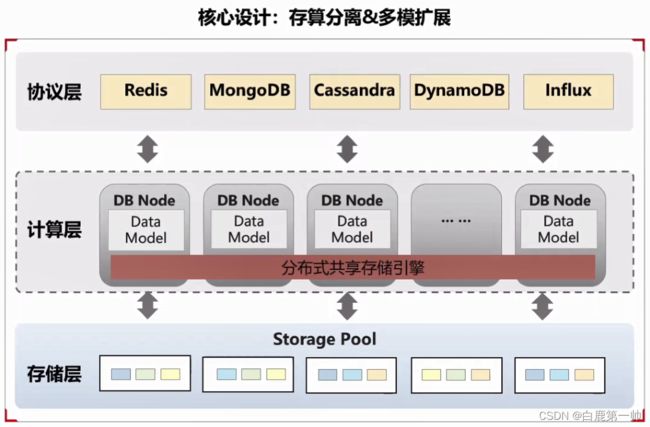
数据库的存算分离是指将数据库的存储和计算功能分离开来,分别由不同的组件来完成。通过将存储和计算功能分开,实现了更高的灵活性和扩展性。具体来说,存储功能由存储引擎(Storage Engine)来完成,计算功能由计算引擎(Compute Engine)来完成,存储引擎负责数据的读写和存储,计算引擎负责数据的查询和计算,两者之间通过接口进行通信和协作。在这套架构之上,我们就可以快速扩展多种协议支持,如 Redis、MongoDB、Cassandra、DynamoDB、InfluxDB。
2.2、存算分离&多模扩展核心优势
我们对于 GeminiDB 云原生架构的优势进行展开如下:
- 高可用:故障 “秒级” 接管,容忍 N-1 个节点故障。
- 弹性扩展:扩容速度比开源自建提升百倍。
- 分级存储:冷热分离,应用 “0” 改造。
- 高可靠:集群 3AZ 容灾,跨 Region 双活。
2.3、高可用:秒级故障接管
一个 GeminiDB 是一个分布式集群,包含了多个节点,下图示例中,包含三个节点,假设节点二和三出现任何意外,挂掉之后,负载可能很低,但也有可能出现故障情况,这时在 GeminiDB 中不需要搬迁数据,只需要改一个个路由表,具体如下图所示:
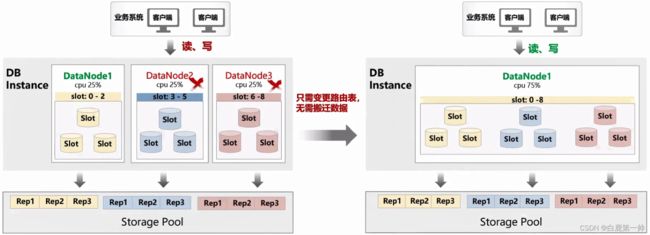
这里的 Slot 信息代表一个路由信息,我们可以看到节点 1 负责 0-2,节点 2 负责 3-5,节点 3 负责 6-8,当节点 2 和 3 挂掉之后,它们所负责 Slot 信息都会迁移给节点 1,这个过程不需要数据搬迁,只需要路由表修改,速度会非常的快,可以做到秒级接管;同时,活着的节点能够提供所有的服务,底层共享一个存储,节点 1 可以看见节点 2 和节点 3 维护的数据,实现容忍 N-1 个节点故障。
2.4、弹性扩展:扩计算,业务仅秒级抖动
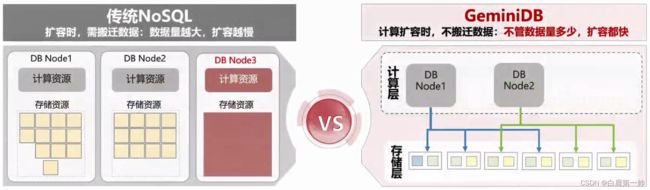
我们把数据库扩展分成计算和存储两层。传统 NoSQL 在扩容时,不管是算力不够,还是数据量不够,都需要加一个节点,那就难免搬迁数据,下图展示了从节点 1 和节点 2 搬迁数据到节点 3 的过程,这个过程是很慢的,具体如下图所示:
在下图中我们可以看到,在开始阶段,OPS 和时延都是稳定的,但是在数据搬迁过程中可以看到它的延迟是上下波动的,在业务影响方面,吞吐也是上下波动的,并且整个过程持续时间非常久,结束之后才会进入平稳状态,具体如下图所示:

而 GeminiDB 扩容分为两种,首先是计算扩容,增加一条路由信息,把以前节点的路由信息分配给新的 DataNode3,可以看见底下的数据,完成计算分钟级扩容,具体如下图所示:
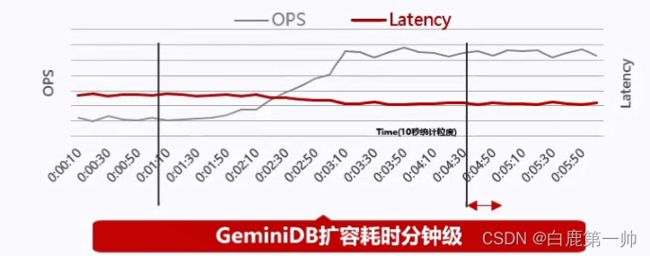
整个扩容过程中,在上图我们可以看到红色的线,时延是没有大的变化的。扩容之后时延下降了一点,算力得到了提升。OPS 也是一个线性的增长过程,分钟级就可以完成 1 个节点添加。
2.5、弹性扩展:扩存储,业务“0”感知
下图黄色线是某一个实例的存储上限,绿色线是业务数据的每天变化,可以看到业务数据每天都在增加,当到达拐点的时候,已经接近容量上限,如果不扩容就会进入那个只读状态,具体如下图所示:

这个时候,GeminiDB 扩容一键就可以完成,完全不影响业务。在存仓分离架构下,存储扩容对于我们来说就是调整配额的一个参数,当前 GeminiDB 可以满足用户 4GB-36TB 的平滑扩缩容。最新版本里已经支持自动扩容,用户在购买界面如果勾选自动扩容,当用户的数据量达到一定比例、配额的时候,根本不需要用户关心容量大小。
2.6、分级存储:自动化冷热交替,应用“0”改造
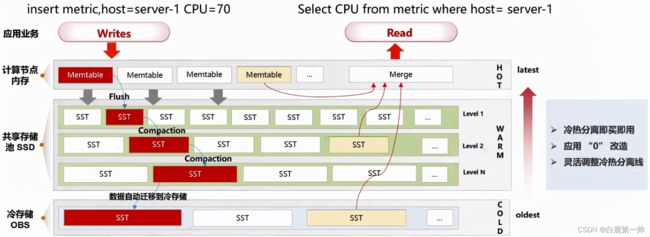
我们以 Influx 的一条插入语句为例,语句如下:
insert metric,host = server - 1 CPU = 70
插入过程从内存到分布式存储,同步插入过程中,会根据用户的配置参数,如定义热数据的时间,超过一定时间,就定义成冷数据,在异步过程中把数据推到远端的 obs 上,obs 对我们来说是冷存储,保证用户在共享存储中的热数据控制在一定范围内,节省用户存储成本。
我们以 Influx 的一条查询语句为例,语句如下:
Select CPU from metric where host = server - 1
在读的过程中,根据用户的输入,自动去存储做集合查询,把需要的结果返回给用户。
“冷热分离”,即买即用,当用户购买 GeminiDB 的时候,用户可以选择是否开启冷存储,同时冷存储的空间的范围也可以选定,在创建一张表的时候,指定好数据到期时间,如一周或者是一月,当数据插进来超过一周,定义为冷数据,整个过程对于用户“0”改造。
2.7、高可靠:Region 内 3AZ 容灾,跨 Region 双活
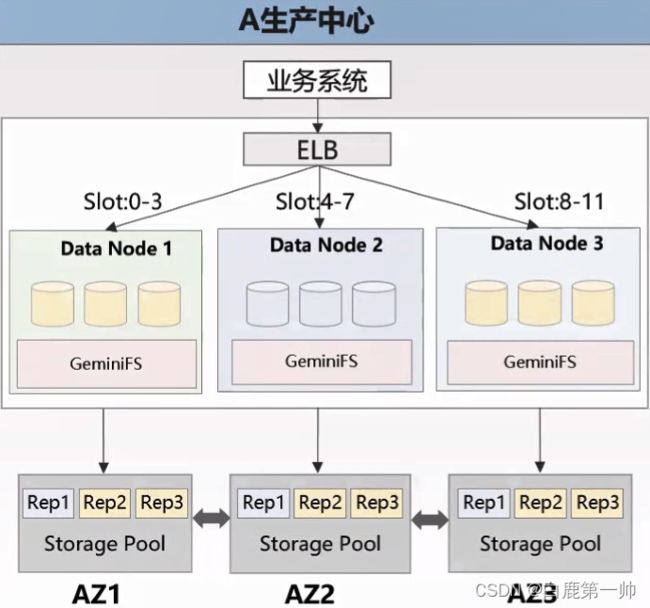
GeminiDB 高可靠实现分为两种,一种是单个 Region 内 3AZ 容灾,另一种是两个 Region 间的容灾。
