我就喜欢 6大"N饭"永不投诚经典语录
DX11性能大幅度领先对手
● DX11性能大幅度领先对手
如果说AMD的HD5000系列现在在2009年末发布拉开了DirectX 11的序幕,那NVIDIA此次发布的Fermi架构GTX400系列显卡,则是将一个更为完整和强大的DirectX 11技术带给了用户。因为DirectX11技术的两大关键点就是新增的专有硬件Tessellation(曲面细分)单元和利用Computer Shader做图形后处理。

DirectX 11为游戏带来的更多新奇美妙的特性
● 着色器版本提升到Shader Model 5.0,采用面向对象的概念,并且完全支持双精度数据。
● Tessellation曲面细分技术获得微软正式支持,逐渐走向成熟;
● Multithreading多线程处理,让图形处理面对多线程编程环境不再尴尬;
● 提出微软自己的Compute Shader通用计算概念,把GPU通用计算推向新的巅峰;
● 全新Texture Compression纹理压缩,在画质损失极小的环境下带来了硬件资源的节约。
早在2009年9月份就已经亮相的Radeon HD 5870当中,就包含了ATI的首款DX11显示核心——Cypress(RV870,官方正式代号为Cypress)。Cypress核心可以看到两组SIMD阵列呈对称型排列,其中每组阵列当中均有800个流处理单元设计。在单一SIMD引擎当中,ATI采用的排列方式依然是RV770的设计方式。
也就是说,每个SIMD阵列当中包含10组SIMD阵列,而每个SIMD阵列当中又包含16个流处理器,每个流处理器包含5个流处理单元,因此总计1600个流处理单元。两者通过相同的高速数据总线与L2 Cache相连,同时也连通到Global Data Share上进行数据共享。

ATI为了抢先发布DX11显卡,只是在上代产品的技术上添加了对DX11指令集的支持而已,并没有针对DX11新的渲染流程和关键技术做优化。如此一来HD5000在DX9C/DX10游戏中的表现依然出色,但在DX11游戏中就出现了瓶颈,DX11特性使用越多,其性能就越差。
从上面的架构图可以看出,Cypress更像是两个RV770核心的合体,而对于DX11技术的升级,主要集中在Graphics Engine当中。这样的设计方式,无疑更加简单,对于ATI的研发周期来说也会大幅缩短,这也是为何ATI的DX11产品会如此之早就能发布的一个重要原因。
● 完全针对DX11而设计的显卡——GTX480
HD5800这一领先,又是半年,这次NVIDIA的阵脚并没有像NV30那样被打乱,而是按部就班的按照既定的设计目标推出全新架构的一代产品,而不是像ATI那样在上代产品基础上改改就发布新品,因为DX11是全新的API,必须为DX11新的特性做相应的优化,才能获得最出色的DX11效能。
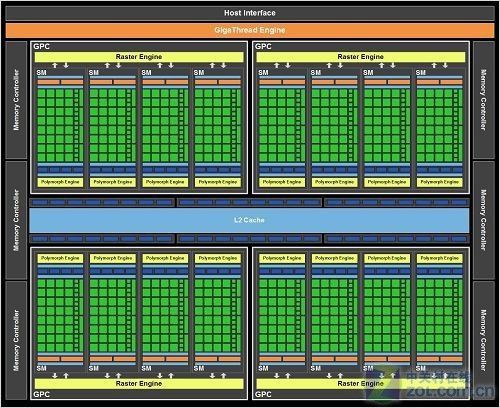
GF100核心是既G80和R600之后,近4年来GPU架构改进最大的一次。GF100核心主要划分为Host Interface(主接口,负责PCI-E通讯传输,包括读取CPU指令等)、GigaThread Engine(主线程调度引擎)、4组Graphics Processing Clusters(后文简称GPC,图形处理集群,GPU的核心部分)、6组Memory Controller(显存控制器,每组显存控制器位宽为64bit,总位宽384bit)、L2 Cache(二级缓存,容量为768KB)、6组ROP单元(每组包含8个ROP,共48个)。
