- (Python基础篇)字符串的操作
EternityArt
基础篇python开发语言算法
目录引言一、字符串的基本定义与访问(一)字符串的定义(二)字符串的索引与切片二、字符串的常用操作方法(一)字符串的拼接与重复(二)字符串的大小写转换(三)字符串的去除空白(四)字符串的查找与替换(五)字符串的分割与连接(六)字符串的判断方法三、字符串的格式化(一)使用%运算符(二)使用str.format()方法(三)使用f-字符串(Python3.6+)四、字符串的不可变性五、总结引言在Pyth
- 华为OD机试 2025B卷 - 小明减肥(C++&Python&JAVA&JS&C语言)
YOLO大师
华为odc++python华为OD2025B卷华为OD机试华为机试2025B卷华为OD机试2025B卷
2025B卷目录点击查看:华为OD机试2025B卷真题题库目录|机考题库+算法考点详解2025B卷100分题型最新华为OD机试真题目录:点击查看目录华为OD面试真题精选:点击立即查看题目描述小明有n个可选运动,每个运动有对应卡路里,想选出其中k个运动且卡路里和为t。k,t,n都是给定的。求出可行解数量输入描述第一行输入ntk第一行输入每个运动的卡路里按照空格进行分割备注00,00输出描述求出可行解
- 【华为OD机试真题 2025B卷】130、最多获得的短信条数、云短信平台优惠活动 | 机试真题+思路参考+代码解析(C++、Java、Py、C语言、JS)
KFickle
最新华为OD机试(C++JavaPyCJS)+OJ华为odc++javajavascript华为OD机试真题c语言最多获得的短信条数
文章目录一、题目题目描述输入输出样例1样例2二、代码与思路参考C++代码Java代码Python代码C语言代码JS代码订阅本专栏后即可解锁在线OJ刷题权限个人博客首页:KFickle专栏介绍:最新的华为OD机试真题,使用C++,Java,Python,C语言,JS五种语言进行解答,每个题目都包含解题思路,五种语言的解法,每日持续更新中,订阅后支持开通在线OJ测试刷题!!!一次订阅永久享受更新,有代
- 【华为OD机试真题 2025B卷】128、 判断一组不等式是否满足约束并输出最大差 | 机试真题+思路参考+代码解析(C++、Java、Py、C语言、JS)
KFickle
最新华为OD机试(C++JavaPyCJS)+OJ华为odc++java华为OD机试真题c语言javascript
文章目录一、题目题目描述输入输出样例1样例2二、代码与思路参考C++代码Java代码Python代码C语言代码JS代码订阅本专栏后即可解锁在线OJ刷题权限个人博客首页:KFickle专栏介绍:最新的华为OD机试真题,使用C++,Java,Python,C语言,JS五种语言进行解答,每个题目都包含解题思路,五种语言的解法,每日持续更新中,订阅后支持开通在线OJ测试刷题!!!一次订阅永久享受更新,有代
- Python编程菜鸟教程:从入门到精通的完全指南_python菜鸟教程
2401_89285717
python开发语言
我们将介绍Python在数据科学、机器学习、Web开发等方面的应用,并带你了解Python社区和生态系统。基础入门Python安装:在官方网站下载安装包,根据不同操作系统进行安装。Mac用户可直接使用Homebrew进行安装Windows用户需下载安装包后进行手动安装Linux用户可使用apt-get或yum进行安装基础语法:Python是一种解释型语言,支持面向对象、函数式和面向过程等多种编程范
- Python Pandas库超详细教程:从入门到精通实战指南
stormsha
Pythonpythonpandas开发语言python3.11数据分析
欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。推荐:「stormsha的主页」,「stormsha的知识库」持续学习,不断总结,共同进步,为了踏实,做好当下事儿~非常期待和您一起在这个小小的网络世界里共同探索、学习和成长。✨✨欢迎订阅本专栏✨✨TheStart点点关注,收藏不迷路文章目录Pyt
- python中的元类Metaclass
ReedSun
pythonpython
python中的元类Metaclass理解元类之前需要学习的知识如果说让我们创建一个类,最先想到的肯定是用class创建,当我们使用class创建类的时候,python解释器自动创建这个对象,但是python同样也提供了手动处理的方法来创建类,这就是用python的自建函数type()。我们所熟知的type()函数的作用是返回一个参数的类型,但是实际上,它也有一种完全不同的能力,即接受一个类的一些
- python 元类的继承_Python学习_13_继承和元类
五伤先生
python元类的继承
继承继承的含义就是子类继承父类的命名空间,子类中可以调用父类的属性和方法,由于命名空间的查找方式,当子类中定义和父类同名属性或者方法时,子类的实例调用的是子类中的属性,而不是父类,这就形成了python中的多态:defSuperClass:defa_method:passdefSubClass(SuperClass):defa_method:passobj=SubClass()obj.a_meth
- 网络安全用什么编程语言_网络安全的5种最佳编程语言
程序员羊羊
web安全网络安全开发语言数据库
网络安全用什么编程语言要成为网络安全专家,要取得成功,需要多种技能。全方位的专业人员可以放心地实施和监视安全措施,以保护计算机系统免受攻击和未经授权的访问。总部位于巴西的Python专家Henrique教人们如何使用该语言创建应用程序,他强调“除了紧跟网络安全领域的最新动态,您还需要熟悉各种编程语言。”这里有5种最佳编程语言,可帮助您提高网络安全职业的学习能力。1.C和C++C和C++是网络安全专
- Python面试题:使用Python进行元编程:元类和元编程技巧
在Python中,元编程是一种编程技巧,它涉及到代码本身的结构和行为的编程。元编程允许你编写能够操作、修改或生成代码的代码。最常见的元编程技术包括使用元类、装饰器和类装饰器。以下是对Python元编程的详细讲解,包括元类和一些常用的元编程技巧。1.元类(Metaclasses)1.1定义和概念元类是用来创建类的类。换句话说,元类定义了类的行为,就像类定义了对象的行为一样。在Python中,type
- Python元类基础知识示例深度剖析,从新手小白成为Python编程高手
只存在于虚拟的King
python开发语言深度学习学习经验分享计算机网络程序人生
文章目录引言一、什么是元类?二、元类的工作原理三、如何定义元类四、元类的应用场景五、元类的注意事项六、结论关于Python技术储备一、Python所有方向的学习路线二、Python基础学习视频三、精品Python学习书籍四、Python工具包+项目源码合集①Python工具包②Python实战案例③Python小游戏源码五、面试资料六、Python兼职渠道引言Python是一种强大的编程语言,一部
- stm32 micropython vscode_VS Code 上最硬核的 MicroPython 插件
weixin_39968309
stm32micropythonvscode
介绍VSCode上最硬核的MicroPython插件——RT-ThreadMicroPython,为MicroPython开发提供了强大的开发环境,主要特性如下:设备快速连接(串口、网络、USB)支持基于MicroPython的代码智能补全与语法检查支持MicroPythonREPL交互环境提供丰富的代码示例与demo程序提供工程同步功能支持下载单个文件或文件夹至开发板支持在内存中快速运行代码文件
- Python对JSON数据操作
在Python中,对JSON数据进行增删改查及加载保存操作,主要通过内置的json模块实现。一、基础操作1.加载JSON数据•从文件加载使用json.load()读取JSON文件并转换为Python对象(字典/列表):importjsonwithopen('data.json','r',encoding='utf-8')asf:data=json.load(f)•从字符串加载使用json.load
- 【转载】python json
概念序列化(Serialization):将对象的状态信息转换为可以存储或可以通过网络传输的过程,传输的格式可以是JSON、XML等。反序列化就是从存储区域(JSON,XML)读取反序列化对象的状态,重新创建该对象。JSON(JavaScriptObjectNotation):一种轻量级数据交换格式,相对于XML而言更简单,也易于阅读和编写,机器也方便解析和生成,Json是JavaScript中的
- Python os库完全指南:文件操作必备
晨曦543210
Python启航之路python开发语言
一、简介Python的os库。这个库主要用于和操作系统交互,比如管理文件、目录、运行系统命令等。二、导入库importos三、基础操作获取当前工作目录current_dir=os.getcwd()print("当前目录:",current_dir)切换目录os.chdir("/path/to/new/directory")列出目录内容files=os.listdir()#不传参数则默认当前目录pr
- Python 爬虫实战:Selenium 爬取豆瓣相册(图片分类 + 标签提取)
西攻城狮北
python爬虫selenium
一、引言豆瓣作为国内知名的社区平台,其相册功能允许用户上传和分享各类图片,涵盖电影海报、音乐专辑、生活记录等多个领域。这些图片数据对于了解用户兴趣、进行内容推荐和市场调研具有重要价值。然而,豆瓣对直接的数据访问设定了诸多限制,因此,本文将介绍如何通过Python爬虫技术结合Selenium自动化工具,合法高效地爬取豆瓣相册图片,并运用深度学习技术实现图片分类和标签提取。二、开发环境搭建(一)编程语
- Python JSON操作完全指南
目录一、简介二、JSON和Python的对应关系三、核心函数1.json.dumps():将Python对象→JSON字符串2.json.loads():将JSON字符串→Python对象3.json.dump():将Python对象→JSON文件4.json.load():从JSON文件→Python对象四、常见错误处理1.JSON解析错误2.类型不支持错误五、总结六、常用函数1️⃣json.d
- AI“大航海”时代:企业人力资源的AI-HR实践与效能提升策略
在数字化浪潮的推动下,人工智能(AI)正以前所未有的速度渗透各行各业,人力资源管理(HR)领域也不例外。AI技术的引入与应用落地,不仅提升HR管理效率,更在深层次上带来人力资源运作模式的变革。什么是AI-HR所谓AI-HR,是指将人工智能技术应用于人力资源管理,并通过机器学习、自然语言处理、数据挖掘等技术,优化招聘、培训、绩效评估、员工关系等人力资源各个业务模块。近年来,随着AI技术的成熟和普及,
- 华为OD机试 - 计算某字符出现次数(Python/JS/C/C++ 2025 B卷 100分)
哪 吒
华为odpythonjavascript2025B卷华为OD机试
2025B卷华为OD机试统一考试题库清单(持续收录中)以及考点说明(Python/JS/C/C++)。专栏导读本专栏收录于《华为OD机试真题(Python/JS/C/C++)》。刷的越多,抽中的概率越大,私信哪吒,备注华为OD,加入华为OD刷题交流群,每一题都有详细的答题思路、详细的代码注释、3个测试用例、为什么这道题采用XX算法、XX算法的适用场景,发现新题目,随时更新。一、题目描述写出一个程序
- 华为OD机试 - 取零食 - 动态规划(Python/JS/C/C++ 2024 E卷 100分)
哪 吒
华为od动态规划python
2025华为OD机试题库(按算法分类):2025华为OD统一考试题库清单(持续收录中)以及考点说明(Python/JS/C/C++)。专栏导读本专栏收录于《华为OD机试真题(Python/JS/C/C++)》。刷的越多,抽中的概率越大,私信哪吒,备注华为OD,加入华为OD刷题交流群,每一题都有详细的答题思路、详细的代码注释、3个测试用例、为什么这道题采用XX算法、XX算法的适用场景,发现新题目,随
- 华为OD机试 - 快速人名查找 - 深度优先搜索dfs(Python/JS/C/C++ 2025 B卷 200分)
哪 吒
华为od深度优先python2025A卷华为OD机试
一、题目描述给一个字符串,表示用","分开的人名。然后给定一个字符串,进行快速人名查找,符合要求的输出。快速人名查找要求:人名的每个单词的连续前几位能组成给定字符串,一定要用到每个单词。二、输入描述第一行是人名,用“,”分开的人名第二行是查找字符串。三、输出描述输出满足要求的人名。四、测试用例测试用例1:1、输入alicebob,charliedelta,alicecharlieac2、输出ali
- 2025上半年最新华为OD机试与面试指南,最新2025B卷独家总结上岸技巧,答读者问!必看!【万字长文,建议收藏】(Python/JS/C/C++)
专栏导读本专栏收录于《华为OD机试真题(Python/JS/C/C++)》。刷的越多,抽中的概率越大,私信哪吒,备注华为OD,加入华为OD刷题交流群,每一题都有详细的答题思路、详细的代码注释、3个测试用例、为什么这道题采用XX算法、XX算法的适用场景,发现新题目,随时更新。2025年5月12日,华为官方已经将华为OD机试(A卷)切换为B卷。目前正在考的是B卷,按照华为OD往常的操作,B卷题目是由往
- Jetson Orin NX Super安装TensorRT-LLM
u013250861
#LLM/部署&推理elasticsearch大数据搜索引擎
根据图片中显示的JetsonOrinNXSuper系统环境(JetPack6.2+CUDA12.6+TensorRT10.7),以下是针对该平台的TensorRT-LLM安装优化方案:一、环境适配调整基于你的实际配置:JetPack6.2(含CUDA12.6,TensorRT10.7)Python3.10.12aarch64架构需选择适配的TensorRT-LLM版本。由于官方预编译包可能未覆盖此
- SpringBoot多数据源动态切换方案:AbstractRoutingDataSource详解
fanxbl957
Webspringboot后端java
博主介绍:Java、Python、js全栈开发“多面手”,精通多种编程语言和技术,痴迷于人工智能领域。秉持着对技术的热爱与执着,持续探索创新,愿在此分享交流和学习,与大家共进步。DeepSeek-行业融合之万象视界(附实战案例详解100+)全栈开发环境搭建运行攻略:多语言一站式指南(环境搭建+运行+调试+发布+保姆级详解)感兴趣的可以先收藏起来,希望帮助更多的人SpringBoot多数据源动态切换
- 想要了解大模型,看懂这一篇就够了!大模型工作流程及核心参数介绍!
Gq.xxu
qwen3vllmtransforms大语言模型部署深度学习人工智能
若想深入探究大模型核心参数的效果与作用,就务必先弄清大模型的工作流程,明确核心参数在流程各阶段的效能与功能,知晓其具体含义。一,大模型的工作流程大模型运行时的工作原理可以概括为输入处理→特征提取→模型推理→结果生成四个核心阶段,整个过程融合了深度学习架构、自然语言处理技术以及分布式计算能力。从用户输入到大模型输出,整个工作的处理流程如下:输入文本→分词→嵌入+位置编码→Transformer多层处
- 「源力觉醒 创作者计划」_以FastDeploy为例部署ERNIE-4.5-21B大模型全流程实践
cooldream2009
大模型基础AI技术文心大模型FastDeploy
目录前言1环境准备与依赖安装1.1硬件要求1.2Python环境与pip升级2下载ERNIE-4.5模型权重2.1安装HuggingFaceCLI工具2.2设置国内镜像加速(可选)2.3下载模型文件3安装FastDeploy与Paddle推理引擎3.1安装PaddlePaddle-GPU版本3.2安装FastDeploy-GPU4启动ERNIE-4.5本地服务4.1启动OpenAI兼容API服务4
- Python打卡:Day46
剑桥折刀s
python打卡python
importtorchimporttorch.nnasnnimporttorch.optimasoptimimporttorchvisionfromtorchvisionimportdatasets,transformsfromtorch.utils.dataimportDataLoaderfromtorch.utils.tensorboardimportSummaryWriterimportnu
- 为什么在 macOS 中运行 Python 项目必须使用虚拟环境?
coding随想
Pythonmacospython开发语言
为什么在macOS中运行Python项目必须使用虚拟环境?在macOS上开发Python项目时,虚拟环境(VirtualEnvironment)是一个不可或缺的工具。无论你是初学者还是资深开发者,理解虚拟环境的意义和使用方法,都是提升开发效率和项目稳定性的关键。本文将从macOS的特殊性出发,深入浅出地解释为什么在macOS中运行Python项目必须使用虚拟环境。一、macOS系统Python的局
- 扣子智能体5:使用Python异步执行工作流并获取执行结果
呆萌的代Ma
大模型python扣子
使用python异步执行工作流的步骤有3步:异步执行工作流,获取工作流的execute_id,之后就能根据这个id查询工作流的执行情况如果execute_id=“Success”,就表示工作流执行完毕执行完毕后,打印output,就是大模型最后的全部示例代码fromloguruimportloggerimportrequestsimportjsondefrun_coze_ai(coze_api_t
- MCP客户端请求MCP服务器资源的Python SDK实现
AI天才研究院
计算AI人工智能与大数据Python实战python开发语言ai服务器
我将为您提供一个详细的指南,说明如何使用PythonSDK让MCP客户端请求MCP服务器的资源。MCP客户端请求MCP服务器资源的PythonSDK实现核心概念ModelContextProtocol(MCP)是一个标准化协议,允许应用程序以标准化的方式为大语言模型(LLM)提供上下文,将提供上下文的关注点与实际的LLM交互分离。MCP中的资源(Resources)是一种核心原语,允许服务器暴露数
- Spring4.1新特性——Spring MVC增强
jinnianshilongnian
spring 4.1
目录
Spring4.1新特性——综述
Spring4.1新特性——Spring核心部分及其他
Spring4.1新特性——Spring缓存框架增强
Spring4.1新特性——异步调用和事件机制的异常处理
Spring4.1新特性——数据库集成测试脚本初始化
Spring4.1新特性——Spring MVC增强
Spring4.1新特性——页面自动化测试框架Spring MVC T
- mysql 性能查询优化
annan211
javasql优化mysql应用服务器
1 时间到底花在哪了?
