【计算机组成与体系结构Ⅱ】流水线及流水线中的冲突(实验)
实验3:流水线及流水线中的冲突
一、实验目的
- 加深对计算机流水线基本概念的理解。
- 理解MIPS结构如何用5段流水线来实现,理解各段的功能和基本操作。
- 加深对数据冲突和资源冲突的理解,理解这两类冲突对CPU性能的影响。
- 进一步理解解决数据冲突的方法,掌握如何应用定向技术来减少数据冲突引起的停顿。
二、实验平台
指令级和流水线操作级模拟器MIPSsim。
三、实验内容和步骤
- 启动MIPSsim。
- 进一步理解流水线窗口中各段的功能,掌握流水寄存器的含义。(鼠标双击各段,即可看到各流水寄存器的内容)
- 载入一个样例程序pipeline.s(本模拟器所在文件夹下的“样例程序”文件夹中),然后分别以单步执行一个周期、执行多个周期、连续执行、设置断点等方式运行程序,观察程序的执行情况,观察 CPU 中寄存器和存储器内容的变化,特别是流水寄存器内容的变化。
- 选择配置菜单中的“流水方式”选项,使模拟器工作于流水方式下。
- 观察程序在流水方式下的执行情况。
四、实验结果
1:按照实验内容(3),选择“非流水方式”,载入pipeline.s,使用连续执行运行,可以得到该文件的最终执行情况
(1)代码窗口情况:

(2)内存窗口情况:

(3)寄存器情况:


2:按照实验内容(4)和(5),选择“流水方式”,载入pipeline.s,使用单步执行一个周期运行,可以得到该文件的在流水方式下每个时钟周期各个指令在IF、ID、EX、MEM、WB段的执行情况,以及可以观察到发生变化的通用寄存器以及流水线寄存器
(1)流水线模拟中间结果:
时钟周期:0~18
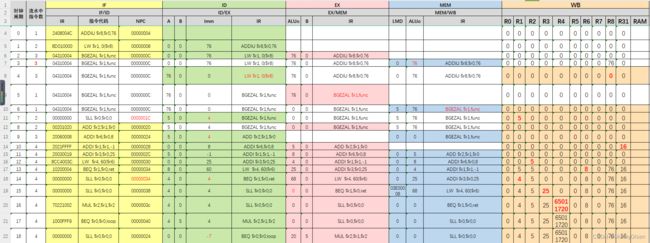
时钟周期:19~32

时钟周期:33~46
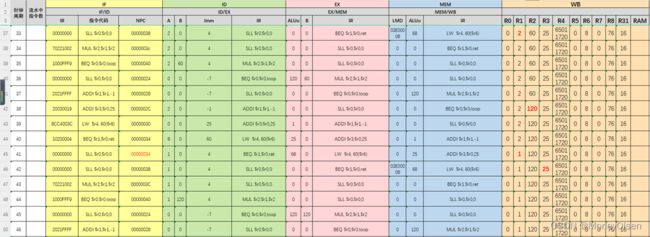
时钟周期:47~57

(2)统计窗口情况:
执行周期数:58(即时钟周期0至时钟周期57)
硬件配置:加法器1个,执行6个周期;乘法器1个,执行7个周期;除法器1个,执行10个周期;不采用定向技术

停顿周期:
| 停顿内容 |
停顿周期数 |
| RAW停顿 |
4 |
| 控制停顿 |
11 |
| 自陷停顿 |
1 |
| 停顿总数 |
16 |

分支指令:

Load/Store指令:

浮点指令:

自陷指令:

(3)时钟周期图情况:
时钟周期:0~21

时钟周期:22~43(从上一张图的【ADDI $r1,$r1,-1】开始)

时钟周期:44~57(从上一张图的【BEQ $r1,$r0,ret】开始)

