nodejs Koa框架及常用中间件
目录
前言:了解nodejs
1、nodejs简介
2、nodejs安装
3、检验是否安装成功
4、npm介绍以及使用
①、koa基础
1、koa创建简单实例
2、koa中间件
②、koa中常用的第三方中间件和nodejs的库
1、@koa/router(路由)
2、koa-body(处理post等请求)
3、@koa/cors(处理跨域)
4、koa-static(静态资源)
5、sequelize(操作数据库)
6、node-xlsx(处理excel表格)
7、cheerio(网络爬虫)
8、puppeteer(网络爬虫)
9、china-time(时间格式化)
10、md5(摘要,加密)
11、bcryptjs(对称,非对称加密)
对于第三方中间件和库的总结
③、nodejs内置模块
1、path模块
2、fs模块
④、其他常用后端功能
1、客户端下载文件
前言:了解nodejs1、nodejs简介2、nodejs安装2.1、linux安装2.2、Windows安装3、检验是否安装成功4、npm介绍以及使用4.1、npm简介4.2、npm常用命令①、koa基础1、koa创建简单实例1.1、koa简介1.2、koa安装1.3、koa实例(hello,word)2、koa中间件2.1、挂载中间件2.2、上下文2.3、ctx中的参数2.3.1、ctx.request2.3.2、ctx.response②、koa中常用的第三方中间件和nodejs的库1、@koa/router(路由)1.1、@koa/router的简介1.2、@koa/router的安装1.3、@koa/router的使用1.4、设置路由前缀1.5、路由嵌套和拆分1.6、*简化路由(模块化)2、koa-body(处理post等请求)2.1、koa-body的简介2.2、koa-body的安装2.3、koa-body的使用2.4、获取请求参数3、@koa/cors(处理跨域)3.1、简介3.2、了解CORS3.3、同源策略3.4、哪些情况遵循同源策略3.5、为什么需要CORS3.6、@koa/cors安装3.7、@koa/cors的使用4、koa-static(静态资源)4.1、koa-static的简介4.2、koa-static的安装4.3、koa-static的使用4.4、koa-static的避坑5、sequelize(操作数据库)5.1、sequelize的简介5.2、sequelize的安装5.3、引入sequelize5.4、连接数据库5.4.1、安装驱动程序5.4.2、连接数据库5.5、日志处理5.6、关闭连接5.7、sequelize完成数据库的CRUD(增删改查)5.7.1、sequelize.query中的参数5.7.2、具体实现代码5.8、结尾6、node-xlsx(处理excel表格)6.1、node-xlsx的简介6.2、node-xlsx的安装6.3、node-xlsx的使用6.3.1、将excel的数据导入到数据库6.3.2、将数据库中的表格导出到excel表6.4、总结7、cheerio(网络爬虫)7.1、cheerio的简介(仅供娱乐)7.2、cheerio的安装7.3、cheerio的使用8、puppeteer(网络爬虫)8.1、puppeteer的简介(仅供娱乐)8.2、puppeteer的安装8.3、puppeteer的使用9、china-time(时间格式化)9.1、china-time简介9.2、china-time的安装9.3、china-time的使用10、md5(摘要,加密)10.1、概述10.2、下载md510.3、引入md510.4、将要产生摘要的数据放入10.5、输出结果11、bcryptjs(对称,非对称加密)11.1、bcryptjs简介11.2、bcryptjs的安装11.3、bcryptjs的使用对称加密对于第三方中间件和库的总结③、nodejs内置模块1、path模块1.1简介1.2、path模块的简单使用2、fs模块2.1、fs模块简介2.2、fs模块的使用2.2.1、fs创建目录2.2.2、fs删除目录和文件2.2.3、修改和创建文件④、其他常用后端功能1、客户端下载文件1.1、封装1.2、实现代码
前言:了解nodejs
1、nodejs简介
Node.js发布于2009年5月,由Ryan Dahl开发,是一个基于Chrome V8引擎的JavaScript运行环境,使用了一个事件驱动、非阻塞式I/O模型, [1] 让JavaScript 运行在服务端的开发平台,它让JavaScript成为与PHP、Python、Perl、Ruby等服务端语言平起平坐的脚本语言。 [2]
Node.js对一些特殊用例进行优化,提供替代的API,使得V8在非浏览器环境下运行得更好,V8引擎执行Javascript的速度非常快,性能非常好,基于Chrome JavaScript运行时建立的平台, 用于方便地搭建响应速度快、易于扩展的网络应用。
2、nodejs安装
2.1、linux安装
-
在线下载Linux的nodejs安装包。
wget https://nodejs.org/dist/v12.18.1/node-v12.18.1-linux-x64.tar.xz // 下载 tar xf node-v12.18.1-linux-x64.tar.xz // 解压 cd node-v12.18.1-linux-x64 // 进入解压目录
-
然后 vim /etc/profile,在最下面添加 export PATH=$PATH: 后面跟上 node 下 bin 目录的路径
export PATH=$PATH:/root/node-v12.18.1-linux-x64/bin
2.2、Windows安装
在nodejs官网下载Windows的nodejs安装包。
![]()
自行选择安装的版本。下载后直接点击安装,一直下一步即可。
3、检验是否安装成功
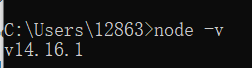
在命令提示符界面,输入node -v ,出现安装的nodejs的版本信息即为安装成功。
4、npm介绍以及使用
4.1、npm简介
npm是一个node包管理和分发工具,已经成为了非官方的发布node模块(包)的标准。有了npm,可以很快的找到特定服务要使用的包,进行下载、安装以及管理已经安装的包。个人觉得npm就和java的maven一样。
4.2、npm常用命令
npm init //会引导你创建一个package.json文件,包括名称、版本、作者这些信息等 npm install //安装package.json文件中"dependencies"参数下的所有第三方库 npm install -g moduleName //将包安装到全局环境下 npm install --save moduleName//安装的同时,将信息写入package.json中项目路径 npm list //查看当前目录下已安装的node包 npm update moduleName //更新node模块 npm uninstall moudleName //卸载node模块
