网络编程关注的问题与reactor的应用
文章目录
- 一、网络编程关注的问题
-
- 连接的建立
- 连接的断开
- 消息的到达
- 消息发送完毕
- 二、reactor作为网络框架的职责
-
- 检测 IO与操作io
- io多路复用
- epoll编程
- 三、reactor的应用
-
- 单reactor
- 多reactor(one eventloop per thread)
- 水平与边缘触发的应用
一、网络编程关注的问题
连接的建立
分为两种:服务端处理接收客户端的连接,服务端作为客户端第三方连接
int clientfd = accept(listenfd, addr, sz);
// 举例为非阻塞io,阻塞io成功直接返回0;
int connectfd = socket(AF_INET, SOCK_STREAM, 0);
int ret = connect(connectfd, (struct sockaddr *)&addr, sizeof(addr));
// ret == -1 && errno == EINPROGRESS 正在建立连接
// ret == -1 && errno = EISCONN 连接建立成功
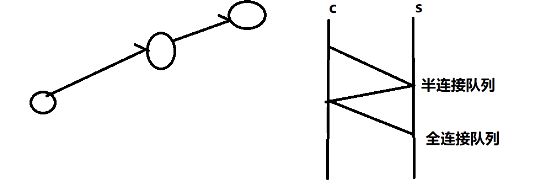
int clientfd = accept(listenfd, addr, sz);
accept作用的对象就是那个全连接队列里边的数据,生成clientfd,addr与sz就能解出客户端的ip地址,如果clientfd == -1 && errno == EWOULDBLOCK,说明全连接队列为空,accept能检测全连接队列的数据的状态,能够操作io。
accept检测的是全连接队列是否有数据到达!内核的网络协议栈自动完成三次握手建立连接以后,全连接队列增加数据,accept才处理(操作)全连接队列的数据,然后返回
连接的断开
分为两种:主动断开和被动断开
// 主动关闭
close(fd);
shutdown(fd, SHUT_RDWR);
// 主动关闭本地读端,对端写段关闭
shutdown(fd, SHUT_RD);
// 主动关闭本地写端,对端读段关闭
shutdown(fd, SHUT_WR);
// 被动:读端关闭
// 有的网络编程需要支持半关闭状态,所以有时候只关闭一端
int n = read(fd, buf, sz);
if (n == 0)
{
close_read(fd); //关闭读端
// write() ,有时候半关闭,还能发送数据
// close(fd); 不支持半关闭,直接调用close
}
// 被动:写端关闭
int n = write(fd, buf, sz);
if (n == -1 && errno == EPIPE)
{
close_write(fd);
// close(fd);
}
一条连接有读端和写端
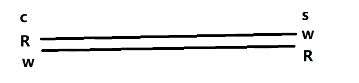
对应的就是四次挥手了
有的支持半关闭状态,也就是读端和写端只关闭其中一个
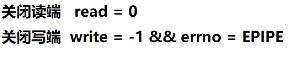
消息的到达
从缓冲区中读取数据
int n = read(fd, buf, sz);
if (n < 0) {
// n == -1
if (errno == EINTR || errno == EWOULDBLOCK)
break;
