7.1 处理缺失数据
pandas使用浮点值NaN(Not a Number)表示缺失数据。我们称其为哨兵值,可以方便的检测出来:
In [10]: string_data = pd.Series(['aardvark', 'artichoke', np.nan, 'avocado'])
In [11]: string_data
Out[11]:
0 aardvark
1 artichoke
2 NaN
3 avocado
dtype: object
In [12]: string_data.isnull()
Out[12]:
0 False
1 False
2 True
3 False
dtype: bool
Python内置的None值在对象数组中也可以作为NA:
In [13]: string_data[0] = None
In [14]: string_data.isnull()
Out[14]:
0 True
1 False
2 True
3 False
dtype: bool

而对于DataFrame对象,事情就有点复杂了。你可能希望丢弃全NA或含有NA的行或列。dropna默认丢弃任何含有缺失值的行:
In [19]: data = pd.DataFrame([[1., 6.5, 3.], [1., NA, NA],
....: [NA, NA, NA], [NA, 6.5, 3.]])
In [20]: cleaned = data.dropna()
In [21]: data
Out[21]:
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
2 NaN NaN NaN
3 NaN 6.5 3.0
In [22]: cleaned
Out[22]:
0 1 2
0 1.0 6.5 3.0
传入how='all'将只丢弃全为NA的那些行:
In [23]: data.dropna(how='all')
Out[23]:
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
3 NaN 6.5 3.0
用这种方式丢弃列,只需传入axis=1即可:
In [24]: data[4] = NA
In [25]: data
Out[25]:
0 1 2 4
0 1.0 6.5 3.0 NaN
1 1.0 NaN NaN NaN
2 NaN NaN NaN NaN
3 NaN 6.5 3.0 NaN
In [26]: data.dropna(axis=1, how='all')
Out[26]:
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
2 NaN NaN NaN
3 NaN 6.5 3.0
另一个滤除DataFrame行的问题涉及时间序列数据。假设你只想留下一部分观测数据,可以用thresh参数实现此目的:
In [27]: df = pd.DataFrame(np.random.randn(7, 3))
In [28]: df.iloc[:4, 1] = NA
In [29]: df.iloc[:2, 2] = NA
In [30]: df
Out[30]:
0 1 2
0 -0.204708 NaN NaN
1 -0.555730 NaN NaN
2 0.092908 NaN 0.769023
3 1.246435 NaN -1.296221
4 0.274992 0.228913 1.352917
5 0.886429 -2.001637 -0.371843
6 1.669025 -0.438570 -0.539741
In [31]: df.dropna()
Out[31]:
0 1 2
4 0.274992 0.228913 1.352917
5 0.886429 -2.001637 -0.371843
6 1.669025 -0.438570 -0.539741
In [32]: df.dropna(thresh=2)
# 去除有2列为空的行数据
Out[32]:
0 1 2
2 0.092908 NaN 0.769023
3 1.246435 NaN -1.296221
4 0.274992 0.228913 1.352917
5 0.886429 -2.001637 -0.371843
6 1.669025 -0.438570 -0.539741
7.2 数据转换
移除重复数据
drop_duplicates方法,它会返回一个DataFrame,重复的数组会标为False:
In [48]: data.drop_duplicates()
Out[48]:
k1 k2
0 one 1
1 two 1
2 one 2
3 two 3
4 one 3
5 two 4
这两个方法默认会判断全部列,你也可以指定部分列进行重复项判断。假设我们还有一列值,且只希望根据k1列过滤重复项:
In [49]: data['v1'] = range(7)
In [50]: data.drop_duplicates(['k1'])
Out[50]:
k1 k2 v1
0 one 1 0
1 two 1 1
duplicated和drop_duplicates默认保留的是第一个出现的值组合。传入keep='last'则保留最后一个:
In [51]: data.drop_duplicates(['k1', 'k2'], keep='last')
Out[51]:
k1 k2 v1
0 one 1 0
1 two 1 1
2 one 2 2
3 two 3 3
4 one 3 4
6 two 4 6
利用函数或映射进行数据转换(map函数)
对于许多数据集,你可能希望根据数组、Series或DataFrame列中的值来实现转换工作。我们来看看下面这组有关肉类的数据:
In [52]: data = pd.DataFrame({'food': ['bacon', 'pulled pork', 'bacon',
....: 'Pastrami', 'corned beef', 'Bacon',
....: 'pastrami', 'honey ham', 'nova lox'],
....: 'ounces': [4, 3, 12, 6, 7.5, 8, 3, 5, 6]})