①、koa基础
1、koa创建简单实例
1.1、koa简介
Koa 是一个新的 web 框架,由 Express 幕后的原班人马打造, 致力于成为 web 应用和 API 开发领域中的一个更小、更富有表现力、更健壮的基石。 通过利用 async 函数,Koa 帮你丢弃回调函数,并有力地增强错误处理。 Koa 并没有捆绑任何中间件, 而是提供了一套优雅的方法,帮助您快速而愉快地编写服务端应用程序。
1.2、koa安装
npm install -S koa
1.3、koa实例(hello,word)
const Koa = require('koa');// 引入koa
const app = new Koa();// 创建koa应用
//中间件
app.use(async ctx => {
ctx.body = 'Hello World';
});
// 启动服务监听本地3000端口
app.listen(3000, () => {
console.log('应用已经启动,http://localhost:3000');
})
2、koa中间件
2.1、挂载中间件
在koa中使用app.use()挂载中间件
app.use(async ctx => {
ctx.body = 'Hello World';
});
2.2、上下文
Koa Context 将 node 的 request 和 response 对象封装到单个对象中,为编写 Web 应用程序和 API 提供了许多有用的方法。 这些操作在 HTTP 服务器开发中频繁使用,它们被添加到此级别而不是更高级别的框架,这将强制中间件重新实现此通用功能。
ctx.reques //koa 的 `Request` 对象. ctx.response //koa 的 `Response` 对象. ctx.app.emit //Koa 应用扩展了内部 EventEmitter。ctx.app.emit 发出一个类型由第一个参数定义的事件。 ctx.cookies.get(name, [options]) //通过 options 获取 cookie name options看官网 ctx.cookies.set(name, value, [options]) //通过 options 设置 cookie name 的 value options看官网 ctx.throw([status], [msg], [properties]) //用来抛出一个包含 .status 属性错误的帮助方法,其默认值为 500。这样 Koa 就可以做出适当地响应。
2.3、ctx中的参数
2.3.1、ctx.request
常用的koa 的 Request 对象.
ctx.request.header //请求头对象。这与 node http.IncomingMessage 上的 headers 字段相同 ctx.request.url //获取请求 URL. ctx.request.originalUrl //获取请求原始URL。 ctx.request.origin //获取URL的来源,包括 protocol 和 host。 ctx.request.href //获取完整的请求URL,包括 protocol,host 和 url。 ctx.request.path //获取请求路径名。 ctx.request.ip //请求远程地址。 当 app.proxy 是 true 时支持 X-Forwarded-Proto。 ctx.request.method //请求方法。 ctx.request.length //返回以数字返回请求的 Content-Length,或 undefined。 ctx.request.query //获取解析的查询字符串, 当没有查询字符串时,返回一个空对象
2.3.2、ctx.response
常用的koa 的 Response 对象.
ctx.response.header //响应头对象。 ctx.response.headers //响应头对象。别名是 response.header。 ctx.response.socket //响应套接字。 作为 request.socket 指向 net.Socket 实例。 ctx.response.status //获取响应状态。默认情况下,response.status 设置为 404 而不是像 node 的 res.statusCode 那样默认为 200。 ctx.response.body= //设置响应体 ctx.response.status= //通过数字代码设置响应状态 ctx.response.set(field, value) //设置响应头 field 到 value:
②、koa中常用的第三方中间件和nodejs的库
1、@koa/router(路由)
1.1、@koa/router的简介
@koa/router 是 koa 的一个路由中间件,它可以将请求的URL和方法(如:GET 、 POST 、 PUT 、 DELETE 等) 匹配到对应的响应程序或页面。
1.2、@koa/router的安装
npm install -S @koa/router
1.3、@koa/router的使用
const Koa = require('koa'); // 引入koa
const Router = require('@koa/router'); // 引入@koa/router
const app = new Koa(); // 创建koa应用
const router = new Router(); // 创建路由,支持传递参数
// 指定一个url匹配
router.get('/', async (ctx,next) => {
conslog.log(ctx.query);//请求参数在ctx.query中
ctx.body = 'hello world!';
})
// 调用router.routes()来组装匹配好的路由,返回一个合并好的中间件
// 调用router.allowedMethods()获得一个中间件,当发送了不符合的请求时,会返回 `405 Method Not Allowed` 或 `501 Not Implemented`
app.use(router.routes());
app.use(router.allowedMethods({
// throw: true, // 抛出错误,代替设置响应头状态
// notImplemented: () => '不支持当前请求所需要的功能',
// methodNotAllowed: () => '不支持的请求方式'
}));
// 启动服务监听本地3000端口
app.listen(3000, () => {
console.log('应用已经启动,http://localhost:3000');
})
1.4、设置路由前缀
//设置路由前缀 可以通过调用 router.prefix(prefix) 来设置路由的前缀,也可以通过实例化路由的时候传递参数设置路由的前缀
router.prefix('/api')
// 或者
