数据结构初阶之排序
个人主页:点我进入主页
专栏分类:C语言初阶 C语言程序设计————KTV C语言小游戏 C语言进阶
C语言刷题 数据结构初阶 Linux
欢迎大家点赞,评论,收藏。
一起努力,共赴大厂。
目录
一.前言
二.选择排序
2.1选择排序思想
2.2代码实现
三.快速排序
3.1霍尔的思想
3.2代码实现
3.3代码性能分析与改进
3.3.1优化点一
3.3.2优化点二
3.4挖坑法
3.5代码实现
3.6双指针法
3.7代码实现
3.8非递归实现快速排序
四.归并排序
4.1归并的思想
4.2代码实现
4.3非递归思想
4.4代码实现
五.计数排序
5.1计数排序思想
5.2代码实现
六.总结
一.前言
在前面我们写过冒泡排序,堆排序,插入排序以及希尔排序。今天我主要给大家带来的包括选择排序,快速排序的霍尔版本。其中选择排序就是找到最大最小的数然后放在两边然后进行循环,进行下一次的最大最小数据的查找替换,其中有一个坑,坑在哪里后面会说,对于霍尔的快速排序,既然叫快速排序,那么它必然会非常的快,这个需要我们找到一个关键值然后进行,由于霍尔版本的坑非常的多,又有一些大佬对霍尔的快速排序进行了修改,包括思路类似的挖坑法和另一种思路不同的双指针法,这些内容逐渐的进行讲解。
二.选择排序
2.1选择排序思想
选择排序我们先排第一趟,我们先找到最大和最小的数,例如我们想要将数组形成升序,我们将小的放在前面,大的放在后面,这就形成了我们的第一趟,我们将前和后进行调整,然后重复这样的过程,就会形成我们的选择排序,我们可以看一下动图,可以更好的了解我们的选择排序。
2.2代码实现
void SelectSort(int* a, int n)
{
int begin = 0, end = n - 1;
while (begin < end)
{
int maxi = begin, mini = begin;
for (int i = begin; i <= end; i++)
{
if (a[i] > a[maxi])
{
maxi = i;
}
if (a[i] < a[mini])
{
mini = i;
}
}
Swap(&a[begin], &a[mini]);
Swap(&a[end], &a[maxi]);
begin++;
end--;
}
}我们运行我们的程序我们可以看到

看到这里我们可以看到我们的程序出现了问题,没有达到我们的预期,那么问题出现在那里了?我们进行调试
我们可以看到这时候我们的mini的值为9,maxi的值为0,我们先进行交换我们可以看到数组的元素变成了0,8,7,6,5,4,3,2,1,9.我们的maxi的值为0,但是我们的最大值却在9的位置,所以我们需要在第一个数据交换的位置加一个判断条件,
if (maxi == begin)
{
maxi = mini;
}我们运行代码后我们运行后我们可以看到

我们的全部代码为
void SelectSort(int* a, int n)
{
int begin = 0, end = n-1;
while (begin < end)
{
int maxi = begin, mini = begin;