通过以上分析可以看出,由于HD5800的架构与HD4800完全相同,只是流处理器规模翻倍而已,因此它确实拥有出色的DX10/10.1性能,但DX11的性能却很一般。因为DX11是一款全新的API,并不是针对DX10的小修小补,很多特性不是兼容SM5.0指令集就能做得到的。
ATI虽然通过抢先发布DX11显卡赚得了满堂彩,但却没能经得住时间的考验,未能重现DX9时代R300的辉煌。因为时代变了,当年的R300是全新的架构,完美支持DX9,而NV30架构存在很多缺陷。而现在正好相反,Cypress完全是RV770加上DirectX 11要求的硬件IC,而GF100则是真正的DX11架构,这在所有DX11测试中都得到了证实。
| 濮元恺所写过的技术分析类文章索引(持续更新) | |||
| NVIDIA/ATI命运转折 |
改变翻天覆地 |
显卡只能玩游戏? 10年GPU通用计算回顾 |
通用计算对决 |
| 从裸奔到全身武装 |
AMD统一渲染架构 |
浅析DirectX11技术 |
摩尔定律全靠它 |
| 我就喜欢 |
别浪费你的电脑 分布式计算在中国 |
从Folding@home项目 |
Computex独家泄密 解析AMD下代GPU |

史上最强GPU架构设计
● 史上最强GPU架构设计
GF100 GPU基于图形处理团簇(翻译为GPC),可扩展流阵列多处理器(SM)和内存控制器(MC)。一个完整GF100实现四个GPC,16个SM和6个内存控制器。通过对GPC的开启和关闭,对SM和内存控制器不同的配置,可以划分出满足不同价位的产品。所以我们也可以称GF100为一个4 GPC核心的GPU。

Fermi架构GF100功能单元分布
图中我们可以看到GF100的总线接口、GigaThread线程调度器、四个完整的GPC单元、六个内存控制器、六个ROP簇和768KB二级缓存。每个GPC单元包含四个多边形引擎。六个ROP簇紧邻二级缓存。
CPU的命令通过Host Interface总线接口传输到GPU。在GigaThread引擎会从系统内存提取指定数据,并把它们拷贝到指定的显存。 GF100集成了6个64位GDDR5内存控制器(共计384位),以便获得高带宽和低延迟。然后GigaThread引擎创建并调度这些block到各个SM,其次再到warp(每个warp包含32个threads线程)交给CUDA Core和其他执行单位。在GigaThread引擎重新分配工作时,图形流水线上的各个单元如细分曲面和光栅化之类的单元也会继续工作。
GF100拥有512个CUDA Core,它们属于16个SM单元,每个SM单元包括32个CUDA内核。每个SM是一个高度平行处理器,最多支持在任何规定时间完成对48个warp的处理 。每个CUDA Core是一个统一的处理器核心,执行顶点,像素,几何和kernel函数。一个统一的768KB二级缓存架构负责线程加载、存储和纹理操作。每组SM里四个纹理单元,共享使用12KB一级纹理缓存,并和整个芯片共享768KB二级缓存。每个纹理单元每周期可计算一个纹理寻址、拾取四个纹理采样,并支持DX11新的压缩纹理格式。

Fermi架构GF100核心照片
GF100拥有48个ROP单元,用来执行抗锯齿和原子内存操作。这48个ROP单元被分配为6组,每组8个,每组ROP配备一个内存控制器。内存控制器、L2高速缓存和ROP单元是紧密耦合的,也可以成组屏蔽。所有ROP单元和整个芯片共享768KB二级缓存(GT200里是独享)。
关于运行频率,在每一组SM阵列里,纹理单元、一二级缓存、ROP单元和各个单元的频率也都完全不同于以往。除了ROP单元和二级缓存,几乎其他所有单元的频率都和Shader频率(NVIDIA暂称之为GPC频率)关联在一起:一级缓存和Shader单元本身是全速,纹理单元、光栅引擎、多形体引擎则都是一半。