close(fd);
} else if (n == 0)
{
close(fd);
} else {
// 处理 buf
}
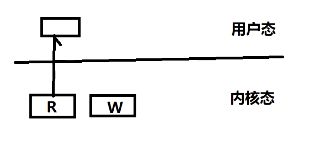
我们需要关注的是用户态和内核态的工作,从内核态的读缓冲区中读到我们的用户态中去
int n = read(fd,buf,sz);
fd对应的是内核读缓冲区,buf就是用户态的buf,sz就是预期要拷贝的数据的多少
n的值就是实际数据读的长度,如果n=-1,说明缓冲区为空,阻塞与非阻塞,主要看fd的属性,如果fd是阻塞的属性,缓冲区为空则会阻塞在读这里
消息发送完毕
我们把数据从用户态写到内核态的写缓冲区中
int n = write(fd, buf, sz);
n=-1//写缓冲区已经满了
n = sz//写入的长度
int n = write(fd, buf, sz);//write要么写入sz那么多数据,要么返回-1
if (n == -1)
{
if (errno == EINTR || errno == EWOULDBLOCK)
{
return;
}
close(fd);
}
二、reactor作为网络框架的职责
检测 IO与操作io
io 函数本身可以检测 io 的状态;但是只能检测一个 fd 对应的状态,比如说read;io 多路复用可以同时检测多个io的状态;区别是:io函数可以检测具体状态;io 多路复用只能检测出可读、可写、错误、断开等笼统的事件;
检测io可以通过函数的返回值返回一些错误码,根据错误码,
操作io只能使用 io 函数来进行操作
分为两种操作方式:阻塞 io 和非阻塞 io
区别就是阻塞在网络线程,比如说read这个线程里边,如果缓冲区里边有数据可读了,read才能返回,否则会一直阻塞在read这里不能往下走
连接的fd阻塞属性决定了 io 函数是否阻塞;
具体差异在:io函数在数据未到达时是否立刻返回;
// 默认情况下,fd 是阻塞的,设置非阻塞的方法如下;
int flag = fcntl(fd, F_GETFL, 0);
fcntl(fd, F_SETFL, flag | O_NONBLOCK);
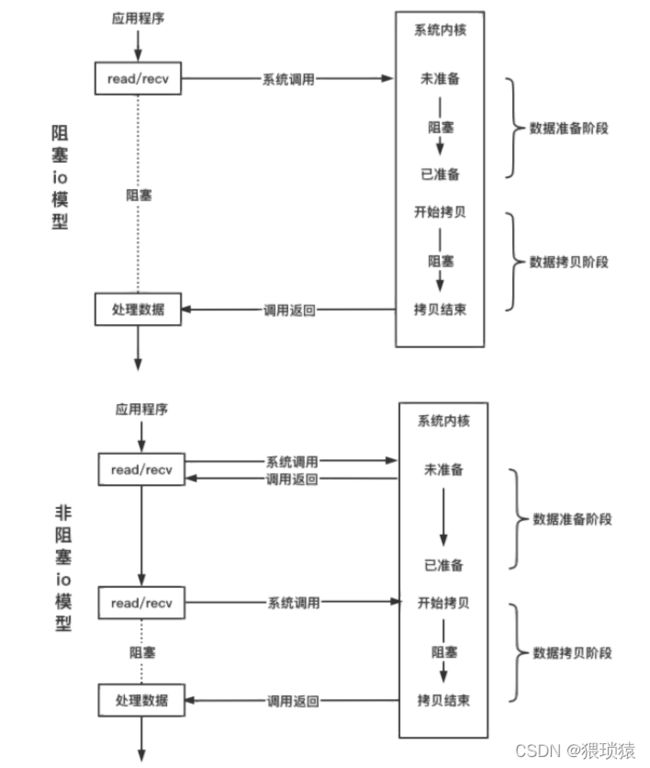
下图当中第一个阻塞io模型,数据准备与拷贝阶段都是阻塞
第二个非阻塞模型中,在数据准备阶段不管有没有数据都立刻返回,直到有了数据以后,函数返回有数据的返回值,就进行数据拷贝,其中数据拷贝阶段还是阻塞的
两个的区别就是数据准备阶段是否立刻返回
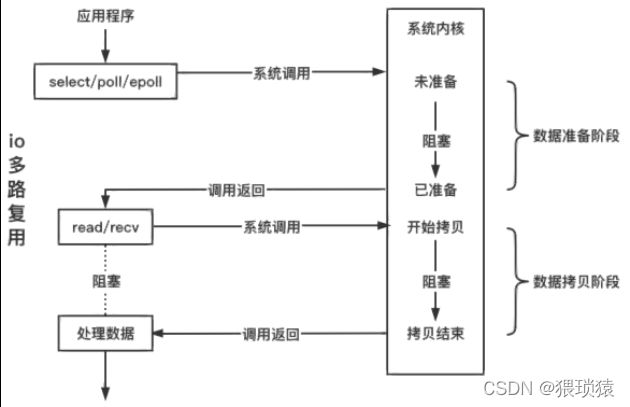
io多路复用
io多路复用的意思就是说,用一个事件管理器管理多个io,比如epoll
只负责检测io,不负责操作io
int n = epoll_wait(epfd, evs, sz, timeout); //timeout = -1 一直阻塞直到网络事件到达;
imeout = 0 不管是否有事件就绪立刻返回;对应非阻塞io
timeout = 1000 最多等待 1 s,如果1 s内没有事件触发则返回;
 epoll结构以及接口
epoll结构以及接口
struct eventpoll {
// ...
struct rb_root rbr; // 管理 epoll 监听的事件,红黑树
struct list_head rdllist; // 保存着 epoll_wait 返回满⾜条件的事件,双向链表
// ...