for (int i = begin; i <= end; i++)
{
if (a[i] > a[maxi])
{
maxi = i;
}
if (a[i] < a[mini])
{
mini = i;
}
}
Swap(&a[begin], &a[mini]);
if (maxi == begin)
{
maxi = mini;
}
Swap(&a[end], &a[maxi]);
begin++;
end--;
}
}三.快速排序
3.1霍尔的思想
对于霍尔的快速排序,我们就是根据递归进行写的,先找出一个关键值,我们想要一个升序的序列,我们将这个关键值得左边全部小于它,右边全部大于它,然后进行递归,我们同样进行第一次排序,我们先找在右边开始小于这个关键值得数,然后在左边开始,找到大于这个关键值的数只要这两个不相交,进行这两个数进行交换,相遇的时候我们将这个关键值和相遇的位置进行交换,这就是我们的第一趟排序,然后进行递归。在这里我们有很多坑,也有一个问题,为什么保证最后的值为最小的,这个问题我们后面会进行讲解。接下来我们看一组动图,来深刻了解一下霍尔的排序思路
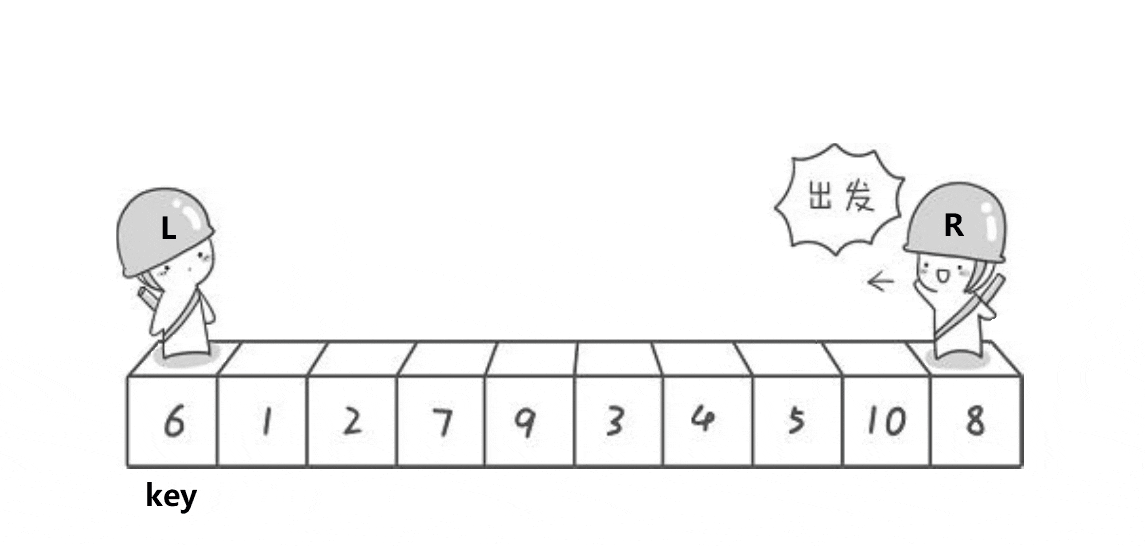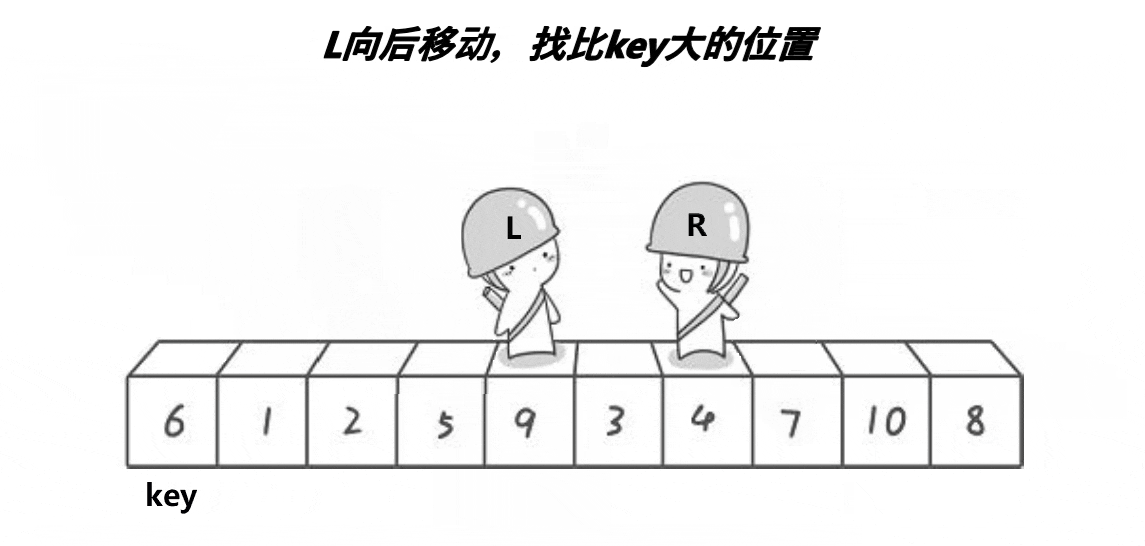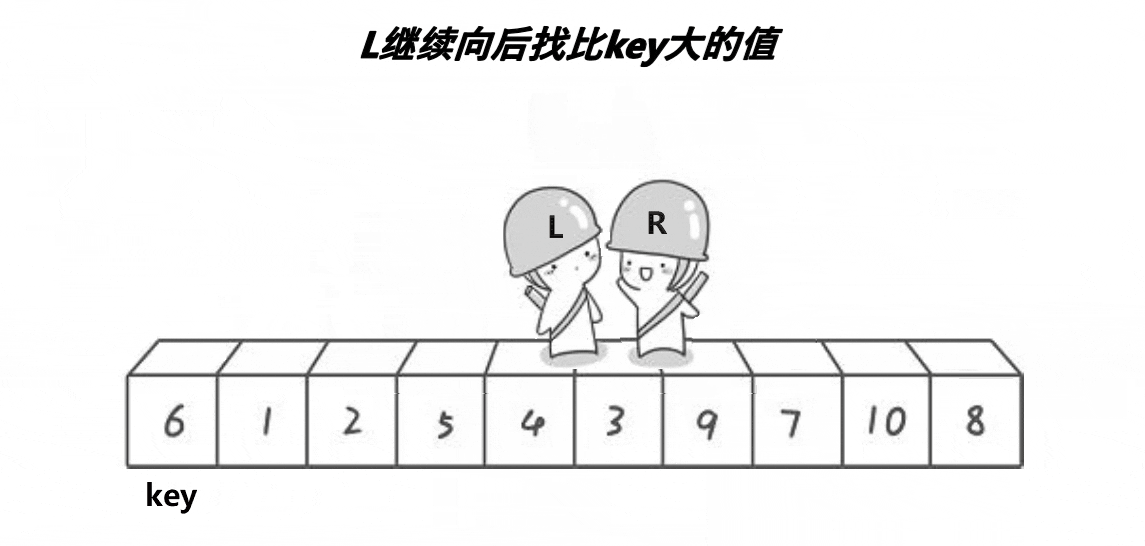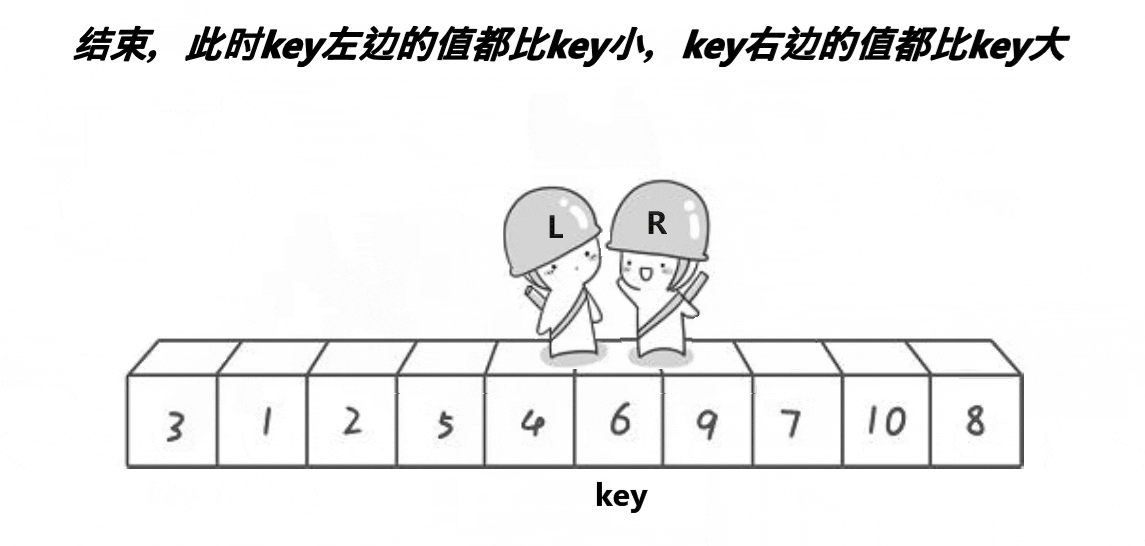
3.2代码实现
void QuickSort(int* a, int begin, int end)
{
if (begin >= end)
return;
int keyi = begin;
int left = begin, right = end;
while (left < right)
{
while (left < right && a[right] <= a[keyi])
{
right--;
}
while (left < right && a[left] >= a[keyi])
{
left++;
}
Swap(&a[right], &a[left]);
}
Swap(&a[left], &a[keyi]);
keyi = left;
QuickSort(a, begin, keyi-1);
QuickSort(a, keyi + 1, end);
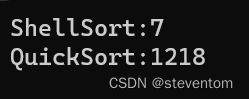
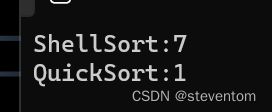
}在这个代码里面有几个坑,第一个是在while循环里面的while循环的判断条件需要加上left 我们做一个随机数产生的数组,我们的代码如下: 这个代码用于计算函数使用的毫秒数,我们在release版本进行实验,由于我们的数据量是十万,由于随机数产生的数据为3万多,我们在数据后还加了一个i这样我们就会将数据看成近似于有序,我们运行代码可以看到 我们知道希尔排序和快速排序时间复杂度都是nlogn但是为什么会相差这么多呢?