Fermi颠覆了G80以来的分频模式,曾今我们称固定单元的频率是GPU核心频率,而流处理器频率较高,它的速度是核心的2.15或者2.25倍。从Fermi开始“核心频率”就是流处理器频率(也可以称为GPC频率),而固定单元的频率默认为“核心频率”的一半,未来的超频模式肯定要发生变化了。
●Fermi GPC运算架构
我们可以这样认为:NVIDIA的第一代CUDA机构是从G80开始延伸至GT200,而GF100将是第二代CUDA架构产品。G80核心的诞生奠定了NVIDIA未来核心架构的主方向,并一直延续至GT200,当然在发展的过程中NVIDIA还是会对核心整体进行优化调整,但总体来说就是累积晶体管增加硬件规格,功能方面并无变化。反观Fermi,核心硬件规格数量相比GT200确实也有大幅增长,但是在产品整体架构上Fermi做了很大改动,可以说是颠覆性改动,它不仅仅是借鉴以前成熟的架构体系,还调整并在架构上新增功能模块,令Fermi不再简简单单的是图形核心,而是一个复合型功能核心。
在NVIDIA产品进入DirectX 10的统一架构后,我们看到核心中引入了TPC(Thread Processing Cluster)、SM(Streaming Mulitporcessor)和SP(Streaming Processor)等新概念。例如,G80拥有8个TPC,每个TPC拥有2个SM,每个SM拥有8个SP,这种由繁化简的结构一直延续在NVIDIA的图形产品中。
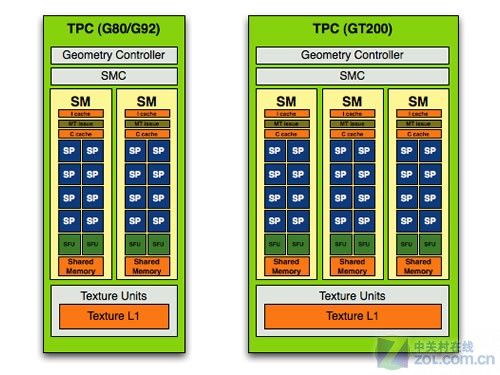
G80和GT200的TPC构成,图片来自Anandtech网站
通过对比G80、GT200到GF100的发展模式,我们看到SM矩阵数量在减少,而每个GPC中SM数量和每组SM中SP数量在增加。在这中架构设计理念上GF100虽然是延续了G80的组成设计,但是每个组成模块的数量优化上有了大幅改变。
GF100图形架构核心,从硬件的块数称为图形处理团簇(GPC)。每个GPC包含一个光栅引擎和四个SM单元。GPC是GF100占主导地位的高层次的硬件模块。除了计算单元它还包括两个重要特点——分别是一个可升级的光栅引擎(Raster Engine)、Z-cull和一个带有属性提取和细分曲面的多边形引擎(Polymorph Engine)。

Fermi架构GPC架构图
正如其名称所示,所有的GPC都集成了关键的图形处理单元。它包括顶点,几何,光栅,纹理均衡设置和像素处理资源。随着ROP单元功能的不断增强,一个GPC单元可以被看作是一个配置齐全的GPU,而GF100拥有4个这样的核心。
几何处理能力成倍提升
● 几何处理能力成倍提升
在过去的几年中,确切说是从Geforce 5800到Geforce GT200的这几年间,GPU的着色器Shader计算能力提升了150倍,这几乎全部是因为大量的顶点和像素处理压力所致。而游戏开发商大都喜欢已经烘焙好的材质不愿意也没有考虑过使用更为真实自由的材质。
正是在这种思路的指导下,GPU的几何处理能力发展缓慢,在着色器Shader计算能力迅猛提升的前提下,几何处理能力只提升了3倍。并且负责几何处理的GPU单元基本上没有发生什么变化,完全是依赖规模的堆积和频率的提升来被动提高性能。

在上图的示例中,Farcry女主角的肩膀放大后出现非常生硬粗糙的边缘;皮革质地的枪套竟然如此光滑;头发部分则因为无法运算很多根头发的物理计算而只能用帽子来遮挡,背景则几乎只能线性放大,没有任何变化的材质最终渲染效果非常不理想。