};
struct epitem {//红黑树的节点
// ...
struct rb_node rbn; // 红⿊树节点
struct list_head rdllist; // 双向链表节点
struct epoll_filefd ffd; // 事件句柄信息
struct eventpoll *ep; // 指向所属的eventpoll对象
struct epoll_event event; // 注册的具体监测事件的类型,
// ...
};
struct epoll_event {
__uint32_t events; // epollin epollout epollel(边缘触发)
epoll_data_t data; // 保存 关联数据
};
typedef union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
}epoll_data_t;
int epoll_create(int size);
/** op: EPOLL_CTL_ADD EPOLL_CTL_MOD EPOLL_CTL_DEL event.events: EPOLLIN 注册读事件 EPOLLOUT 注册写事件 EPOLLET 注册边缘触发模式,默认是水平触发 */
int epoll_ctl(int epfd, int op, int fd, struct epoll_event* event);
/** events[i].events: EPOLLIN 触发读事件 EPOLLOUT 触发写事件 EPOLLERR 连接发生错误 EPOLLRDHUP 连接读端关闭 EPOLLHUP 连接双端关闭 */
int epoll_wait(int epfd, struct epoll_event* events, int maxevents, int timeout);
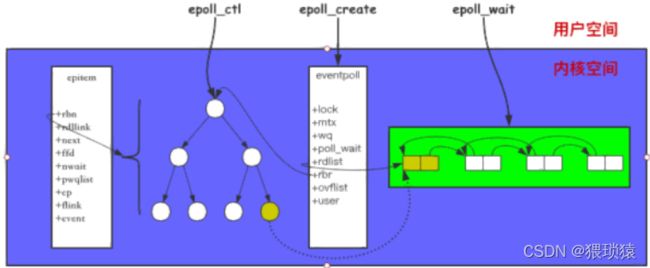
调用 epoll_create 会创建红黑树以及一个就绪队列,一个 epoll 对象;调用 epoll_ctl 去注册事件,添加到 epoll 中的事件都会与网卡驱动程序建立回调关系,epoll_ctrl会去操作这个红黑树,红黑树当中的节点就包含了一个fd,相应事件触发时会调用回调函数 (ep_poll_callback ),将触发的事件拷贝到 rdlist 双向链表中,也就是把红黑树当中的节点拷贝到那个双向链表中去,也就是就绪队列;调用 epoll_wait 将会把 rdlist 中就绪事件拷贝到用户态中,epoll_event* events就是用户态的一个数组,epoll_wait就是把双向队列当中的数据拷贝到event当中去, int maxevents就是预期要处理的数据的大小;第五个参数就是阻塞的时间。
之前的数据准备阶段就是就绪队列当中的数据
epoll编程
连接的建立
// 一、处理客户端的连接
// 1. 注册监听 listenfd 的读事件
struct epoll_event ev; ev.events |= EPOLLIN;
epoll_ctl(efd, EPOLL_CTL_ADD, listenfd, &ev);
// 2. 当触发listenfd的读事件,调用accept接收新的连接
int clientfd = accept(listenfd, addr, sz);
struct epoll_event ev;
ev.events |= EPOLLIN; //读事件,如果一开始是写事件呢,因为对应的是写缓冲区一开始就是空的,一直会触发写事件
epoll_ctl(efd, EPOLL_CTL_ADD, clientfd, &ev);
// 二、处理连接第三方服务
// 1. 创建 socket 建立连接
int connectfd = socket(AF_INET, SOCK_STREAM, 0);
