一、安装JDK
1、在usr目录下新建Java目录,然后将下载的JDK拷贝到这个新建的Java目录中1
创建目录命令:mkdir /usr/java
2、进入到Java目录中解压下载的JDK
解压命令:tar -zxvf jdk-18_linux-x64_bin.tar.gz
在1主机上,将安装包分发到其他机器
scp -r /opt/jdk1.8/ node2:/opt/
3、设置环境变量
设置命令:vim /etc/profile
输入上面的命令后,shift+g快速将光标定位到最后一行,然后按“i”,再输入下面代码
#set java environment
JAVA_HOME=/usr/java/jdk1.8
CLASSPATH=$JAVA_HOME/lib
PATH=$PATH:$JAVA_HOME/bin
export PHTH JAVA_HOME CLASSPATH
填写完代码后按ESC键,输入“:wq”保存并退出编辑页面
4、输入下面命令让设置的环境变量生效
生效命令:source /etc/profile
5、验证JDK是否安装成功java
验证命令:Java -version
二、安装Zookeeper
Zookeeper集群搭建指的是ZooKeeper分布式模式安装。通常由2n+1台server组成。这是因为为了保证Leader选举(基于Paxos算法的实现)能过得到多数的支持,所以ZooKeeper集群的数量一般为奇数。
Zookeeper运行需要java环境,所以需要提前安装jdk。对于安装leader+follower模式的集群,大致过程如下:
配置主机名称到IP地址映射配置
修改ZooKeeper配置文件
远程复制分发安装文件
设置myid
启动ZooKeeper集群
如果要想使用Observer模式,可在对应节点的配置文件添加如下配置:
peerType=observer
其次,必须在配置文件指定哪些节点被指定为Observer,如:
server.1:node1:2181:3181:observer
其次,必须在配置文件指定哪些节点被指定为 Observer,如:
server.1:localhost:2181:3181:observer
这里,我们安装的是leader+follower模式
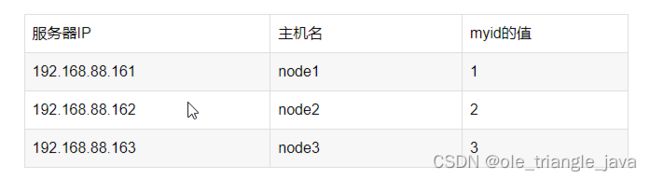
服务器IP
主机名 myid的值
第一步:下载zookeeeper的压缩包,下载网址如下
Index of /dist/zookeeper
我们在这个网址下载我们使用的zk版本为3.4.6
下载完成之后,上传到我们的linux的/opt路径下准备进行安装
第二步:解压
在node1主机上,解压zookeeper的压缩包到/opt路径下去,然后准备进行安装
tar -zxvf zookeeper-3.4.6.tar.gz
第三步:修改配置文件
在node1主机上,修改配置文件
cd /zookeeper-3.4.6/conf/
cp zoo_sample.cfg zoo.cfg
mkdir zkdatas
vim zoo.cfg
修改以下内容
#Zookeeper的数据存放目录
dataDir=/opt/zookeeper-3.4.6/zkdatas
# 保留多少个快照
autopurge.snapRetainCount=3
# 日志多少小时清理一次
autopurge.purgeInterval=1
# 集群中服务器地址
#当前服务器的ip设置为0.0.0.0
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
第四步:添加myid配置
在node1主机的/opt/zookeeper-3.4.6/zkdatas/这个路径下创建一个文件,文件名为myid ,文件内容为1
vim myid
echo 1 > /opt/zookeeper/data//myid
第五步:安装包分发并修改myid的值
在node1主机上,将安装包分发到其他机器
第一台机器上面执行以下两个命令
scp -r /opt/zookeeper-3.4.6/ node2:/opt/
scp -r /opt/zookeeper-3.4.6/ node3:/opt/
第二台机器上修改myid的值为2
echo 2 > /export/server/zookeeper-3.4.6/zkdatas/myid
第三台机器上修改myid的值为3
echo 3 > /export/server/zookeeper-3.4.6/zkdatas/myid
第六步:三台机器启动zookeeper服务
三台机器分别启动zookeeper服务
这个命令三台机器都要执行
/export/server/zookeeper-3.4.6/bin/zkServer.sh start
三台主机分别查看启动状态
/export/server/zookeeper-3.4.6/bin/zkServer.sh status
配置Path环境变量
1:分别在三台中,修改/etc/proflie,添加以下内容
export ZOOKEEPER_HOME=/export/server/zookeeper-3.4.6
export PATH=:$ZOOKEEPER_HOME/bin:$PATH
2:分别在三台主机中,source /etc/profile
切记:必须source,不然不生效
# 启动服务
./zkServer.sh start
# 查看状态
./zkServer.sh status
# 停止服务
./zkServer.sh stop
# 重启服务
./zkServer.sh restart
原文链接:https://blog.csdn.net/qq_64495672/article/details/124371474
三、安装Kafka
1 ) 解压安装包
[atguigu@hadoop102 software]$ tar -zxvf kafka_2.12-3.0.0.tgz -C /opt/module/
