数据库-PostgreSQL搭建PgPool-II集群
测试环境:
172.16.212.61,主机名master
172.16.212.62,主机名slave
172.16.212.100,VIP
1 安装和基本配置
所有主机,安装postgresql 11.8
yum -y install https://download.postgresql.org/pub/repos/yum/11/redhat/rhel-7-x86_64/pgdg-redhat-repo-42.0-11.noarch.rpm
yum -y install postgresql11 postgresql11-libs postgresql11-server
所有主机,安装pgpool 4.1.1
yum install http://www.pgpool.net/yum/rpms/4.1/redhat/rhel-7-x86_64/pgpool-II-release-4.1-1.noarch.rpm -y
yum install pgpool-II-pg11-* -y
所有主机,初始化数据库
/usr/pgsql-11/bin/postgresql-11-setup initdb
systemctl start postgresql-11
systemctl enable postgresql-11
/usr/pgsql-11/bin/psql -V
所有主机上postgresql数据库的基本配置,/var/lib/pgsql/11/data/postgresql.conf
listen_addresses = '*'
shared_buffers = 128MB
wal_level = replica
wal_log_hints = on
archive_mode = on
archive_command = 'cp "%p" "/var/lib/pgsql/archivedir/%f"'
max_wal_senders = 10
max_replication_slots = 10
hot_standby = on
log_directory = 'log'
log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log'
所有主机上修改postgres用户的密码并添加用于记录wal日志的文件夹
passwd postgres
su - postgres
mkdir /var/lib/pgsql/archivedir
所有主机,修改认证信息,/var/lib/pgsql/11/data/pg_hba.conf
local all all trust
host all all 127.0.0.1/32 ident
host all all 172.16.212.61/32 md5
host all all 172.16.212.62/32 md5
host all all ::1/128 ident
local replication all trust
host replication all 127.0.0.1/32 ident
host replication all ::1/128 ident
host replication all 172.16.212.61/32 md5
host replication all 172.16.212.62/32 md5
所有主机,配置ssh认证
cd ~/.ssh
ssh-keygen -t rsa -f id_rsa_pgpool
ssh-copy-id -i id_rsa_pgpool.pub postgres@master
ssh-copy-id -i id_rsa_pgpool.pub postgres@slave
su - postgres
cd ~/.ssh
ssh-keygen -t rsa -f id_rsa_pgpool
ssh-copy-id -i id_rsa_pgpool.pub postgres@master
ssh-copy-id -i id_rsa_pgpool.pub postgres@slave
所有主机,创建认证文件,/var/lib/pgsql/.pgpass
su - postgres
vim /var/lib/pgsql/.pgpass
master:5432:replication:pgpool:pgpool
slave:5432:replication:pgpool:pgpool
master:5432:postgres:postgres:postgres
slave:5432:postgres:postgres:postgres
master:5432:replication:repl:repl
slave:5432:replication:repl:repl
chmod 600 /var/lib/pgsql/.pgpass
master主机,创建数据库用户和密码
psql -U postgres -p 5432
postgres=# SET password_encryption = 'md5';
postgres=# CREATE ROLE pgpool WITH LOGIN;
postgres=# CREATE ROLE repl WITH REPLICATION LOGIN;
postgres=# \password pgpool
postgres=# \password repl
postgres=# \password postgres
postgres=# GRANT pg_monitor TO pgpool;
2 集群简介
3 配置pgpool
3.1 所有pgpool节点的共同配置
cp -p /etc/pgpool-II/pgpool.conf.sample-stream /etc/pgpool-II/pgpool.conf
#通用配置
listen_addresses = '*'
sr_check_user = 'pgpool'
sr_check_password = ''
health_check_period = 5
health_check_timeout = 30
health_check_user = 'pgpool'
health_check_password = ''
health_check_max_retries = 3
backend_hostname0 = 'master'
backend_port0 = 5432
backend_weight0 = 1
backend_data_directory0 = '/var/lib/pgsql/11/data'
backend_flag0 = 'ALLOW_TO_FAILOVER'
backend_application_name0 = 'master'
backend_hostname1 = 'slave'
backend_port1 = 5432
backend_weight1 = 1
backend_data_directory1 = '/var/lib/pgsql/11/data'