这主要就是数组类似有序造成的后果,这时候我们可以做一些优化,我们去取区间中的开头数据,结尾数据,中间数据中不大不小的数据,然后让他和开头进行交换,我们让它做为我们的关键值,取中代码如下: 这样我们运行我们的代码可以看到 我们的快排变快了很多。 我们知道快速排序是递归大方式进行的,我们可以化成图为 我们的最后一层占用的递归次数将近占总体的50%,我们的倒数第二次大约占25%,倒数第三次大约占12.5%,仅仅是这三次就将近占总体递归的87.5%,我们知道debug版本和release版本中我们用debug版本,递归占用的内存还是很多的,但是release版本下编译器已经做了优化,让递归变得好很多,我们的优化点二主要针对于debug版本进行的, 我们将最后的区间中在10个左右时我们用插入排序进行,为什么什么使用插入排序呢?这个主要原因就是我们使用希尔排序的话就有点过了,使用堆排序的话我们还需要进行建堆,比较麻烦,所以这时候我们的插入排序就非常good了,我们的进一步修改为: 我们可以看到我们的调整后有时候大有时候小,有时候相等,在release版本下 我们调整数据的长度,可以看到大部分情况下调整还是会变慢。 挖坑法的主要原理就是出现一个hole进行数据的交换,这样每一趟的结果虽然不同但是最后的结果相同,我们看一看动图来了解一下挖坑法 挖坑法就是先把key保存来,然后我们把起始位置定义为我们的洞,然后先找右边,然后进行填坑,然后新坑就是我们交换过去的数的原始位置,然后再从左边开始,一样进行填坑,挖坑,最后将坑的位置填上key。这样我们的一层排序就完成了,我们在进行递归就完成了。 双指针法是一种非常简单的方式,其核心思想就是我们想要升序,南无prev和cur之间的就是大于key的值,然后进行数据交换,让大的数跳到后边去,小的数跳到前边,我们的动图为 这个代码非常巧妙,我们的cur无论任何情况都会++,只有a[cur]小于key时才交换,当然prev++后和cur相等的时的交换是无意义的所以,可以舍去。 针对我们的非递归实现我们的快速排序,我们可以选择用栈去进行模拟实现,栈的作用就是帮助我们去存储我们的开始和结尾的下标,我们可以利用栈空来判断循环,我们的代码如下: 在这里我们先将原有数组的开始和结尾的下标进行存储,然后进入循环,我们出栈得到我们的开始和结尾的下标,三数取中,我们利用双指针法找到我们的keyi,然后当区间中的元素数量大于1时我们入栈进行存储下标,这样进行循环就可以模拟非递归进行快速排序。 在归并排序中我们有递归的方式和非递归的方式,递归中们需要对数据进行分组,我们进行递归将数据变成每组有序,这时候我们进入我们的合并环节,我们每相邻的两组有序数组进行合并,合成新的有序数组,我们可以将这个步骤画成 我们可以将这个过程看成我们的二叉树的后序遍历的过程,我们进行数组合并时我们做的相当于两个有序数组合并成一个有序数组,这样我们进行合并就可以完成。我们看一看动图,就可以更好的了解一下这个过程, 对于非递归的方式,我们想到是否可以使用栈来实现呢?类似于快速排序的非递归一样,但是我们在取栈顶元素时我们的栈的元素就会取出来,我们分成单个以后就不能干任何事情了,所以这种方式是不可以的,那我们应该如何去做呢?