传统的GPU几何单元设计使用了一个单片前端用来获取、装配和光栅化三角形。这种固定管线模式只能提供性能固定的并行执行内核数量。而随着应用程序的工作量不同,这条几何管线常常瓶颈或利用率不足。单一的几何处理管线在面对复杂的几何需求时,成为GPU性能的主要障碍。
Fermi具备的光栅并行化是一个重要创新。NVIDIA称Fermi GF100是一个全新架构,不但是通用计算方面,游戏方面它也发生了翻天覆地的变化,几乎每一个原有模块都进行了重组:有的砍掉了,有的转移了,有的增强了,还有新增的光栅引擎(Raster Engine)和多形体引擎(PolyMorph Engine)。
多形体引擎则要负责顶点拾取(Vertex Fetch)、细分曲面(Tessellation)、视口转换(Viewport Transform)、属性设定(Attribute Setup)、流输出(Stream Output)等五个方面的处理工作,DX11中最大的变化之一细分曲面单元(Tessellator)就在这里。Fermi GF100产品中有16个多形体引擎,每个SM一个,或者说每个GPC拥有四个。

GF100芯片的一个SM内部纹理单元和几何引擎的配置
凭借多形体PolyMorph引擎,Fermi实现了全球首款可扩展几何学流水线,该流水线在单颗GPU中包含了最多16个Tessellation引擎。这些引擎在DirectX 11最重要的全新图形特性GPU加速Tessellation中能够发挥出革命性的性能。通过将更加细腻的几何图形融入到场景当中,Tessellation让开发人员能够打造出视觉清晰度极高、更加复杂的环境。锯齿边缘平滑了,从而使游戏中所渲染出来的人物能够拥有影院般细腻的画质。
多形体引擎绝非几何单元改头换面、增强15倍而已,它融合了之前的固定功能硬件单元,使之成为一个有机整体。虽然每一个多形体引擎都是简单的顺序设计,但16个作为一体就能像CPU那样进行乱序执行(OoO)了,也就是趋向于并行处理。NVIDIA还特地为这些多形体引擎设置了一个专用通信通道,让它们在任务处理中维持整体性。
在以前的架构中,固定功能单元只是单一的一条流水线。而在GF100,无论是固定功能单元和可编程操作单元都并行设计,这大大提高图形性能,也解决了GPU长期以来未有重大突破的性能短板。
多形体PolyMorph引擎的出现,是几何流水线近几年间不断演化的重大突破。特别是细分曲面操作,需要的三角形和光栅能力都异常可怕,传统GPU无法应对。多边形引擎的出现大幅度提高了三角形、细分曲面和流输出能力。通过给每个SM搭载属于自己的细分曲面Tessellation硬件单元,并为每个GPC搭载属于自己的光栅化引擎,GF100最终为我们提供了高达8倍于GT200几何性能。
PhysX和Tessellation带来震撼
● PhysX和Tessellation带来的震撼
PhysX被NVIDIA极为的重视,因为NVIDIA公司推行的GPGPU方案CUDA缺少大众级的应用,所以NVIDIA急于将AGEIA的物理卡技术通过CUDA转嫁在自家的卡上,以应付AMD公司的ATI系列显卡的强力竞争。首先在NVIDIA显卡上实现的GPU加速是AGEIA曾为<虚幻竞技场3>开发MOD物理加速地图。之后大部分使用虚幻3引擎的游戏都加入了对PhysX for CUDA的支持。

PhysX是一套由NVIDIA设计的执行复杂的物理运算的技术。在 2005年7月20日,索尼同意在即将发售的Playstation3中使用NVIDIA的PhysX和它的SDK——NovodeX。PhysX将会使设计师在开发游戏的过程中使用复杂的物理效果而不需要像以往那样耗费漫长的时间开发一套物理引擎,而且使用了物理引擎还会使一些配置较低的电脑无法流畅运行。
