计算机网络——多路复用与多路分解
一、前言
最近在看《计算机网络——自顶向下方法》这本书,读了一部分之后发现,这真是一本非常不错的计算机网络入门书籍,想要学习计算机网络的人可以去买来看看。今天刚读到运输层这一章,开头详细讲解了运输层的多路复用与多路分解,我觉得颇有收获,所以写篇博客分享一下这一部分内容。
二、解析
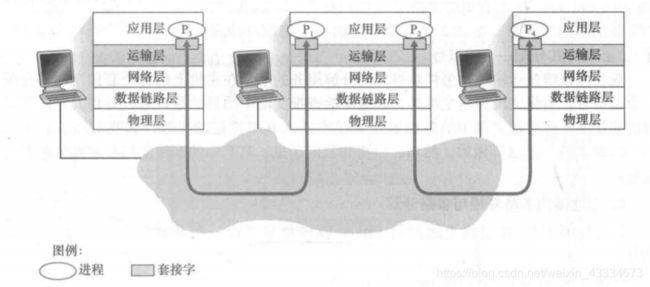
2.1 应用层、运输层以及网络层的关系
想要解析多路复用与多路分解,首先得大致了解一下计算机五层结构中,应用层、运输层与网络层的关系。
网络层是五层结构中的第三层,它的作用就是在网络中提供端到端(即主机之间)的逻辑通信;而运输层的是五层结构中的第四层,它的作用是提供进程之间的通信。应用层则是最顶层,作用是为用户提供与网络打交道的接口。
应用层与运输层之间通过套接字传递数据,套接字是运输层与应用层的一个中间媒介,位于两层之间。运输层接收到数据后,将它交付到正确的套接字中,应用层进程从的相应的套接字中获取数据;反之应用层将数据交付到套接字,运输层从套接字中收集数据。而网络层接收其他主机发送的数据,去除首部信息后交给运输层,由运输层定向到套接字;反之运输层也将从套接字中收集的数据封装后,交给网络层向下传递。
2.2 什么是多路复用与多路分解
这里通过一个类比来理解这两个概念:假设有两个家庭A和B,各有10名家庭成员。假设这两个家庭中的每一个成员,在每个星期都要给另一个家庭的10成员各写一封信,所以A家庭每个星期都要有100封信送到B家庭,B家庭亦是如此。A家庭和B家庭各选出了一个负责人来处理这件事,假设A家庭的负责人是李明,而B家庭的负责人是韩梅梅。这两个负责人每个星期都需要干两件事情:
收集每个家庭成员写的信,并将它交给邮差,由邮差将信交到另一个家庭中;
邮差将信寄到家来时,负责人统一接收,并根据信上的收件人姓名,将信交给指定的家庭成员;
多路复用的过程就好比负责人的要办事情1,而多路分解就好比事情2。下面来看这两个名称的解释:
多路复用:在数据的发送端,传输层收集各个套接字中需要发送的数据,将它们封装上首部信息后(之后用于分解),交给网络层;
多路分解:在数据的接收端,传输层接收到网络层的报文后,将它交付到正确的套接字上;
家庭成员就好比套接字,而这两个负责人就好比主机中的运输层,邮差可以理解为网络层。负责人将寄来的信分发给家庭成员的过程,类似于运输层将数据报分发给指定的套接字;而邮差从一个家庭送信到另一个家庭,也可以类比为网络层中主机之间的通信。
那这两个过程具体是如何工作的呢?每个进程可以有多个套接字,运输层如何知道要将数据交付给哪一个套接字呢?这里我们需要明确复用/分解的要求:
每个套接字都有唯一标识;
每一个传递到运输层的报文段,都包含一些特殊字段,来指明它需要交付到的套接字;
对于每一个套接字,都能被分配一个的端口号。所以,上述要求2中所说的特殊字段就是源端口号字段和目的端口号字段(对于TCP和UDP,这个还有一些其他特殊字段,将在后面讲解)。所以我们知道运输层如何实现分解服务了:当一个报文段到达运输层时,运输层检测报文段中的端口号,根据端口号,将其定向到指定的套接字中。然后数据通过套接字即可进入套接字对应的进程。
2.3 无连接的多路分解与多路复用
上面只是讲解了一下这两个概念的一般形式,但是在具体的实现中要稍微复杂一些,不同协议所使用的套接字也有所区别,下面我们来看看UDP协议中的多路分解与多路复用。
我们知道,UDP是一个面向无连接,不可靠的运输层协议,它尽最大努力传输数据,但是不保证数据是否到达,或者是否按顺序到达,它要做的仅仅是将数据发出,至于发出后如何,它不会在意。