单个 Region 内 3AZ 容灾,GeminiDB 支持 3AZ 可靠,计算和存储都是 3AZ 均衡分布的,用户购买的 3AZ 节点数大于 3 的时候,会将其均匀分布到不同 AZ 上,其中一个机房的计算、存储或者计算存储同时掉电,都能实现防御故障,不会影响整个实例的可靠性和可用性,数据既不会丢,可用性也不会下降。单个 Region 内 3AZ 容灾,具体如下图所示:
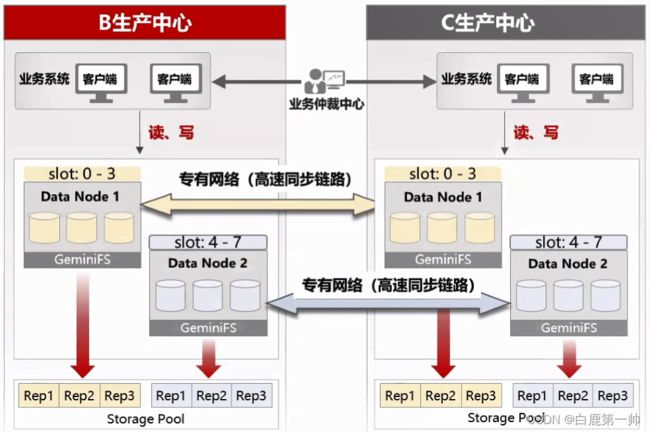
两个 Region 间的容灾,已经实现了 GeminiDB 两个实例间的数据复制,可以做到保序、断点序传,同时支持冲突解决。即在下图中,当用户从 B 中心写入一个数据,可以同步到 C 中心,C 中心写入的数据也可以同步到 B 中心。也就是说当一个 Region 级别的故障,如 B 中心发生故障,业务可以切到 B 中心实现熔灾。两个 Region 间的容灾,具体如下图所示:
三、GeminiDB 多模融合引擎
3.1、生态兼容,层次解耦,数据融合
GeminiDB 支持四种模型,主要有 KV 模型、文档模型、宽表模型和时序模型,表现在用户层面接口是五种,分别是 Redis 接口、MongoDB 接口、Cassandra 接口、DynamoDB 接口、Influx 接口,引擎层主要有 KV 引擎、搜索引擎和文档引擎,最底下就是存储层,具体如下图所示:

3.2、GeminiDB Redis 接口:提供稳定低时延
GeminiDB Redis 接口:提供稳定低时延,适用于广告、游戏场景。
- 无缝兼容:100% 兼容 Redis 协议,支持主备、集群。可轻松替代自建 Redis、自建 Pika,帮助 DBA 实现降本增效。
- 能力增强:提供 GeminiDB 独有特性,为业务开发提供更优解决方案。如 FastLoad 特征灌库、PITR 游戏回档、异地双活客灾、多租权限局离、布隆过滤器 Hash Field 过期等。
应用在广告场景的 FastLoad ,能够帮助用户一键式从 Hadoop、Spark 等大数据系统,一键导入到 GeminiDB 中,由 GeminiDB 提供给上游业务实现实时查询,具体如下图所示:
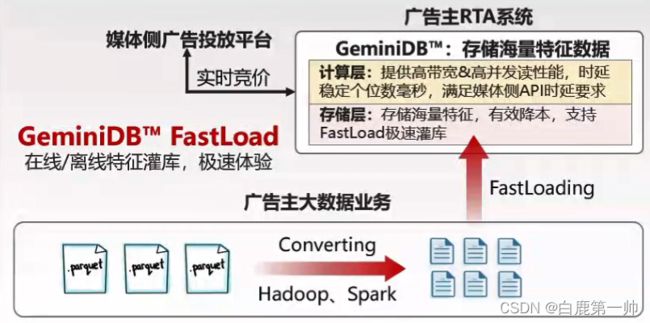
广告营销、个性推荐等业务对时延敏感,也注重存储成本。对此类 AI 业务中 GeminiDB 是作为特征画像数据库的最佳选型:
- 性能稳定:10Gbit/s 超高带宽,时延平稳 p99~2ms;CPU 算力可弹性扩展。
