Elasticsearch 集群规模和容量规划
Elasticsearch 基础架构
自顶向下的架构体系

- Cluster — 协同工作的节点组,以保障 Elasticsearch 的运行。
- Node — 运行 Elasticsearch 软件的 Java 进程。
- Index — 组形成逻辑数据存储的分片的集合。
- Shard — Lucene 索引,用于存储和处理 Elasticsearch 索引的一部分。
- Segment — Lucene 段,存储了 Lucene 索引的一部分且不可变。
- Document — —条记录,用以写入 Elasticsearch 索引并从中检索数据。
节点角色划分及资源使用情况
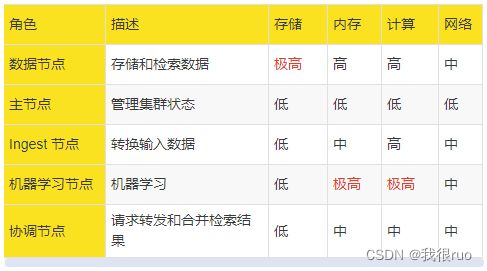
维系 Elasticsearch 高性能的资源组成
4 个基本的计算资源 存储、内存、计算、网络。
存储资源
存储介质
- 固态硬盘(SSD) 提供最佳“热”工作负载的性能。
- 普通磁盘(HDD) 成本低,用于“暖”和“冷”数据存储。
注意:RAID 可以提高性能。RAID 是可选的,因为 Elastic 默认为 N + 1 分片复制策略。
为了追求硬件级别的高可用性,可以接受标准性能的 RAID 配置(例如 RAID 1/10/50 等)。
存储建议
- 建议直接使用:附加存储(DAS)、存储区域网络(SAN)、超融合存储(建议最低〜3Gb / s,250Mb / s)
- 避免使用:网络附加存储(NAS)例如 SMB,NFS,AFP。使用时可能带来的性能问题:网络协议的开销,延迟大和昂贵的存储抽象层。
内存资源
JVM Heap
存储有关集群索引、分片、段和 fielddata 数据。
建议:可用 RAM 的 50%,最多最大 30GB RAM,以避免垃圾回收。
官方文档最大指 32 GB:https://www.elastic.co/guide/en/elasticsearch/guide/master/heap-sizing.html
操作系统缓存
Elasticsearch 将使用剩余的可用内存来缓存数据(Lucene 使用), 通过避免在全文检索、文档聚合和排序环节的磁盘读取,极大地提高了性能。
计算资源
可用的计算资源:线程池、线程队列。
CPU 内核的数量和性能:决定着计算平均速度和峰值吞吐量。
网络资源
小带宽是限制 Elasticsearch 的资源。
针对大规模集群,ingest、搜索和副本复制相关的数据传输可能会导致网络饱和。
在这些情况下,网络连接可以考虑升级到更高的速度,或者 Elastic 部署可以分为两个或多个集群,然后使用跨集群(CCS)作为单个逻辑单元进行搜索。
数据增删改查操作
增、删、改、查是 Elasticsearch 中的四个基本数据操作。
每个操作都有其自己的资源需求。每个业务用例都利用其中一个操作,实际业务往往会侧重其中一个或多个操作。
- 增:新增索引处理文档并将其存储在索引中,以备将来检索。
- 删:从索引中删除文档。
- 改:更新删除文档并为其替换的新文档建立索引。
- 查:搜索从一个或多个索引中检索或聚合一个或多个文档。
增/索引数据处理流程
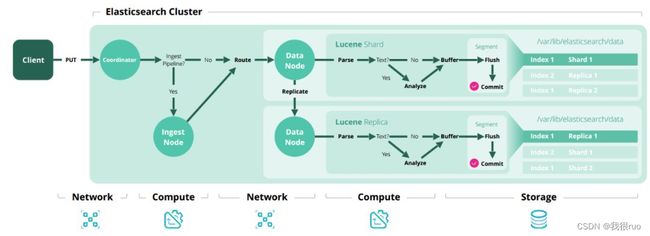
如图所示,增/索引数据大致的处理流程如下:
1、客户端发起写入请求到协调节点;
2、协调节点根据请求类型的不同进行判断,如果是 Ingest 相关,提交给 Ingest 节点;如果不相关,则计算路由后提交给数据节点;
3、数据节点根据数据类型不同决定是否分词以索引化数据,最终落地磁盘存储;同时将副本分发给其他数据节点。
删除数据处理流程
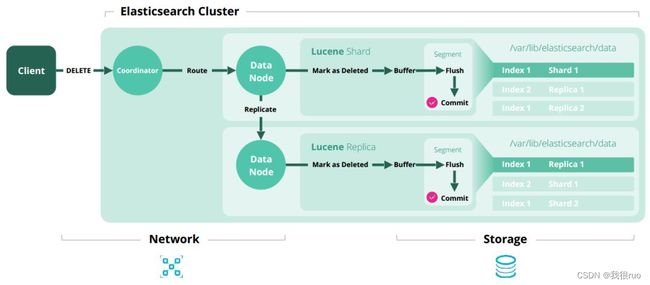
如果所示,删除数据大致处理流程如下:
1、客户端发出删除文档请求到协调节点;
