深度学习 基于aistudio平台从数据标注开始实现语义分割任务
从0基础开始进行深度学习
1、数据处理
1.1 数据标注
准备数据标注软件
使用labelme进行数据标注,labelme的下载地址为:https://download.csdn.net/download/a486259/16097828 下载放到桌面,双击即可运行。
软件界面如下所示:

准备原始数据
数据的获取途径有很多种方式,这里拟采用从谷歌地球上截图的形式获取原始数据。
进行数据标注
根据下图提升,在labelme中选择自己的数据文件夹

选择好数据后,界面通常如下所示。进行语义分割是需要在软件中标注多边形,为每一个多边形分配类别。使用该软件时,可以点击File选择取消Save With Image Data(保存图像数据到json文件中),同时勾选上Save Automaticlly(自动保存标签数据)
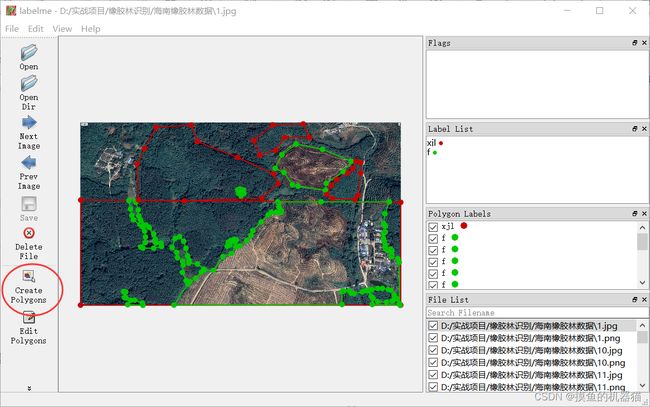
labelme标注后的数据目标下会生成与原始图像同名的json文件,也就是说标注好的数据集由jpg图像和json文件组成,且一一对应。具体如下所示:

json文件的大致格式内容如下,其中shapes内存储了我们标注的信息
{
"version": "4.5.7",
"flags": {},
"shapes": [
{
"label": "f",
"points": [
[
21.5,
6.0
],
[
3,
4685
],
[
8191,
4685
],
[
8191,
0
],
[
40,
0
]
],
"group_id": null,
"shape_type": "polygon",
"flags": {}
}
],
"imagePath": "5.jpg",
"imageData": null,
"imageHeight": 4686,
"imageWidth": 8192
}
1.2 数据绘图
在应用到自己的数据集上,只需要修改json_dir即可。通过以下代码,可以将1.1步骤生成的json文件绘制为png图片
from labelme import utils
import numpy as np
from skimage import io
import glob,os,json
from PIL import Image
#定义一个绘图函数
def draw_json_file(json_dir=""):
#将json_dir下所有的json文件的文件名读取到json_files中
json_files=glob.glob(os.path.join(json_dir, '*.json'))
#设置了标签名和数值的对应关系(标签是文本,绘制需要颜色【通过数值来体现】)
label_name_to_value = {'_background_': 0, "f": 1, "xjl": 2}
#为了绘制伪彩色图片,定义了数值与rgb的对应关系
colors = [(255,255,255), (128, 0, 0), (0, 128, 0), (128, 128, 0), (0, 0, 128), (128, 0, 128), (0, 128, 128),
(128, 128, 128), (64, 0, 0), (192, 0, 0), (64, 128, 0), (192, 128, 0), (64, 0, 128), (192, 0, 128),
(64, 128, 128), (192, 128, 128), (0, 64, 0), (128, 64, 0), (0, 192, 0), (128, 192, 0), (0, 64, 128),
(128, 64, 12)]
colors=np.array(colors).astype(np.uint8)
#遍历所有的json文件
for path in json_files:
print(path)
#将json文件加载为json对象
data = json.load(open(path))
img = io.imread(json_dir+data['imagePath'])
#lbl:语义分割label图 ins:实例分割label图
lbl, ins = utils.shapes_to_label(img.shape, data['shapes'], label_name_to_value)
#将具体的语义分割label值保存为文件 只要图片使用Image.open()进行读取,就不会影响其实际的值
iamge=Image.fromarray(lbl).convert("P")
iamge.putpalette(colors)
iamge.save(path.replace(".json",'.png'))
#生产彩色分割图
# seg_img = np.zeros((img.shape[0],img.shape[1], 3),np.uint8)
# for c in range(len(label_name_to_value)):
# seg_img[:,:,0] += ((lbl[:,: ] == c )*( colors[c][0] )).astype('uint8')
# seg_img[:,:,1] += ((lbl[:,: ] == c )*( colors[c][1] )).astype('uint8')
# seg_img[:,:,2] += ((lbl[:,: ] == c )*( colors[c][2] )).astype('uint8')
#将彩色分割图与原图进行混合
#seg_img = Image.blend(Image.fromarray(img),Image.fromarray(seg_img), 0.7)
#保存彩色分割图
#seg_img.save(path.replace(".json",'_color_label.png'))
#将具体的实例分割label值保存为文件
