CSC8012_Software Development Techniques and Tools
Inheritance
▶Inheritance is a mechanism that allows us to define one class as an extension of another.
▶ It allows us to create two classes that are similar without the need to write the identical part twice.
▶ A new class derived from an existing class is called a subclass (or child class) of the existing class.
▶ The original class from which the other class is derived is called a superclass (or parent class).
▶ The subclass inherits the properties of the superclass and can have more fields and methods than its parent. This is why we say that the subclass extends the superclass.
▶ In Java a class can extend the definition of only one class.
▶ However, more than one class can inherit from the same superclass.
▶ Inheritance is transitive: that means that if a is a child class of b, and b is a child class of c, then c is related by inheritance to a.
▶ Classes can form an inheritance hierarchy.
继承是一种机制,允许我们将一个类定义为另一个类的扩展。
它允许我们创建两个相似的类,而不需要两次编写相同的部分。
从现有类派生的新类称为现有类的子类(或子类)。
派生另一个类的原始类称为超类(或父类)。
子类继承父类的属性,并且可以比父类拥有更多的字段和方法。这就是为什么我们说子类扩展了超类。
在Java中,一个类只能扩展一个类的定义。
但是,多个类可以从同一个超类继承。
继承是可传递的:这意味着如果a是B的子类,而B是c的子类,那么c通过继承与a相关。
类可以形成继承层次结构。
▶ General syntax:
public class ClassName extends ExistingClassName
{
// class members
}
Superclasses and Subclasses
▶ The private members of the superclass are private to the superclass. Hence, the methods of the subclass cannot directly access them.
▶ The subclass can directly access the public members of the superclass.
▶ The subclass can have additional fields and/or methods.
▶ The subclass can overload the public methods of the superclass.
That means, in the subclass, you can have a method with the same name as a method in the superclass, but different number and/or
types of parameters.
▶ The subclass can override (redefine) the public methods of the
superclass. That means, in the subclass, you can have a method with
the same name, number and types of parameters as a method in the
superclass. However, this redefinition applies only to the objects of
the subclass, and not to the objects of the superclass.
▶ All fields of the superclass are also fields of the subclass.
▶ The methods of the superclass (unless overridden) are also methods
of the subclass.
超类的私有成员对于超类是私有的。因此,子类的方法不能直接访问它们。
子类可以直接访问超类的公共成员。
子类可以有额外的字段和/或方法。
子类可以重载超类的公共方法。这意味着,在子类中,你可以有一个与超类中的方法同名的方法,但是不同的编号和/或参数的类型。
子类可以重写(重定义)超类的公共方法。这意味着,在子类中,您可以使用超类中的方法的参数的名称、数量和类型相同。然而,这种重新定义仅适用于子类对象而不是超类的对象。
超类的所有字段也是子类的字段。
超类的方法(除非被重写)也是子类的方法。
Constructors of the Superclass and Subclass
▶ When an object is created, the constructor of that object makes sure that all object fields are initialised to some reasonable state.
▶ When a subclass object is created, it inherits the fields of the superclass, but the subclass object cannot directly access the private fields of the superclass. The constructors of the subclass can directly initialise only the fields of the subclass.
To initialise the private inherited fields we need to call one of the constructors of the superclass.
▶ To call a constructor of the superclass we use the keyword super
▶ For a constructor without parameters
super();
▶ For a constructor with parameters
super(actual parameter list);
▶ A call to the constructor of the superclass must be the first statement in the body of a constructor of the subclass
当一个对象被创建时,该对象的构造函数确保所有对象字段都被初始化为某种合理的状态。
当子类对象被创建时,它继承了超类的字段,但子类对象不能直接访问超类的私有字段。子类的构造函数只能直接初始化子类的字段。
为了初始化私有继承字段,我们需要调用超类的一个构造函数。
要调用超类的构造函数,我们使用关键字super
对于没有参数的构造函数
super();
对于带参数的构造函数
super(实际参数列表);
对超类构造函数的调用必须是子类构造函数体中的第一条语句
protected Members of a Class
▶ The private members of the superclass are private to the superclass. The methods of the subclass cannot directly access them.
▶ In our last example, we had the following field declarations:
private String name; //in the Animal class
private int grassNeeded; //in the Herbivore class
▶ The above private fields can be accessed in the Elephant class
using public methods of the Animal and Herbivore classes.
public void printCharacteristics()
{
System.out.print(getName() + " ");
System.out.print(getGrassWeight() + " ");
System.out.println(tuskLength + " ");
}
▶ The superclass can give direct access to its private members to the
subclasses by declaring them protected instead.
▶ protected members of the superclass can be accessed directly in
the subclasses. They can be also accessed directly in other classes in
the same package.
超类的私有成员对于超类子类的方法不能直接访问它们。
在我们的最后一个例子中,我们有以下字段声明:
private String name; //在Animal类中
private int grassNeeded; //在Herbivore类中
以上私有字段可以在Elephant类中访问
使用Animal和Herbivore类的公共方法。
public void printCharacteristics()
{
System.out. println();
System.out. println();
System.out.println();
}
超类可以给予子类直接访问其私有成员的权限,而不是声明它们受保护。
超类的受保护成员可以直接被子类访问。其他类也可以直接访问它们,在相同的包下。
Dynamic Binding
▶ When there are several versions of a method in a hierarchy(because it was overridden), the one in the closest subclass to an object is always used.
▶ So, what happens when an object of the subclass is assigned to a variable of the superclass’s type?