2、协调节点将请求路由给数据节点;
3、数据节点接收到请求后,将数据标记为 deleted 状态(注意,此处为逻辑删除)
4、待段合并时机,逻辑删除会变成物理删除。
更新数据处理流程
文档在 Elasticsearch 中是不可变的。当 Elasticsearch 更新文档时,它将删除原始文档并为新的待更新的文档建立索引。
这两步操作在每个 Lucene 分片是原子操作,操作会带来删除和索引(索引不调用任何 ingest pipeline 操作)操作的开销。
Update = Delete + (Index - Ingest Pipeline)
检索操作处理流程
“搜索”是信息检索的通用术语。Elasticsearch 具有多种检索功能,包括但不限于全文搜索、范围搜索、脚本搜索和聚合。
搜索速度和吞吐量受许多因素影响,包括集群的配置、索引、查询和硬件。
实际的容量规划取决于应用上述优化配置后的大量测试实践结果。
Elasticsearch 检索可以细化分为:scatter(分散)、 search(检索)、gather(收集)、merge(合并)四个阶段。
- scatter:将结果分发给各个相关的分片;
- search:在各个分片执行检索;
- gather:数据节点将检索结果汇集到协调节点;
- merge:协调节点将数据结果进行合并,返回给客户端。
用例场景
Elasticsearch 有一些常规的使用模式。大致可分类如下:
- 写/索引(Index)密集型的业务场景:Logging, Metrics, Security, APM
- 检索(search)密集型的业务场景:App Search, Site Search, Analytics
- 更新(update)密集型的业务场景:Caching, Systems of Record
- 混合(hybrid)业务场景:支持多种操作的混合用例 Transactions Search
Elasticsearch 索引化流程
概述
以下过程适用于 ingest 节点处理数据流程。
- Json 数据转换——结构化或非结构化数据,转换为 json 落地存储。
- 数据索引化——数据以不同数据类型进行处理和索引。
- 数据压缩——提高存储效率。
- 副本复制——提高容错能力和搜索吞吐量。
Json 转换
结构化或非结构化数据转换成 json 格式,可通过_source 控制是否展示。
数据索引化
第一:数据结构 Elasticsearch 索引各种数据结构中的值。每种数据类型 有自己的存储特性。
第二:多种索引方法 某些值可以通过多种方式索引。字符串值通常是索引两次(借助 fields 实现)。
- 一次作为聚合的 keyword 类型;
- 一次作为文本用于全文搜索的 text 类型。
数据压缩
Elasticsearch 可以使用两种不同的压缩算法之一来压缩数据:LZ4(默认)和 DEFLATE。
与 LZ4 相比,DEFLATE 节省了多达 15%的额外空间,但以增加的计算时间为代价。
通常,Elasticsearch 可以将数据压缩 20 – 30%。
副本分片拷贝
第一:存储 Elasticsearch 可以在数据节点之间复制分片一次或多次,以提高容错能力和搜索吞吐量。
每个副本分片都是其主分片的完整副本。
第二:索引和搜索吞吐量
- 日志记录和指标用例场景(Logging and metrics)通常具有一个副本分片,这是确保出现故障的最小数量, 同时最大程度地减少了写入次数。
- 搜索用例通常具有更多的副本分片以提高搜索吞吐率。
完整示例

集群规模和容量规划预估方法
容量规划 —— 预估集群中每个节点的分片数、内存及存储资源。
吞吐量规划 —— 以预期的延迟和吞吐量估算处理预期操作所需的内存,计算和网络资源。
数据量预估
第一,问自己几个问题:
- 您每天将索引多少原始数据(GB)?