In [53]: data
Out[53]:
food ounces
0 bacon 4.0
1 pulled pork 3.0
2 bacon 12.0
3 Pastrami 6.0
4 corned beef 7.5
5 Bacon 8.0
6 pastrami 3.0
7 honey ham 5.0
8 nova lox 6.0
假设你想要添加一列表示该肉类食物来源的动物类型。我们先编写一个不同肉类到动物的映射:
meat_to_animal = {
'bacon': 'pig',
'pulled pork': 'pig',
'pastrami': 'cow',
'corned beef': 'cow',
'honey ham': 'pig',
'nova lox': 'salmon'
}
Series的map方法可以接受一个函数或含有映射关系的字典型对象,但是这里有一个小问题,即有些肉类的首字母大写了,而另一些则没有。因此,我们还需要使用Series的str.lower方法,将各个值转换为小写:
In [55]: lowercased = data['food'].str.lower()
In [56]: lowercased
Out[56]:
0 bacon
1 pulled pork
2 bacon
3 pastrami
4 corned beef
5 bacon
6 pastrami
7 honey ham
8 nova lox
Name: food, dtype: object
In [57]: data['animal'] = lowercased.map(meat_to_animal)
In [58]: data
Out[58]:
food ounces animal
0 bacon 4.0 pig
1 pulled pork 3.0 pig
2 bacon 12.0 pig
3 Pastrami 6.0 cow
4 corned beef 7.5 cow
5 Bacon 8.0 pig
6 pastrami 3.0 cow
7 honey ham 5.0 pig
8 nova lox 6.0 salmon
离散化和面元划分(分桶)
为了便于分析,连续数据常常被离散化或拆分为“面元”(bin)。假设有一组人员数据,而你希望将它们划分为不同的年龄组:
In [75]: ages = [20, 22, 25, 27, 21, 23, 37, 31, 61, 45, 41, 32]
In [76]: bins = [18, 25, 35, 60, 100]
In [77]: cats = pd.cut(ages, bins)
In [81]: pd.value_counts(cats)
Out[81]:
(18, 25] 5
(35, 60] 3
(25, 35] 3
(60, 100] 1
dtype: int64
跟“区间”的数学符号一样,圆括号表示开端,而方括号则表示闭端(包括)。哪边是闭端可以通过right=False进行修改:
In [82]: pd.cut(ages, [18, 26, 36, 61, 100], right=False)
Out[82]:
[[18, 26), [18, 26), [18, 26), [26, 36), [18, 26), ..., [26, 36), [61, 100), [36,
61), [36, 61), [26, 36)]
Length: 12
Categories (4, interval[int64]): [[18, 26) < [26, 36) < [36, 61) < [61, 100)]
你可 以通过传递一个列表或数组到labels,设置自己的面元名称,而且利用values_counts函数进行统计会带有标签:
In [83]: group_names = ['Youth', 'YoungAdult', 'MiddleAged', 'Senior']
In [84]: pd.cut(ages, bins, labels=group_names)
Out[84]:
[Youth, Youth, Youth, YoungAdult, Youth, ..., YoungAdult, Senior, MiddleAged, Mid
dleAged, YoungAdult]
Length: 12
Categories (4, object): [Youth < YoungAdult < MiddleAged < Senior]
qcut是一个非常类似于cut的函数,它可以根据样本分位数对数据进行面元划分。根据数据的分布情况,cut可能无法使各个面元中含有相同数量的数据点。而qcut由于使用的是样本分位数,因此可以得到大小基本相等的面元:
In [87]: data = np.random.randn(1000) # Normally distributed
In [88]: cats = pd.qcut(data, 4) # Cut into quartiles
In [89]: cats
Out[89]:
[(-0.0265, 0.62], (0.62, 3.928], (-0.68, -0.0265], (0.62, 3.928], (-0.0265, 0.62]
, ..., (-0.68, -0.0265], (-0.68, -0.0265], (-2.95, -0.68], (0.62, 3.928], (-0.68,
-0.0265]]
Length: 1000
Categories (4, interval[float64]): [(-2.95, -0.68] < (-0.68, -0.0265] < (-0.0265,
0.62] <
(0.62, 3.928]]
In [90]: pd.value_counts(cats)
Out[90]:
(0.62, 3.928] 250
(-0.0265, 0.62] 250
(-0.68, -0.0265] 250
(-2.95, -0.68] 250
dtype: int64
与cut类似,你也可以传递自定义的分位数(0到1之间的数值,包含端点):
In [91]: pd.qcut(data, [0, 0.1, 0.5, 0.9, 1.])
Out[91]:
[(-0.0265, 1.286], (-0.0265, 1.286], (-1.187, -0.0265], (-0.0265, 1.286], (-0.026
5, 1.286], ..., (-1.187, -0.0265], (-1.187, -0.0265], (-2.95, -1.187], (-0.0265,
1.286], (-1.187, -0.0265]]
Length: 1000
Categories (4, interval[float64]): [(-2.95, -1.187] < (-1.187, -0.0265] < (-0.026
5, 1.286] <
(1.286, 3.928]]
检测和过滤异常值
过滤或变换异常值(outlier)在很大程度上就是运用数组运算。来看一个含有正态分布数据的
DataFrame:
In [92]: data = pd.DataFrame(np.random.randn(1000, 4))
In [93]: data.describe()
Out[93]:
0 1 2 3
count 1000.000000 1000.000000 1000.000000 1000.000000
mean 0.049091 0.026112 -0.002544 -0.051827
std 0.996947 1.007458 0.995232 0.998311
min -3.645860 -3.184377 -3.745356 -3.428254
25% -0.599807 -0.612162 -0.687373 -0.747478
50% 0.047101 -0.013609 -0.022158 -0.088274
75% 0.756646 0.695298 0.699046 0.623331
max 2.653656 3.525865 2.735527 3.366626
假设你想要找出某列中绝对值大小超过3的值:
In [94]: col = data[2]
In [95]: col[np.abs(col) > 3]
Out[95]:
41 -3.399312
136 -3.745356
Name: 2, dtype: float64
要选出全部含有“超过3或-3的值”的行,你可以在布尔型DataFrame中使用any方法:
In [96]: data[(np.abs(data) > 3).any(1)]
Out[96]:
0 1 2 3
41 0.457246 -0.025907 -3.399312 -0.974657
60 1.951312 3.260383 0.963301 1.201206
136 0.508391 -0.196713 -3.745356 -1.520113
235 -0.242459 -3.056990 1.918403 -0.578828
258 0.682841 0.326045 0.425384 -3.428254
322 1.179227 -3.184377 1.369891 -1.074833
544 -3.548824 1.553205 -2.186301 1.277104
635 -0.578093 0.193299 1.397822 3.366626
782 -0.207434 3.525865 0.283070 0.544635
803 -3.645860 0.255475 -0.549574 -1.907459
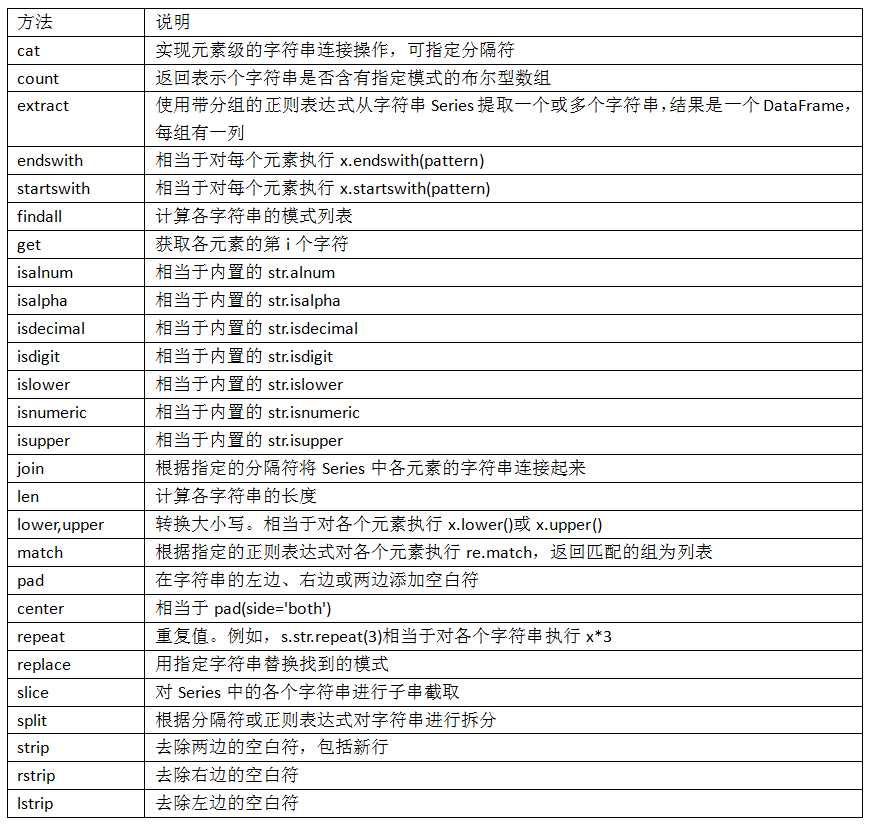
7.3 字符串操作
字符串对象方法
对于许多字符串处理和脚本应用,内置的字符串方法已经能够满足要求了。例如,以逗号分隔的字符串可以用split拆分成数段:
In [134]: val = 'a,b, guido'
In [135]: val.split(',')
Out[135]: ['a', 'b', ' guido']
split常常与strip一起使用,以去除空白符(包括换行符):
In [136]: pieces = [x.strip() for x in val.split(',')]
In [137]: pieces
Out[137]: ['a', 'b', 'guido']
一种更快更符合Python风格的方式是,向字符串"::"的join方法传入一个列表或元组:
In [140]: '::'.join(pieces)
Out[140]: 'a::b::guido'
其它方法关注的是子串定位。检测子串的最佳方式是利用Python的in关键字,还可以使用index和find:
In [141]: 'guido' in val
Out[141]: True
In [142]: val.index(',')
Out[142]: 1
In [143]: val.find(':')
Out[143]: -1
注意find和index的区别:如果找不到字符串,index将会引发一个异常(而不是返回-1):
In [144]: val.index(':')
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
in ()
----> 1 val.index(':')
ValueError: substring not found
与此相关,count可以返回指定子串的出现次数:
In [145]: val.count(',')
Out[145]: 2
replace用于将指定模式替换为另一个模式。通过传入空字符串,它也常常用于删除模式:
In [146]: val.replace(',', '::')
Out[146]: 'a::b:: guido'
In [147]: val.replace(',', '')
Out[147]: 'ab guido'


正则表达式
re模块的函数可以分为三个大类:模式匹配、替换以及拆分。当然,它们之间是相辅相成的。一个regex描述了需要在文本中定位的一个模式,它可以用于许多目的。我们先来看一个简单的例子:假设我想要拆分一个字符串,分隔符为数量不定的一组空白符(制表符、空格、换行符等)。描述一个或多个空白符的regex是\s+:
In [148]: import re
In [149]: text = "foo bar\t baz \tqux"
In [150]: re.split('\s+', text)
# \s+为多个空白符
Out[150]: ['foo', 'bar', 'baz', 'qux']
调用re.split('\s+',text)时,正则表达式会先被编译,然后再在text上调用其split方法。你可以用re.compile自己编译regex以得到一个可重用的regex对象:
In [151]: regex = re.compile('\s+')
In [152]: regex.split(text)
Out[152]: ['foo', 'bar', 'baz', 'qux']
如果打算对许多字符串应用同一条正则表达式,强烈建议通过re.compile创建regex对象。这样将可以节省大量的CPU时间。
match和search跟findall功能类似。findall返回的是字符串中所有的匹配项,而search则只返回第一个匹配项。match更加严格,它只匹配字符串的首部。来看一个小例子,假设我们有一段文本以及一条能够识别大部分电子邮件地址的正则表达式:
text = """Dave [email protected]
Steve [email protected]
Rob [email protected]
Ryan [email protected]
"""
pattern = r'[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,4}'
# 字母数字或者. _ % + -
# re.IGNORECASE makes the regex case-insensitive
regex = re.compile(pattern, flags=re.IGNORECASE)
# flags=re.IGNORECASE忽略大小写
sub还能通过诸如\1、\2之类的特殊符号访问各匹配项中的分组。符号\1对应第一个匹配的组,\2对应第二个匹配的组,以此类推:
In [166]: print(regex.sub(r'Username: \1, Domain: \2, Suffix: \3', text))
Dave Username: dave, Domain: google, Suffix: com
Steve Username: steve, Domain: gmail, Suffix: com
Rob Username: rob, Domain: gmail, Suffix: com
Ryan Username: ryan, Domain: yahoo, Suffix: com