- 存储降本:NVMe 分布式存储,叠加双重数据压缩,带来明确可见的成本节约。
- 功能增强:FastLoad 可实现海量数据极速灌库;Hash 数据可设置 field 过期。
PITR 游戏回档广泛应用于游戏场景,游戏场景中,如发版或者变更,经常需要把对应的数据库回挡到某一个时间点,GeminiDB 支持五分钟粒度的时间片回档,用户需要回荡到任意时间都可以在控制台上完成操作,并且支持原地回档,具体如下图所示:
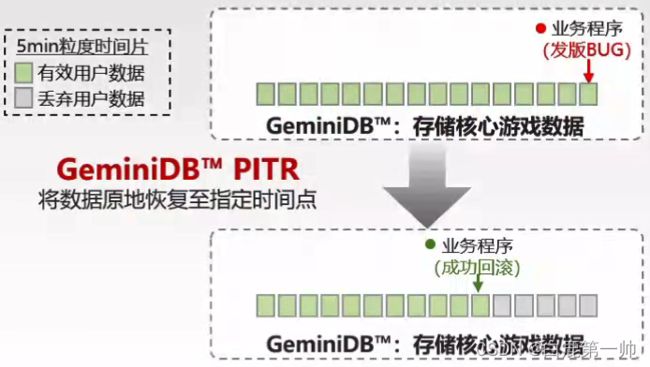
游戏业务场景丰富,好友链、聊天、抢红包、排行榜…强依赖 Redis 丰富数据结构,同时对数据回档有诉求。GeminiDBm 提供游戏全服解决方案:
- 简化架构:自带可靠存储+缓存加速,可替代 DB+ Cache。
- 透明化开发:100% 兼容 Redis 全命令,开发当做普通 Redis 数据库使用即可。
- PITR 数据闪回:支持在游戏发版失误时快速回档到任意时间点,5min 粒度。
3.3、GeminiDB Mongo 接口:大容量&强一致
GeminiDB Mongo 接口:大容量&强一致,适用于互联网、游戏、社交。
- 兼容生态:100% 兼容 MongoDB 协议,可支持超大容量 96TB,提供副本集部署,并具备服务化迁移能力。
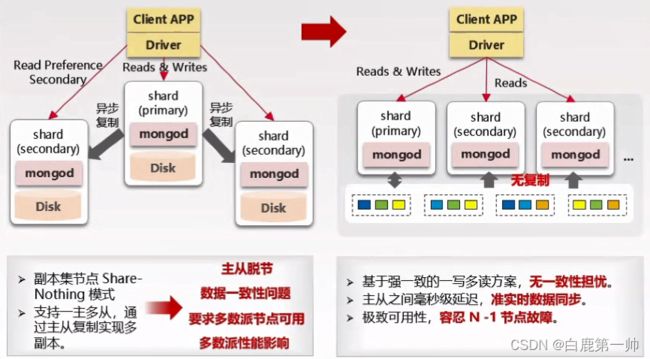
极速扩容:计算节点可极速增加多个只读节点,分钟级完成读节点扩展。存储资源秒级扩容,业务平滑无感知,具体如下图所示:

数据和服务高可靠:基于强一致一写多读消除 Read/Write Concern 的性能影响;主从同步毫秒级稳定延迟,彻底解决主从脱节问题;容忍 N-1 节点故障,依旧保持全量服务可用性,具体如下图所示:
3.4、GeminiDB Cassandra 接口:类 SQL 语法
GeminiDB Cassandra 接口:类 SQL 语法,适用于海量宽表存储场景。
- 兼容生态:100% 兼容 Cassandra 协议;类 SQL 语法,开发体验类似 MySQL。
- 能力增强:索引能力增强,轻松应对海量数据复杂查询场景;数据秒级闪回、PITR 等数据恢复能力,构筑极高的数据可靠性。
- 超高性能:2 倍读写性能提升;最高可支持 PB 级存储。
3.4.1、增强索引
增强索引,具体如下图所示:
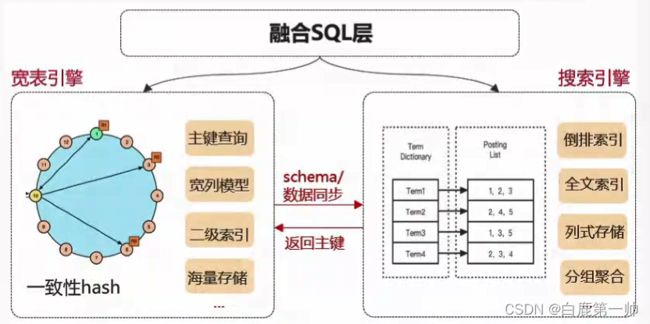
关键技术点:
- 内嵌 Lucene 搜索引擎,与存储引擎搭配,实现宽表存储引擎与搜索引擎的深度融合。