#iamge=Image.fromarray(ins).convert("P")
#iamge.putpalette(colors)
#iamge.save(path.replace(".json",'_ins.png'))
#设置自己的数据路径
json_dir="./海南橡胶林数据/"
draw_json_file(json_dir)
代码执行效果如下所示:

1.3 数据裁剪
非必要。只针对于大图数据,如果原始标准的就是小图,则不需要进行裁剪。这里标注的是较大的卫星遥感影像,故需要进行裁剪。
在以下代码中,需要注意的是path对应自己数据集的路径,然后
import math,os
import numpy as np
from PIL import Image
#将大图裁剪为小图
#img:要裁剪的大图
#crop_size:要裁剪的大小
#pad:每一次裁剪图像的填充,避免将一个对象裁剪到两个图像中
def big_img2small_crop(img,crop_size=(736,736),pad=0):
img_list=[]
img_size=img.shape
loc=[]
size=(crop_size[0]-2*pad,crop_size[1]-2*pad)
for i in range(pad,img.shape[0]-pad,size[0]):
for j in range(pad,img.shape[1]-pad,size[1]):
tmp=img[i-pad:i+size[0]+pad,j-pad:j+size[1]+pad]
if tmp.shape[0]!=crop_size[0] or tmp.shape[1]!=crop_size[1]:
if tmp.shape[0]!=crop_size[0]:
i=img.shape[0]-size[0]-pad
if tmp.shape[1]!=crop_size[1]:
j=img.shape[1]-size[1]-pad
tmp=img[i-pad:i+size[0]+pad,j-pad:j+size[1]+pad] #256
img_list.append(tmp)
loc.append((i-pad,j-pad,*size))
return img_list,img_size,loc
path=r'海南橡胶林数据\\'
save_dir="crop"
crop_size=(1024,1024)
pad=50
#检测save_dir是否存在,不存在则创建
if not os.path.exists(save_dir):
os.makedirs(save_dir)
#提取出path下的jpg文件名
flist=os.listdir(path)
flist=[x for x in flist if '.jpg' in x]
print(flist)
""" 具体输出信息如下所示
['1.jpg', '10.jpg', '11.jpg', '12.jpg', '13.jpg', '14.jpg', '15.jpg', '16.jpg',
'17.jpg', '18.jpg', '19.jpg', '2.jpg', '20.jpg', '21.jpg', '22.jpg', '23.jpg',
'24.jpg', '25.jpg', '26.jpg', '27.jpg', '28.jpg', '29.jpg', '3.jpg', '30.jpg',
'31.jpg', '32.jpg', '33.jpg', '34.jpg', '35.jpg', '36.jpg', '37.jpg', '38.jpg',
'39.jpg', '4.jpg', '40.jpg', '41.jpg', '42.jpg', '43.jpg', '45.jpg', '46.jpg',
'47.jpg', '48.jpg', '49.jpg', '5.jpg', '50.jpg', '51.jpg', '52.jpg', '53.jpg',
'54.jpg', '55.jpg', '56.jpg', '57.jpg', '58.jpg', '59.jpg', '6.jpg', '60.jpg',
'61.jpg', '7.jpg', '8.jpg', '9.jpg']
"""
#为了绘制伪彩色图片,定义了数值与rgb的对应关系
colors=[(255,255,255), (128, 0, 0), (0, 128, 0), (128, 128, 0), (0, 0, 128), (128, 0, 128), (0, 128, 128),
(128, 128, 128), (64, 0, 0), (192, 0, 0), (64, 128, 0), (192, 128, 0), (64, 0, 128), (192, 0, 128),
(64, 128, 128), (192, 128, 128), (0, 64, 0), (128, 64, 0), (0, 192, 0), (128, 192, 0), (0, 64, 128),
(128, 64, 12)]
colors=np.array(colors).astype(np.uint8)
#用于切片的计数,同时作为保存切片的文件名
fcount=0
for fname in flist:
img=Image.open(path+fname)#返回图像对象
img=np.array(img)#将图像对象转换为np数组
#获取与jpg对应的标签文件名
l_name=fname.replace(".jpg",".png")#示例:1.jpg=>1.png
img_l=Image.open(path+l_name)#返回图像对象
img_l=np.array(img_l)#将图像对象转换为np数组
print(fname,img.shape)
#获取原始图像的裁剪小图
img_list,_,_=big_img2small_crop(img,crop_size,pad)