Animal a, aRef;
Herbivore h;
a = new Animal(“Lion”);
a.printInfo(); // calls Animal version of printInfo
h = new Herbivore(“Rhino”,200);
h.printInfo(); // calls Herbivore version of printInfo
aRef = h;
aRef.printInfo(); // calls Herbivore version of printInfo
▶ Even though aRef was declared as a variable of the type
Animal, when the program executes, in the last statement the printInfo method of the Herbivore class is called. This is called dynamic binding — the method to call is determined at execution time rather than at compile time.
当层次结构中有多个版本的方法时(因为它被重写了),总是使用与对象最近的子类中的那个。
那么,当子类的一个对象被赋给超类类型的一个变量时会发生什么呢?
动物a,aRef;
草食动物h;
a = new Animal(“Lion”);
a.printInfo(); //调用printInfo的Animal版本
h = new Herbivore(“Rhino”,200);
h.printInfo(); //调用printInfo的Herbivore版本
return h;
aRef.printInfo(); //调用printInfo的草食动物版本
即使aRef被声明为类型为Animal,当程序执行时,在最后一条语句中调用Herbivore类的printInfo方法。这被称为动态绑定–要调用的方法是在执行时而不是在编译时确定的。
Abstract Classes
▶ An abstract method is a method that has only the heading, with no
body. The heading of an abstract method contains the reserved word
abstract and ends with a semicolon. For example:
public void abstract print();
▶ An abstract class is a class that is declared with the reserved word
abstract in the heading:
public abstract class ClassName { … }
▶ An abstract class can contain instance variables, constructors and non-abstract methods.
▶ An abstract class can contain abstract method(s).
▶ If a class contains an abstract method, then it must be declared as abstract.
▶ You cannot instantiate an object of an abstract class type. You can only declare a reference variable of an abstract class type.
▶ You can instantiate an object of a subclass of an abstract class,but only if the subclass implements (defines) all the abstract methods of the superclass.
▶ Abstract classes are used as superclasses from which other subclasses within the same context can be derived. They can implement their shared behaviour.
抽象方法是一种只有方法名,没有方法体的方法。
身体抽象方法的标题包含保留字
abstract抽象and ends结束with a pronouns子.举例来说:
public void print();
抽象类是用保留字声明的类。
标题中的摘要:
public abstract class Class { }
抽象类可以包含实例变量、构造函数和非抽象方法。
抽象类可以包含抽象方法。
如果一个类包含一个抽象方法,那么它必须被声明为抽象的。
不能实例化抽象类类型的对象。只能声明抽象类类型的引用变量。
你可以实例化一个抽象类的一个子类的一个对象,但前提是这个子类实现(定义)了超类的所有抽象方法。
抽象类被用作超类,从它可以派生出同一上下文中的其他子类。他们可以实现他们的共同行为。
Polymorphism
▶ Method names in Java are polymorphic (literally, have many shapes). They have a different meaning depending on the context.
▶ Method polymorphism is achieved in Java by:
▶ method overloading in classes;
▶ method overriding in subclasses and
▶ having methods with the same name (but different implementations) in different classes that implement the same interface.
▶ Reference variables in Java are polymorphic. A variable can hold references to objects of many types: the declared type or any subtype of the declared type.
▶ When declaring a reference variable, we can use two different types on the left and right sides of the assignment operator:
StaticType var1 = new DynamicType(…);
var1 = new DifferentDynamicType(…);
▶ The same method call may at different times invoke different methods, depending on the dynamic type of the variable (due to dynamic binding).
Java中的方法名是多态的(字面上,有许多形状)。它们根据上下文有不同的含义。
Java中的方法多态性是通过以下方式实现的:
避免类中的方法重载;
在子类中重写方法,
在实现相同接口的不同类中使用同名(但实现不同)的方法。
Java中的引用变量是多态的。变量可以包含对许多类型的对象的引用:声明的类型或声明类型的任何子类型。
当声明引用变量时,我们可以在赋值运算符的左侧和右侧使用两种不同的类型:
System. out. println = new System. out. println();
var 1 = new DifferentDynamicType(.);
相同的方法调用可能在不同的时间调用不同的方法,这取决于变量的动态类型(由于动态绑定)。
Exceptions
▶ An exception is an occurrence of a failure during program execution.
▶ Examples:
▶ division by zero,
▶ inputting a letter when a number is being read in,
▶ referring to a file that cannot be found,
▶ using array index which is less than 0 or greater than or equal to the length of the array.
▶ Java provides a number of exception classes for different types of
exceptions. For the exceptions listed above, we have the following classes:
▶ ArithmeticException
▶ NumberFormatException
▶ FileNotFoundException
▶ ArrayIndexOutOfBoundsException
▶ Programmers are allowed to create their own exception classes.
▶ When an exception occurs in a method, an object of a specific exception class is created and “thrown”. The exception can be either “caught” and handled by the method or propagated to a higher level
异常是程序执行过程中出现的故障。
示例:
除以零,
当读入数字时,输入字母,
如果引用的文件找不到,
使用小于0或大于等于数组长度的数组索引进行重命名。
Java为不同类型的
例外.对于上面列出的例外情况,我们有以下类:
ArithmeticException
Number
错误文件未找到异常
ArrayIndexOutOfBoundsException
允许程序员创建自己的异常类。
当一个异常在一个方法中发生时,一个特定异常类的对象被创建并“抛出”。异常可以被方法“捕获”并处理,也可以传播到更高级别。
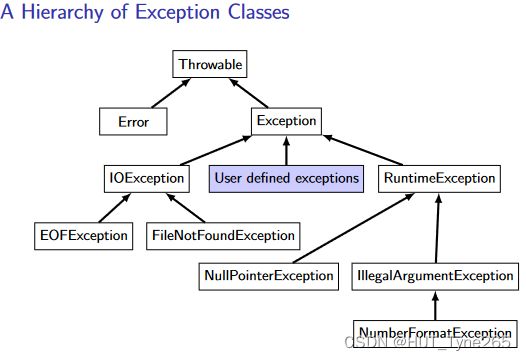
Explaining the Hierarchy
▶ The Throwable class, which is derived from the Object class,is the superclass of all the exception classes in Java.