这时候需要我们对归并排序的递归形式的运行过程有深刻的了解,我们可以去模拟递归的过程去完成非递归,我们可以使用一个gap,当gap为1时我们的每一组的数组的长度都是1,这时我们相邻的两组之间进行有序数组合并,我们用四个变量来保存数组的范围,我们利用i来实现组的变换,这时候我们会遇到范围的越界,这时候我们需要一些判断,由于i小于n所以第一个数不需要判断,当第二个数大于等于n时我们就没有了第二组,这时候由于数组有序,所以不需要排序,当第三个数大于等于时也是不需要排序,第四个数大于等于时我们直接对他进行赋值即可。 对于计数排序,我们用到了哈希表和相对映射,我们先找到最大最小值,然后开辟最大-最小+1大小的数组,然后进行计数,计数的位置为a[i]-min,然后我们映射回去就可以得到排序后的数组,计数排序的时间复杂度为o(n),但是它有一些局限,最大和最小相差很多时我们使用这个会非常麻烦。 我们知道排序分为内存排序和外排序,我们写过的八种排序都是内排序,内排序就是在内存中进行排序,我们知道内存就是量小,价格贵,带电存储的,我们的外排序就是储存在硬盘中,其中我们的归并排序也是外排序,例如我们想要排序存在文件中的数据,这时候我们需要我们的归并排序了,归并排序是对于有序的数组进行归并,我们可以选取一些数据使用快速排序,希尔排序等较快的排序,然后让他们变成有序的数组,然后使用归并排序,这里不做具体的写法,只提供一个思路。最后希望大家可以一件三连,点点赞支持一下。3.3代码性能分析与改进
3.3.1优化点一
int main()
{
srand(time(0));
int n = 100000;
int* a1 = (int*)malloc(sizeof(int) * n);
int* a2 = (int*)malloc(sizeof(int) * n);
int* a3 = (int*)malloc(sizeof(int) * n);
int* a4 = (int*)malloc(sizeof(int) * n);
int* a5 = (int*)malloc(sizeof(int) * n);
int* a6 = (int*)malloc(sizeof(int) * n);
int* a7 = (int*)malloc(sizeof(int) * n);
for(int i = 0; i < n; i++)
{
a1[i] = i + rand();
a2[i] = a1[i];
a3[i] = a1[i];
a4[i] = a1[i];
a5[i] = a1[i];
a6[i] = a1[i];
a7[i] = a1[i];
}
int begin1 = clock();
ShellSort(a1, n);
int end1 = clock();
printf("ShellSort:%d\n", end1 - begin1);
int begin2 = clock();
QuickSort(a1, 0,n-1);
int end2 = clock();
printf("QuickSort:%d\n", end2 - begin2);
return 0;
}
int GetMid(int* a, int begin, int end)