- SQL 层统一融合,在兼容原生 Cassandra 语法基础上,提供多维查询、文本检索、模糊查询统计分析等能力,全面提升用户在海量数据场景下的查询体验。
3.4.2、数据通道
数据通道,具体如下图所示:

关键技术点:
- Cassandra 流表特性,用于实时分析数据变化对标 AWS Stream 功能。
- 与大数据结合增强离线分析能力,效率提升 60%。
3.4.3、全局索引
全局索引,具体如下图所示:
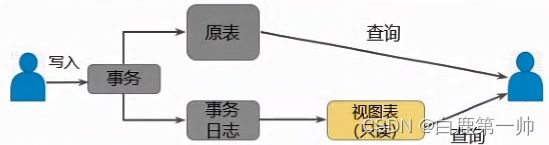
关键技术点:
- 在原生 Cassandra 基础上对物化视图特性进行了增强,支持复合主键视图查询场景更丰富。
- 通过事务日志保证视图数据与原表数据的最终一致性。
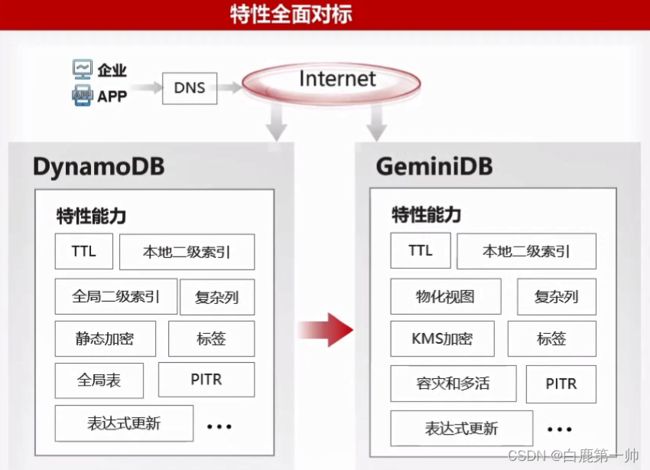
3.5、GeminiDB DynamoDB 接口:助力 DynamoDB 客户平滑迁移
- 能力平替:100% 兼容 DynamoDB 协议和数据模型,关键特性全面对标。
- 平滑迁移:迁移过程不需要业务任何改造;支持全量+增量迁移,业务无需停服;反向数据同步,业务可随时回切。
- 低成本:在相同读写性能下,成本降低 50%,数据量越大成本降低越明显。
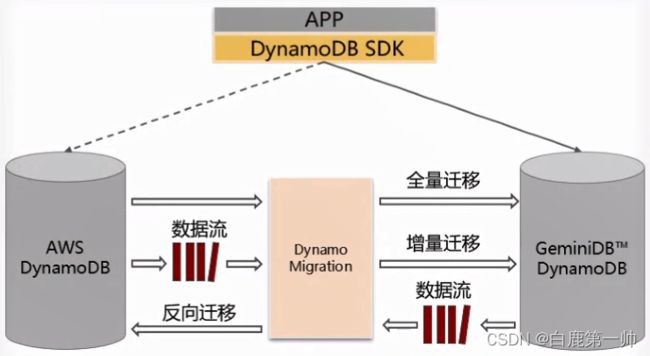
关键技术点:
- 无缝对接:协议全面兼容,业务无需改造。
- 无需停服:全量+增量迁移能力,助力平滑迁移,业务滚动切流即可。
- 无损回切:反向增量迁移能力,业务可随时回切,数据无丢失风险。
3.6、GeminiDB Influx 接口:时空数据存、算、析一体平台
GeminiDB Influx 接口:时空数据存、算、析一体平台,广泛用于 IoT 场景。
- 无缝兼容:100% 兼容 InfluxDB 协议,支持单机版、集群。可轻松替代自建 InfluxDB,提供更强的性能和更高的服务可用性。
- 能力增强:自适应压缩算法、多维时序索引、向量化 MPP 查询引擎、定制化聚合运算和 Rollup Cache 等,为业务开发提供更优解决方案。
四、GeminiDB 典型应用场景
4.1、GeminiDB 携手迷你创想开启全民创作的新时代


- 全球部署:全球 23 区域支持资源快速下发。
- 高性能:性能 5 倍提升,0.1ms 稳定无抖轻松支撑千万级玩家在线。
- 高可靠:数据强一致,TB 级地图数据实时同步更新。
- 快速安全扩容:秒级存储扩容,轻松应对 20X 轻业务高峰变化。