▶ The Error class indicates a disaster of some kind — these are usually so serious that it is almost never worth catching them.
▶ The Exception class is the root of all classes of exceptions which are worth catching.
▶ The RuntimeException class and its subclasses indicate exceptions that are almost always the results of programming errors.
▶ The IOException class and its subclasses indicate exceptions which are thrown when something in the environment behaves badly.
▶ Programmers are allowed to create their own exception classes, by extending the Exception class or one of its subclasses.
Throwable类是从Object类派生的,是Java中所有异常类的超类。
Error类表示某种灾难-这些灾难通常非常严重,几乎不值得捕捉它们。
Exception类是所有值得捕获的异常类的根。
RuntimeException类及其子类指示几乎总是由编程错误导致的异常。
IOException类及其子类表示当环境中的某些行为不好时引发的异常。
允许程序员通过扩展Exception类或它的一个子类来创建自己的异常类。
▶ The Throwable class is contained in the java.lang package.
▶ It contains some useful methods which are inherited by its subclasses:
▶ public String getMessage()
returns the detailed message stored in this object.
▶ public String toString()
returns the detailed message stored in this object as well as the name of the exception class.
▶ public void printStackTrace()
prints the sequence of method calls when an exception occurs
Checked and Unchecked Exceptions
▶ Java’s predefined exceptions are divided into two categories:
checked exceptions and unchecked exceptions.
▶ Any exception that can be detected by the compiler is called a
checked exception. For example, FileNotFountExceptions and IOExceptions are checked exceptions.
▶ If a checked exception occurs in a method, then the method can either handle this exception or throw it to a higher level.
In the latter case, it must include an appropriate throws clause in its heading.
▶ An exception that cannot be detected by the compiler is called an unchecked exception. For example,RuntimeExceptions are unchecked exceptions.
▶ If an unchecked exception occurs in a method, then the method does not need to include any throws clause in its heading when throwing this exception to a higher level.
Java的预定义异常分为两类:
检查异常和未检查异常。
编译器可以检测到的任何异常都称为
检查异常。例如,FileNotFoundException和IOException是检查异常。
如果一个方法中发生了一个检查异常,那么这个方法可以处理这个异常,也可以将它抛出到更高的级别。
在后一种情况下,它必须在其标题中包含适当的throws子句。
编译器无法检测到的异常称为未检查异常。例如,运行时异常是未经检查的异常。
如果一个方法中发生了一个未检查的异常,那么当将这个异常抛出到更高的级别时,这个方法不需要在它的标题中包含任何throws子句。
try/catch/finally Block
▶ A try block contains the code you would normally write to carry out the standard task.
▶ Placing the code in the try block recognises that one or more possible exceptions may occur during its execution.
▶ The try block is followed by zero or more catch blocks.
▶ A catch block takes a parameter which defines the type of exception it is prepared to deal with, and contains a code to handle this type of exception.
▶ The last catch block may be followed by a finally block. If a try block has no catch block, then it must have a finally block.
▶ Executing the try/catch/finally block:
▶ If no exception occurs in a try block, all catch blocks associated with
the try block are ignored and program execution resumes after the last
catch block.
▶ If an exception occurs in a try block, the remaining statements in the
try block are ignored. The program searches the catch blocks (in the
order in which they appear after the try block) looking for an appropriate
exception handler (a catch block with the parameter type matching the
type of the thrown exception). If one is found, the code of that catch
block is executed and the remaining catch blocks are ignored.
▶ The finally block (if there is one) always executes regardless of whether an exception occurs or not.
try块包含了你通常用来执行标准任务的代码。
将代码放置在try块中可以识别在其执行期间可能发生的一个或多个异常。
try块后面跟着零个或多个catch块。
catch块接受一个参数,该参数定义了它准备处理的异常类型,并包含处理这种类型异常的代码。
最后一个catch块后面可以跟一个finally块。如果try块没有catch块,那么它必须有finally块。
执行try/catch/finally块:
如果try块中没有发生异常,则与try块被忽略,并且程序执行在最后一次捕获块。
如果try块中发生异常,try块被忽略。程序搜索catch块(在它们出现在try块之后的顺序),异常处理程序(参数类型与抛出的异常类型)。如果找到一个,则该捕获的代码块被执行,其余的catch块被忽略。
finally块(如果有的话)总是执行,不管是否发生异常。
Generic Programming
▶ Generic programming is the creation of programming constructs that can be used with many different types.
▶ In Java, generic programming can be achieved with inheritance or with type variables (discussed later).
▶ Inheritance allows us to assign an object of any type to a reference variable of type Object.
▶ Type variables can be substituted with any class or interface type.
▶ However, you cannot treat values of primitive types as objects.
Similarly, you cannot substitute any of the primitive types for a type variable. Java’s solution to this problem is wrapper classes. For example:
▶ The wrapper class for int is called Integer.
▶ The wrapper class for char is called Character.
▶ Whenever a value of a primitive type is used in a context that requires a wrapper type, it is automatically converted to an appropriate wrapper object. This is called autoboxing. The reverse operation, unboxing, is also performed automatically.