3:分析pipeline.s所执行的功能
pipeline.s每一条指令所执行的内容如下表所示。
| 指令 |
指令注释 |
| .text |
代码段起始 |
| main: |
main起始 |
| ADDIU $r8,$r0,num |
将 $r0 与num的地址相加,结果存入 $r8 |
| LW $r1, 0($r8) |
将 $r8 指向的地址加载一个字到 $r1 |
| BGEZAL $r1,func |
如果 $r1 的值大于等于0,则跳转到 func,并保存返回地址 |
| SLL $r0,$r0,0 |
空指令 |
| SW $r2, 60($r0) |
将 $r2 的内容存储到 $r0 + 60 的地址 |
| TEQ $r0,$r0 |
自陷指令 |
| SLL $r0,$r0,0 |
空指令 |
| func: |
func起始 |
| ADD $r2,$r1,$r0 |
将 $r1 和 $r0 的值相加,结果存入 $r2 |
| ADDI $r6,$r0,8 |
将 $r0 的值加上8,结果存入 $r6 |
| loop: |
loop起始 |
| ADDI $r1,$r1,-1 |
将 $r1 的值减1 |
| ADDI $r3,$r0,25 |
将 $r0 的值加上25,结果存入 $r3 |
| LW $r4, 60($r6) |
从 $r6 + 60 的地址加载一个字到 $r4 |
| BEQ $r1,$r0,ret |
如果 $r1 等于 $r0,则跳转到 ret |
| SLL $r0,$r0,0 |
空指令 |
| MUL $r2,$r1,$r2 |
将 $r1 和 $r2 的值相乘,结果存入 $r2 |
| BEQ $r0,$r0,loop |
无条件跳转回 loop |
| SLL $r0,$r0,0 |
空指令 |
| ret: |
ret起始 |
| JR $r31 |
跳转到 $r31 寄存器存储的地址 |
| SLL $r0,$r0,0 |
空指令 |
| .data |
数据段起始 |
| num: .word 5 |
定义一个数据标签 num,初始化为 5 |
五、实验分析和总结
- 下载并完成网络平台中的“实验3-流水线模拟中间结果(学生)”,回答excel表中的最后两列提出的问题,并对本次实验进行总结,提出意见和建议。
1:表后问题回答
具体内容如【实验3-流水线模拟中间结果(学生).xlsx】所示,此处不再赘述。
2:实验总结
1)增强了对 MIPS 汇编语言和计算机流水线基本概念的理解,包括基本语法、指令集和如何用汇编语言编写程序。
2)学习了如何识别流水线中的数据冲突情况,以及通过定向技术、流水线暂停等方法解决流水线中的此类冲突。
3)学会了遇到资源冲突时可以考虑设置多个资源,使得指令能够并并行,例如在硬件配置中增加加法器、 乘法器和除法器的个数。
4)理解了MIPS结构如何用5段流水线来实现,理解了各段的功能和基本操作。
3:意见和建议
1)确保同学在动手操作之前对 MIPS 汇编语言和流水线处理的基本概念有充分的理解。
2)鼓励同学之间进行合作和讨论,促进知识的交流和更深入的理解。
- 观察和分析该流水段中都有哪些相关性,对CPU性能有哪些影响?模拟器中都采用了哪些方法避免冲突,请举例说明。
1:流水段中的相关性,及其对CPU性能的影响
相关性:
(1)数据相关性
读后写(RAW):指令 LW $r1, 0($r8) 读取 $r8 指向的内存地址的值。而紧接着的指令 BGEZAL $r1,func 需要使用 $r1 的结果,就必须等待 LW 指令完成后才能执行。
(2)控制相关性
指令 BGEZAL $r1,func 和 BEQ $r1,$r0,ret 是分支指令。分支指令引入控制相关性,因为它们决定了程序的下一步执行哪些指令。
(3)结构相关性
本实验中不存在结构相关性。
注:如果 CPU 的某些部件无法同时被多条指令共享,就会发生结构相关性。例如,如果内存访问(由 LW 和 SW 指令进行)和指令取出竞争同一个内存总线或缓存,就可能发生冲突。
影响:
(1)流水线延迟: 数据和结构相关性可能导致流水线暂停(即产生“气泡”),直到相关数据准备好或资源冲突解决才能继续流水。
(2)分支误预测的代价: 控制相关性导致的分支预测错误会使流水线中的一些已经执行的指令作废,这些指令需要被重新取出和执行,增加了额外的时间开销。
2:模拟器采用的避免冲突的方法,及其示例
(1)定向技术
定向技术是一种用于解决RAW的数据相关性的方法。例如,如果一条指令需要使用前一条指令的结果作为其输入,那么该结果可以直接从执行阶段转发到需要它的指令,而不必等待它先写回到寄存器文件。
示例:指令 ADDIU $r8,$r0,num 后紧跟 LW $r1, 0($r8),则 $r8 的值可以直接从 ADDIU 的执行单元转发给 LW。
(2)流水线暂停
当数据需要多个周期来准备的时候,流水线需要暂停。
示例:LW $r1, 0($r8) 后立即跟随 BGEZAL $r1,func,且数据从内存加载需要一个以上的周期,则 BGEXAL 指令需要等待直到 LW 完成数据加载后才能执行。
(3)分支预测
控制相关性是由分支指令引起的。分支预测器会尝试预测分支的结果,并据此提前取出指令。如果预测正确,可以显著减少因等待分支决策而浪费的周期。
示例:在处理 BEQ $r1,$r0,ret 指令时,分支预测器可能预测分支不会发生,并提前取出 ret 之后的指令。