而Tessellation技术,相信大家在我们之前的多次分析中已经非常明晰。Tessellation这个英文单词直译为“镶嵌”,也就是在顶点与顶点之间自动嵌入新的顶点。Tessellation经常被意译为“细分曲面”,因为在自动插入大量新的顶点之后,模型的曲面会被分得非常细腻,看上去更加平滑致密。它是一种能够在图形芯片内部自动创造顶点,使模型细化,从而获得更好画面效果的技术。Tessellation能自动创造出数百倍与原始模型的顶点,这些不是虚拟的顶点,而是实实在在的顶点,效果是等同于建模的时候直接设计出来的。
图形业界对于曲面细分的探索不断深入
在此之前,人们对低代价多边形操作法已经探索了近10年,从最开始的对三角形的fan操纵,到后来的龟裂和冲撞检查,这些方法可以实现曲面细分效果,但是对资源的消耗量太大不可控制。这次微软在DirectX 11中加入硬件Tessellation单元,我们可以视作曲面细分技术历经长时间的磨练后修成正果。虽然它不太符合通用处理单元的设计方向,但是如果计算晶体管的投入与性能回报,独立的硬件Tessellation单元是目前最好的选择。
如果将NVIDIA独有的PhysX物理加速和Tessellation曲面细分技术结合使用,将会给用户在DirectX 11时代带来如何的视觉体验呢?下面这个Demo将会告诉你答案。

以上图片是通过NVIDIA专为GF100开发的演示Demo,名字叫做Hair。这个示范中角色的头发完全是模拟运算而来,由NVIDIA图形处理器(GPU)综合硬件曲面细分技术(HW Tessellation),几何渲染(Geometry Shading)……等技术所创造与绘制。
首先Tessellation能够把头发一根根渲染出来,同时抖动后我们发现每一根头发都是独立的,这时抖动的头发就用到了PhysX物理加速技术来实现。这个Demo对NVIDIA在Fermi架构中的15个Tessellation进行了耗尽式的应用,同时它必须配合PhysX物理加速技术,才能够对每一根头发进行精确的计算。
头发丝是由DX11的硬件曲面细分技术(HW Tessellation)用等值线区域(isoline domain)凭空创造而来的。由曲面细分技术引擎(Tessellation engine)所创造的等值线(Isolines),被送入几何渲染器(Geometry Shader)以扩增其三角形细节。
只有166根头发备用来进行模拟运算, 这大约用到4500个头发顶点。在最高的精细度层级(LOD, Level Of Detail)设定下, 可以凭空创造高达18000根发丝(也就是高达280万个三角形)流体动态模体(Fluid Dynamics Simulation)被用来模拟发丝迎风飘扬的特效。
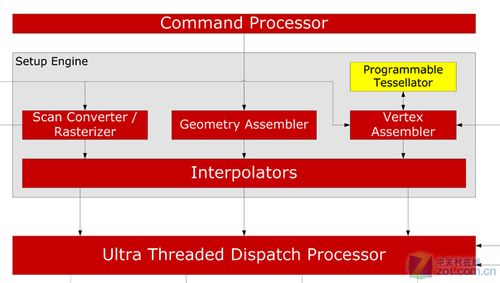
超线程发送处理器UTDP单元(图片来自PCINLIFE网站)
如果使用AMD显卡演示这个Demo,我们会发现明显的两个性能瓶颈,首先是由于HD5870在其Ultra Threaded Dispatch Processor中集成了1个Tessellation单元,而NVIDIA在每个SM中就有1个Tessellation单元,曲面细分的性能差距几乎是15:1。
在R5XX的时候,ATI开始引入Ultra Threaded Dispatch Processor的概念。UTDP为不同的shader类型提供了专门的命令队列窗口,这些窗口内塞满了等待执行的线程,每个线程都是若干条对输入数据处理的指令。