泛型编程是创建可以与许多不同类型一起使用的编程构造。
在Java中,泛型编程可以通过继承或类型变量(稍后讨论)来实现。
继承允许我们将任何类型的对象分配给Object类型的引用变量。
类型变量可以用任何类或接口类型替换。
但是,不能将基元类型的值视为对象。
同样,不能用任何基元类型替换类型变量。Java解决这个问题的方法是包装类。举例来说:
int的包装类称为int。
char的包装类叫做Character。
当在需要包装器类型的上下文中使用基元类型的值时,它会自动转换为适当的包装器对象。这被称为自动装箱。反向操作取消装箱也会自动执行。
▶ In Java, generic programming can be achieved with type variables.
▶ The java.util.ArrayList class is a generic class, which has been
declared with a type variable E. The type variable denotes the element
type:
public class ArrayList
{
public ArrayList() {…}
public void add(E element) {…}
…
}
▶ Type variables can be instantiated with class or interface types, or
wrapper types of primitive types. For example:
ArrayList triangles = new ArrayList();
ArrayList polygons = new ArrayList ();
ArrayList integers = new ArrayList();
Defining a Generic Method
▶ Generic methods can be defined inside ordinary and generic classes.
▶ We can define a generic method that depends on type variables using the following syntax:
modifiers
methodName(parameters)
{ body }
▶ For example:
public static void print(E[] a)
{
for(E e: a)
System.out.print(e + " ");
System.out.println();
}
▶ Type variables declared at the class level can only be used by non-static members and methods. So generic methods are particularly useful for defining static generic methods.
▶ When calling a generic method, it is necessary to instantiate the type
variables
Big-O Notation
▶ We can describe an algorithm’s performance by considering how many basic operations (assignments, number of comparisons etc.) are required for a given input of size n (e.g. an array with n items).
▶ Example: Consider an algorithm for displaying an array of numbers. For an input array of size n, how many operations are required?
▶ Big-O is a notation that gives a rough upper bound on an algorithm’s performance.
▶ It only considers dominant terms (as n approaches infinity):
2n + 5 = O(n)
n2 − 100n = O(n2)
2n + 5n4 = O(2n)
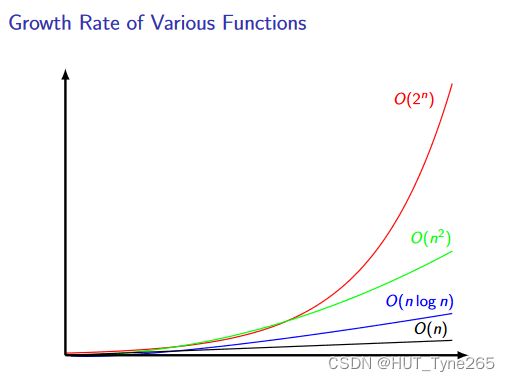
▶ Consider what happens if we double input size n for different
Big-O bounds:
O(1) Nothing (constant)
O(n) Doubles
O(n log n) Slightly more than double
O(n2) Factor of 4
O(n3) Factor of 8
O(2n) Square
Selection Sort
▶ Suppose we have an array with n items.
▶ Selection sort works by selecting the sorted items one at a time.
▶ The smallest item belongs in position 0 of the sorted array, so exchange it with whatever item is stored there.
▶ Now select the next smallest item from the n − 1 remaining items and store it at position 1.
▶ On the each subsequent iteration, select the smallest item from the remaining items and store it at the right position.
▶ After i iterations, the first i array locations will contain the first i smallest items in sort order. Thus, after n − 1 iterations, the whole array will be sorted.
假设我们有一个包含n个元素的数组。
选择排序的工作原理是一次选择一个已排序的项目。
最小的项属于排序数组的位置0,因此将其与存储在那里的任何项交换。
现在从剩下的n-1个项目中选择下一个最小的项目,并将其存储在位置1。
在每次后续的迭代中,从剩余的项目中选择最小的项目并将其存储在正确的位置。
在i次迭代之后,数组的前i个位置将包含排序顺序中的前i个最小项。因此,在n-1次迭代后,整个数组将被排序。
public static
{
E temp;
int minIndex;
for (int j=0; j
minIndex = j;
for (int k=j+1; k
if (a[k].compareTo(a[minIndex])<0)
{
minIndex = k;
}
}
temp = a[minIndex];
a[minIndex] = a[j];
a[j] = temp;
}
}
▶ For the array with n items we have:
▶ The number of assignments related to swaps:
3(n − 1) = O(n)
▶ The number of comparisons:
(n − 1) + (n − 2) + · · · + 2 + 1 = n(n − 1)/2 = O(n2)
▶ The performance of the algorithm is therefore O(n2)
▶ This algorithm is good only for small size arrays because O(n2) grows rapidly as n grows.
▶ The selection sort algorithm does not depend on the initial arrangement of data. The number of comparisons is always O(n2) and the number of assignments is O(n)
Insertion Sort
▶ The idea of Insertion sort is to sort the array from left to right.
▶ The array can be viewed as containing two parts: sorted and unsorted. At the beginning the sorted part contains only the item at position 0. The rest is considered unsorted.
▶ The items in the unsorted part are to be moved one at a time to their proper places in the sorted part.
▶ In each iteration, we take the first item of the unsorted part(called value) and all the items from the sorted part that should follow value are shifted by one position to the right to make room for value.
▶ After i iterations, the first i + 1 array items are sorted, so after n − 1 iterations the whole array is sorted.