const router = new Router({
prefix: '/api'
})
1.5、路由嵌套和拆分
当路由涉及到很多业务模块时,需要对模块进行嵌套拆分,在koa-router中, 提供了路由嵌套的功能,使用很简单,就是创建两个 Router 实例,然后将被嵌套的模块路由作为父级路由的中间件使用。
//子路由 文件名为sonRouter
var sonRouter = new Router();
sonRouter.get('/a', (ctx, next) => {
});
sonRouter.get('/b', (ctx, next) => {
});
//路由拆分
moudle.experts=sonRouter
//父路由 文件名为router
var router = new Router();
router.get("/",(ctx,next)=>{
})
//挂载子路由
router.use('/sonRouter', sonRouter.routes(), sonRouter.allowedMethods());
//路由拆分
moudle.experts=sonRouter
1.6、*简化路由(模块化)
在实际开发中,我们要完成的业务不能直接写在路由层,所以我们一般都是建立一个业务层,专门来处理业务。例如我们要处理
一个业务层(如要完成人的日常功能),那么我们需要建立一个文件,例如:person.js文件
//完成人的日常功能
let person={
async eat(ctx,next){
},
async drink(ctx,next){
},
async work(ctx,next){
},
}
//模块化,导出person模块
module.experts=person;
在路由层
//引入业务
let person=require("./person")//引入person.js文件,并命名为person
var router = new Router();
/*
router.get("/",(ctx,next)=>{
})
*/
//此时我们就可以写为,在路由层,我们仅仅就只需要写如下这些接口就行。而我们将业务封装到业务层。
router.get("/eat",person.eat);
router.get("/drink",person.drink);
router.get("/work",person.work);
//导出
module.experts=router
2、koa-body(处理post等请求)
2.1、koa-body的简介
koa-body中间件适用于处理post请求数据,也提供了文件上传功能。
2.2、koa-body的安装
npm install -S koa-body
2.3、koa-body的使用
let koa_body = require('koa-body'); //引入
// 解决发送ajax请求方式问题
app.use(koa_body({
multipart: true,//如果不将multipart设置为true 则ctx.request.body会获取不到参数
parsedMethods: ['POST', 'PUT', 'PATCH'],//将解析正文的 HTTP 方法,处理post等请求
formidable: {
maxFieldsSize: 10*1024*1024,//设置上传文件大小最大限制,默认2M 10*1024*1024
multipart: true
//uploadDir: 可以填写一个路径,不填写默认为 os.tmpDir()
}
}));
2.4、获取请求参数
在koa-body中,前端传的数据都封装在ctx.request.body中。
如果传输的为文件,那么数据封装在ctx.request.files中。文件传输采用流的形式。
在《nodejs使用流处理前端上传的文件》的文章中有写到。
3、@koa/cors(处理跨域)
3.1、简介
@koa/cors 是基于 node-cors 开发的 Koa CORS中间件。主要用于处理同源策略的跨域问题。
3.2、了解CORS
跨域资源共享(Cross-Origin Resource Sharing)是一种机制,用来允许不同源服务器上的指定资源可以被特定的Web应用访问。
3.3、同源策略
同源是指不同的站点间,域名、端口、协议都相同,浏览器的同源策略(same-origin policy)出于安全原因,会限制浏览器的跨源 HTTP 请求。
3.4、哪些情况遵循同源策略
-
由 XMLHttpRequest 或 Fetch 发起的跨域 HTTP 请求。
-
Web 字体 (CSS 中通过 @font-face 使用跨域字体资源)。
-
WebGL 贴图
-
使用 drawImage 将 Images/video 画面绘制到 canvas
3.5、为什么需要CORS
Web应用向服务器请求资源时,由于同源策略限制,Web应用程序只能从同一个域请求 HTTP 资源。如果服务器和Web应用不在同一个域,会发起一个跨域 HTTP 请求。
3.6、@koa/cors安装
npm install -S @koa/cors
3.7、@koa/cors的使用
@koa/cors的用法十分简单,只需要引入后使用即可。
let cors = require("@koa/cors") //解决跨域问题
app.use(cors())//挂载
4、koa-static(静态资源)
4.1、koa-static的简介
Koa 静态文件服务中间件,用于对静态资源的处理,例如,图片,网页等等。
4.2、koa-static的安装
npm install -S koa-static
4.3、koa-static的使用
let koa_static = require("koa-static");//引入koa-static
koa.use(koa_static(__dirname, './public/'));//将当前目录下的public目录设置为静态目录
如此我们就可以通过IP+端口+public下的文件路径或文件名称访问指定的文件了。比如,我们这里要访问bb.gif文件。我们就可以通过
http://127.0.0.1:端口号来访问到bb.gif文件。
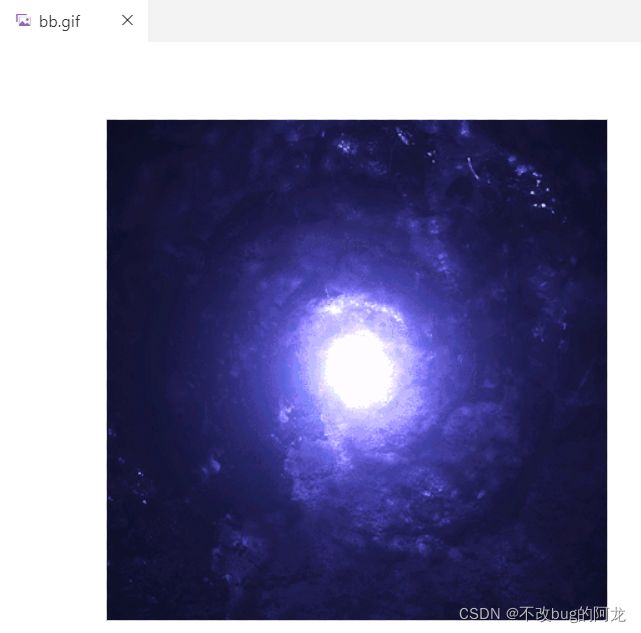
访问结果如下:

4.4、koa-static的避坑
细心一点的伙伴就会发现,当我们访问bb.gif文件的时候,我们并没有加上public路径,写成http://127.0.0.1:9000/public/bb.gif,而是写成http://127.0.0.1:9000/bb.gif,这是koa-staitc最容易遇到的问题,很多伙伴在使用koa-static访问静态资源时,都会习惯性的把路径加全,但是恰恰是因为这个习惯导致出错,所以,在使用koa-staitc时,一定到主要,在访问静态资源时,一定不要将设置为静态资源的路径加上,否则就会访问不到。
5、sequelize(操作数据库)
5.1、sequelize的简介