Computer Shader做图形后处理
● 利用Computer Shader做图形后处理
GPU是图形处理器,以往的GPU通用计算需要程序员先将资料伪装成GPU可识别的图像,再将GPU输出的图像转换为想要的结果,而通过DX11中的Compute Shader通用计算,任意类型的数据(即使是非图形数据)都可以直接进行计算,而且不受图形渲染流程的束缚,可以随时写入写出,GPU通用计算的效能提高了很多。
由于GPU的浮点运算能力非常强大,支持GPU进行通用计算的技术发展势头很快,NVIDIA和AMD分别有CUDA和Stream技术,以前两家是各自为战,如今微软也看到了GPU通用计算的曙光,在DX11中加入了Compute Shader这一技术,意在统一当前的通用计算技术。你可以认为Compute Shader标准就是微软提出的OPEN CL。
Compute Shader技术是微软DirectX 11 API新加入的特性,在Compute Shader的帮助下,程序员可直接将GPU作为并行处理器加以利用,GPU将不仅具有3D渲染能力,也具有其他的运算能力,也就是我们说的GPGPU的概念和物理加速运算。多线程处理技术使游戏更好地利用系统的多个核心。
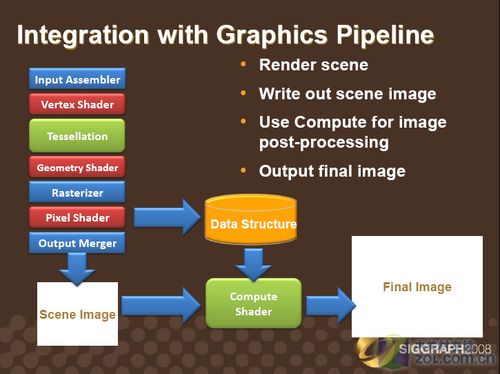
Compute Shader图形流水线
Compute Shader主要特性包括线程间数据通信、一整套随机访问和流式I/O操作基本单元等,能加快和简化图像和后期处理效果等已有技术,也为DX11级硬件的新技术做好了准备,对于游戏和应用程序开发有着很重大的意义。
在DirectX 11以及CS的帮助下,游戏开发者便可以越过复杂的数据结构,并在这些数据结构中运行更多的通用算法。与其他完整的可编程的DX10和DX11管线阶段一样,CS将会共享一套物质资源(也就是着色处理器)。

利用Compute Shader技术运算图形景深
在硬件支持Compute Shader之后,相应的硬件必须要比当代硬件更加灵活,因为在运行CS代码的时候,硬件必须支持随机读写、不规则列阵(而不是简单的流体或者固定大小的2D列阵)、多重输出、可根据程序员的需要直接调用个别或多个线程、32k大小的共享寄存空间和线程组管理系统、粒数据指令集、同步建构以及可执行无序IO运算的能力。
Compute Shader可发挥的地方很多,游戏中可以使用GPU进行光线追踪、A-Buffer采样抗锯齿、物理特效、人工智能AI等游戏特效运算。在游戏之外,程序员也可以利用CS架构进行图像处理、后处理(Post Process)等。
计算机体系结构的基本原理是,任何软件能够实现的,硬件都能够实现,相反也成立,这被成为硬件软件等效原理。这一原理只是功能等效,性能来说,良好优化和设计的硬件通常要比同样水平的软件快很多,同样开发周期长,开发成本也要高不少。体系结构研究的重点就是从需要出发,寻求最佳的软硬件平衡点,在一定的成本约束下,获得最高的性能。
Compute Shader技术用作运算图形景深等后处理,标志着传统的ROP单元已经慢慢失去了专用功能化单元的至高地位。而GPU去功能化的进程将因为Compute Shader技术的出现大大加速。未来的GPU中,Shader将成为主要甚至是唯一的处理单元,而ROP和TMU甚至是现在正被抬得很高的Tessellation单元,都有可能逐渐消失,最终被Shader单元替代。
架构设计基于图形而又超越图形
● 基于图形而又超越图形的设计理念