{
int mid = (begin + end) / 2;
if (a[mid] > a[begin])
{
if (a[end] > a[mid])
{
return mid;
}
else if (a[end] < a[begin])
{
return begin;
}
else
{
return end;
}
}
else
{
if (a[mid] > a[end])
{
return mid;
}
else if (a[end] > a[begin])
{
return begin;
}
else
{
return end;
}
}
}
3.3.2优化点二

void QuickSort(int* a, int begin, int end)
{
if (begin >= end)
return;
int midi = GetMid(a, begin, end);
Swap(&a[midi], &a[begin]);
if (end - begin + 1 <= 10)
{
InsertSort(a + begin, end - begin + 1);
}
else
{
int keyi = QuickSort1(a, begin, end);
QuickSort(a, begin, keyi - 1);
QuickSort(a, keyi + 1, end);
}
}



3.4挖坑法
3.5代码实现
int QuickSort2(int* a, int begin, int end)
{
int key = a[begin], hole = begin;
int left = begin, right = end;
while (left < right)
{
while (left < right && a[right] >= key)
{
right--;
}
Swap(&a[right], &a[hole]);
hole = right;
while (left < right && a[left] <= key)
{
left++;
}
Swap(&a[left], &a[hole]);
hole = left;
}
a[hole] = key;
return hole;
}3.6双指针法
3.7代码实现
int QuickSort3(int* a, int begin, int end)
{
int keyi = begin;
int prev = begin, cur = begin + 1;
while (cur <= end)
{
if (a[cur]3.8非递归实现快速排序
void QuickSortNonP(int* a, int begin, int end)
{
Stack s;
InitStack(&s);
PushStack(&s, begin);
PushStack(&s, end);
while (!EmptyStack(&s))
{
end = TopStack(&s);
PopStack(&s);
begin = TopStack(&s);
PopStack(&s);
int midi = GetMid(a, begin, end);
