Redis之bigkey
目录
1、什么是bigkey?
2、bigkey大的小
3、bigkey有哪些危害?
4、bigkey如何产生?
5、bigkey如何发现?
6、bigkey如何删除?
7、BigKey调优,惰性释放lazyfree
8、生产上限制keys * /flushdb/flushall等危险命令防止误删误用
9、SCAN命令
1、什么是bigkey?
bigkey通常用来描述存储大量数据的键。
2、bigkey大的小
根据《阿里云Redis开发规范》string类型大于10KB就是bigkey,list、hash、set和zset,个数超过
5000就是bigkey
3、bigkey有哪些危害?
-
内存消耗:大键占用更多的内存空间。由于Redis是一个基于内存的数据库,过多的大键可能导致内存不足或增加运行成本。
-
网络传输延迟:当从Redis服务器读取或写入大键时,需要更多的时间和网络带宽来传输数据。这可能会导致响应时间延长,影响性能。
-
数据处理效率降低:对大键进行读写操作可能会导致Redis服务器的处理速度变慢,因为它需要花费更多的时间来处理大量的数据。
-
持久化备份问题:如果你使用了持久化功能(如RDB快照或AOF日志),大键会增加备份和恢复的时间和存储空间。
-
缓存失效问题:如果大键被频繁更新,可能会导致与该键相关的其他缓存项失效,影响缓存系统的效率。
4、bigkey如何产生?
社交类,统计类数据会造成bigkey
5、bigkey如何发现?
1、redis-cli --bigkeys
redis-cli -h 127.0.0.1 -p 6379 -a 111111 -bigkeys
2、MEMORY USAGE
MEMORY USAGE key
MEMORY USAGE是Redis提供的一个命令,用于获取指定键所占用的内存大小。执行该命令后,Redis会返回一个整数值,表示该键占用的内存大小(以字节为单位)。如果键不存在,命令会返回0。
注意:
-
MEMORY USAGE命令只能用于检查指定键的内存使用情况,无法一次性获取所有键的内存使用情况。 -
Redis使用了一些特殊的算法来最小化内存的使用,因此实际占用的内存大小可能会比预期小。
-
当使用Redis Cluster等分布式环境时,
MEMORY USAGE命令只能用于检查本地节点的键的内存使用情况,无法检查整个集群的内存使用情况。
6、bigkey如何删除?
string类型:一般用del,如果过于庞大unlink
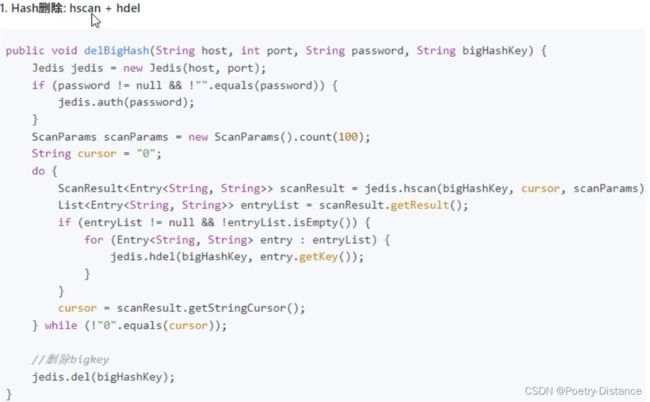
hash类型:使用hscan每次获取少量field-value,再使用hdel删除每个field
list类型:使用ltrim渐进式逐步删除,直到全部删除完成
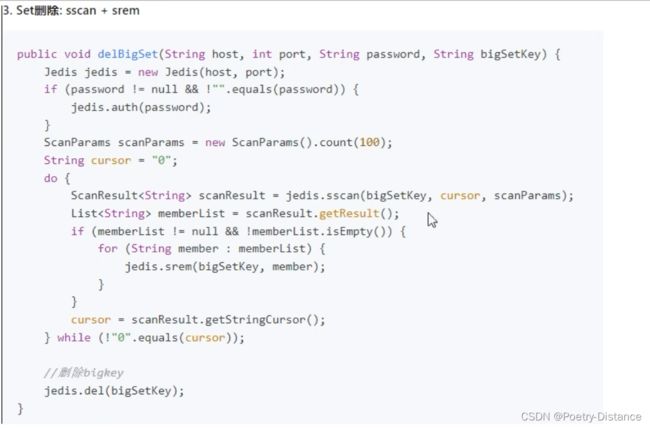
set类型:使用sscan每次获取部分元素,再使用srem命令删除每个元素
zset类型:使用zscan每次获取部分元素,再使用ZREMRANGEBYRANK命令删除每个元素

7、BigKey调优,惰性释放lazyfree
打开redis.conf配置文件LAZY FREEING相关说明

1、lazyfree-lazy-server-del no: 这个选项用于控制Redis服务器删除键时的行为。当设置lazyfree-lazy-server-del选项为no时,服务器会立即删除键,而不延迟删除操作。
2、replica-lazy-flush no: 这个选项用于控制主节点执行FLUSHALL或FLUSHDB命令时是否传播给从节点。当设置了replica-lazy-flush选项为no时,主节点执行这些命令后会将其传播给从节点,使得从节点也执行相同的操作。
3、lazyfree-lazy-user-del no: 这个选项用于控制Redis服务器删除键时的行为,与lazyfree-lazy-server-del选项类似。当设置了lazyfree-lazy-user-del选项为no时,服务器会立即删除键,而不延迟删除操作。
8、生产上限制keys * /flushdb/flushall等危险命令防止误删误用
通过配置设置禁用这些命令,redis.conf在SECURITY这一项中
9、SCAN命令
Redis的SCAN命令用于迭代遍历Redis中的键。它允许逐批返回与指定模式匹配的键。执行SCAN命令后,Redis会返回两个值:下一个迭代器位置和匹配的键列表。
SCAN cursor [MATCH pattern] [COUNT count]
cursor:表示迭代器的起始位置。初始时,cursor值设置为0。MATCH pattern(可选):用于指定要匹配的键模式。只有与模式匹配的键才会被返回。COUNT count(可选):指定每次迭代返回的键的数量。默认情况下,Redis会尽量返回所有匹配的键。
示例:
redis 127.0.0.1:6379> scan 0
1) "17"
2) 1) "key:12"
2) "key:8"
3) "key:4"
4) "key:14"
5) "key:16"
6) "key:17"
7) "key:15"
8) "key:10"
9) "key:3"
10) "key:7"
11) "key:1"
redis 127.0.0.1:6379> scan 17
1) "0"
2) 1) "key:5"
2) "key:18"
3) "key:0"
4) "key:2"
5) "key:19"
6) "key:13"
7) "key:6"
8) "key:9"
9) "key:11"SCAN返回一个包含两个元素的数组
第一个元素是用于进行下一次迭代的新游标。
第二个元素则是一个数组,这个数组中包含了所有被迭代的元素。如果新游标返回零表示迭代已结束。
SCAN的遍历顺序:它不是从第一维数组的第零位一直遍历到末尾,而是采用了高位进位加法来遍
历。是为了在字典的扩容和缩容时避免槽位的遍历重复和遗漏。
注意:由于Redis是单线程的,当执行SCAN命令时,Redis服务器可能会阻塞一段时间,直到迭代完成。因此,在处理大型数据库时,建议使用SCAN命令进行分批处理,以避免对服务器性能造成影响。