GT200发布时其宣传口号是所谓的Gaming Beyond和Computing Beyond,这个宣传口号第一次鲜明地体现了NVIDIA的GPU设计方向发生了明显变化。GPU Computing概念的提出,说明了GPU身份已经转变为一颗通用计算处理器。同时NVIDIA需要为开拓GPU通用计算市场而做出一些设计方面的变化。

而不久前发布的Fermi架构GTX400系列显卡,正是这一概念的深刻体现。代号GF100的Fermi设计方案在4年前确定下来并付诸行动,这时正值代号G80的Geforce 8800GTX做最后的出厂准备。G80凭借全新的MIMD(多指令流多数据流)统一着色器(又称流处理器)获得了业界的一致认同,同时被业界关注的还有G80的通用计算性能。
NVIDIA的Tony Tamasi先生(NVIDIA高级副总裁,产品与技术总监)表示:“以前的G80架构是非常出色的图形处器。但Fermi则是一款图形处理同样出色的并行处理器。”
这句话揭示了Fermi的与众不同,它已经不再面向图形领域设计了,因为更广阔的通用计算市场在等待它。Fermi将为通用计算市场带来前所未有的变革,图形性能和游戏被提及已经越来越少。
NVIDIA公司在不断强调并行计算的重要性
从NVIDIA处理器架构的发展来看,Tamasi先生的话意思很清楚。回顾历史我们可以发现NVIDIA最近几年间,大规模改进图形处理架构设计的是GeForce 6000(NV40)系列,之后就是GeForce 8000(G80)和GeForce GTX 200(GT200),最后就是Fermi。
“CUDA Cores”是Fermi最基础的运算单元,将它的历史向上追溯首先是G80时代的统一着色单元(Unified Shader Model),我们在G80和GT200时代将它统称为流处理器(Stream Processor),再向上追溯可知,这个单元将Vertex Shader(顶点着色器)和Pixel Shader(像素着色器)合并而成。
理论上说“CUDA Cores”只是起了一个好听的名字,让人们更看重GPU通用计算的作用,实际上我们在图形领域还是将它视为普通的流处理器。但这背后透露出NVIDIA公司的另一种计划——面向并行计算领域设计一颗芯片,并使其具备图形运算能力,这颗芯片由众多的“CUDA Cores”组成,运算速度主要由“CUDA Cores”的数量和频率决定。
在没有了解Fermi的核心构成之前,很多人“CUDA Cores”概念嗤之以鼻,认为这是NVIDIA公司的营销策略,就像HD5870所拥有的1600个流处理器一样,实际上是320个SIMD单元。两家公司确实打了不少口水仗,无数玩家也跟着它们提出的概念升级了自己的显卡。不过这次Fermi改变名称和设计方向,是有备而来的。
Fermi架构视频解析
NVIDIA这次敢提出图形性能和通用计算并重,说明GPU设计的重点和难点都在通用计算方面而非图形。因为一颗已经演化了十年的GPU肯定能做好自己的老本行图形计算,但是要做通用计算,需要更强大的线程管理能力,更强大的仲裁机制,丰富的共享cache和寄存器资源以及充足的发射端……如果做不好这些东西,GPU永远都是PC中的配角,永远都是一颗流处理器。这些表面上看这些部件是极占晶体管的东西,更可怕的是设计这些部件需要太多科研成本和时间。
Impress Watch网站知名IT评论人後藤弘茂称NVIDIA全新Fermi架构,是以处理器为目标进行设计的。因为你在Fermi身上可以看到以前GPU上从来没有的东西,包括更多的指令双发射、统一的L2全局缓存、64KB的可配置式L1或者Shared Memory、大量的原子操作单元等等。
原文地址:http://vga.zol.com.cn/179/1794723_all.html#p1794723