▶ If the array is already nearly sorted, Insertion sort is very efficient.
插入排序的思想是从左到右对数组进行排序。
数组可以被看作包含两部分:排序和未排序。在开始时,排序部分仅包含位置0处的项。其余的被认为是未分类的。
未排序部分中的项目将一次一个地移动到排序部分中的适当位置。
在每次迭代中,我们取未排序部分的第一项(称为value),而所有来自排序部分的应跟随value的项都向右移动一个位置,为value腾出空间。
在i次迭代后,数组的前i + 1个元素被排序,所以在n-1次迭代后,整个数组被排序。
如果数组已经接近排序,插入排序是非常有效的。
public static
{
for (int i = 1; i < a.length; i++)
{
E value = a[i];
int j;
for (j = i; j > 0; j–)
{
if (a[j-1].compareTo(value)<0)
{
break;
}
else
{
a[j] = a[j-1];
}
}
a[j] = value;
}
}
▶ We analyse behaviour in terms of the number of comparisons
Cn needed for an array of size n.
▶ We always execute the outer loop n − 1 times.
▶ Best case: array is already sorted
▶ The inner loop exits after the first comparison.
▶ So Cn = n − 1.
▶ Performance is O(n).
▶ Worst case: array is in reverse order (i.e. descending)
▶ The inner loop is executes i times for i = 1, . . . , n − 1.
▶ So Cn = n(n − 1)/2.
▶ Performance is O(n2)
▶ Average case: behaviour on random data
▶ The inner loop is executed i/2 times for i = 1, . . . , n − 1.
▶ Approximately Cn = n2/4 comparisons.
▶ Performance is O(n2)
Other Sorting Algorithms
▶ There are other sorting algorithms. For example: Bubble sort,Shell sort, Merge sort, Quick sort.
▶ Merge sort and Quick sort are examples of divide-and-conquer algorithms: they partition the array and recursively sort the partitions.
▶ Elementary sorting algorithms which are based on comparing adjacent array items are usually O(n2).
▶ However, “divide-and-conquer” algorithms can have better performance:
▶ Merge sort is O(n log n).
▶ Quick sort, on average, makes O(n log n) comparisons to sort n items. In the worst case, however, it makes O(n2) comparisons, though this behaviour is rare. Quick sort is often
faster in practice than algorithms like Merge sort.
▶ It can be proved that any sorting algorithm which uses comparisons requires at least O(n log n) operations.
有其他的排序算法。例如:冒泡排序,Shell排序,合并排序,快速排序。
合并排序和快速排序是分治算法的例子:它们对数组进行分区,并对分区进行递归排序。
算法复杂度为O(n2),时间复杂度为O(n2)。
然而,“分而治之”算法可以有更好的性能:
时间复杂度为O(n)
快速排序,平均来说,对n个项目进行排序的比较是O(n log n)。但是,在最坏的情况下,它进行O(n2)比较,尽管这种行为很少见。快速排序通常
在实践中比像合并排序这样的算法更快。
可以证明任何使用比较的排序算法至少需要O(n log n)操作。
Sequential Search
▶ A sequential search of an array examines each item in turn,looking for a specific item.
▶ The search terminates when a matching item is found or when there are no items left.
▶ If the array is ordered, then it is possible to terminate the search sooner.
▶ Sometimes it is possible to rearrange the items in the array to speed up subsequent searches.
▶ However, all sequential searching algorithms are O(n) in the worst-case.
数组的顺序搜索依次检查每个项目,查找特定的项目。
搜索在找到匹配项或没有剩余项时终止。
如果数组是有序的,那么可以更快地终止搜索。
有时可以重新排列数组中的项目以加快后续搜索。
但是,所有的顺序搜索算法在最坏情况下都是O(n)的。
public static
int seqSearch(E[] a, E searchItem)
{
int loc;
boolean found = false;
for (loc = 0; loc < a.length; loc++)
{
if (a[loc].compareTo(searchItem) == 0)
{
found = true;
break;
}
}
if (found)
return loc;
else
return -1;
}
Ordered Searching
▶ A disadvantage of a sequential search is that it is necessary to examine every item in case the item we are looking for is not present. If the items of the array are sorted into order, then
the search can be terminated early.
▶ Assuming the items are sorted in increasing order, once a “bigger” item (according to the compareTo method) is found,there is no point in looking any further.
▶ But this is still an O(n) algorithm.
▶ If we are searching an ordered array, we can do much better using Binary Search.
顺序搜索的一个缺点是,如果我们正在寻找的项目不存在,则需要检查每个项目。如果数组中的项按顺序排序,则
则可以提前终止搜索。
假设这些项是按升序排序的,一旦找到了一个“更大”的项(根据compareTo方法),就没有必要再进一步查找了。
这是一个复杂度为O(n)的算法。
如果我们正在搜索一个有序数组,我们可以使用二进制搜索做得更好。
Binary Search
▶ A sequential search of an ordered array is still O(n) even though only half the items have to be examined on average.
However, an important property of an array is that you do not have to access its items in sequence.
▶ You can access any array item at constant cost i.e. array
access is O(1).
▶ It is possible to exploit this property to develop an O(log2 n) algorithm for searching a sorted array.
▶ At each stage, the array is divided into two roughly equal halves.
▶ By examining the item stored at the mid-point, it is easy to determine which half of the array might contain an item being sought (assuming such an item is present).
▶ Thus, at each stage the number of items to be searched is halved, so that after log2 n stages there is only one item left to be examined.