backend_flag1 = 'ALLOW_TO_FAILOVER'
backend_application_name1 = 'slave'
enable_pool_hba = on
use_watchdog = on
delegate_IP = '172.16.212.100'
if_up_cmd = '/usr/bin/sudo /sbin/ip addr add $_IP_$/24 dev ens33 label ens33:0'
if_down_cmd = '/usr/bin/sudo /sbin/ip addr del $_IP_$/24 dev ens33'
arping_cmd = '/usr/bin/sudo /usr/sbin/arping -U $_IP_$ -w 1 -I ens33'
wd_hostname = '本机的主机名/IP' //比如,master主机填master,slave主机填slave
wd_port = 9000
other_pgpool_hostname0 = '写集群中其他节点的主机名' //比如,master主机就写 slave,slave主机就写master
other_pgpool_port0 = 9999
other_wd_port0 = 9000
heartbeat_destination0 = '写集群中其他节点的主机名' //比如,master主机就写 slave,slave主机就写master
heartbeat_destination_port0 = 9694
heartbeat_device0 = 'ens33'
log_destination = 'syslog'
syslog_facility = 'LOCAL1'
3.2 master主机Failover
1)/etc/pgpool-II/pgpool.conf
#master主机
failover_command = '/etc/pgpool-II/failover.sh %d %h %p %D %m %H %M %P %r %R %N %S'
#slave主机,没有该设置
#failover_command = '/etc/pgpool-II/failover.sh %d %h %p %D %m %H %M %P %r %R %N %S'
2)脚本内容
vi /etc/pgpool-II/failover.sh
#!/bin/bash
# This script is run by failover_command.
set -o xtrace
exec > >(logger -i -p local1.info) 2>&1
# Special values:
# %d = failed node id
# %h = failed node hostname
# %p = failed node port number
# %D = failed node database cluster path
# %m = new master node id
# %H = new master node hostname
# %M = old master node id
# %P = old primary node id
# %r = new master port number
# %R = new master database cluster path
# %N = old primary node hostname
# %S = old primary node port number
# %% = '%' character
FAILED_NODE_ID="$1"
FAILED_NODE_HOST="$2"
FAILED_NODE_PORT="$3"
FAILED_NODE_PGDATA="$4"
NEW_MASTER_NODE_ID="$5"
NEW_MASTER_NODE_HOST="$6"
OLD_MASTER_NODE_ID="$7"
OLD_PRIMARY_NODE_ID="$8"
NEW_MASTER_NODE_PORT="$9"
NEW_MASTER_NODE_PGDATA="${10}"
OLD_PRIMARY_NODE_HOST="${11}"
OLD_PRIMARY_NODE_PORT="${12}"
PGHOME=/usr/pgsql-11
logger -i -p local1.info failover.sh: start: failed_node_id=$FAILED_NODE_ID old_primary_node_id=$OLD_PRIMARY_NODE_ID failed_host=$FAILED_NODE_HOST new_master_host=$NEW_MASTER_NODE_HOST
## If there's no master node anymore, skip failover.
if [ $NEW_MASTER_NODE_ID -lt 0 ]; then
logger -i -p local1.info failover.sh: All nodes are down. Skipping failover.
exit 0
fi
## Test passwrodless SSH
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@${NEW_MASTER_NODE_HOST} -i ~/.ssh/id_rsa_pgpool ls /tmp > /dev/null
if [ $? -ne 0 ]; then
logger -i -p local1.info failover.sh: passwrodless SSH to postgres@${NEW_MASTER_NODE_HOST} failed. Please setup passwrodless SSH.
exit 1
fi
## If Standby node is down, skip failover.
if [ $FAILED_NODE_ID -ne $OLD_PRIMARY_NODE_ID ]; then
logger -i -p local1.info failover.sh: Standby node is down. Skipping failover.
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@$OLD_PRIMARY_NODE_HOST -i ~/.ssh/id_rsa_pgpool "
${PGHOME}/bin/psql -p $OLD_PRIMARY_NODE_PORT -c \"SELECT pg_drop_replication_slot('${FAILED_NODE_HOST}')\"
"
if [ $? -ne 0 ]; then
logger -i -p local1.error failover.sh: drop replication slot "${FAILED_NODE_HOST}" failed