2 ) 修改解压后的文件名称
[atguigu@hadoop102 module]$ mv kafka_2.12-3.0.0/ kafka
3 ) 进入到 /opt/module/kafka 目录,修改配置文件
[atguigu@hadoop102 kafka]$ cd config/
[atguigu@hadoop102 config]$ vim server.properties
输入以下内容:
#broker 的全局唯一编号,不能重复,只能是数字。
broker.id=0
# 处理网络请求的线程数量
num.network.threads=3
# 用来处理磁盘 IO 的线程数量
num.io.threads=8
# 发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
# 接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
# 请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka 运行日志 ( 数据 ) 存放的路径,路径不需要提前创建, kafka 自动帮你创建,可以
配置多个磁盘路径,路径与路径之间可以用 " , " 分隔
log.dirs=/opt/module/kafka/datas
#topic 在当前 broker 上的分区个数
num.partitions=1
# 用来恢复和清理 data 下数据的线程数量
num.recovery.threads.per.data.dir=1
# 每个 topic 创建时的副本数,默认时 1 个副本
offsets.topic.replication.factor=1
#segment 文件保留的最长时间,超时将被删除
log.retention.hours=168
# 每个 segment 文件的大小,默认最大 1G
log.segment.bytes=1073741824
# 检查过期数据的时间,默认 5 分钟检查一次是否数据过期
log.retention.check.interval.ms=300000
# 配置连接 Zookeeper 集群地址(在 zk 根目录下创建 /kafka ,方便管理)
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka
4 ) 分发安装包
[atguigu@hadoop102 module]$ scp -r /opt/zookeeper-3.5.8/ node2:/opt/
5 ) 分别在 hadoop103 和 hadoop104 上修改配置文件 /opt/module/kafka/config/server.properties
中的 broker.id=1 、 broker.id=2
注: broker.id 不得重复,整个集群中唯一。
[atguigu@hadoop103 module]$ vim kafka/config/server.properties
修改 :
# The id of the broker. This must be set to a unique integer for
each broker.
broker.id=1
[atguigu@hadoop104 module]$ vim kafka/config/server.properties
修改 :
# The id of the broker. This must be set to a unique integer for
each broker.
broker.id=2
6 ) 配置环境变量
( 1 )在 /etc/profile.d/my_env.sh 文件中增加 kafka 环境变量配置
[atguigu@hadoop102 module]$ sudo vim /etc/profile
增加如下内容:
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
( 2 )刷新一下环境变量。
[atguigu@hadoop102 module]$ source /etc/profile
( 3 )分发环境变量文件到其他节点,并 source 。
[atguigu@hadoop102 module]$ sudo /home/atguigu/bin/xsync /etc/profile.d/my_env.sh
[atguigu@hadoop103 module]$ source /etc/profile
[atguigu@hadoop104 module]$ source /etc/profile
7 ) 启动集群
( 1 )先启动 Zookeeper 集群,然后启动 Kafka 。
[atguigu@hadoop102 kafka]$ zk.sh start
( 2 )依次在 hadoop102 、 hadoop103 、 hadoop104 节点上启动 Kafka 。
[atguigu@hadoop102 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
[atguigu@hadoop103 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
[atguigu@hadoop104 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
注意:配置文件的路径要能够到 server.properties 。
8 ) 关闭集群
[atguigu@hadoop102 kafka]$ bin/kafka-server-stop.sh
[atguigu@hadoop103 kafka]$ bin/kafka-server-stop.sh
[atguigu@hadoop104 kafka]$ bin/kafka-server-stop.sh
通过jps命令查看运行的情况