对有序数组的顺序搜索仍然是O(n),即使平均只有一半的项目需要检查。
但是,数组的一个重要属性是,您不必按顺序访问其项。
你可以以固定成本访问任何数组项,即数组时间复杂度为O(1)。
这是一个O(log2 n)的算法,可以用来搜索一个有序数组。
在每个阶段,阵列被分成大致相等的两半。
通过检查存储在中点的项,很容易确定数组的哪一半可能包含正在查找的项(假设存在这样的项)。
因此,在每一个阶段,要搜索的项目数量减半,这样在log2 n阶段之后,只剩下一个项目要检查。
public static
int binarySearch(E[] a, E searchItem)
{
int first = 0;
int last = a.length - 1;
int mid = -1;
boolean found = false;
while (first <= last && !found)
{
// comparing searchItem with the middle element of the
// currently examined portion of the array
}
if (found)
return mid;
else
return -1;
}
while (first <= last && !found)
{
mid = (first + last) / 2;
int result = a[mid].compareTo(searchItem);
if (result == 0)
found = true;
else
if (result > 0)
last = mid - 1;
else
first = mid + 1;
}
▶ Suppose a is a sorted array of size n.
▶ Moreover, suppose that n is a power of 2, for example:
n = 2m (m = log2 n).
▶ After each iteration of the while - loop about half the items are left to search. This means the search sub-array for the next iteration is half the size of the current sub-array. For example, after the first iteration, the search sub-array is of size n/2 = 2m−1.
▶ The maximum number of iterations for the while loop is m + 1, and each iteration makes two comparisons
▶ So, the maximum number of comparisons to determine whether an item x is in a is:
2(m + 1) = 2(log2 n + 1) = 2 log2 n + 2 = O(log2 n).
▶ The Collections class of java.util package contains static sort and binarySearch methods:
▶ The sort method sorts the specified list into ascending order,according to the natural ordering of its elements. All elements in the list must implement the Comparable interface.
▶ The binarySearch method searches the specified list for the specified object using the binary search algorithm. The list must be sorted into ascending order according to the natural ordering of its elements prior to making this call. It returns the index of the search object, if it is contained in the list.
▶ These methods can be used to sort an ArrayList of objects:
int[] intArray = {13, 2, 10, 7, 1};
ArrayList integers = new ArrayList();
for (Integer i: intArray) integers.add(i);
Collections.sort(integers);
int index = Collections.binarySearch(integers, 10);
java.util包的Collections类包含静态排序和binarySearch方法:
sort方法根据元素的自然顺序将指定的列表按升序排序。列表中的所有元素都必须实现Comparable接口。
binarySearch方法使用二进制搜索算法在指定的列表中搜索指定的对象。在进行此调用之前,必须根据其元素的自然顺序将列表排序为升序。它返回搜索对象的索引,如果它包含在列表中。
Stack
▶ A stack is a way of organising a list of items so that only the most recently added item is accessible.
▶ This item is said to be at the top of the stack.
▶ It is as if the items were stacked on top of each other with only the top item being visible.
▶ Thus, one way to visualise a stack is as a tower of items. New items are added at the top of the stack.
▶ When a new item is added, the item that used to be at the top of the stack is hidden.
▶ When an item is removed from the stack, the item which it was hiding (the old top of the stack) becomes visible again.
Only the item on the top of the stack can be removed, so items are removed in the reverse of the order in which they were added.
堆栈是一种组织列表的方式,只有最近添加的数据才能访问。
此数据据说位于堆栈的顶部。
这就好像数据被堆叠在彼此的顶部,只有顶部的数据是可见的。
因此,一种可视化堆栈的方法是将其视为一个数据塔。新项将添加到堆栈的顶部。
当添加新项时,以前位于堆栈顶部的项将被隐藏。
当一个数据从堆栈中移除时,它隐藏的数据(旧的堆栈顶部)再次可见。
只有位于堆栈顶部的项才能被移除,因此项的移除顺序与它们的添加顺序相反。
The LIFO Property
▶ The last item to be added to a stack is at the top of the stack.
▶ The first item to be added to a stack is at the bottom of the stack.
▶ Items in between are ordered according to when they were added to the stack.
▶ The more recently an item has been added to a stack, the closer it is to the top of the stack.
▶ Only the item at the top of the stack can be removed, so only the most recently added item is accessible.
▶ Removing the top item exposes the next item (the next most recently added item) and makes it accessible.
▶ Thus, the order in which items can be removed from a stack is the reverse of the order in which they were added to the stack.
▶ In other words, items are removed from a stack in Last In,First Out or LIFO order - this is the LIFO property of a stack.
Real World Examples
▶ Stack of plates in a cafeteria
▶ Spring loaded
▶ Only the top plate accessible
▶ Often difficult to remove more than one plate at a time
▶ Trucks/carriages in a railway siding
▶ Buffer prevents access at one end
▶ Shunting engine can only couple to first truck
▶ Possible to remove more then one truck at a time
▶ Possible to add more than one truck at a time
▶ Several sidings are usually employed as stacks in tandem
▶ In-tray
▶ Jobs removed from the top
▶ Some jobs may remain in the in-tray forever
▶ Some sorting mechanism to impose priority essential
▶ Several trays (urgent, non-urgent) often employed
Stack Operations
▶ push(item)
▶ Add a new item to the top of the stack
▶ pop()
▶ Return and remove the most recent item
▶ peek()
▶ Return the value of the item at the top of the stack
▶ empty()
▶ A stack which contains no items is said to be empty
▶ Attempting to pop an empty stack is an error
▶ This error is sometimes referred to as stack underflow
▶ size()
▶ Return the number of elements on the stack
Stacks as Templates
▶ The items stored on a stack must all have the same type, e.g.Stack of Integer, Stack of BankAccount etc.