exit 1
fi
exit 0
fi
## Promote Standby node.
logger -i -p local1.info failover.sh: Primary node is down, promote standby node ${NEW_MASTER_NODE_HOST}.
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null \
postgres@${NEW_MASTER_NODE_HOST} -i ~/.ssh/id_rsa_pgpool ${PGHOME}/bin/pg_ctl -D ${NEW_MASTER_NODE_PGDATA} -w promote
if [ $? -ne 0 ]; then
logger -i -p local1.error failover.sh: new_master_host=$NEW_MASTER_NODE_HOST promote failed
exit 1
fi
logger -i -p local1.info failover.sh: end: new_master_node_id=$NEW_MASTER_NODE_ID started as the primary node
exit 0
3.3 master主机配置Online Recovery
1)/etc/pgpool-II/pgpool.conf
#master主机
recovery_user = 'postgres'
recovery_password = 'postgres'
recovery_1st_stage_command = 'recovery_1st_stage'
#slave主机,无特殊配置,默认即可
2)创建相应脚本
su - postgres
touch /var/lib/pgsql/11/data/recovery_1st_stage
touch /var/lib/pgsql/11/data/pgpool_remote_start
chmod +x /var/lib/pgsql/11/data/{recovery_1st_stage,pgpool_remote_start}
3)recovery_1st_stage脚本内容
#!/bin/bash
# This script is executed by "recovery_1st_stage" to recovery a Standby node.
set -o xtrace
exec > >(logger -i -p local1.info) 2>&1
PRIMARY_NODE_PGDATA="$1"
DEST_NODE_HOST="$2"
DEST_NODE_PGDATA="$3"
PRIMARY_NODE_PORT="$4"
DEST_NODE_ID="$5"
DEST_NODE_PORT="$6"
PRIMARY_NODE_HOST=$(hostname)
PGHOME=/usr/pgsql-11
ARCHIVEDIR=/var/lib/pgsql/archivedir
REPLUSER=repl
logger -i -p local1.info recovery_1st_stage: start: pg_basebackup for Standby node $DEST_NODE_ID
## Test passwrodless SSH
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@${DEST_NODE_HOST} -i ~/.ssh/id_rsa_pgpool ls /tmp > /dev/null
if [ $? -ne 0 ]; then
logger -i -p local1.info recovery_1st_stage: passwrodless SSH to postgres@${DEST_NODE_HOST} failed. Please setup passwrodless SSH.
exit 1
fi
## Get PostgreSQL major version
PGVERSION=`${PGHOME}/bin/initdb -V | awk '{print $3}' | sed 's/\..*//' | sed 's/\([0-9]*\)[a-zA-Z].*/\1/'`
if [ $PGVERSION -ge 12 ]; then
RECOVERYCONF=${DEST_NODE_PGDATA}/myrecovery.conf
else
RECOVERYCONF=${DEST_NODE_PGDATA}/recovery.conf
fi
## Create replication slot "${DEST_NODE_HOST}"
${PGHOME}/bin/psql -p ${PRIMARY_NODE_PORT} << EOQ
SELECT pg_create_physical_replication_slot('${DEST_NODE_HOST}');
EOQ
## Execute pg_basebackup to recovery Standby node
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@$DEST_NODE_HOST -i ~/.ssh/id_rsa_pgpool "
set -o errexit
rm -rf $DEST_NODE_PGDATA
rm -rf $ARCHIVEDIR/*
${PGHOME}/bin/pg_basebackup -h $PRIMARY_NODE_HOST -U $REPLUSER -p $PRIMARY_NODE_PORT -D $DEST_NODE_PGDATA -X stream
if [ ${PGVERSION} -ge 12 ]; then
sed -i -e \"\\\$ainclude_if_exists = '$(echo ${RECOVERYCONF} | sed -e 's/\//\\\//g')'\" \
-e \"/^include_if_exists = '$(echo ${RECOVERYCONF} | sed -e 's/\//\\\//g')'/d\" ${DEST_NODE_PGDATA}/postgresql.conf
fi
cat > ${RECOVERYCONF} << EOT
primary_conninfo = 'host=${PRIMARY_NODE_HOST} port=${PRIMARY_NODE_PORT} user=${REPLUSER} application_name=${DEST_NODE_HOST} passfile=''/var/lib/pgsql/.pgpass'''
recovery_target_timeline = 'latest'