Sequelize 是一个基于 promise 的 Node.js ORM, 目前支持 Postgres, MySQL, MariaDB, SQLite 以及 Microsoft SQL Server. 它具有强大的事务支持, 关联关系, 预读和延迟加载,读取复制等功能。
Sequelize 遵从 语义版本控制。 支持 Node v10 及更高版本以便使用 ES6 功能。
5.2、sequelize的安装
npm install --save sequelize
5.3、引入sequelize
let { Sequelize } = require("sequelize");
5.4、连接数据库
5.4.1、安装驱动程序
连接数据库需要安装对应的驱动程序。驱动程序安装命令如下。按照自己所要的数据库执行对应安装。
// 驱动类型 dialect:mysql,mariadb,postgres,mssql npm install -S pg pg-hstore npm install -S mysql2 mysql驱动安装命令 npm install -S mariadb npm install -S sqlite3 npm install -S tedious sqlserver驱动安装命令
5.4.2、连接数据库
这篇文章使用sequelize连接数据库主要使用异步(async/await)的方式。
在连接数据库是,产生的数据库对象需要传入几个参数。
database:数据库名称
user:数据库用户账户
password:连接数据库的密码
host:连接的数据库的IP
dialect:要连接的数据库的类型的驱动 /* 选择 'mysql' | 'mariadb' | 'postgres' | 'mssql' 其一 */
将如上参数填写无误后,可以使用authenticate()进行测试连接。
let db = null;
//数据库的连接
async connect() {
try {
db = new Sequelize(database, user, password, {
host: host,
dialect: dialect, //数据库驱动
logging: console.log, //是否输出log信息(sql语句)
}),
await db.authenticate();
return db;//******这里一定要注意返回连接数据库的实例对象*******
} catch (error) {
console.log("数据库连接失败。。。。。");
console.log(error);
}
},
5.5、日志处理
在我们使用sequelize时,使用上述 logging: console.log可以在控制台中输出日志信息,但是这仅仅只适用于开发阶段,所以我们的项目在发布上线后需要将输出信息存入日志文件。所以,我们可以自定义一个方法,来对日志信息进行操作。将logging的参数改为一个自定义方法。
logging: this.databaseLog,
//数据库语句日志
async databseLog(msg) {
//我们可以将其中得到的数据库日志消息进行我们想要的处理,比如将日志写入文件等等。
console.log(msg);
// fs.wirteFile有三个参数
// 1,第一个参数是要写入的文件路径
// 2,第二个参数是要写入得内容
// 3,第三个参数是可选参数,表示要写入的文件编码格式,一般就不写,默认就行
// 4,第四个参数是个回调函数 只有一个参数error,来判断是否写入成功
fs.appendFileSync(filePath,msg+"\n", error => {
if (error) return console.log("写入文件失败,原因是" + error.message);
});
//如果在使用fs.writeFIle时,要写入文件不存在,则直接写入,如果存在,则会覆盖原内容,所以这里可以使用fs.appendFileSync。
}
5.6、关闭连接
默认情况下,Sequelize 将保持连接打开状态,并对所有查询使用相同的连接. 如果你需要关闭连接,请调用 sequelize.close()(这是异步的并返回一个 Promise).
// 关闭数据库
async close() {
if (db != null) {
await db.close();
} else
return db;
},
5.7、sequelize完成数据库的CRUD(增删改查)
将如上连接数据库的函数,抽离出来模块化封装。然后在Dao层引入。由于常常使用简单的方式来执行原始/已经准备好的SQL查询,因此可以使用 sequelize.query 方法。在文件中导入QueryTypes。
let operDB = require('../operDB/operDB');
let { QueryTypes } = require('sequelize');
5.7.1、sequelize.query中的参数
由于其基本原理相同,所以我们就只拿查询举例。在sequelize.query中有几个常用参数
-
第一个参数:sql语句
-
第二个参数是一个对象,里面包含许多参数
-
type:执行的sql语句的类型,查询为QueryTypes.SELECT,修改为QueryTypes.UPDATE,删除为QueryTypes.DELETE,增加为QueryTypes.INSERT。其他类型具体看官方文档。这里不多做赘述。
-
replacements:替换,这个参数的值是一个对象,主要用于将传递的参数在replacements中替换后拼接到数据库中,在sql语句中需要替换的参数需要在前面加上 ":" ,如下代码。
-
5.7.2、具体实现代码
async login(user, password) {
let db = await operDB.getConnect();//获得数据库实例,连接上数据库。
if (db == null) {
return null;
};
//定义一个sql语句
let sql = "SELECT user,power FROM user WHERE user =:user AND PASSWORD=:password";
let rs = await db.query(sql, {
type: QueryTypes.SELECT,
replacements: {
user,
password,
},
})
return rs;
},
5.8、结尾
在上述使用replacements时,有没有伙伴觉得这是多此一举呢?传过来的参数直接替换拼接不久好了吗?其实当初我也是这样想的,但是再往后面不断的学习中,就会了解到sql注入。什么是sql注入呢?这里简单的介绍一下。
SQL注入是比较常见的网络攻击方式之一,它不是利用操作系统的BUG来实现攻击,而是针对程序员编写时的疏忽,通过SQL语句,实现无账号登录,甚至篡改数据库。
如果我么直接使用拼接语句,那么就有很大可能给别人用sql注入攻击爬取你数据库的数据,这是非常严重的,因为在这个数据为重的时代,数据就是一切。
所以,在我们对数据库操作的时候,一定要注意sql语言的书写规范。谨防非法人员不安好心!