▶ However, the behaviour of a stack does not depend on the type of the items it stores.
▶ Thus, we want to be able to use the same definition of a Stack class, regardless of the type of items that the stack contains.
▶ To do this in Java, we use generic types.
Stack Interface
public interface Stack
{
public void push(E x);
public E pop() throws EmptyStackException;
public E peek() throws EmptyStackException;
public boolean empty();
public int size();
}
Stack Applications
▶ The LIFO property of stacks turns out to be just what is required to solve many problems.
▶ Stacks can be used to store a nested sequence of values that need to be retrieved in reverse order. Many problems have this kind of nested structure.
▶ For example, if a problem can be solved using a series of
nested steps, then a stack can be used to remember
intermediate results.
▶ Similarly, a stack can be used to simplify an algorithm that
has to process data with a nested structure. In particular,
stacks can be used to implement recursive algorithms.
▶ If an algorithm is recursive, then it needs to save a partial
result somewhere while it goes off and computes another
result recursively.
▶ As the recursion unwinds, these partial results are retrieved in
LIFO order so they could be stored on a stack.
Algorithm
▶ Ignore all the input characters except brackets.
▶ Use the stack to remember the start of each bracket pair and match the corresponding closing bracket.
▶ Push each opening bracket character onto the stack.
▶ When a closing bracket is found, pop the corresponding opening bracket off the top of the stack.
▶ If the brackets don’t match, then the program contains a syntax error.
Reverse Polish Notation
▶ Expressions involving operators with different precedences are
usually written using brackets e.g. (3 + 4) * 5 vs.
3 + (4 * 5).
▶ Using Reverse Polish Notation (RPN), operators such as +
and * are written after operands such as 3 and 4.
▶ Since each operator refers to the previous two operands or
results of operations, there is no need for brackets.
▶ For example:
▶ 3 4 + 5 * means the same as (3 + 4) * 5
▶ 3 4 5 * + means the same as 3 + (4 * 5)
▶ Calculators which work with RPN use a stack internally:
▶ Operands are pushed onto the stack.
▶ Operators take their operands off the stack and push the result
back on again - if there are not enough operands on the stack,
the expression is invalid.
▶ The result of the expression should be the only value left on
the stack at the end of the algorithm.
Evaluating RPN Expressions
public static void main(String[] args)
{
Stack stack = new ArrayStack();
try
{
String expression = “9 5 2 + -”; // or read from keyboard
String[] token = expression.split(" ");
for (int i=0; i
if (token[i].charAt(0) == ’+’)
{
int rhs = stack.pop();
int lhs = stack.pop();
stack.push(lhs + rhs);
}
else if (token[i].charAt(0) == ’-’)
{
int rhs = stack.pop();
int lhs = stack.pop();
stack.push(lhs - rhs);
}
else
{
stack.push(Integer.parseInt(token[i]));
}
} //end of for
System.out.println("Result is " + stack.pop());
} //end of try
catch (EmptyStackException e)
{
System.out.println(“Missing operand”);
}
if (!stack.empty())
System.out.println("ERROR - too many operands in the expression. " +
“The result is incorrect.”);
} //end of main
Implementing Stacks Using Arrays
▶ An array is a convenient place to store the items on a stack.
▶ However, the size of an array is fixed, whilst the number of items on a stack can vary.
▶ Thus, it is necessary to keep track of which part of the array is being used to store the contents of the stack.
▶ Typically, this will grow and shrink as items are pushed and popped from the stack.
▶ What happens when the array fills up?
▶ There are two possibilities:
▶ give a stack overflow error,
▶ expand the array.
▶ We will avoid overflow by expanding the array.
Keeping Track of the Top of the Stack
▶ An integer variable topOfStack is used as an array index to
keep track of the top of the stack.
▶ As items are pushed onto the stack, topOfStack is increased;as items are popped off the stack, topOfStack is decreased.
▶ There are two possible conventions for the value of topOfStack:
▶ topOfStack points to the item on the top of the stack
▶ topOfStack points to where the next item will be added.
▶ The difference is whether topOfStack must be incremented before or after pushing an item onto the stack.
▶ We will choose the first convention i.e. topOfStack will point to the position of the top item.
▶ Since an empty stack doesn’t have a top item, we shall use position -1 for this case.
▶ A stack is initially empty so the value of topOfStack should be initialised accordingly.
▶ Arrays are indexed from 0 in Java, so the first item will be added when topOfStack is at position -1.
▶ Thus, the Stack constructor must set the value of topOfStack to -1 to indicate that the stack is initially empty.
▶ If theArray can only hold DEFAULT_CAPACITY items, then the stack is full when topOfStack == DEFAULT_CAPACITY-1.
Stack Operations
▶ ArrayStack() // constructor
▶ create theArray object with some fixed size
▶ set topOfStack to -1
▶ empty()
▶ return (topOfStack == -1)
▶ size()
▶ return (topOfStack + 1)
▶ push(item)
if (stack is full)
{
expand array
}
increase topOfStack and store item in theArray[topOfStack].