restore_command = 'scp ${PRIMARY_NODE_HOST}:${ARCHIVEDIR}/%f %p'
primary_slot_name = '${DEST_NODE_HOST}'
EOT
if [ ${PGVERSION} -ge 12 ]; then
touch ${DEST_NODE_PGDATA}/standby.signal
else
echo \"standby_mode = 'on'\" >> ${RECOVERYCONF}
fi
sed -i \"s/#*port = .*/port = ${DEST_NODE_PORT}/\" ${DEST_NODE_PGDATA}/postgresql.conf
"
if [ $? -ne 0 ]; then
${PGHOME}/bin/psql -p ${PRIMARY_NODE_PORT} << EOQ
SELECT pg_drop_replication_slot('${DEST_NODE_HOST}');
EOQ
logger -i -p local1.error recovery_1st_stage: end: pg_basebackup failed. online recovery failed
exit 1
fi
logger -i -p local1.info recovery_1st_stage: end: recovery_1st_stage complete
exit 0
4)pgpool_remote_start脚本内容
#!/bin/bash
# This script is run after recovery_1st_stage to start Standby node.
set -o xtrace
exec > >(logger -i -p local1.info) 2>&1
PGHOME=/usr/pgsql-11
DEST_NODE_HOST="$1"
DEST_NODE_PGDATA="$2"
logger -i -p local1.info pgpool_remote_start: start: remote start Standby node $DEST_NODE_HOST
## Test passwrodless SSH
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@${DEST_NODE_HOST} -i ~/.ssh/id_rsa_pgpool ls /tmp > /dev/null
if [ $? -ne 0 ]; then
logger -i -p local1.info pgpool_remote_start: passwrodless SSH to postgres@${DEST_NODE_HOST} failed. Please setup passwrodless SSH.
exit 1
fi
## Start Standby node
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@$DEST_NODE_HOST -i ~/.ssh/id_rsa_pgpool "
$PGHOME/bin/pg_ctl -l /dev/null -w -D $DEST_NODE_PGDATA start
"
if [ $? -ne 0 ]; then
logger -i -p local1.error pgpool_remote_start: $DEST_NODE_HOST PostgreSQL start failed.
exit 1
fi
logger -i -p local1.info pgpool_remote_start: end: $DEST_NODE_HOST PostgreSQL started successfully.
exit 0
5)master主机上需要在template1上安装用于recovery的模版
su - postgres
psql template1 -c "CREATE EXTENSION pgpool_recovery"
3.4 所有主机,配置认证
/etc/pgpool-II/pool_hba.conf
local all all trust
host all all 127.0.0.1/32 trust
host all all ::1/128 trust
host all all 172.16.212.0/24 md5
/etc/pgpool-II/pool_passwd
pg_md5 -p -m -u postgres pool_passwd
pg_md5 -p -m -u pgpool pool_passwd
#会生成密码文件
cat /etc/pgpool-II/pool_passwd
postgres:md53175bce1d3201d16594cebf9d7eb3f9d
pgpool:md5f24aeb1c3b7d05d7eaf2cd648c307092
3.5 所有主机,/etc/sysconfig/pgpool Configuration
OPTS=" -D -n"
3.6 所有主机,配置日志
mkdir /var/log/pgpool-II
touch /var/log/pgpool-II/pgpool.log
vi /etc/rsyslog.conf
LOCAL1.* /var/log/pgpool-II/pgpool.log
vi /etc/logrotate.d/syslog
/var/log/pgpool-II/pgpool.log
systemctl restart rsyslog
3.7 所有主机,配置pcp
echo 'pgpool:'`pg_md5 pgpool` >> /etc/pgpool-II/pcp.conf
echo 'localhost:9898:pgpool:pgpool' > ~/.pcppass
chmod 600 ~/.pcppass
3.8 管理pgpool
systemctl start pgpool.service
systemctl stop pgpool.service
3.9 功能验证用到的命令
pcp_recovery_node -h 172.16.212.100 -p 9898 -U pgpool -n 1
pcp_watchdog_info -h 172.16.212.100 -p 9898 -U pgpool
psql -h 172.16.212.100 -p 9999 -U pgpool postgres -c "show pool_nodes"
pg_ctl -D /var/lib/pgsql/11/data -m immediate stop
psql -h slave -p 5432 -U pgpool postgres -c "select pg_is_in_recovery()"
4 功能验证
4.1 pgpool服务状态
master主机:
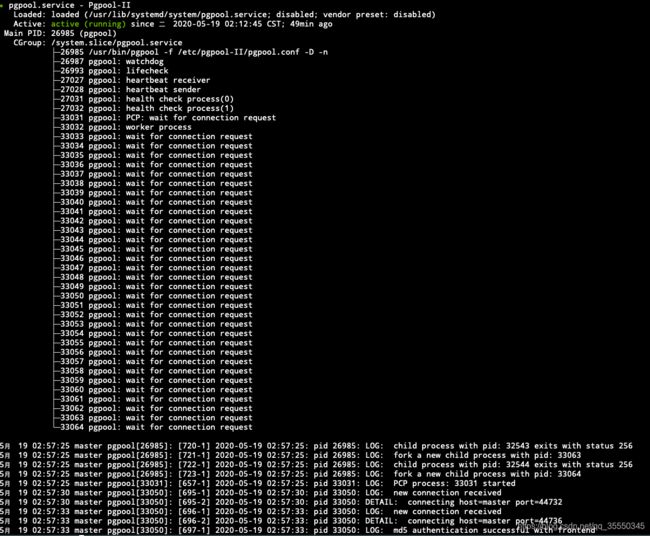
slave主机:

4.2 模拟primary节点故障,将standby节点提升为primary节点
当前状态:master主机即为primary节点

故障模拟:停止master主机的postgresql

slave主机已经变成了primary节点,测试一下是否可写——可以
启动master主机的postgresql数据库,然后
将处于down状态的standby节点恢复正常状态:pcp_recovery_node -h 172.16.212.100 -p 9898 -U pgpool -n 1

查看master主机的数据库上是否同步了数据——成功同步了数据

再看一下slave主机上,数据是一样的:


4.3 恢复master主机为primary节点
停止slave主机上的postgresql,查看pool_nodes状态——master主机立马切换成了primary

启动slave主机上的postgresql,然后恢复standby节点的状态为up

这样就恢复了!
4.4 模拟备节点故障,恢复备节点后同步数据
停止slave主机上的postgresql

更新数据库,删除2个库,插入一条新数据
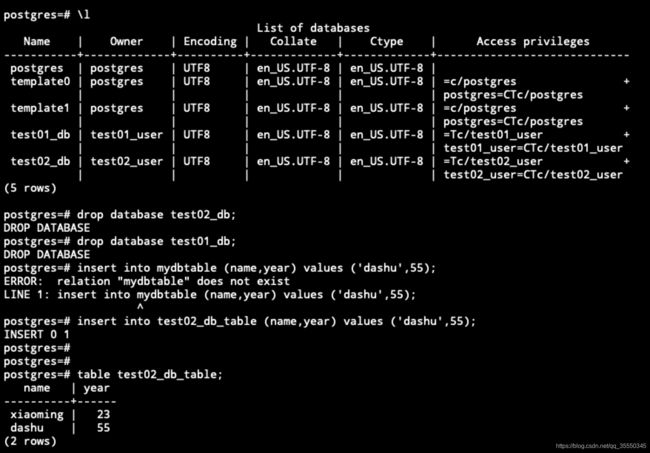
启动slave主机的postgresql并恢复其状态为up

查看数据是否同步成功——数据已经同步成功!

4.5 在主节点新增数据,查看另外一个节点是否同步
在master上创建sonar数据库:

在slave上查看,已经同步成功:
