从一到无穷大 #20 TimeUnion,适用于混合云的时序数据库?是玩具还是真实可用
 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
- 引言
- 论文
-
- 块存储与对象存储
- 统一数据模型
- 高效的内存数据结构
- Elastic time-partitioned LSM-tree
-
- Key Format
- Architecture
- Compaction on fast cloud storage
- Compaction on slow cloud storage
- Dynamic size control
- 总结
引言
工作上有一段攻坚时期,使得距离上一次写文章已经过了两个月,终于把拖了很久的《TimeUnion: An Efficient Architecture with Unified Data Model for Timeseries Management Systems on Hybrid Cloud Storage》学习完,并有时间记录一下,结合昨天的国足比赛,有一种吃了两颗屎味巧克力的感觉。
但是辩证的看,也不全然是坏消息,分辨屎味以及说出为什么这是一个屎味的巧克力也同样重要,这也是这篇文章诞生的原因。
论文
现有的开源时间序列数据库(比如 Prometheus,InfluxDB)的设计大多借鉴了LSM-tree的理念,以追求高写入吞吐,数据按照时间进行shard分区,首先在内存中分批处理写入数据,然后刷新到磁盘,此外,每个shard都自包含倒排索引和数据本身。在设计中,有几个假设:
- 内存容量足够大,可以处理最近时间分区的所有倒排索引、元数据和数据本身
- 假设只使用一种持久性存储,而不考虑利用分层存储
- 它假设时间序列是独立处理和存储的。
基于如上假设,在云上部署现有系统以管理大量时间序列时,存在以下几个关键问题。
- 每个tag对都会构建一个倒排索引项,并携带一系列tsid列表,这样的设计会占用大量内存
- 磁盘结构的元数据会被载入到内存中加速查询,增加内存消耗
- 内存中的批处理消耗大量内存
- 没有考虑多云存储性价比与性能的权衡
为了引出主要贡献,作者设计了两个实验:
- 向prometheus插入12小时的随机数据,时间间隔为60s,发现inverted index, block metadata, 以及data samples分别占用了51%, 34%, 15%的内存使用
- 将golang版本的leveldb集成到prometheus中,对于每个数据压缩块,生成一个ULID[5]作为键, 插入leveldb,发现LSM-Tree 能够处理大量的时间序列数据,但是考虑到在混合云存储上的部署,需要重新设计原有的压缩机制,以减少压缩过程中的低效数据读取;
a. LevelDB插入吞吐量仅比 Prometheus tsdb 低 1.6%
b. LevelDB 完成所有压缩的时间多了 18%;这可能会影响系统的性能,因为在使用慢速云存储时,压缩的成本会很高
c. LevelDB 向磁盘写入的数据仅多 2.4%
d. 在一次压缩中,我们平均需要读取 36% 的 SSTables。此外每次压缩时至少需要从下一级读取一个重叠的 SSTable
作者认为这篇文章的贡献主要集中在:
- 对云盘存储和对象存储进行一系列实验,归纳云上设计时序数据库的关键原则
- 提出了一种统一数据模型,并证明在某些情况下可以减少内存使用和提升查询性能
- 为倒排索引和数据本身重新设计了数据结构,旨在解决当前内存瓶颈,对应实验1
- 设计Elastic time-partitioned LSM-tree,原生支持数据的冷热分离(共三层前两层存储热数据,最后一层存储冷数据,由于大部分数据在前两级压缩后都已排序,具有较高的数据相关性,因此只在冷存储中保留一级),对应实验2
在我的角度来看,这篇文章可以看出作者科研实力较强,但是论文提及的系统本身工程意义不大,原因如下:
- 云盘与对象存储的评估较为简单,且没有理解较深的结论
- group在我看来更像是把ClickHouse的稀疏索引本身融合到数据模型中,且没有详细阐述每个group中二级索引的实现,且在形式化证明中可以看到并不是所有情况都是可以节省内存的
- 重新设计的内存数据结构不具备工程化基础。第一,使用double-array trie + mmap作为全局唯一的倒排索引,前者的更新效率过于低下,基本无法用于生产,其次后者以我们运营百亿时间线级别时序数据库的实践经验来看mmap[6]不适合数据库存储引擎;
- 这种LSM-tree的设计看起来确实可以做到天然分层存储时序数据,但是并不具备实践意义;
a. 第一,这种运营方式不适合公有云卖服务的形式,因为云盘和对象存储都太贵,远没有物理机便宜性价比高
b. 第二,对于时序数据库来讲,分层降冷是一个伪需求(极少场景使用,比如用于新能源车企的合规需求),文中认为两小时数据存储在云盘,其他数据认为是冷数据存储在对象存储,以目前运营经验来看所有的分钟级别时序数据都是热数据,这部分数据都会被经常查询(同比,环比查询,BI分析),在超过retention policy后会被淘汰,淘汰之前都可以认为会被频繁查询,真正的冷数据是粒度较粗的数据,比如小时聚合数据,天聚合数据,这部分数据会经过Flink或者时序数据库内部的降采样,流计算等手段被写入到另一个retention policy完全不同的db,这部分数据才是冷数据;
c. 第三,文章花大功夫在时间分区的LSM细节上,但是降冷本身和时间关系不是特别大,完全可以去除时间这个约束,简单的认为最后一层的数据沉入冷数据,但是也和普通的LSM的降冷没什么区别,有一种为了设计而设计的感觉。
块存储与对象存储
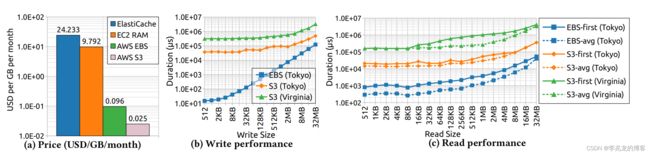
作者讨论了块存储与对象存储的成本与读写性能,这个值其实参考意义不是特别大,各大公有云厂商的具体值都不太一样,且与实例所属地域也有很大的关系,建议对这方面数据较为敏感的同学还是自己测试。
这里提一下为什么16kb一下对象存储的时延不变,现有公有云对象存储的架构鼻祖基本上是《Windows Azure Storage: A Highly Available Cloud Storage Service with Strong Consistency》,其中Partition Layer为对象表,Stream Layer则为实际的存储模块,一个大的对象在对象存储内部会被分为多个分块,并在对象表中记录大对象的所有分块在存储中的元数据(生命周期,索引等),所以单个分片阈值以下时延是稳定的,在有些实现中当一个对象小于这个分块阈值时kv只存在对象表,对象表的实现一般是一个range kv系统,存储都是SSD的,所以小对象存储会很快,看起来s3没有使用这种优化。
从结果可以看到大的指导方向就是:块存储贵性能高,对象存储便宜性能差
对象存储是文件系统/存储的一种简化替代:牺牲了强一致性、目录管理,访问时延等功能属性,以换取廉价的成本与海量伸缩的能力。它提供了一个简单的、高延迟、高吞吐扁平 KV 存储服务,从标准的存储服务中剥离出来。作为云服务之锚,对象存储优势还有很多:
- 可扩展性: 对象存储非常适合处理大量的非结构化数据,可以轻松扩展到多个数据中心和地理位置。
- 成本效益: 通常基于使用量计费,且由于其设计,对象存储可以更有效地管理和存储大量数据。
- 耐久性和可用性: 对象存储通常具有内置的数据复制和分布式架构,提供高水平的耐久性和可用性。
- 元数据和自定义索引: 对象可以包含丰富的元数据,使得数据管理和检索更加灵活和强大。
- 简化的数据访问: 通过HTTP/HTTPS协议访问,可以从任何地方通过网络访问数据。
块存储作为当然优势也有很多,但是价格真的非常高昂:
- 性能: 块存储提供高性能的I/O处理,适合需要快速读写操作的应用。
- 灵活性: 块存储可以像本地磁盘一样挂载,支持各种操作系统和文件系统。
- 低延迟: 对于数据库和交易性应用,块存储的低延迟特性非常重要。
统一数据模型
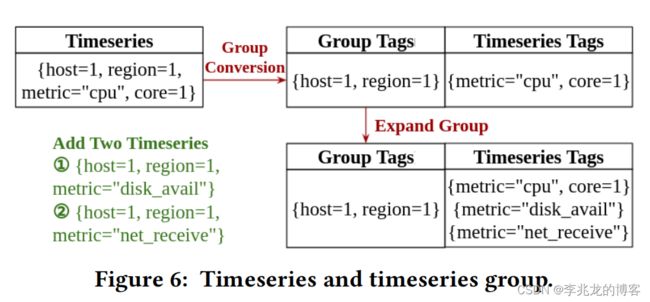
逻辑视图的核心思想在于每一个时间序列都归属于一个group,在向group中添加新的时间序列时,group tags会被提取出来,而其他tags则用于唯一标识group内的时间序列,且在构建倒排索引时使用group id,这样可以使得倒排索引中的发布列表长度大幅度减少(如下图),但是带来的问题就是如何快速索引组内的时间序列。
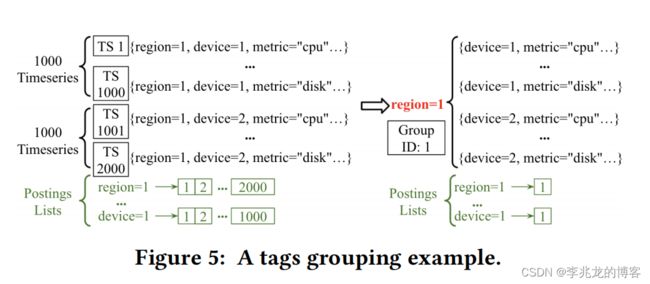
我对这里独立时间序列和group分离的理解是这种组织形式支持两种索引方式,普通的独立时间序列和目前influxdb的组织形式类似,而group是论文提出的组织形式,论文设计了两种方式的组织方式,最终都会被转化为Elastic time-partitioned LSM-tree的SSTable。
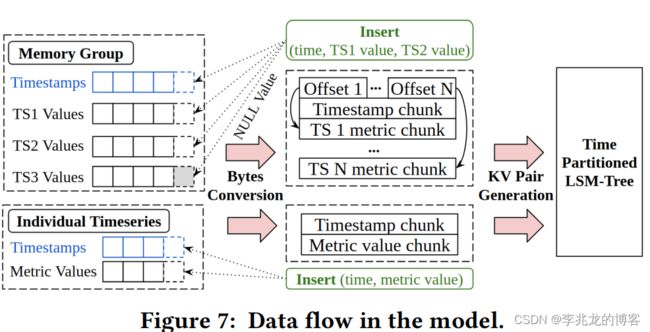
我认为设计两种组织形式的原因于论文中形式化证明的结果有关,具体可参考论文3.1节的Grouping analysis。
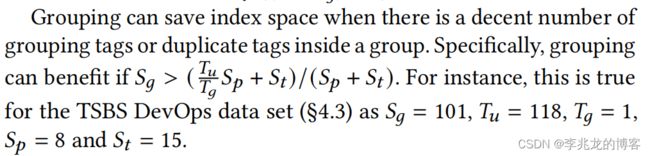
高效的内存数据结构
这里优化的动机来自于实验1,实验本身没有问题,但是优化本身的现实意义有待商榷,我认为可以聊的具体有两个优化点:
- 使用全局独立的索引结构double-array trie作为倒排索引。这里我认为问题很大,前缀树本身很适合作为时间线较少时的倒排索引结构,IotDB tsfile内的索引结构就是前缀树,但是double-array trie本身更新复杂度高的缺陷使得这个结构并不适合时序数据库的倒排索引,其次因为倒排索引会存储serieskey本身的字符串,这个结构独立以后会变的相当大,又加剧了写入开销,最后这个结构使用三个mmap持久化索引数据,这个动作又使得写入变的更慢,原因可参考[6]。
- 数据在内存中时被映射为mmap,在chunk满后被写入lsm,并清空mmap,这样做的缺陷是当内存不足mmap开始频繁缺页是写路径会变的非常慢
Elastic time-partitioned LSM-tree
这里优化的动机来自于实验2,优化的本质是需要重新设计原有的压缩机制,以减少压缩过程中的低效数据读取。
可以想到如果写入的时间戳永远单调递增,写入可以理解为内存到L0永远不存在合并,但是处理乱序数据会打破这个约束;其次因为不同层处于不同的介质,如何提升压缩率也是需要考虑的问题;
所以Elastic time-partitioned LSM-tree解决的问题就是如何平衡写入放大和增加数据压缩率。
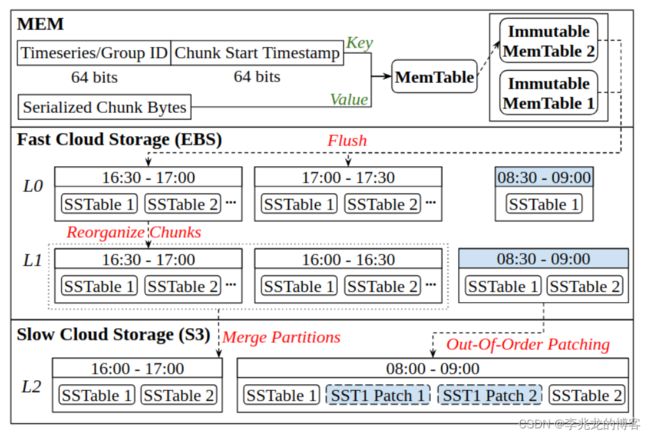
具体架构如下:
Key Format
分别使用大端编码将时间序列/组 ID 和时间序列/组块的起始时间戳存储在第一和第二个 64 位中,这样的设计可以使得同一个时间序列的数据存储在一起,同时根据时间戳排序,这样的key格式同时可以利用到key的前缀压缩功能,使得时间序列本身被压缩。
这样的设计利好于数据压缩,但是不利好于查询,因为时间序列的指定实际上是随机的,这样的key format使得一次查询涉及到的key遍布引擎的整个key namespace,从而使得查询性能极差。
这也是influxdb1.x原生引擎就存在的问题。
Architecture
LSM 树只维护三个级别,第 0 层和第 1 层管理块存储中相对较少的时间序列数据(即最近 2 小时的数据),较早的数据存储在对象存储(第二层),以避免不必要的压缩(速度较慢)。由于时间序列数据是按时间戳排序的,因此我们根据不同的时间范围将 SSTables 划分到不同的级别,以控制每个级别的大小。对于第 0 级和第 1 级,时间分区长度从一个相对较小的值开始(如 30 分钟),该值将根据预定义的快速存储大小限制进行动态调整。特定时间分区的 SSTables 中数据块的数据样本严格受分区时间范围的限制。当 SST 表压缩到第 2 级时,几个分区会合并以创建更大的分区(如 2 小时)
Compaction on fast cloud storage
为了减少不可变 MemTable 刷新时的插入阻塞,TimeUnion扩展了一个不可变 MemTable 队列,允许同时进行多次刷新,这是一个比较常见的优化方式,在底层写入较慢时是一个很好的缓冲方法。
当第 0 层中累积的时间分区超过阈值(即 2)时,将触发从第 0 层到第 1 层的压缩,以压缩第 0 层中最旧的时间分区。在快速存储中保留两个级别有两个考虑因素。
- 首先,相同key的键值对会合并成更大的键值对,以获得更好的压缩比
- 其次,由于在 0 级时间分区中,同一时间序列/组的数据块可能分散在不同的 SST 表中,因此在压缩过程中,我们会将同一时间序列/组的键值对集中到同一个 SST 表中,以提高数据的本地性
- 如果所选的第 0 级sstable与第 1 层重叠,TimeUnion 将把它与第 1 级中重叠的分区合并
这个流程和正常的LSM压缩没有什么区别
Compaction on slow cloud storage
当 0 级时间分区的总体时间跨度超过 2 级分区时间长度(例如最初为 2 小时)时,将触发从 1 级到 2 级的压缩。
这里有一点比较有意思,即patches,用于第 1 级与第 2 级出现重叠时,为了不重写对象存储中的SST,会将重叠的地方生成一个patches,写入第二层
Dynamic size control
只在块存储上存储两个小时的数据显然不太合适,在快速存储上存的越多肯定是越利好于查询的,考虑到块存储的成本相对较高,需要考虑在快存储有限的可用容量上存储尽可能多的数据,但是时间维度不能很好的表示数据的多少,所以引入Dynamic size control。
如果level 1 的总时间跨度足够大但总大小小于阈值(例如,数据样本稀疏,或者时间序列数量少),会增加分区长度。此外,为了便于compaction期间的时间分区对齐,在动态控制期间将可调的时间分区长度乘/除以 2。这里最小也得是2,否则无法对齐。
这里我有一个疑问,目前来看这么多复杂设计就是为例基于时间做冷热数据分离,如果只是最后一层的数据沉降,key中也不携带时间,好像也没什么问题,还可以更好的控制块存储中的大小。
总结
思路上patches有借鉴意义,可以有效的减少写入放大,在混合云场景下很有意义。但是整体来看还是一个玩具,生产中基本无法使用。
参考:
- SIGMOD’22 论文阅读:TimeUnion一种具有统一数据模型和混合云存储支持的高效时间序列管理系统架构
- TimeUnion: An Efficient Architecture with Unified Data Model for Timeseries Management Systems on Hybrid Cloud Storage
- 云盘是不是杀猪盘?
- 扒皮云对象存储:从降本到杀猪
- Universally Unique Lexicographically Sortable Identifier. https://github.com/oklog/ulid
- 从一到无穷大 #11 Is mmap shit or not?
- HanLP — 双数组字典树 (Double-array Trie) 实现原理
- 从一到无穷大 #10 讨论 Apache IoTDB 大综述中看到的优劣势