4.2、GeminiDB 支撑 RTA 广告业务快速上线
RTA(Realtime API)广告业务模式,用于满足广告主实时个性化的投放需求,在竞价中减少资金浪费,具体如下图所示:

- 稳定高效:稳定性远超开源缓存 Redis,业务运行更高效。
- 低成本:大容量的稳定存储,存储百 GB~数 TB 画像数据,成本比开源缓存 Redis 节约 50%。
- 低时延:数 + 万 QPS 流量,平均时延 1ms,p99 时延 2ms,保障终端用户丝滑体验。
4.3、GeminiDB 助力数字娱乐巨头客户 DynamoDB 迁移
客户旗下的多款 APP 全球累计安装用户数近 24 亿,覆盖 200 多个国家和地区,是全球领先的数字娱乐内容平台,具体如下图所示:
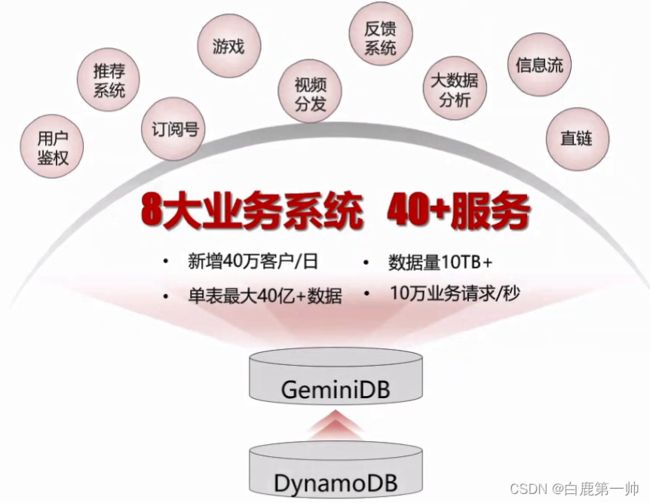
- 高性能、高可靠:性能得到 2 倍提升、数据强一致。
- 低成本:成本平均降低 40%。
- 快速安全扩容:分钟级计算扩容、秒级存储扩容。
- 海量数据:集群规模 2000 核,单套实例最大 100TB 数据。
4.4、GeminiDB 助力华为终端云打造体验天花板
GeminiDB 助力华为终端云打造体验天花板,具体如下图所示:

- 总节点数 11000+。
- 总数据量 10PB+。
- 单集群最大 600 节点。
- 单集群 10万+ 并发响应。
- 单集群数据量最大 100TB。
- 跨 AZ 双活 RTO<10S、RPO=0。
- 跨 Region 多活 RPO<10s、实例级可用度 5 个 9。
- 分钟级计算扩容。
- 秒级存储扩容。
4.5、GeminiDB 助力 loT 场景数据分析实现万物互联
GeminiDB 助力 loT 场景数据分析实现万物互联,具体如下图所示:

- 海量设备管理:轻松支持亿级别设备管理。
- 专用压缩算法:压缩率提升 10X+。
- 高速并行写入:写性能提升 2X+,计算成本降低 30%。
- 成本降低:支持冷热分离存储,成本降低 80%。
总结
在这个信息爆炸的时代,数据的管理和应用变得越来越重要,多模数据库作为一种新兴的数据管理解决方案,正受到越来越多的关注。GeminiDB 的技术架构到底是什么,支持什么样的接口,又是如何同时支持多种数据模型,技术特征有哪些,适用于什么样的场景呢,通过本文我们详细了解了华为云云原生多模数据库 GeminiDB 架构与应用实践。
我是白鹿,一个不懈奋斗的程序猿。望本文能对你有所裨益,欢迎大家的一键三连!若有其他问题、建议或者补充可以留言在文章下方,感谢大家的支持!