#获取标签图像的裁剪小图
img_list2,_,_=big_img2small_crop(img_l,crop_size,pad)
#同时遍历两个小图集,crop对应img_list,crop2对应img_list2
for crop,crop2 in zip(img_list,img_list2):
#只保存标签面积超过阈值的数据 如果标签中黑色面积较大则不保存
if crop2.sum()>crop.shape[1]*30:
iimg=Image.fromarray(crop)
iimg.save('%s/%s.jpg'%(save_dir,fcount))
iimg=Image.fromarray(crop2,mode='P')
iimg.putpalette(colors)#设置伪彩色画板,只能针对mode='P'的Image对象
iimg.save('%s/%s.png'%(save_dir,fcount))
fcount+=1
2、环境安装
2.1 基本环境安装
为了避免新手上路,硬件资源不足。直接采用百度的aistudio平台作为开发环境。在aistudio中的基本环境如下:
OS 64位操作系统
Python 3(3.6/3.7/3.8/3.9/3.10),64位版本
pip/pip3(9.0.1+),64位版本
CUDA >= 10.2
cuDNN >= 7.6
PaddlePaddle (版本>=2.4)
如果是在自己的电脑上则在自己的电脑上配置好显卡(cuda、cudnn)、python、PaddlePaddle 环境等。
2.2 paddlseg安装
paddleseg的安装可以参考https://github.com/PaddlePaddle/PaddleSeg/blob/release/2.8/docs/install_cn.md
先是下载PaddleSeg
git clone https://github.com/PaddlePaddle/PaddleSeg
然后执行安装命令
cd PaddleSeg
pip install --user -r requirements.txt
pip install -v -e .
cd PaddleSeg是指进入下载好的PaddleSeg目录
pip install --user -r requirements.txt 是安装PaddleSeg的依赖环境
pip install -v -e . 是将PaddleSeg安装在当前目录(-e表示可编辑模式)
3、训练模型
3.1 数据格式分析
因为自己处理的数据集格式,不一定与PaddleSeg默认的数据格式相同,故对其基本案例中的数据集格式进行分析。
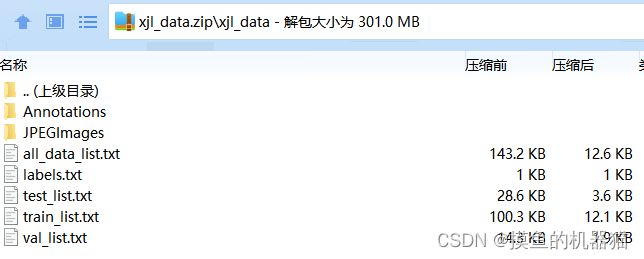
paddleseg提供的参考数据集---- 视盘分割(optic disc segmentation)数据集下载链接如下:https://paddleseg.bj.bcebos.com/dataset/optic_disc_seg.zip
下载解压后发现其在Annotations下存储着png标注图像,在JPEGImages中存储着jpg原始图片

labels.txt的内容如下:
背景
视盘
test_list.txt、train_list.txt和val_list.txt分别存储着测试集、训练集和验证集数据,每个txt中的格式均为文件列表格式,具体如下。每一行表示一个数据样本,原始图像在前,标签图片在后,使用空格分割。
JPEGImages/P0005.jpg Annotations/P0005.png
JPEGImages/N0156.jpg Annotations/N0156.png
JPEGImages/P0199.jpg Annotations/P0199.png
JPEGImages/P0180.jpg Annotations/P0180.png
JPEGImages/P0077.jpg Annotations/P0077.png
JPEGImages/N0044.jpg Annotations/N0044.png
JPEGImages/P0189.jpg Annotations/P0189.png
JPEGImages/P0192.jpg Annotations/P0192.png
JPEGImages/P0195.jpg Annotations/P0195.png
JPEGImages/P0050.jpg Annotations/P0050.png
JPEGImages/N0019.jpg Annotations/N0019.png
JPEGImages/P0165.jpg Annotations/P0165.png
JPEGImages/P0082.jpg Annotations/P0082.png
JPEGImages/P0169.jpg Annotations/P0169.png
JPEGImages/N0067.jpg Annotations/N0067.png
3.2 数据格式转换
我们需要将自己的数据集转换为paddleseg默认的格式。具体分两步实现:一、将所有的数据集信息转换为文件列表的形式
二、对现有的文件列表进行分割,得到训练集、验证集和测试集
先将我们的原始图像(jpg图像)存入JPEGImages目录下,将标签图片(png图片)存入Annotations目录下。
信息转文件列表
默认将数据集存储在xjl_data文件夹下,所有的数据信息存储在all_data_list.txt中
import os
path="D:/实战项目/橡胶林识别/xjl_data/JPEGImages/"
f = open("./xjl_data/all_data_list.txt", "w")
for fname in os.listdir(path):
jpg_name='JPEGImages/'+fname
#print(fname)
fname_list=fname.split(".")
fname_list[1]="png"
png_name=".".join(fname_list)
png_name='Annotations/'+ png_name
txt=jpg_name+" "+png_name
print(txt)
f.write(txt+"\n")
f.close()
数据集划分
通过以下代码可以将all_data_list.txt中的信息划分为训练集、验证集和测试集。可以设置它们的划分比例;同时,可以通过设置随机种子打乱数据的顺序。
import random
f=open('xjl_data/all_data_list.txt', encoding='gbk')
txt=[]
for line in f:
txt.append(line.strip())
#设置随机数种子
random.seed(2)
#根据种子打乱顺序
random.shuffle(txt)
#print(txt)
#设置划分比例
train_rate=0.7
test_rate=0.2
val_rate=1-(train_rate+test_rate) #0.1
#计算每一个数据集的数量,注意float转int
train_len=len(txt)*train_rate
test_len=int(len(txt)*test_rate)
val_len=int(len(txt)*val_rate)
train_len=int(train_len)
#print(train_len,test_len,val_len)
train_data=txt[0:train_len]
test_data=txt[train_len:train_len+test_len]
val_data=txt[train_len+test_len:]
print(val_data,len(val_data),val_len)
file=open('xjl_data/train_list.txt','w')
for data in train_data:
file.write(data)
file.write('\n')
file.close()
file=open('xjl_data/test_list.txt','w')
for data in test_data:
file.write(data)
file.write('\n')
file.close()
file=open('xjl_data/val_list.txt','w')
for data in val_data:
file.write(data)
file.write('\n')
file.close()
数据集压缩
将前面步骤中生成的数据集,构造成以下格式的压缩包。记住,要连父目录一块压缩,压缩包打开是先看到xjl_data目录
数据集上传
在aistudio平台中的操作界面中进入PaddleSeg/data目录下(如果没有data目录则自己创建一个)

数据集解压
需要在终端|命令行里进入PaddleSeg/data目录,然后执行unzip xjl_data.zip 命令进行文件解压
aistudio@jupyter-2334047-6029671:~/PaddleSeg$ cd data
aistudio@jupyter-2334047-6029671:~/PaddleSeg/data$ ls
xjl_data.zip
aistudio@jupyter-2334047-6029671:~/PaddleSeg/data$ unzip xjl_data.zip
最终,我们的目录结构如下:
aistudio@jupyter-2334047-6029671:~/PaddleSeg/data$ tree -L 2
.