6、node-xlsx(处理excel表格)
6.1、node-xlsx的简介
node-xlsx是一个专门用于处理excel表格的第三方模块,我们在实际应用中也十分的常用。例如,当我们要把一个公司人员的所有信息填入excel表格,然后存入到数据库中是,我们不可能直接在数据库一个人员一个人员的录入进去,那这时候想要录入数据库在nodejs中就可以利用node-xlsx了。
6.2、node-xlsx的安装
npm install -S node-xlsx
6.3、node-xlsx的使用
6.3.1、将excel的数据导入到数据库
其实我们仔细分析一下excel表格就会发现对应excel表格里面是这样的层次。一个excel文件里面可以有多个表格,每一个表格有若干条数据。所以,我们要想将一个表格里面的数据插入到数据库总,无非就是取出excel文件里面的某个表格,然后在将表格中的数据取出来插入到数据库中。所以基本用法看如下代码即可。
let xlsx = require("node-xlsx");//引入node-xlsx
let rs;
let elsxData = xlsx.parse("./excel/info.xlsx");//用parse解析一个文件,将文件的内容存入exsxData中
let excel_content = elsxData[0].data;//我们的数据都存在excel表里面的第一个表里面,将数据取出放入excel_content里面
/*在excel表的表格里面,我们还有许多不要的数据,比如一个表的表头,我们数据库中肯定不能插入这些垃圾信息,所以我们需要将其剔除,这时我们可以使用splice(0,n)取出表格中第0-n行的数据*/
excel_content.splice(0, 1);//去除表头
console.log("共" + excel_content.length + "人");
for (let i = 0; i < excel_content.length; i++) {
let xy = excel_content[i][1];//第i行第1列
let bj = excel_content[i][2];//第i行第2列
let xh = excel_content[i][3];//第i行第3列
let xm = excel_content[i][4];//第i行第4列
let xb = excel_content[i][5];//第i行第5列
......
//插入数据库的对应语句,详细操作请看上面是sequelize
rs = await studuntDao.insert(xy, bj, xh, xm, xb,...);
如此就算完成了将excel表格的数据插入到数据库。要注意,因为对于关系型数据库如MySQL或是SQL server来说,excel数据格式要严谨,比如当你要将excel表格里面的某个字段设置为主键时,必须要确保该字段是唯一,当excel表格里面某个字段为空时,数据库表的设计也需要考虑,还有数据的类型等等。
6.3.2、将数据库中的表格导出到excel表
将数据库导出到excel表格也很简单...,下面直接看代码,看完代码再看后面的解释比较容易理解:
let xlsx = require("node-xlsx");//引入node-xlsx
let fs =require("fs");
//取出数据库数据,具体实现看上面sequelize的使用
let rs = await studentRoomInfoDao.queryStudentInfoByClass_MajorAndGrade("计算机科学与技术", "2019", "3");
let datas = [];//定义一个数组,用来装学生数据
//由于取出的数据没有表头,所以我们要根据自己数据库的字段和我们的需求给excel表格添加表头
datas[0] = ["学号", "姓名", "校区", "院系", "专业", "年级", "班级", "楼栋", "房间", "职务"];
//这里将从数据库中取出来的数据也挨个取出,给student数组,然后再将student数组追加给datas数组。
for (let i = 0; i < rs.length; i++) {
let student = [];
student[0] = rs[i].number;
student[1] = rs[i].name;
student[2] = rs[i].campus;
student[3] = rs[i].faculty;
student[4] = rs[i].major;
student[5] = rs[i].grade;
student[6] = rs[i].class;
student[7] = rs[i].building;
student[8] = rs[i].room;
student[9] = rs[i].position;
datas.push(student);
}
//下面就是node-xlsx的一些api下面会进行解释。
const options = { '!cols': [{ wch: 10 }, { wch: 10 }, { wch: 10 }, { wch: 20 }, { wch: 20 }] }; //自定义列宽
let buffer = node_xlsx.build([{
name: 'tableName',
data: datas
}], options);
//将得到的数据存入到buffer中,写入当前目录下的excel下的student.xlsx文件,若没有文件,则会自动创建
fs.writeFileSync('./excel/student.xlsx', buffer, { 'flag': 'w' });
在node-xlsx中,使用build方法来进行我们需要对excel进行的操作。在build方法里面,
第一个参数是一个对象数组,数组里面的每一个对象有两个参数
-
name:为我们要导出的excel表格的表格名称。
-
data:为我们从数据库取出来要存入excel表格的数据。
讲到这里,就要解释为什么要通过for循环将数据以数组的形式存到student数组里,在将student数组存入datas数组里面。因为由于excel表格的格式和规范,只能够存入二维数组。所以在上面进行了如此繁琐的操作。(我不知道此方法是否为最优的,但是确实可以顺利的实现应该完成的功能。如果有大佬有更好的办法,可以提出)。
第二个参数是一个对象,可以定义列宽。对象里面是一个键值对,键是“!cols”(在官方文档里面,键好像可以随便命名,可以自行尝试),值是一个对象数组,里面每一个对象代表你要设置的列的宽度,从左到右按照顺序设置。
最后利用nodejs的fs内置模块,利用fs.writeFileSync方法将数据写入指定路径下的excel表格即可。
注意:这里所讲述的用法和参数不是完整的,只是说的基本的,在官网上,还可以对导出的数据进行排序等等,具体实现可以看node-xlsx官网
6.4、总结
总之,在现实场景中,将excel表格的数据从数据库导入导出是非常常用的,特别是导出到excel表格。想象一下,如果你不是一个程序员,想要将某个app或者网站的某些数据导出到excel表格里面(特别是学校),此时对于用户来说就只想要简单点击一个按钮就可以得到数据,将数据放入到excel表格中。所以导出数据库的数据到excel包非常重要。
7、cheerio(网络爬虫)
7.1、cheerio的简介(仅供娱乐)
cheerio是nodejs的抓取页面模块,为服务器特别定制的,快速、灵活、实施的jQuery核心实现。适合各种Web爬虫程序。
Cheerio 包括了 jQuery 核心的子集。Cheerio 从jQuery库中去除了所有 DOM不一致性和浏览器尴尬的部分,揭示了它真正优雅的API。
Cheerio 工作在一个非常简单,一致的DOM模型之上。解析,操作,呈送都变得难以置信的高效。基础的端到端的基准测试显示Cheerio 大约比JSDOM快八倍(8x)。