Swap(&a[midi], &a[begin]);
int keyi = QuickSort3(a, begin, end);
if(keyi-1>begin)
{
PushStack(&s, begin);
PushStack(&s, keyi - 1);
}
if(end>keyi+1)
{
PushStack(&s, keyi + 1);
PushStack(&s, end);
}
}
DestoryStack(&s);
}四.归并排序
4.1归并的思想


4.2代码实现
void _MergeSort(int* a, int begin, int end, int* tmp)
{
if (begin >= end)
return;
int mid = (begin + end) / 2;
_MergeSort(a, begin, mid,tmp);
_MergeSort(a, mid + 1, end, tmp);
int i = begin, j = mid + 1;
int k = i;
while (i <= mid && j <= end)
{
if (a[i] < a[j])
{
tmp[k++] = a[i++];
}
else
{
tmp[k++] = a[j++];
}
}
while (i <= mid)
{
tmp[k++] = a[i++];
}
while (j <= end)
{
tmp[k++] = a[j++];
}
memcpy(a + begin, tmp + begin, sizeof(int) * (end - begin + 1));
}
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail");
return;
}
_MergeSort(a, 0, n - 1, tmp);
memcpy(a, tmp, sizeof(int) * n);
}
4.3非递归思想
4.4代码实现
void _MergeSortNonP(int* a, int n, int* tmp)
{
int gap = 1;
while(gap五.计数排序
5.1计数排序思想
5.2代码实现
void CountSort(int* a, int n)
{
int max=0, min=0;
for (int i = 0; i < n; i++)
{
if (a[i] > max)
{
max = a[i];
}
if (a[i] < min)
{
min = a[i];
}
}
int* hash = (int*)calloc(max - min+1, sizeof(int));
memset(hash, 0, sizeof(int) * (max - min + 1));
for (int i = 0; i < n; i++)
{
hash[a[i] - min]++;
}
int j = 0;
for (int i = 0; i < max - min + 1; i++)
{
while (hash[i]--)
{
a[j++] = i;
}
}
}六.总结