pandas之数据筛选(后附源数据供大家练习)
目录
所用数据读取预览:
1.单个条件筛选(筛选男生)
(1)条件书写
(2)取出数据
2.query多条件筛选(筛选总分大于160的男生)
(1)条件写入
注意:
(2)取出数据
3.筛选文本开头内容(筛选襄阳市的)startswith/endswith
(1)条件书写
(2)取出数据(同1.的方法)
(3)测试筛选信阳市(小伙伴们自己动手哦)
4.筛选整个文本中存在的内容contains(太好用啦)
(1)条件书写
(2) 取出数据
5.contains与正则表达式结合进行模糊匹配
(1)条件书写
(2)取出数据
6.筛选日期
(1)方法一(loc筛选某日期或者某日期区间的数据)
A.准备工作
B.筛选1987年出生的数据
C.查询某日期区间内的数据
(2)方法二(truncate函数筛选某日期之间或之后的数据)
A.truncate函数介绍
B.使用方法
a.准备步骤
b.进行筛选(before、after)
注意:日期要加引号,否则会报错
7.源数据网盘链接
所用数据读取预览:

1.单个条件筛选(筛选男生)
(1)条件书写
conditions=data['性别']=='男'
(2)取出数据
data[conditions]

2.query多条件筛选(筛选总分大于160的男生)
(1)条件写入
conditions="性别=='男' and 总分>160"
注意:
两个条件要用引号引起来
条件之间用and连接
引号外双内单,内单外双
列名不用加引号(如果误加,将会和我一样得到一片飘红)
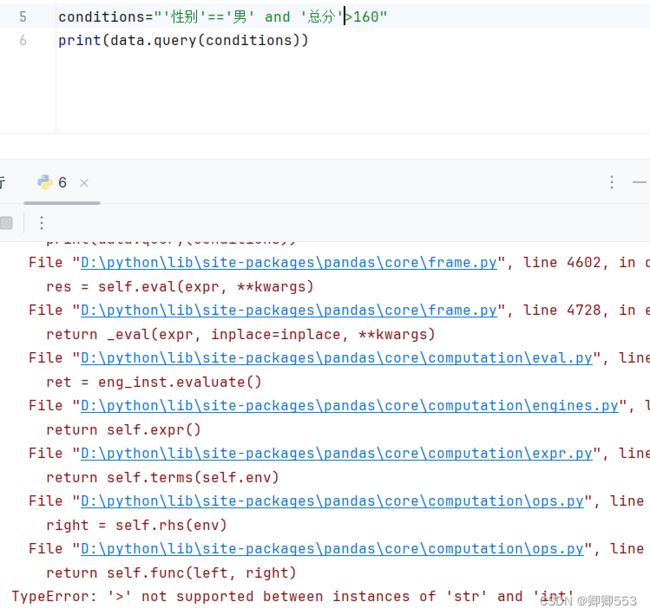
(2)取出数据
利用query方法将条件写入
data.query(conditions)

3.筛选文本开头内容(筛选襄阳市的)startswith/endswith
(1)条件书写
这里条件的书写方式不同于前面,条件的组成结构是:数据['列名'].该列数据类型.startswith('匹配的开头文本内容')
conditions=data['地址'].str.startswith('襄阳市')
(2)取出数据(同1.的方法)
data[conditions]

(3)测试筛选信阳市(小伙伴们自己动手哦)
4.筛选整个文本中存在的内容contains(太好用啦)
小伙伴们在运用上一方法时是否遇到了这样的困惑,如果要查询信阳市的话,会有一个河南省信阳市的数据被遗漏,别急,接下来要讲解的方法可以完美解决这个问题~~~
这个方法就是:contains!!!这个方法不纠结于你到底是不是在开头或结尾,只要在文本中存在,就能把你揪出来
(1)条件书写
条件的书写只是把上一方法中的startswith换成了contains
conditions=data['地址'].str.contains('信阳市')
(2) 取出数据
data[conditions]

5.contains与正则表达式结合进行模糊匹配
比如我们想要查找家庭地址楼栋是A座的同学,但是因为数据填写标准没有统一,有的同学写的A,而有的同学写的a,这个时候正则表达式就赶来救场了
(1)条件书写
数据['列名'].str.contains('正则表达式')
data['地址'].str.contains('[aA]座')
(2)取出数据
data[conditions]

6.筛选日期
(1)方法一(loc筛选某日期或者某日期区间的数据)
A.准备工作
将出生日期设置为索引,将出生日期列设置为日期格式
data=pd.read_excel(adress,index_col='出生日期',parse_dates=['出生日期'])
B.筛选1987年出生的数据
data.loc['1987']

C.查询某日期区间内的数据
data.loc['1985-6':'1989-9']

(2)方法二(truncate函数筛选某日期之间或之后的数据)
A.truncate函数介绍
truncate函数可以截取某个时期之前或之后的数据,以及某个时间区间内的数据
B.使用方法
a.准备步骤
将日期设置为索引并排序
data=pd.read_excel(adress,index_col='出生日期') data=data.sort_index()
b.进行筛选(before、after)
以查询1987-2-06后的数据为例
注意:日期要加引号,否则会报错
结果是包含所写这天的
这里我没有写错,查询某日期之后的数据要用before,查询某日期之后的数据要用after
data.truncate(before='1987-2-06')

7.源数据网盘链接
链接:https://pan.baidu.com/s/1pHVfrNpsPgf2j7L_A2sZig
提取码:1234