Structured Streaming 整合 Kafka指南
用于 Kafka 0.10 的结构化流式处理集成,用于从 Kafka 读取数据和写入数据。
从kafka读取数据
// Subscribe to 1 topic
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
// Subscribe to 1 topic, with headers
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.option("includeHeaders", "true")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)", "headers")
.as[(String, String, Map)]
// Subscribe to multiple topics
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1,topic2")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
// Subscribe to a pattern
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribePattern", "topic.*")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
从kafka指定offset读取数据
// Subscribe to 1 topic defaults to the earliest and latest offsets
val df = spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
// Subscribe to multiple topics, specifying explicit Kafka offsets
val df = spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1,topic2")
.option("startingOffsets", """{"topic1":{"0":23,"1":-2},"topic2":{"0":-2}}""")
.option("endingOffsets", """{"topic1":{"0":50,"1":-1},"topic2":{"0":-1}}""")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
// Subscribe to a pattern, at the earliest and latest offsets
val df = spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribePattern", "topic.*")
.option("startingOffsets", "earliest")
.option("endingOffsets", "latest")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
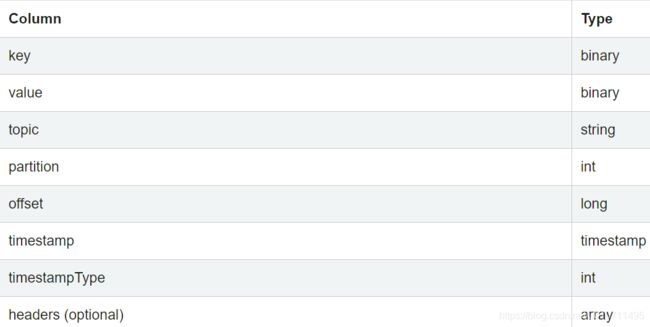
source中内容每一行的schema如下,key和value都是binary类型的,所以需要处理下,cast as string
以下参数必须设置,其中assign,subscribe,subscribePattern三个参数选择一个设置就可以了
| Option | value | meaning |
|---|---|---|
| assign | json string {“topicA”:[0,1],“topicB”:[2,4]} | Specific TopicPartitions to consume. |
| subscribe | 逗号分开的topics | The topic list to subscribe. |
| subscribePattern | java正则表达式 | The pattern used to subscribe to topic(s). |
| kafka.bootstrap.servers | 逗号分割的host:port | 等价于 Kafka “bootstrap.servers” 配置 |
以下参数是可选的
startingOffsets
取值可以是
"earliest", "latest" (streaming only),
or json string """ {"topicA":{"0":23,"1":-1},"topicB":{"0":-2}} """
含义
开始查询时的起点,可以是“earliest”(来自最早的偏移量),“latest”(仅来自最新的偏移量),或者是为每个TopicPartition指定起始偏移量的json字符串。 在json中,可使用-2作为偏移量来指代最早的,-1到最新的。 注意:对于批查询,不允许最新(隐式或在json中使用-1)。 对于流查询,这仅在启动新查询时适用,并且恢复将始终从查询中断的地方开始。 查询期间新发现的分区最早将开始。
参考
Structured Streaming + Kafka Integration Guide (Kafka broker version 0.10.0 or higher) - Spark 3.0.1 Documentation
https://spark.apache.org/docs/latest/structured-streaming-kafka-integration.html