├── xjl_data
│ ├── all_data_list.txt
│ ├── Annotations
│ ├── JPEGImages
│ ├── labels.txt
│ ├── test_list.txt
│ ├── train_list.txt
│ └── val_list.txt
└── xjl_data.zip
3.3 训练|验证|测试
配置文件构造
将以下内容保存到PaddleSeg/congfigs目录下的mydata.yaml文件中(可以自建一个)
这里需要注意dataset_root、train_path、val_path、num_classes的设置
batch_size: 4 #设定batch_size的值即为迭代一次送入网络的图片数量,一般显卡显存越大,batch_size的值可以越大。如果使用多卡训练,总得batch size等于该batch size乘以卡数。
iters: 1000 #模型训练迭代的轮数
train_dataset: #训练数据设置
type: Dataset #指定加载数据集的类。数据集类的代码在`PaddleSeg/paddleseg/datasets`目录下。
dataset_root: data/xjl_data #数据集路径
train_path: data/xjl_data/train_list.txt #数据集中用于训练的标识文件
num_classes: 2 #指定类别个数(背景也算为一类)
mode: train #表示用于训练
transforms: #模型训练的数据预处理方式。
- type: ResizeStepScaling #将原始图像和标注图像随机缩放为0.5~2.0倍
min_scale_factor: 0.5
max_scale_factor: 2.0
scale_step_size: 0.25
- type: RandomPaddingCrop #从原始图像和标注图像中随机裁剪512x512大小
crop_size: [512, 512]
- type: RandomHorizontalFlip #对原始图像和标注图像随机进行水平反转
- type: RandomDistort #对原始图像进行亮度、对比度、饱和度随机变动,标注图像不变
brightness_range: 0.5
contrast_range: 0.5
saturation_range: 0.5
- type: Normalize #对原始图像进行归一化,标注图像保持不变
val_dataset: #验证数据设置
type: Dataset #指定加载数据集的类。数据集类的代码在`PaddleSeg/paddleseg/datasets`目录下。
dataset_root: data/xjl_data #数据集路径
val_path: data/xjl_data/val_list.txt #数据集中用于验证的标识文件
num_classes: 2 #指定类别个数(背景也算为一类)
mode: val #表示用于验证
transforms: #模型验证的数据预处理的方式
- type: Normalize #对原始图像进行归一化,标注图像保持不变
optimizer: #设定优化器的类型
type: SGD #采用SGD(Stochastic Gradient Descent)随机梯度下降方法为优化器
momentum: 0.9 #设置SGD的动量
weight_decay: 4.0e-5 #权值衰减,使用的目的是防止过拟合
lr_scheduler: # 学习率的相关设置
type: PolynomialDecay # 一种学习率类型。共支持12种策略
learning_rate: 0.01 # 初始学习率
power: 0.9
end_lr: 0
loss: #设定损失函数的类型
types:
- type: CrossEntropyLoss #CE损失
coef: [1, 1, 1] # PP-LiteSeg有一个主loss和两个辅助loss,coef表示权重,所以 total_loss = coef_1 * loss_1 + .... + coef_n * loss_n
model: #模型说明
type: PPLiteSeg #设定模型类别
backbone: # 设定模型的backbone,包括名字和预训练权重
type: STDC2
pretrained: https://bj.bcebos.com/paddleseg/dygraph/PP_STDCNet2.tar.gz
具体操作如下所示

详细命令可以参考https://github.com/PaddlePaddle/PaddleSeg/blob/release/2.8/README_CN.md
模型训练
export CUDA_VISIBLE_DEVICES=0 # Linux下设置1张可用的卡
# set CUDA_VISIBLE_DEVICES=0 # Windows下设置1张可用的卡
python tools/train.py \
--config configs/mydata.yaml \
--save_interval 500 \
--do_eval \
--use_vdl \
--num_workers 4 \
--save_dir output
上述训练命令解释:
–config指定配置文件。
–save_interval指定每训练特定轮数后,就进行一次模型保存或者评估(如果开启模型评估)。
–do_eval开启模型评估。具体而言,在训练save_interval指定的轮数后,会进行模型评估。
–use_vdl开启写入VisualDL日志信息,用于VisualDL可视化训练过程。
–num_workers 4 开启4个进程加载数据(视情况增大)。
–save_dir指定模型和visualdl日志文件的保存根路径。
在PP-LiteSeg示例中,训练的模型权重保存在output目录下,如下所示。总共训练1000轮,每500轮评估一次并保存模型信息,所以有iter_500和iter_1000文件夹。评估精度最高的模型权重,保存在best_model文件夹。后续模型的评估、测试和导出,都是使用保存在best_model文件夹下精度最高的模型权重。
模型评估
export CUDA_VISIBLE_DEVICES=0 # Linux下设置1张可用的卡
# set CUDA_VISIBLE_DEVICES=0 # Windows下设置1张可用的卡
python tools/val.py \
--config configs/mydata.yaml \
--model_path output/best_model/model.pdparams
模型预测
python tools/predict.py \
--config configs/mydata.yaml \
--model_path output/best_model/model.pdparams \
--image_path H0002.jpg \
--save_dir output/result