当进程需要发送UDP数据报时,首先要创建一个UDP套接字,然后应用层通过这个UDP套接字将数据传递到运输层,运输层为数据加上源端口号以及目的端口号,封装成数据报后交给网络层,网络层再为数据报封装上源IP以及目的IP。由于UDP协议仅仅只是将数据发出,所以对于UDP报文来说,最重要的就是目的地址的所在。可能正是因为这个原因,一个UDP套接字的标识就是目的IP+目的端口号。因此对于多个不同的UDP数据报,只要它们的目的IP+端口号相同,就算源地址不同,也会在目的主机中被定向到同一个UDP套接字中,被同一个进程所接收。目的IP决定了数据报将要发送到哪台主机,而目的端口号为运输层的的分解提供了标识。
这里可能就会有些疑问了,既然这样,那UDP报文为什么需要包含源IP+源端口号呢(IP在网络层被封装)?这是因为UDP是无连接的,当接收到一个UDP报文时,可能想要回送一个报文,这时候不知道源在何处将无法实现。所以当需要向源主机回复报文时,只需提取UDP报文中的源IP和源端口号,然后将它们作为目的IP+目的端口号即可实现。

2.4 面向连接的多路复用与多路分解
既然有无连接的实现,自然就有连接的实现。运输层乃至整个计算机网络最著名的协议——TCP协议,就是一个面向连接的协议。TCP是一个面向连接,可靠的运输层协议。既然面向连接,那它就需要关注两个方面:源地址和目的地址,因为TCP的传输,需要两边协作完成。正因为TCP的特性,导致TCP的套接字和UDP也有所区别。TCP套接字的标识是一个四元组,即源IP+源端口+目的IP+目的端口(UDP是目的IP+目的端口)。我们通过一个实例来讲解TCP的多路复用/分解过程。
大部分人使用最多的应用层协议应该就是HTTP协议,而它就是基于TCP协议实现的,当我们在浏览器中请求一个页面时,将经历以下过程:
Web服务器监听80端口,等待客户端的连接;
用户在浏览器输入一个URL,回车后,浏览器进程创建一个套接字,此套接字由服务器IP,服务器80端口,本地IP,本地进程端口,四部分标识;
浏览器进程将数据通过此套接字从应用层传入运输层,运输层为TCP报文加上首部(包括源端口和目的端口)后,交给网络层,网络层为其加上网络层首部(包括源IP和目的IP)传输传输到Web服务器;
Web服务器的接收到此数据报后,检测到数据报请求的是端口80,于是检测80端口正在运行,且允许连接,则创建一个新的套接字,此套接字由服务器IP,服务器80端口,源IP,源端口,这四部分标识;
此后到达的Web服务器的数据报,若以上四部分完全相等,则将进入此套接字中;
既然TCP套接字是由源IP+源端口+目的IP+目的端口四部分标识,不难想到,我们无法在同一台主机上,依靠同一个端口,向服务器的某个一个端口建立两个TCP连接,因为这样将无法区分两个连接。以下通过Java进行测试:
public static void main(String[] args) throws IOException {
// 建立第一个TCP连接,结果正常
Socket socket1 = new Socket("www.baidu.com", 80, null, 8888);
// 建立第二个连接,与上一个连接的目的IP,目的端口,以及本地端口均相同
// 结果抛出异常:
// java.net.BindException: Address already in use: JVM_Bind
Socket socket2 = new Socket("www.baidu.com", 80, null, 8888);
}
以上代码执行时抛出异常,提示地址已经被使用,但是修改第二个socket对象的本地端口后,异常消失,验证了上面的结论。