mysql在执行查询的时候需要执行一系列的子任务,这些子任务包含了整个查询周期最重要的阶段,这其中包含了大量为了
检索数据列到存储引擎的调用以及调用后的数据处理,包括排序、分组等。在完成这些任务的时候,查询需要在不同的地方
花费时间,包括网络、cpu计算、生成统计信息和执行计划、锁等待等。尤其是向底层存储引擎检索数据的调用操作。这些调用需要在内存操
- windows系统配置
cherishLC
windows
删除Hiberfil.sys :使用命令powercfg -h off 关闭休眠功能即可:
http://jingyan.baidu.com/article/f3ad7d0fc0992e09c2345b51.html
类似的还有pagefile.sys
msconfig 配置启动项
shutdown 定时关机
ipconfig 查看网络配置
ipconfig /flushdns
- 人体的排毒时间
Array_06
工作
========================
|| 人体的排毒时间是什么时候?||
========================
转载于:
http://zhidao.baidu.com/link?url=ibaGlicVslAQhVdWWVevU4TMjhiKaNBWCpZ1NS6igCQ78EkNJZFsEjCjl3T5EdXU9SaPg04bh8MbY1bR
- ZooKeeper
cugfy
zookeeper
Zookeeper是一个高性能,分布式的,开源分布式应用协调服务。它提供了简单原始的功能,分布式应用可以基于它实现更高级的服务,比如同步, 配置管理,集群管理,名空间。它被设计为易于编程,使用文件系统目录树作为数据模型。服务端跑在java上,提供java和C的客户端API。 Zookeeper是Google的Chubby一个开源的实现,是高有效和可靠的协同工作系统,Zookeeper能够用来lea
- 网络爬虫的乱码处理
随意而生
爬虫网络
下边简单总结下关于网络爬虫的乱码处理。注意,这里不仅是中文乱码,还包括一些如日文、韩文 、俄文、藏文之类的乱码处理,因为他们的解决方式 是一致的,故在此统一说明。 网络爬虫,有两种选择,一是选择nutch、hetriex,二是自写爬虫,两者在处理乱码时,原理是一致的,但前者处理乱码时,要看懂源码后进行修改才可以,所以要废劲一些;而后者更自由方便,可以在编码处理
- Xcode常用快捷键
张亚雄
xcode
一、总结的常用命令:
隐藏xcode command+h
退出xcode command+q
关闭窗口 command+w
关闭所有窗口 command+option+w
关闭当前
- mongoDB索引操作
adminjun
mongodb索引
一、索引基础: MongoDB的索引几乎与传统的关系型数据库一模一样,这其中也包括一些基本的优化技巧。下面是创建索引的命令: > db.test.ensureIndex({"username":1}) 可以通过下面的名称查看索引是否已经成功建立: &nbs
- 成都软件园实习那些话
aijuans
成都 软件园 实习
无聊之中,翻了一下日志,发现上一篇经历是很久以前的事了,悔过~~
断断续续离开了学校快一年了,习惯了那里一天天的幼稚、成长的环境,到这里有点与世隔绝的感觉。不过还好,那是刚到这里时的想法,现在感觉在这挺好,不管怎么样,最要感谢的还是老师能给这么好的一次催化成长的机会,在这里确实看到了好多好多能想到或想不到的东西。
都说在外面和学校相比最明显的差距就是与人相处比较困难,因为在外面每个人都
- Linux下FTP服务器安装及配置
ayaoxinchao
linuxFTP服务器vsftp
检测是否安装了FTP
[root@localhost ~]# rpm -q vsftpd
如果未安装:package vsftpd is not installed 安装了则显示:vsftpd-2.0.5-28.el5累死的版本信息
安装FTP
运行yum install vsftpd命令,如[root@localhost ~]# yum install vsf
- 使用mongo-java-driver获取文档id和查找文档
BigBird2012
driver
注:本文所有代码都使用的mongo-java-driver实现。
在MongoDB中,一个集合(collection)在概念上就类似我们SQL数据库中的表(Table),这个集合包含了一系列文档(document)。一个DBObject对象表示我们想添加到集合(collection)中的一个文档(document),MongoDB会自动为我们创建的每个文档添加一个id,这个id在
- JSONObject以及json串
bijian1013
jsonJSONObject
一.JAR包简介
要使程序可以运行必须引入JSON-lib包,JSON-lib包同时依赖于以下的JAR包:
1.commons-lang-2.0.jar
2.commons-beanutils-1.7.0.jar
3.commons-collections-3.1.jar
&n
- [Zookeeper学习笔记之三]Zookeeper实例创建和会话建立的异步特性
bit1129
zookeeper
为了说明问题,看个简单的代码,
import org.apache.zookeeper.*;
import java.io.IOException;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ThreadLocal
- 【Scala十二】Scala核心六:Trait
bit1129
scala
Traits are a fundamental unit of code reuse in Scala. A trait encapsulates method and field definitions, which can then be reused by mixing them into classes. Unlike class inheritance, in which each c
- weblogic version 10.3破解
ronin47
weblogic
版本:WebLogic Server 10.3
说明:%DOMAIN_HOME%:指WebLogic Server 域(Domain)目录
例如我的做测试的域的根目录 DOMAIN_HOME=D:/Weblogic/Middleware/user_projects/domains/base_domain
1.为了保证操作安全,备份%DOMAIN_HOME%/security/Defa
- 求第n个斐波那契数
BrokenDreams
今天看到群友发的一个问题:写一个小程序打印第n个斐波那契数。
自己试了下,搞了好久。。。基础要加强了。
&nbs
- 读《研磨设计模式》-代码笔记-访问者模式-Visitor
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
import java.util.ArrayList;
import java.util.List;
interface IVisitor {
//第二次分派,Visitor调用Element
void visitConcret
- MatConvNet的excise 3改为网络配置文件形式
cherishLC
matlab
MatConvNet为vlFeat作者写的matlab下的卷积神经网络工具包,可以使用GPU。
主页:
http://www.vlfeat.org/matconvnet/
教程:
http://www.robots.ox.ac.uk/~vgg/practicals/cnn/index.html
注意:需要下载新版的MatConvNet替换掉教程中工具包中的matconvnet:
http
- ZK Timeout再讨论
chenchao051
zookeepertimeouthbase
http://crazyjvm.iteye.com/blog/1693757 文中提到相关超时问题,但是又出现了一个问题,我把min和max都设置成了180000,但是仍然出现了以下的异常信息:
Client session timed out, have not heard from server in 154339ms for sessionid 0x13a3f7732340003
- CASE WHEN 用法介绍
daizj
sqlgroup bycase when
CASE WHEN 用法介绍
1. CASE WHEN 表达式有两种形式
--简单Case函数
CASE sex
WHEN '1' THEN '男'
WHEN '2' THEN '女'
ELSE '其他' END
--Case搜索函数
CASE
WHEN sex = '1' THEN
- PHP技巧汇总:提高PHP性能的53个技巧
dcj3sjt126com
PHP
PHP技巧汇总:提高PHP性能的53个技巧 用单引号代替双引号来包含字符串,这样做会更快一些。因为PHP会在双引号包围的字符串中搜寻变量, 单引号则不会,注意:只有echo能这么做,它是一种可以把多个字符串当作参数的函数译注: PHP手册中说echo是语言结构,不是真正的函数,故把函数加上了双引号)。 1、如果能将类的方法定义成static,就尽量定义成static,它的速度会提升将近4倍
- Yii框架中CGridView的使用方法以及详细示例
dcj3sjt126com
yii
CGridView显示一个数据项的列表中的一个表。
表中的每一行代表一个数据项的数据,和一个列通常代表一个属性的物品(一些列可能对应于复杂的表达式的属性或静态文本)。 CGridView既支持排序和分页的数据项。排序和分页可以在AJAX模式或正常的页面请求。使用CGridView的一个好处是,当用户浏览器禁用JavaScript,排序和分页自动退化普通页面请求和仍然正常运行。
实例代码如下:
- Maven项目打包成可执行Jar文件
dyy_gusi
assembly
Maven项目打包成可执行Jar文件
在使用Maven完成项目以后,如果是需要打包成可执行的Jar文件,我们通过eclipse的导出很麻烦,还得指定入口文件的位置,还得说明依赖的jar包,既然都使用Maven了,很重要的一个目的就是让这些繁琐的操作简单。我们可以通过插件完成这项工作,使用assembly插件。具体使用方式如下:
1、在项目中加入插件的依赖:
<plugin>
- php常见错误
geeksun
PHP
1. kevent() reported that connect() failed (61: Connection refused) while connecting to upstream, client: 127.0.0.1, server: localhost, request: "GET / HTTP/1.1", upstream: "fastc
- 修改linux的用户名
hongtoushizi
linuxchange password
Change Linux Username
更改Linux用户名,需要修改4个系统的文件:
/etc/passwd
/etc/shadow
/etc/group
/etc/gshadow
古老/传统的方法是使用vi去直接修改,但是这有安全隐患(具体可自己搜一下),所以后来改成使用这些命令去代替:
vipw
vipw -s
vigr
vigr -s
具体的操作顺
- 第五章 常用Lua开发库1-redis、mysql、http客户端
jinnianshilongnian
nginxlua
对于开发来说需要有好的生态开发库来辅助我们快速开发,而Lua中也有大多数我们需要的第三方开发库如Redis、Memcached、Mysql、Http客户端、JSON、模板引擎等。
一些常见的Lua库可以在github上搜索,https://github.com/search?utf8=%E2%9C%93&q=lua+resty。
Redis客户端
lua-resty-r
- zkClient 监控机制实现
liyonghui160com
zkClient 监控机制实现
直接使用zk的api实现业务功能比较繁琐。因为要处理session loss,session expire等异常,在发生这些异常后进行重连。又因为ZK的watcher是一次性的,如果要基于wather实现发布/订阅模式,还要自己包装一下,将一次性订阅包装成持久订阅。另外如果要使用抽象级别更高的功能,比如分布式锁,leader选举
- 在Mysql 众多表中查找一个表名或者字段名的 SQL 语句
pda158
mysql
在Mysql 众多表中查找一个表名或者字段名的 SQL 语句:
方法一:SELECT table_name, column_name from information_schema.columns WHERE column_name LIKE 'Name';
方法二:SELECT column_name from information_schema.colum
- 程序员对英语的依赖
Smile.zeng
英语程序猿
1、程序员最基本的技能,至少要能写得出代码,当我们还在为建立类的时候思考用什么单词发牢骚的时候,英语与别人的差距就直接表现出来咯。
2、程序员最起码能认识开发工具里的英语单词,不然怎么知道使用这些开发工具。
3、进阶一点,就是能读懂别人的代码,有利于我们学习人家的思路和技术。
4、写的程序至少能有一定的可读性,至少要人别人能懂吧...
以上一些问题,充分说明了英语对程序猿的重要性。骚年
- Oracle学习笔记(8) 使用PLSQL编写触发器
vipbooks
oraclesql编程活动Access
时间过得真快啊,转眼就到了Oracle学习笔记的最后个章节了,通过前面七章的学习大家应该对Oracle编程有了一定了了解了吧,这东东如果一段时间不用很快就会忘记了,所以我会把自己学习过的东西做好详细的笔记,用到的时候可以随时查找,马上上手!希望这些笔记能对大家有些帮助!
这是第八章的学习笔记,学习完第七章的子程序和包之后
![已解决nltk.download(‘stopwords‘) [nltk_data] Error loading stopwords: <urlopen error [Errno 11004] [nlt_第1张图片](http://img.e-com-net.com/image/info8/7769a786f82f41639940fd3599a568d4.jpg)
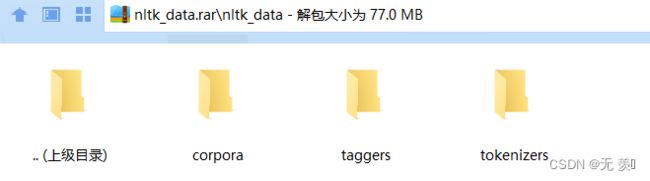


![已解决nltk.download(‘stopwords‘) [nltk_data] Error loading stopwords: <urlopen error [Errno 11004] [nlt_第2张图片](http://img.e-com-net.com/image/info8/98d1219d6a884c1d8e82546e70e221ac.jpg)



