java大数据hadoop2.9.2 Java编写Hadoop分析平均成绩
1、准备文件,例如score.txt,内容如下:
zs k1 88
ls k1 98
ww k1 78
zs k2 88
ls k2 98
ww k2 78
zs k3 88
ls k3 98
ww k3 782、创建maven项目
org.apache.hadoop
hadoop-common
2.9.2
org.apache.hadoop
hadoop-client
${hadoop.version}
org.apache.hadoop
hadoop-hdfs
${hadoop.version}
org.apache.hadoop
hadoop-mapreduce-client-core
${hadoop.version}
3、编写代码
(1)读取文件数据
package cn.com.dfs.score;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.util.LineReader;
public class ScoreRecoderReader extends RecordReader {
// 起始位置(相对整个分片而言)
private long start;
// 结束位置(相对整个分片而言)
private long end;
// 当前位置
private long pos;
// 文件输入流
private FSDataInputStream fin = null;
// key、value
private Text key = null;
private Text value = null;
// 定义行阅读器(hadoop.util包下的类)
private LineReader reader = null;
@Override
public void close() throws IOException {
if (this.fin != null) {
this.fin.close();
}
}
@Override
public Text getCurrentKey() throws IOException, InterruptedException {
return this.key;
}
@Override
public Text getCurrentValue() throws IOException, InterruptedException {
return this.value;
}
@Override
public float getProgress() throws IOException, InterruptedException {
if (start == end) {
return 0.0f;
} else {
return Math.min(1.0f, (pos - start) / (float) (end - start));
}
}
@Override
public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
// 获取分片
FileSplit fileSplit = (FileSplit) split;
// 获取起始位置
start = fileSplit.getStart();
// 获取结束位置
end = start + fileSplit.getLength();
// 创建配置
Configuration conf = context.getConfiguration();
// 获取文件路径
Path path = fileSplit.getPath();
// 根据路径获取文件系统
FileSystem fileSystem = path.getFileSystem(conf);
// 打开文件输入流
fin = fileSystem.open(path);
// 找到开始位置开始读取
fin.seek(start);
// 创建阅读器
reader = new LineReader(fin);
// 将当期位置置为1
pos = this.start;
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
boolean bool = false;
Text lineText = new Text();
// 读取一行数据
int count = this.reader.readLine(lineText);
if(count != 0) {
String line = lineText.toString();
String[] content = line.split(" ");
this.key = new Text(content[0]);
this.value = new Text(content[1]+":"+content[2]);
bool = true;
}
return bool;
}
}
(2)格式化
public class ScoreInputFormat extends FileInputFormat {
@Override
public RecordReader createRecordReader(InputSplit arg0, TaskAttemptContext arg1)
throws IOException, InterruptedException {
return new ScoreRecoderReader();
}
} (3)mapper操作
package cn.com.dfs.score;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class ScoreMapper extends Mapper {
// 从输入的value中获取分数
// 输出key-名称 value-》分数
@Override
protected void map(Text key, Text value, Mapper.Context context)
throws IOException, InterruptedException {
String kmScore = value.toString();
String[] content = kmScore.split(":");
int score = Integer.parseInt(content[1]);
context.write(key, new DoubleWritable(score));
}
}
(4)reduce操作
package cn.com.dfs.score;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class ScoreReduce extends Reducer {
@Override
protected void reduce(Text arg0, Iterable arg1,
Reducer.Context arg2) throws IOException, InterruptedException {
double sum = 0;
int count = 0;
for(DoubleWritable num:arg1) {
sum += num.get();
count++;
}
sum = sum/count;
arg2.write(arg0, new DoubleWritable(sum));
}
}
(5)执行操作
package cn.com.dfs.score;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class ScoreDriver {
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "My WordCount Demo Job");
job.setJarByClass(ScoreDriver.class);
job.setInputFormatClass(ScoreInputFormat.class);
job.setMapperClass(ScoreMapper.class);
job.setReducerClass(ScoreReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DoubleWritable.class);
FileInputFormat.addInputPath(job, new Path("/demo/score/input"));
FileOutputFormat.setOutputPath(job, new Path("/demo/score/output"));
System.exit(job.waitForCompletion(true)?0:1);
}
}
这几个类编写完成后,执行maven打包操作
mvn install
4、上传文件
例如把打包的maven项目的jar和score.txt文件上传到自己的目录/usr/local/jar
cd /usr/local/jar
hdfs dfs -mkdir /demo/score/input
hdfs dfs -put ./score.txt /demo/score/input
下面的命令是执行jar包的类中的main函数
hadoop jar ./HadoopDfs-0.0.1-SNAPSHOT.jar cn.com.dfs.score.ScoreDriver
任务开始执行,执行完成如下
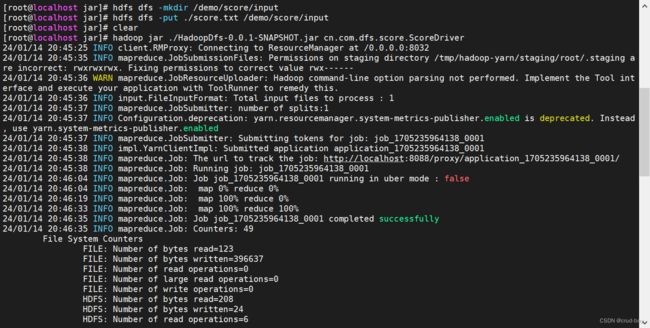
hdfs dfs -cat /demo/score/output/part-r-00000
part-r-00000任务执行完成生成的,会分析出每个学生的平均成绩