Cheerio 封装了兼容的htmlparser。Cheerio 几乎能够解析任何的 HTML 和 XML document。
7.2、cheerio的安装
npm install -S cheerio
7.3、cheerio的使用
没怎么研究过,当初没有能力弄这些,现在又懒得弄了,下面的代码是当时初学的时候写的,好像跑不起来。
let cheerio = require('cheerio')//文档解析
let axios = require('axios');
let fs = require('fs');
const path = require('path');
let request = require("request")
let url = "https://www.doutula.com/article/list/?page=";//定义要抓取页面的url地址
let repilte = {
async repilteOnePage(url) {
for (j = 0; j <= 2; j++) {
await axios.get(`${url}${j}`).then((res) => {
let $ = cheerio.load(res.data);
$('.center-wrap>a').each((i, element) => {
let ImagesUrl = $(element).attr('href');//获取图片地址
let title = $(element).find('.random_title').text();//获取图片名字
//利用正则去除日期
let reg = /(.*?)\s?\d/igs;
title = reg.exec(title)[1];
//创建目录
// fs.mkdir(`reptile/reptileImg/${j}/`, (err) => {
// if (err) {
// console.log(err);
// } else {
// console.log("creat done!");
// }
// });
repilte.imageUrl(ImagesUrl, title.slice(0, 5));//请求图片
});
})
}
},
async imageUrl(ImagesUrl, title) {//单个页面中的一个链接中的表情包数据
let rs = await axios.get(ImagesUrl).then((res) => {
let $ = cheerio.load(res.data);
$('.pic-content .artile_des img').each((i, element) => {//获得图片类别的地址
let imagesUrl_onePage = $(element).attr('src');
console.log(imagesUrl_onePage);
let extName = path.extname(imagesUrl_onePage);//获取图片扩展名
let imgPath = `${path.resolve(__dirname, '../reptileImg')}/${title}_${i}${extName}`//图片存储路径
console.log(imgPath)
let ws = fs.createWriteStream(imgPath, { autoClose: true });//创建写入流
request(imagesUrl_onePage).pipe(ws);//写入文件
console.log("图片加载完成" + imgPath);
});
})
return rs;
}
}
repilte.repilteOnePage(url);
// async imageUrl(ImagesUrl, title) {//单个页面中的一个链接中的表情包数据
// let rs = await axios.get(ImagesUrl).then((res) => {
// let $ = cheerio.load(res.data);
// $('.pic-content .artile_des img').each((i, element) => {//获得图片类别的地址
// let imagesUrl_onePage = $(element).attr('src');
// // console.log(imagesUrl_onePage);
// let extName = path.extname(imagesUrl_onePage);//获取图片扩展名
// let imgPath = `reptile/reptileImg/${title}/${title}_${i}${extName}`
// let ws = fs.createWriteStream(imgPath);//创建写入流
// axios.get(imagesUrl_onePage, { responseType: 'stream' }).then((res) => {
// res.data.pipe(ws);
// console.log("图片加载完成" + imgPath);
// res.data.on('close', () => {//关闭写入流
// ws.close();
// })
// })
// });
// })
// return rs;
// }
8、puppeteer(网络爬虫)
8.1、puppeteer的简介(仅供娱乐)
Puppeteer是NPM库,它提供了NodeJS高级API来控制Chrome。Puppeteer 默认以无头(无界面)方式运行,但也可以配置为运行有界面的Chrome。
Puppeteer 提供了一系列 API,通过 Chrome DevTools Protocol 协议控制 Chromium/Chrome 浏览器的行为。
8.2、puppeteer的安装
npm install -S puppeteer
8.3、puppeteer的使用
也是仅作兴趣爱好,下面的代码当初学习的时候好像是能够爬取图片的。
let puppeteer = require('puppeteer');
let path = require("path");
let fs = require("fs");
let axios = require('axios')
let request = require("request")
let puppeteerDemo = {
async puppeteer() {
try {
//launch
let browser = await puppeteer.launch({//启动
headless: false,//取消无头模式,模拟浏览器运行
product: 'chrome',//product:运行的浏览器,默认为谷歌
defaultViewport: {//窗口大小设置
width: 1920,
height: 1080
},
timeout: 3000//超时,默认30秒
});
// newPage
let page = await browser.newPage();//用browser创建page实例
await page.goto('https://www.baidu.com');//跳转到这个网站
console.log("已经跳转到https://www.baidu.com");
let searchInput = await page.$('#kw')//绑定搜索框
await searchInput.focus();//定位到搜索框
await page.keyboard.type('狗');//向页面发送信息
console.log("输入内容完成.......................")
await page.click('#su');
console.log('已经点击按钮.....................');
await page.waitForSelector("div > h3 > a");//!!!!!!!!!!!!必须要执行这一步,等待获取属性值
const newPage = new Promise(x => browser.once('targetcreated', target => x(target.page()))); // 声明变量
await page.click('div > h3 > a');
let page2 = await newPage;//新对象
await page2.setViewport({//设置窗口大小
width: 1920,
height: 1080
})
await page2.waitForTimeout(1000);//等待2执行下一个操作
await page2.screenshot({//截取图片
path: `${path.resolve(__dirname, '../screenShot')}/狗狗图片总览.png`
})
console.log("图片截取完成.....................");
await puppeteerDemo.autoScroll(page2);//自动滚动,获取翻页数据
for (let index = 0; index < 74; index++) {
let i = 0;
console.log(`第${index + 1}页的图片`);
await page2.waitForTimeout(1000);
let paths = `#imgid .pageNum${index} img`;
let srcs = await page2.$$eval(paths, img => img.map(i => i.src))//$$eval
await srcs.forEach(element => {
let extName = path.extname(element);//获取图片扩展名
let ws = fs.createWriteStream(`../screenShot/${index}_${i++}${extName}`);
page2.waitForTimeout(100);//等待0.1秒执行下一步
//方式一
request(element).pipe(ws);
console.log(element + " 图片抓取成功!!!下载路径为" + `${path.resolve(__dirname, '../screenShot/')}`);
//方式二,暂时无法成功
// let rs = fs.createReadStream(element);
// rs.pipe(ws);
// console.log(element + " 图片抓取成功!!!路径为" + `${path.resolve(__dirname, '../screenShot/')}`);
//方式三,不行
// axios.get(element, {
// responseType: 'arraybuffer',
// }).then((res) => {
// let rs = fs.createReadStream(res.data);
// rs.pipe(ws);
// })
});
}
await page2.waitForTimeout(500);//等待0.5秒执行下一个操作
await browser.close();//关闭
console.log("页面已经关闭......................")
} catch (error) {
console.log(error)
}
},
async autoScroll(page) {//控制页面滚动
return page.evaluate(() => {
return new Promise((resolve, reject) => {
//滚动的总高度
var totalHeight = 0;
//每次向下滚动的高度 100 px
var distance = 100;
var timer = setInterval(() => {
//页面的高度 包含滚动高度
var scrollHeight = document.body.scrollHeight;
//滚动条向下滚动 distance
window.scrollBy(0, distance);
totalHeight += distance;
//当滚动的总高度 大于 页面高度 说明滚到底了。也就是说到滚动条滚到底时,以上还会继续累加,直到超过页面高度
if (totalHeight >= scrollHeight) {
clearInterval(timer);
resolve();
}
}, 100);
})
});
}
}
puppeteerDemo.puppeteer();
module.exports = puppeteerDemo;
9、china-time(时间格式化)
9.1、china-time简介
一个用于格式化时间的第三方库,可以将当前时间格式化为各种形式,简单方便。
9.2、china-time的安装
npm install -S china-time
9.3、china-time的使用
let chinaTime = require('china-time');//时间格式化模块
console.log(chinaTime()); // 2021-10-31T09:15:00.000Z
console.log(chinaTime().getTime()); // 1635671700000 时间戳
console.log(chinaTime('YYYY-MM-DD HH:mm:ss')); // 2021-10-31 17:15:07
console.log(chinaTime('YY/MM/DD HH:mm')); // 21/10/31 17:15
console.log(chinaTime('YYYY MM DD')); // 2021 10 31
10、md5(摘要,加密)
10.1、概述
MD5,即消息摘要算法第五版,是一种被广泛使用的密码散列函数。散列算法的基本原理是:进行数据(如一段文字)运算,将原始数据变为另一段固定长度的值。
10.2、下载md5
npm install -S md5
10.3、引入md5
let md5 = require('md5');
10.4、将要产生摘要的数据放入
const a = "admin"; console.log(md5(a));
10.5、输出结果
![]()
运行后则会产生32位的摘要信息,在一些简单的个人系统开发种,可以使用md5产生的摘要加密密码,存入数据库。但是使用MD5产生的32位的密文其实也不安全,因为可以进行暴力破解,所以如果确实需要安全性很高的的加密,可以引入一些第三方的库进行加盐处理,进行对称加密或者非对称加密。
11、bcryptjs(对称,非对称加密)
11.1、bcryptjs简介
bcryptjs是bcrypt的替代模块,bcryptjs是纯js实现,bcrypt是c++实现。
11.2、bcryptjs的安装
npm install -S bcryptjs
11.3、bcryptjs的使用
对称加密
具体实现如下:
const bcrypt = require("bcryptjs");
const saltRounds = 10;//加盐
const clientPassword = '123456';
let databasePassword = "$2a$10$DVzcPrUmEy2qbQsgE01oZOx8iHxklzyjtse8n07SEG9O5hQnRoojW";
//加盐处理方式一
// bcrypt.genSalt(saltRounds, function(err, salt) {
// bcrypt.hash(clientPassword, salt, function(err, hash) {
// console.log(hash) //$2a$10$aHEtUiC6Auu3SIUMMYnRpusmxMTMEA71piVONyW8VIQpguLdkq99G
// });
// });
//加盐处理方式二
bcrypt.hash(clientPassword, saltRounds, (err, hash) => {
//生成的值可以存入数据库
console.log(hash) //$2a$10$X1Xg5eb1ZZ0WgHjzlCtKf.fxBKphxlfDu.8h.nJCsb3A6Fpow2xI.
//解密:将前端传过来的密码与数据库取出来的串进行对比,返回结果true或者false
bcrypt.compare(clientPassword, databasePassword, function(err, result) {
console.log(result); // true;
});
});
对于第三方中间件和库的总结
以上介绍的一些中间件只是我认为比较常用的,当然好用的第三方库肯定很多,而且在进行解释的时候肯定有许许多多的错误,特别是网络爬虫那儿,纯属个人兴趣,希望大家看到错误的地方请指出,本人也是一个在校的小菜鸟,纯粹爱好。谢谢!!!
③、nodejs内置模块
1、path模块
1.1简介
Node.js path 模块提供了一些用于处理文件路径的小工具。在日常开发中十分实用。
1.2、path模块的简单使用
var path = require("path");//引入path模块
/*用于连接路径。在koa-staitc中出现过path.join的影子,利用__dirname,将当前的路径拼接到指定路径*/
path.join([path1][, path2][, ...]);
path.dirname(p)//返回路径中代表文件夹的部分,同 Unix 的dirname 命令类似。
path.basename(p[, ext])//返回路径中的最后一部分。同 Unix 命令 bashname 类似。
path.extname(p)//返回路径中文件的后缀名,即路径中最后一个'.'之后的部分。如果一个路径中并不包含'.'或该路径只包含一个'.' 且这个'.'为路径的第一个字符,则此命令返回空字符串。
2、fs模块
2.1、fs模块简介
fs模块用于对系统文件及目录进行读写操作。
2.2、fs模块的使用
2.2.1、fs创建目录
// 创建 dir 目录
fs.mkdir('./dir', function(err) {
if (err) {
throw err;
}
console.log('make dir success.');
});
2.2.2、fs删除目录和文件
//异步删除
var fs = require('fs');
fs.unlink('/dir', function(err){
if (err) throw err;
console.log('successfully deleted dir');
//同步示例
var fs = require('fs');
fs.unlinkSync('/dir');
console.log('successfully deleted dir');
//删除目录
async deleteDirectory(dirPath) {
var files = [];
//判断给定的路径是否存在
if (fs.existsSync(dirPath)) {
//返回文件和子目录的数组
files = fs.readdirSync(dirPath);
files.forEach(function (file, index) {
// var curPath = url + "/" + file;
var curPath = path.join(dirPath, file);
//fs.statSync同步读取文件夹文件,如果是文件夹,在重复触发函数
if (fs.statSync(curPath).isDirectory()) { // recurse
deleteFolderRecursive(curPath);
// 是文件delete file
} else {
fs.unlinkSync(curPath);
}
});
//清除文件夹
fs.rmdirSync(dirPath);
} else {
console.log("给定的路径不存在,请给出正确的路径");
}
},
//删除文件
async deleteFile(filePath) {
try {
let rs = fs.unlinkSync(filePath);
return rs;
} catch (err) {
console.error(err)
}
}
2.2.3、修改和创建文件
使用fs.writeFile(filename,data,[options],callback)写入内容到文件。在使用下面的不管是哪个方法时,如果文件不存在则会自动创建。
//使用writeFile方法都不追加内容,而是覆盖内容
let msg = "aaaaaa";
fs.writeFile("./写入信息到文件/writeFileLog.txt", msg, err => {
console.log(err);
});
fs.writeFileSync("./写入信息到文件/writeFileSyncLog.txt", msg, err => {
console.log(err);
});
//使用appendFile方法能实现文件内容追加,不会覆盖内容
var os = require("os");
let msg = "aaaaaa";
//注意,这里的os.EOL就是换行符的意思,与\n用法相同。
fs.appendFile("./写入信息到文件/appendFileLog.txt", msg + os.EOL, err => {
console.log(err);
});
fs.appendFileSync("./写入信息到文件/appendFileSyncLog.txt", msg + "\n", err => {
console.log(err);
});
④、其他常用后端功能
1、客户端下载文件
在实际开发中,下载东西的应用十分广泛和常用。
1.1、封装
将读取数据的方法单独封装起来,使用promise异步返回读取的数据流。
//输入流
async images(fileUrl) {
let myread = fs.createReadStream(fileUrl);
let content = Buffer.alloc(0);
let promise = new Promise((resolve, reject) => {
myread.on('readable', () => {
while ((temp = myread.read(1024)) != null) {
content = Buffer.concat([content, temp]);
}
});
myread.on('end', () => {
resolve(content);
});
myread.on('error', (err) => {
reject(err);
})
})
let rs = await promise;
return rs;
},
1.2、实现代码
在浏览器中,浏览器会默认打开能够识别的文件,比如图片等等,但是,当我们下载的时候,显然不能让其展示在浏览器上面,而是点击下载的时候弹出下载框,保存在电脑本地。所以我们需要在koa的ctx中设置响应类型,第二个参数要写为attachment附件形式。filename设置要传输的图片的名字。当文件名字为汉字时,需要使用${encodeURI("xx学院.gif")}设置编码格式。否则则会显示为无效的编码格式。
![]()
async downLoadImage(ctx, next) {
//将要下载的文件路径传给上面封装好的流
let rs = await tools.images('D:/vscode/pro/fs/public/aa.png');
ctx.response.set('Content-disposition', 'attachment;filename=aa.png');
// ctx.response.set("Content-Type", "attachment;filename=image");
ctx.body = rs;
},
async downLoadGif(ctx, next) {
let rs = await tools.images('D:/vscode/pro/fs/public/bb.gif');
ctx.response.set(`Content-disposition`, `attachment;filename=${encodeURI("x学院.gif")}`);
ctx.body = rs;
}