- 您将保留数据多少天?
- 每天增量数据是多少?
- 您将强制执行多少个副本分片?
- 您将为每个数据节点分配多少内存?
- 您的内存:数据比率是多少?
第二,预留存储以备错误。(Elastic 官方推荐经验值) - 预留 15%警戒磁盘水位空间。
- 为错误余量和后台活动预留+ 5%。
- 保留等效的数据节点以处理故障。
第三,容量预估计算方法如下: - 总数据量(GB) = 原始数据量(GB) /每天 X 保留天数 X 净膨胀系数 X (副本 + 1)
- 磁盘存储(GB) = 总数据量(GB)* ( 1 + 0.15 + 0.05)
- 数据节点 = 向上取整(磁盘存储(GB)/ 每个数据节点的内存量 / 内存:数据比率)+ 1
Tips:腾讯云 在 2019 4 月的 meetup 分享中建议:磁盘容量大小 = 原始数据大小 * 3.38。
分片预估
第一,问自己几个问题:
- 您将创建多少索引?
- 您将配置多少个主和副本分片?
- 您将在什么时间间隔旋转索引?
- 您将保留索引多长时间?
- 您将为每个数据节点分配多少内存?
第二,经验值(Elastic 官方推荐)
- 每 GB JVM 堆内存支持的分片数不超过 20 个。
- 每个分片大小不要超过 50GB。推荐阅读:https://www.elastic.co/cn/blog/how-many-shards-should-i-have-in-my-elasticsearch-cluster
Tips:
- 将小的每日索引整合为每周或每月的索引,以减少分片数。
- 将大型(> 50GB)每日索引分拆分成小时索引或增加主分片的数量。
第三,分片预估方法如下:
- 总分片数 = 索引个数 X 主分片数 * (副本分片数 +1)X 保留间隔
- 总数据节点个数 = 向上取整(总分片数 / (20 X 每个节点内存大小))
搜索吞吐量预估
搜索用例场景除了考虑搜索容量外,还要考虑如下目标:
- 搜索响应时间;
- 搜索吞吐量。
这些目标可能需要更多的内存和计算资源。
第一:问自己几个问题
- 您期望每秒的峰值搜索量是多少?
- 您期望平均搜索响应时间是多少毫秒?
- 您期望的数据节点上几核 CPU,每核有多少个线程?
第二:方法论 与其确定资源将如何影响搜索速度,不如通过在计划的固定硬件上进行测量,可以将搜索速度作为一个常数,
然后确定集群中要处理峰值搜索吞吐量需要多少个核。
最终目标是防止线程池排队的增长速度超过了 CPU 的处理能力。
如果计算资源不足,搜索请求可能会被拒绝掉。
第三:吞吐量预估方法
- 峰值线程数 = 向上取整(每秒峰值检索请求数 * 每个请求的平均响应时间(毫秒)/1000)
- 线程队列大小 = 向上取整((每个节点的物理 cpu 核数 * 每核的线程数 * 3 / 2)+ 1)
- 总数据节点个数 = 向上取整(峰值线程数 / 线程队列大小)
冷热集群架构
Elasticsearch 可以使用分片分配感知(shard allocation awareness)在特定硬件上分配分片。
索引密集型业务场景通常使用它在热节点、暖节点和冷(Frozen)节点上存储索引,
然后根据业务需要进行数据迁移(热节点 -> 暖节点 -> 冷节点),以完成数据的删除和存档需要。
这是优化集群性能的最经济方法之一,在容量规划期间,先确定每一类节点的数据规模,然后进行组合。
冷热集群架构推荐:

集群节点角色划分
Elasticsearch 节点执行一个或多个角色。通常,当集群规模大时,每个节点分配一个具体角色很有意义。
您可以针对每个角色优化硬件,并防止节点争夺资源,具体方法见前面章节。