▶ pop()
if (stack is empty)
{
throw stack underflow exception
}
return theArray[topOfStack] and decrement topOfStack
public class ArrayStack implements Stack
{
private E[] theArray;
private int topOfStack;
public static final int DEFAULT_CAPACITY = 20;
public ArrayStack()
{
theArray = (E[]) new Object[DEFAULT_CAPACITY];
topOfStack = -1;
}
public void push(E x)
{
if (topOfStack == theArray.length - 1)
{
doubleArray();
}
topOfStack++;
theArray[topOfStack] = x;
}
public E peek() throws EmptyStackException
{
if (empty())
{
throw new EmptyStackException(“Stack peek”);
}
return theArray[topOfStack];
}
public E pop() throws EmptyStackException
{
if (empty())
{
throw new EmptyStackException(“Stack pop”);
}
E result = theArray[topOfStack];
topOfStack–;
return result;
}
public boolean empty()
{
return topOfStack == -1;
}
public int size()
{
return topOfStack + 1;
}
// To expand an Array object, you need to create another
// reference to the array, create a new larger array
// and then copy the items across from the smaller array
private void doubleArray()
{
E[] temp = theArray;
theArray = (E[]) new Object[temp.length2];
// cannot say new E[temp.length2];
for (int i=0; i
theArray[i] = temp[i];
}
}
} // end of class
Expansion Factor
▶ How much bigger should the new array be? One approach would be to increase the size of the array by a fixed amount each time. However, expanding an array is an expensive operation because of all the copying involved.
▶ A good approach is to use an adaptive strategy and increase the array size in proportion to its current size. The bigger the array becomes, the more it is expanded by each time it overflows.
▶ For example, if the array size started at 16 and grew by 50%
each time the array was expanded, successive sizes would be:
16, 24, 36, 54, 81, 120, 180, 270 etc.
Queue
▶ A queue is a way of organising a list of items in order of arrival.
▶ Items arrive at the back of the queue and are eventually removed from the front of the queue.
▶ The item at the front of the queue arrived earlier than any of the other items in the queue.
▶ The item at the back of the queue was the last one to arrive.
▶ Items are removed from the queue in order of arrival.
▶ Thus, only the item at the front of the queue can be removed.
▶ New items are put at the back of the queue.
▶ A queue is a First In, First Out (FIFO) data structure, unlike a stack which is Last In, First Out (LIFO).
Real-world Examples
▶ Queues are used to resolve any situation which is “First Come,First Served” e.g. ticket returns at the Theatre Box Office.
▶ Queues are also used whenever there is a customer/server relationship:
▶ a queue at the stottie shop,
▶ a queue at the post office,
▶ a queue at the supermarket checkout.
▶ Customers arrive at the back of the queue and are served in turn as they reach the front of the queue.
▶ If there is more than one server, then it is fairest if there is only one queue.
▶ However, sometimes each server has their own queue and you have to guess which queue will move the fastest.
Queue Operations
▶ offer(item)
▶ Add a new item to the back of the queue if possible.
▶ The rest of the queue remains unchanged.
▶ poll()
▶ Return and remove the item stored at the front of the queue.
▶ The queue “moves up,” but remains in order.
▶ peek()
▶ Return the item stored at the front of the queue.
▶ empty()
▶ Is the queue empty?
▶ size()
▶ How many elements are on the queue?
Queue Interface
public interface Queue
{
public boolean empty();
public int size();
public boolean offer(E x);
public E peek(); // returns null if queue empty
public E poll(); // returns null if queue empty
}
Implementation Issues
▶ In theory, a queue can grow in size indefinitely and contain an arbitrary number of elements.
▶ In the real world, this might happen if the servers were too slow and customers arrived very quickly.
▶ In practice, customers arrive in bursts (e.g. everyone getting off a train or coming out of a lecture) and the queue only needs to be big enough to hold the biggest burst.
▶ A queue needs memory to hold all the elements which have been added to the queue and not yet removed.
▶ Like stacks, queues can be implemented using either a fixed amount of storage (arrays) or a variable amount (linked lists).
▶ We will show an implementation of Queue based on arrays.
从理论上讲,队列的大小可以无限增长,并包含任意数量的元素。
在真实的世界中,如果服务器速度太慢而客户到达非常快,则可能会发生这种情况。
在实践中,客户会突然到达(例如每个人都下车或演讲),队列只需要足够大,以容纳最大的突发事件。
一个队列需要内存来保存所有已经添加到队列中但尚未删除的元素。
与堆栈类似,队列可以使用固定数量的存储(数组)或可变数量的存储(链表)来实现。
我们将展示一个基于数组的队列实现。
▶ offer(item)
▶ if (queue is full)
{
return false
}
▶ increment back modulo n
▶ store item at theArray[back]
▶ increment currentSize
▶ return true
▶ poll()
▶ if (queue is empty)
{
return null
}
▶ remember the item at theArray[front] as the result
▶ increment front modulo n
▶ decrement currentSize
▶ return result
public class ArrayQueue implements Queue
{
private E[] theArray;
private int front;
private int back;
private int currentSize;
private static final int DEFAULT_CAPACITY = 20;
private int increment(int x)
{
return (x + 1) % theArray.length;
}
public ArrayQueue()
{
theArray = (E[]) new Object[DEFAULT_CAPACITY];
makeEmpty();
}
private void makeEmpty()
{
front = currentSize = 0;
back = -1;
}
public boolean empty()
{
return currentSize == 0;
}
public boolean offer(E x)
{
if (currentSize == theArray.length)
{
return false;
}
back = increment(back);
theArray[back] = x;
currentSize++;
return true;
}
public E peek()
{
if (empty())
{
return null;
}
return theArray[front];
}
public int size()
{
return currentSize;
}
public E poll()
{
if (empty())
{
return null;
}
E frontItem = theArray[front];
front = increment(front);
currentSize–;
return frontItem;
}
}