connect(connectfd, (struct sockaddr *)&addr, sizeof(addr));
// 2. 注册监听 connectfd 的写事件,因为我们在最后一次握手当中要把ack包发出去,所以要注册可写事件
struct epoll_event ev; ev.events |= EPOLLOUT; epoll_ctl(efd, EPOLL_CTL_ADD, connectfd, &ev);
// 3. 当 connectfd 写事件被触发,连接建立成功
if (status == e_connecting && e->events & EPOLLOUT) //触发写事件
{
status == e_connected; // 这里需要把写事件关闭
epoll_ctl(epfd, EPOLL_CTL_DEL, connectfd, NULL);
}
连接断开
//epoll只能
if (e->events & EPOLLRDHUP) //读端关闭,epoll_wait处理数据之后
{ // 读端关闭
close_read(fd);
//close(fd);
}
if (e->events & EPOLLHUP)//读写端都关闭
{ // 读写端都关闭
close(fd);
}
数据到达
// 可能会出现读缓冲区无数据的情况,所以reactor 要用非阻塞io
// select当中没有数据可读,用阻塞的io会一直阻塞影响其他事件的处理,所以要用非阻塞io
//epoll
if (e->events & EPOLLIN)
{
while (1)
{
int n = read(fd, buf, sz);
if (n < 0)
{
if (errno == EINTR)
continue;
if (errno == EWOULDBLOCK)
break;
close(fd);
} else if (n == 0) {
close_read(fd);
// close(fd);
}
// 执行业务逻辑
}
}
数据发送完毕
指的是把数据写进写缓冲区,数据怎么到达对端,是由linux内核协议栈决定的
int n = write(fd, buf, dz);
if (n == -1)
{
if (errno == EINTR)
continue;
if (errno == EWOULDBLOCK) //写缓冲区已经满了或者不够的时候,也会返回EWOULDBLOCk
{
struct epoll_event ev;
ev.events = EPOLLOUT;
epoll_ctl(epfd, EPOLL_CTL_ADD, fd, &ev);//当写事件失败时才会去注册写事件,也就是写缓冲区不够用的时候,这也是为啥之前一开始不注册写事件的原因,一开始写缓冲区是空的
}
close(fd);
}// ...
if (e->events & EPOLLOUT)//接下来会区检测这个写缓冲区是否可写
{
int n = write(fd, buf, sz);//再来尝试写
//...
if (n > 0) //如果写成功了,还需要把写事件进行删掉
{
epoll_ctl(epfd, EPOLL_CTL_DEL, fd, NULL);
}
}
必须把这几个流程理清楚了,才会了解网络编程
三、reactor的应用
组成:io多路复用+非阻塞io
事件方式通知 事件循环
将io的处理转化为对事件的处理
while(1){
}
单reactor
redis用的就是单reactor的模型
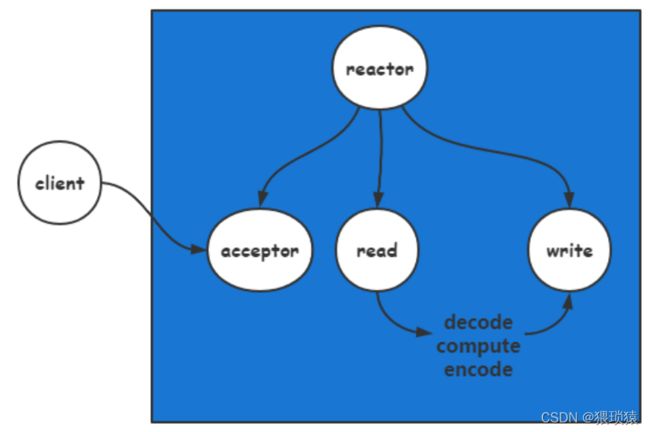
多条连接,也就是多个client都是由一个reactor进行管理
redis的封装层次

注册事件—>触发事件—>回调函数处理—>在回调函数中进行io操作
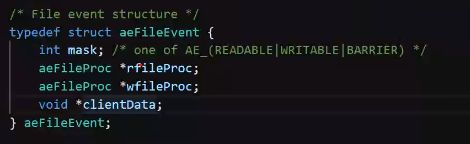
事件注册
其中mask相当于状态机,存储红黑树节点的状态
 事件循环中所取出的事件
事件循环中所取出的事件

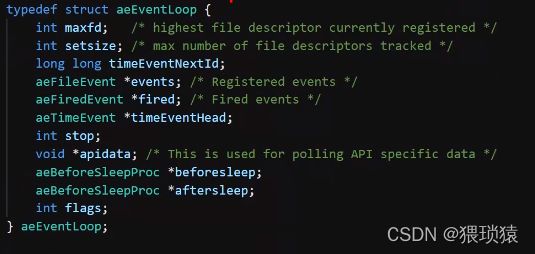
reactor事件管理器的封装
业务处理流程:
1、int n = read(fd, buf, sz);
2、cmd, args = decode(buf, sz);
3、out = logic(cmd, args);
4、reply = encode(out);
5、write(fd, reply, sizeof(reply));
优化思路:将耗时操作交给线程池来做。
redis:12、45交给线程池。
skynet:2345交给线程池。
具体根据业务需求进行优化,要注意多线程read、write的数据安全问题。
io多线程
redis当中,将读这个事件塞到队列当中,然后分配到多个io多线程去处理

网络线程做这么几个步骤,将以下的步骤分别下发到不同的线程进行处理
read放到网路主线程处理,write放到下面的多线程处理
一条连接放到多个线程去处理,也就是同样的fd,skynet就是这么搞的
write放到多线程去处理,写入顺序没有问题的,会不会有数据错乱的问题呢
用简单的加锁可以做到,因为只要主线程不去操作fd,那么write对fd的操作就是一次性的,要么写成功要么写失败,如果写失败再由网络主线程去写
为什么不在多线程去读呢,因为多线程读就可能出现数据错乱的问题,客户端发送一个包,分成两次来发,通过多线程去读,一个线程读到数据包的一半,另一个线程读到另一半,读的顺序就会出现问题。write每次都是全写入,要么成功要么失败,所以不用担心多线程写
所以单线程读,多线程写,这么做是没有问题的

redis为啥可以使用单reactor呢,里边的命令操作比较简单,数据结构比较优秀,这个我们后续可以详细讨论
其中decode与encode在执行当中比较长,会影响其他的业务,我们可以把他们纳入多线程进行处理,单线程读,多线程写,这些都是单reactor的优化
多reactor(one eventloop per thread)
为什么要将listenfd单独交由一个事件循环管理?
为了及时处理连接。reactor个数一般和CPU核心树相同。

把事件分发到多个reactor进行处理,每一个reactor都是一个线程
mysql当中由select专门处理连接的建立
如果每一个连接都有很多临界资源的交互,那么这个多reactor不适用
在每个线程比较独立的时候,加锁比较方便的时候,用多线程比较方便
那么这里为什么还要专门分配一个reactor专门管理连接呢
当我们要处理并发的连接,一个reactor还要处理其他的业务逻辑,连接总是被延迟处理了,这里我们就可以用一个reactor专门来处理连接的建立,这样就能尽快地处理连接
多进程
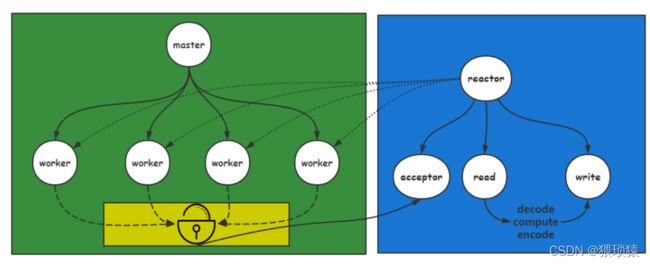
多进程例如我们的nginx
通过一个master进程fork出多个worker进程,每个worker进程中都有一个reactor,连接是通过worker进程进行连接,worker进程会监听到同一个端口上边,这里我们有一个共享内存,也就是用锁锁住的部分,worker进程会尝试去获取锁,谁获取锁,就会用accept接收这条连接,就把这条连接交由worker进程当中的epoll进行管理,都是由worker进程进行管理,这也是为啥nginx能把多进程做得那么出色的原因
水平与边缘触发的应用
redis和memcache使用的水平触发
用户层并不知道里边有多少数据,我们就需要去界定数据包,然后做业务逻辑,以业务为导向的通常会去用水平触发
nginx使用的边缘触发
nginx用来做反向代理的,客户端通过nginx转发到不同的服务器上边去,主要是用来做转发与反向代理的,不需要解析界定数据包,读到数据就往外边转发,用边缘触发效率就会高些